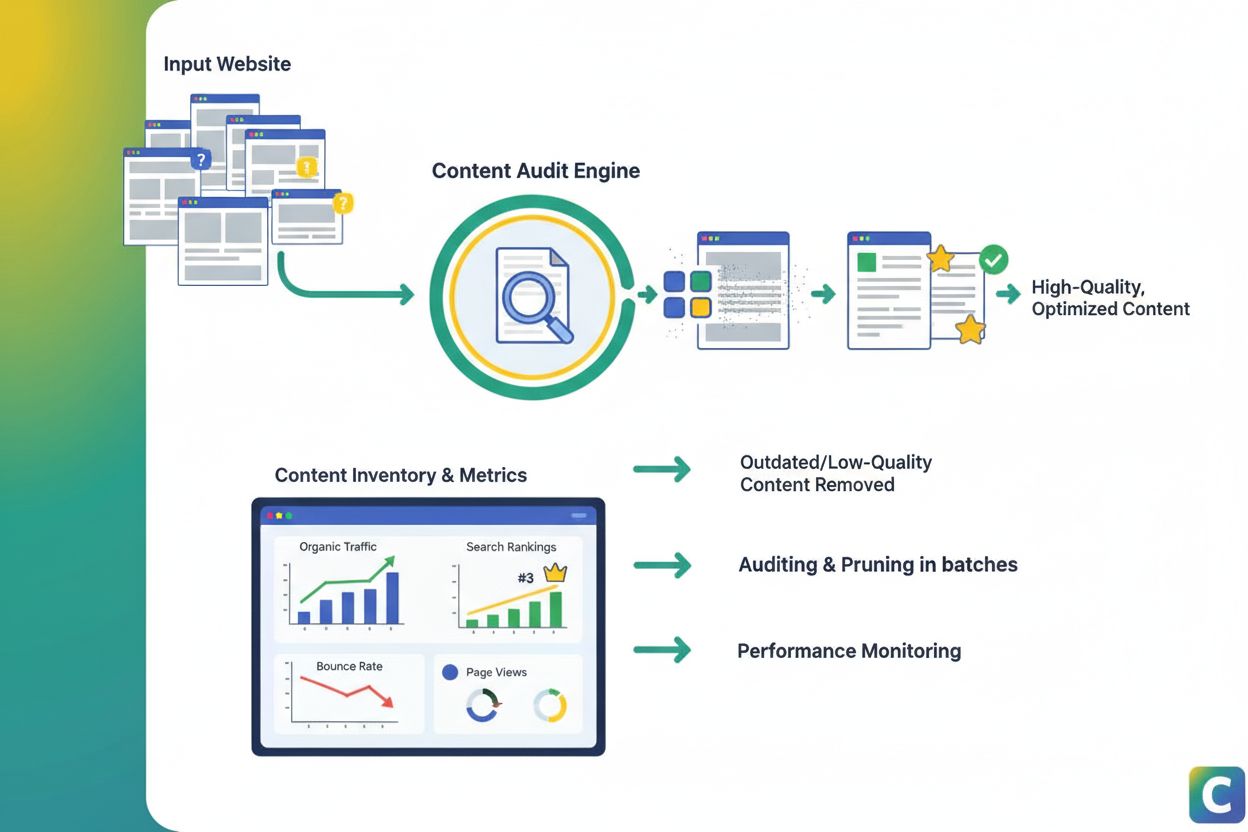
Poda de Contenido
La poda de contenido es la eliminación estratégica o actualización de contenido con bajo rendimiento para mejorar el SEO, la experiencia del usuario y la visibi...
18 min de lectura

Descubre qué es la poda de contenido para IA, cómo funciona, los diferentes métodos de poda y por qué es esencial para implementar modelos de IA eficientes en dispositivos edge y entornos con recursos limitados.
La poda de contenido para IA es una técnica que elimina selectivamente parámetros, pesos o tokens redundantes o menos importantes de los modelos de IA para reducir su tamaño, mejorar la velocidad de inferencia y disminuir el consumo de memoria manteniendo la calidad del rendimiento.
La poda de contenido para IA es una técnica fundamental de optimización utilizada para reducir la complejidad computacional y la huella de memoria de los modelos de inteligencia artificial sin comprometer significativamente su rendimiento. Este proceso implica identificar y eliminar de manera sistemática componentes redundantes o menos importantes de las redes neuronales, incluidos pesos individuales, neuronas completas, filtros o incluso tokens en modelos de lenguaje. El objetivo principal es crear modelos más ligeros, rápidos y eficientes que puedan implementarse eficazmente en dispositivos con recursos limitados como teléfonos inteligentes, sistemas de computación en el borde y dispositivos IoT.
