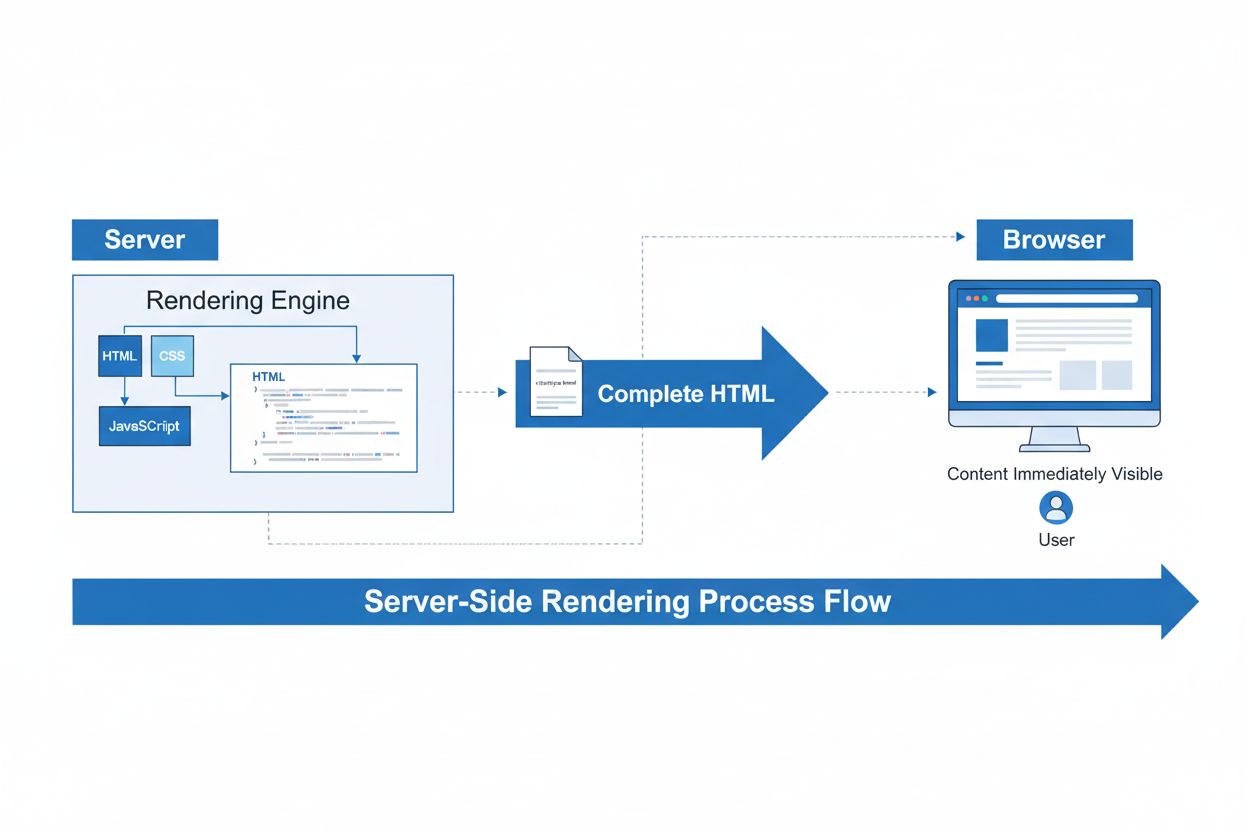
Renderizado del lado del servidor (SSR)
El Renderizado del lado del servidor (SSR) es una técnica web donde los servidores renderizan páginas HTML completas antes de enviarlas a los navegadores. Descu...
14 min de lectura

Descubre cómo el renderizado del lado del servidor permite un procesamiento eficiente de IA, despliegue de modelos y una inferencia en tiempo real para aplicaciones impulsadas por IA y cargas de trabajo LLM.
El renderizado del lado del servidor para la IA es un enfoque arquitectónico donde los modelos de inteligencia artificial y el procesamiento de inferencia ocurren en el servidor en lugar de en los dispositivos del cliente. Esto permite gestionar de manera eficiente tareas de IA computacionalmente intensivas, garantiza un rendimiento constante para todos los usuarios y simplifica el despliegue y las actualizaciones de modelos.