El concepto de poda se inspira en los sistemas biológicos, específicamente en la poda sináptica del cerebro humano, donde se eliminan conexiones neuronales innecesarias durante el desarrollo. De manera similar, la poda en IA reconoce que las redes neuronales entrenadas suelen contener muchos parámetros que contribuyen mínimamente al resultado final. Al eliminar estos componentes redundantes, los desarrolladores pueden lograr reducciones sustanciales en el tamaño del modelo mientras mantienen o incluso mejoran la precisión mediante procesos cuidadosos de ajuste fino.
La poda de contenido opera bajo el principio de que no todos los parámetros en una red neuronal son igualmente importantes para realizar predicciones. Durante el proceso de entrenamiento, las redes neuronales desarrollan interconexiones complejas, muchas de las cuales se vuelven redundantes o contribuyen de manera insignificante al proceso de toma de decisiones del modelo. La poda identifica estos componentes menos críticos y los elimina, resultando en una arquitectura de red dispersa que requiere menos recursos computacionales para operar.
La efectividad de la poda depende de varios factores, incluido el método de poda empleado, el grado de agresividad de la estrategia de poda y el proceso de ajuste fino posterior. Diferentes enfoques de poda apuntan a distintos aspectos de las redes neuronales. Algunos métodos se centran en pesos individuales (poda no estructurada), mientras que otros eliminan neuronas completas, filtros o canales (poda estructurada). La elección del método impacta significativamente tanto en la eficiencia del modelo resultante como en la compatibilidad con aceleradores de hardware modernos.
| Tipo de Poda | Objetivo | Beneficios | Desafíos |
|---|---|---|---|
| Poda de Pesos | Conexiones/pesos individuales | Máxima compresión, redes dispersas | Puede que no acelere la ejecución en hardware |
| Poda Estructurada | Neuronas, filtros, canales | Amigable con hardware, inferencia más rápida | Menos compresión que la no estructurada |
| Poda Dinámica | Parámetros dependientes del contexto | Eficiencia adaptativa, ajuste en tiempo real | Implementación compleja, mayor sobrecarga |
| Poda de Capas | Capas o bloques completos | Reducción significativa de tamaño | Riesgo de pérdida de precisión, requiere validación cuidadosa |
La poda no estructurada, también conocida como poda de pesos, opera a nivel granular eliminando pesos individuales de las matrices de peso de la red. Este enfoque suele utilizar criterios basados en la magnitud, donde los pesos con valores cercanos a cero se consideran menos importantes y se eliminan. La red resultante se vuelve dispersa, lo que significa que solo una fracción de las conexiones originales permanece activa durante la inferencia. Si bien la poda no estructurada puede lograr impresionantes tasas de compresión—a veces reduciendo el número de parámetros en un 90% o más—las redes dispersas resultantes no siempre se traducen en mejoras proporcionales de velocidad en hardware estándar sin soporte especializado para cómputo disperso.
La poda estructurada adopta un enfoque diferente al eliminar grupos completos de parámetros simultáneamente, como filtros completos en capas convolucionales, neuronas completas en capas totalmente conectadas o canales enteros. Este método es particularmente valioso para la implementación práctica porque los modelos resultantes son naturalmente compatibles con aceleradores de hardware modernos como GPUs y TPUs. Cuando se podan filtros completos de capas convolucionales, los ahorros computacionales se realizan de inmediato sin requerir operaciones especializadas con matrices dispersas. Las investigaciones han demostrado que la poda estructurada puede reducir el tamaño del modelo entre un 50% y un 90% manteniendo una precisión comparable a los modelos originales.
La poda dinámica representa un enfoque más sofisticado donde el proceso de poda se adapta durante la inferencia del modelo según la entrada específica que se procesa. Esta técnica aprovecha el contexto externo como embeddings de hablante, señales de eventos o información específica del idioma para ajustar dinámicamente qué parámetros están activos. En sistemas de generación aumentada por recuperación, la poda dinámica puede reducir el tamaño del contexto aproximadamente en un 80% mientras mejora simultáneamente la precisión de las respuestas al filtrar información irrelevante. Este enfoque adaptativo es especialmente valioso para sistemas de IA multimodales que deben procesar diversos tipos de entrada de manera eficiente.
La poda iterativa con ajuste fino representa uno de los enfoques más adoptados en la práctica. Este método implica un proceso cíclico: podar una parte de la red, ajustar finamente los parámetros restantes para recuperar la precisión perdida, evaluar el rendimiento y repetir. La naturaleza iterativa de este enfoque permite a los desarrolladores equilibrar cuidadosamente la compresión del modelo con el mantenimiento del rendimiento. En lugar de eliminar todos los parámetros innecesarios de una vez—lo que podría dañar catastróficamente el rendimiento del modelo—la poda iterativa reduce gradualmente la complejidad de la red mientras permite que el modelo se adapte y aprenda cuáles son los parámetros restantes más críticos.