El renderizado del lado del servidor para la IA se refiere a un patrón arquitectónico donde los modelos de inteligencia artificial, el procesamiento de inferencia y las tareas computacionales se ejecutan en servidores backend en lugar de en dispositivos cliente como navegadores o teléfonos móviles. Este enfoque difiere fundamentalmente del renderizado tradicional del lado del cliente, donde JavaScript se ejecuta en el navegador del usuario para generar contenido. En aplicaciones de IA, el renderizado del lado del servidor significa que los grandes modelos de lenguaje (LLM), la inferencia de aprendizaje automático y la generación de contenido impulsada por IA ocurren de forma centralizada en una infraestructura de servidores potente antes de enviar los resultados a los usuarios. Este cambio arquitectónico se ha vuelto cada vez más importante a medida que las capacidades de la IA requieren mayor potencia computacional y resultan esenciales para las aplicaciones web modernas.
El concepto surgió al reconocer una desalineación crítica entre lo que requieren las aplicaciones modernas de IA y lo que los dispositivos cliente pueden proporcionar realísticamente. Los frameworks de desarrollo web tradicionales como React, Angular y Vue.js popularizaron el renderizado del lado del cliente durante la década de 2010, pero este enfoque genera desafíos significativos al aplicarse a cargas de trabajo intensivas en IA. El renderizado del lado del servidor para la IA aborda estos desafíos aprovechando hardware especializado, gestión centralizada de modelos e infraestructura optimizada a la que los dispositivos cliente simplemente no pueden igualar. Esto representa un cambio fundamental de paradigma en la forma en que los desarrolladores diseñan aplicaciones impulsadas por IA.
Los requerimientos computacionales de los sistemas de IA modernos hacen que el renderizado del lado del servidor no solo sea beneficioso, sino a menudo necesario. Los dispositivos cliente, especialmente smartphones y portátiles económicos, carecen de la potencia de procesamiento para gestionar la inferencia de IA en tiempo real de manera eficiente. Cuando los modelos de IA se ejecutan en los dispositivos cliente, los usuarios experimentan retrasos notorios, mayor consumo de batería y un rendimiento inconsistente dependiendo de las capacidades de su hardware. El renderizado del lado del servidor elimina estos problemas al centralizar el procesamiento de IA en una infraestructura equipada con GPUs, TPUs y aceleradores de IA especializados que ofrecen un rendimiento muy superior al de los dispositivos de consumo.
Más allá del rendimiento, el renderizado del lado del servidor para la IA ofrece ventajas clave en gestión de modelos, seguridad y consistencia. Cuando los modelos de IA operan en servidores, los desarrolladores pueden actualizar, ajustar y desplegar nuevas versiones instantáneamente sin requerir que los usuarios descarguen actualizaciones o gestionen diferentes versiones de modelos localmente. Esto es especialmente importante para grandes modelos de lenguaje y sistemas de aprendizaje automático que evolucionan rápidamente con mejoras y parches de seguridad frecuentes. Además, mantener los modelos de IA en servidores previene el acceso no autorizado, la extracción de modelos y el robo de propiedad intelectual que se hace posible cuando los modelos se distribuyen a los dispositivos cliente.
| Aspecto | IA del lado del cliente | IA del lado del servidor |
|---|---|---|
| Ubicación del procesamiento | Navegador o dispositivo del usuario | Servidores backend |
| Requisitos de hardware | Limitados a las capacidades del dispositivo | GPUs especializadas, TPUs, aceleradores de IA |
| Rendimiento | Variable, dependiente del dispositivo | Consistente, optimizado |
| Actualizaciones de modelos | Requiere descargas del usuario | Despliegue instantáneo |
| Seguridad | Modelos expuestos a extracción | Modelos protegidos en servidores |
| Latencia | Depende de la potencia del dispositivo | Infraestructura optimizada |
| Escalabilidad | Limitada por dispositivo | Altamente escalable entre usuarios |
| Complejidad de desarrollo | Alta (fragmentación de dispositivos) | Baja (gestión centralizada) |
El sobrecoste y la latencia de red representan retos significativos en aplicaciones de IA. Los sistemas de IA modernos requieren comunicación constante con servidores para actualizaciones de modelos, recuperación de datos de entrenamiento y escenarios de procesamiento híbrido. El renderizado del lado del cliente, irónicamente, incrementa las solicitudes de red respecto a las aplicaciones tradicionales, reduciendo los beneficios de rendimiento que se buscaban con el procesamiento en el cliente. El renderizado del lado del servidor consolida estas comunicaciones, disminuyendo los retrasos de ida y vuelta y permitiendo que funciones de IA en tiempo real como traducción en vivo, generación de contenido y procesamiento de visión por computadora funcionen sin los problemas de latencia de la inferencia en el cliente.