La poda de una sola vez (one-shot) ofrece una alternativa más rápida en la que toda la operación de poda ocurre en un solo paso después del entrenamiento, seguida de una fase de ajuste fino. Aunque este enfoque es computacionalmente más eficiente que los métodos iterativos, conlleva un mayor riesgo de degradación de precisión si se eliminan demasiados parámetros simultáneamente. La poda de una sola vez es particularmente útil cuando los recursos computacionales para procesos iterativos son limitados, aunque normalmente requiere un ajuste fino más extenso para recuperar el rendimiento.
La poda basada en análisis de sensibilidad emplea un mecanismo de clasificación más sofisticado al medir cuánto aumenta la función de pérdida del modelo cuando se eliminan pesos o neuronas específicos. Los parámetros que tienen un impacto mínimo en la función de pérdida se identifican como candidatos seguros para la poda. Este enfoque basado en datos ofrece decisiones de poda más matizadas en comparación con los métodos simples basados en magnitud, lo que a menudo resulta en una mejor preservación de la precisión a niveles de compresión equivalentes.
La Hipótesis del Boleto de Lotería presenta un marco teórico interesante que sugiere que dentro de las grandes redes neuronales existe una subred más pequeña y dispersa—el “boleto ganador”—que puede lograr una precisión comparable a la de la red original cuando se entrena desde la misma inicialización. Esta hipótesis tiene profundas implicaciones para comprender la redundancia en las redes y ha inspirado nuevas metodologías de poda que intentan identificar y aislar estas subredes eficientes.
La poda de contenido se ha vuelto indispensable en numerosas aplicaciones de IA donde la eficiencia computacional es primordial. La implementación en dispositivos móviles y embebidos representa uno de los casos de uso más significativos, donde los modelos podados permiten capacidades sofisticadas de IA en smartphones y dispositivos IoT con potencia de procesamiento y batería limitadas. El reconocimiento de imágenes, los asistentes de voz y las aplicaciones de traducción en tiempo real se benefician de modelos podados que mantienen la precisión consumiendo recursos mínimos.
Los sistemas autónomos incluidos los vehículos autónomos y drones requieren toma de decisiones en tiempo real con mínima latencia. Las redes neuronales podadas permiten a estos sistemas procesar datos de sensores y tomar decisiones críticas dentro de estrictos límites de tiempo. La reducción de la carga computacional se traduce directamente en tiempos de respuesta más rápidos, lo cual es esencial para aplicaciones críticas de seguridad.
En entornos de computación en la nube y en el borde, la poda reduce tanto los costos computacionales como los requisitos de almacenamiento para implementar modelos a gran escala. Las organizaciones pueden atender a más usuarios con la misma infraestructura o, alternativamente, reducir significativamente sus gastos computacionales. Los escenarios de computación en el borde se benefician especialmente de los modelos podados, ya que permiten procesamiento de IA sofisticado en dispositivos lejos de los centros de datos centralizados.
La evaluación de la efectividad de la poda requiere una consideración cuidadosa de múltiples métricas más allá de la simple reducción del número de parámetros. La latencia de inferencia—el tiempo que requiere un modelo para generar una salida a partir de una entrada—es una métrica crítica que impacta directamente en la experiencia del usuario en aplicaciones en tiempo real. Una poda efectiva debería reducir sustancialmente la latencia de inferencia, permitiendo tiempos de respuesta más rápidos para los usuarios finales.
La precisión del modelo y las puntuaciones F1 deben mantenerse durante todo el proceso de poda. El desafío fundamental de la poda es lograr una compresión significativa sin sacrificar el rendimiento predictivo. Las estrategias de poda bien diseñadas mantienen la precisión dentro de un 1-5% del modelo original mientras logran una reducción de parámetros del 50-90%. La reducción de la huella de memoria es igualmente importante, ya que determina si los modelos pueden implementarse en dispositivos con recursos limitados.
Las investigaciones que comparan modelos grandes y dispersos (grandes redes con muchos parámetros eliminados) frente a modelos pequeños y densos (redes más pequeñas entrenadas desde cero) con huellas de memoria idénticas muestran consistentemente que los modelos grandes y dispersos superan a sus contrapartes pequeñas y densas. Este hallazgo subraya el valor de comenzar con redes más grandes y bien entrenadas y podarlas estratégicamente en lugar de intentar entrenar redes más pequeñas desde el principio.
La degradación de la precisión sigue siendo el principal desafío en la poda de contenido. Una poda agresiva puede reducir sustancialmente el rendimiento del modelo, requiriendo una calibración cuidadosa de la intensidad de la poda. Los desarrolladores deben encontrar el punto óptimo donde se maximicen las ganancias de compresión sin una pérdida de precisión inaceptable. Este punto óptimo varía según la aplicación específica, la arquitectura del modelo y los umbrales de rendimiento aceptables.
Los problemas de compatibilidad de hardware pueden limitar los beneficios prácticos de la poda. Si bien la poda no estructurada crea redes dispersas con menos parámetros, el hardware moderno está optimizado para operaciones de matrices densas. Las redes dispersas pueden no ejecutarse significativamente más rápido en GPUs estándar sin bibliotecas de cómputo disperso y soporte de hardware especializado. La poda estructurada aborda esta limitación al mantener patrones de cómputo densos, aunque a costa de una compresión menos agresiva.
La sobrecarga computacional de los propios métodos de poda puede ser considerable. Los enfoques iterativos y basados en análisis de sensibilidad requieren múltiples pasadas de entrenamiento y una evaluación cuidadosa, consumiendo recursos computacionales significativos. Los desarrolladores deben sopesar el costo único de la poda frente a los ahorros continuos de implementar modelos más eficientes.
Surgen preocupaciones de generalización cuando la poda es demasiado agresiva. Los modelos podados en exceso pueden funcionar bien en datos de entrenamiento y validación pero generalizar mal a nuevos datos no vistos. Las estrategias de validación adecuadas y las pruebas cuidadosas en conjuntos de datos diversos son esenciales para garantizar que los modelos podados mantengan un rendimiento robusto en entornos de producción.
Una poda de contenido exitosa requiere un enfoque sistemático basado en mejores prácticas desarrolladas a partir de una amplia investigación y experiencia práctica. Comienza con redes más grandes y bien entrenadas en lugar de intentar entrenar redes más pequeñas desde cero. Las redes más grandes brindan más redundancia y flexibilidad para la poda, y la investigación demuestra consistentemente que las redes grandes podadas superan a las redes pequeñas entrenadas desde el principio.
Utiliza poda iterativa con ajuste fino cuidadoso para reducir gradualmente la complejidad del modelo manteniendo el rendimiento. Este enfoque proporciona un mejor control sobre la compensación entre precisión y eficiencia y permite que el modelo se adapte a la eliminación de parámetros. Emplea poda estructurada para la implementación práctica cuando la aceleración por hardware sea importante, ya que produce modelos que se ejecutan eficientemente en hardware estándar sin requerir soporte especializado para cómputo disperso.
Valida extensamente en conjuntos de datos diversos para asegurar que los modelos podados generalicen bien más allá de los datos de entrenamiento. Supervisa múltiples métricas de rendimiento incluyendo precisión, latencia de inferencia, uso de memoria y consumo de energía para evaluar integralmente la efectividad de la poda. Considera el entorno de implementación objetivo al seleccionar estrategias de poda, ya que diferentes dispositivos y plataformas tienen características de optimización distintas.
El campo de la poda de contenido continúa evolucionando con técnicas y metodologías emergentes. La Poda de Tokens Adaptativa Contextual (CATP) representa un enfoque de vanguardia que utiliza alineación semántica y diversidad de características para retener selectivamente solo los tokens más relevantes en modelos de lenguaje. Esta técnica es especialmente valiosa para grandes modelos de lenguaje y sistemas multimodales donde la gestión del contexto es crítica.
La integración con bases de datos vectoriales como Pinecone y Weaviate permite estrategias de poda de contexto más sofisticadas al almacenar y recuperar eficientemente la información relevante. Estas integraciones apoyan decisiones de poda dinámica basadas en la similitud semántica y la puntuación de relevancia, mejorando tanto la eficiencia como la precisión.
La combinación con otras técnicas de compresión como la cuantización y la destilación de conocimiento crea efectos sinérgicos, permitiendo una compresión de modelos aún más agresiva. Los modelos que se podan, cuantifican y destilan simultáneamente pueden lograr tasas de compresión de 100x o más manteniendo niveles de rendimiento aceptables.
A medida que los modelos de IA continúan creciendo en complejidad y los escenarios de implementación se vuelven cada vez más diversos, la poda de contenido seguirá siendo una técnica crítica para hacer que la IA avanzada sea accesible y práctica en todo el espectro de entornos informáticos, desde potentes centros de datos hasta dispositivos edge con recursos limitados.
Descubre cómo AmICited te ayuda a rastrear cuándo tu contenido aparece en respuestas generadas por IA en ChatGPT, Perplexity y otros motores de búsqueda de IA. Asegura la visibilidad de tu marca en el futuro impulsado por IA.
La poda de contenido es la eliminación estratégica o actualización de contenido con bajo rendimiento para mejorar el SEO, la experiencia del usuario y la visibi...

Aprende estrategias esenciales para optimizar tu contenido de soporte para sistemas de IA como ChatGPT, Perplexity y Google AI Overviews. Descubre las mejores p...
Discusión comunitaria sobre la poda de contenido para la visibilidad en IA. Cuándo eliminar contenido antiguo, cuándo consolidar y cuándo dejar el contenido tal...