La complejidad de sincronización surge cuando las aplicaciones de IA necesitan mantener estados consistentes entre múltiples servicios de IA simultáneamente. Las aplicaciones modernas suelen utilizar servicios de embeddings, modelos de completado, modelos ajustados y motores de inferencia especializados que deben coordinarse entre sí. Gestionar este estado distribuido en los dispositivos cliente introduce complejidad significativa y potencial para inconsistencias de datos, especialmente en funciones de IA colaborativas en tiempo real. El renderizado del lado del servidor centraliza la gestión de estos estados, asegurando que todos los usuarios vean resultados consistentes y eliminando la sobrecarga de ingeniería de sincronización compleja en el cliente.
La fragmentación de dispositivos crea grandes retos de desarrollo para la IA del lado del cliente. Los dispositivos varían en sus capacidades de IA, incluyendo unidades de procesamiento neuronal, aceleración por GPU, soporte WebGL y limitaciones de memoria. Crear experiencias de IA consistentes en este panorama fragmentado requiere gran esfuerzo de ingeniería, estrategias de degradación progresiva y múltiples rutas de código para distintas capacidades. El renderizado del lado del servidor elimina esta fragmentación asegurando que todos los usuarios acceden a la misma infraestructura de IA optimizada, independientemente de las especificaciones de su dispositivo.
El renderizado del lado del servidor permite arquitecturas de aplicaciones de IA más simples y mantenibles al centralizar funciones críticas. En lugar de distribuir modelos de IA y lógica de inferencia entre miles de dispositivos cliente, los desarrolladores mantienen una única implementación optimizada en servidores. Esta centralización ofrece beneficios inmediatos como ciclos de despliegue más rápidos, depuración más sencilla y una optimización de rendimiento más directa. Cuando un modelo de IA necesita mejoras o se detecta un error, los desarrolladores lo corrigen una sola vez en el servidor en lugar de intentar distribuir actualizaciones a millones de clientes con tasas de adopción variables.
La eficiencia de recursos mejora drásticamente con el renderizado del lado del servidor. La infraestructura de servidores permite compartir recursos de forma eficiente entre todos los usuarios, con agrupación de conexiones, estrategias de caché y balanceo de carga para optimizar el uso del hardware. Una sola GPU en un servidor puede procesar solicitudes de inferencia de miles de usuarios de forma secuencial, mientras que distribuir esa misma capacidad a los clientes requeriría millones de GPUs. Esta eficiencia se traduce en menores costos operativos, menor impacto ambiental y mejor escalabilidad a medida que las aplicaciones crecen.
La seguridad y la protección de la propiedad intelectual se facilitan mucho con el renderizado del lado del servidor. Los modelos de IA representan una inversión significativa en investigación, datos de entrenamiento y recursos computacionales. Mantener los modelos en servidores previene ataques de extracción de modelos, accesos no autorizados y robo de propiedad intelectual que puede ocurrir cuando se distribuyen a dispositivos cliente. Además, el procesamiento en el servidor permite control de acceso detallado, registro de auditoría y supervisión de cumplimiento que sería imposible de aplicar en dispositivos distribuidos.
Los frameworks modernos han evolucionado para soportar de manera efectiva el renderizado del lado del servidor para cargas de trabajo de IA. Next.js lidera esta evolución con Server Actions que permiten procesamiento de IA directamente desde componentes del servidor. Los desarrolladores pueden llamar APIs de IA, procesar grandes modelos de lenguaje y transmitir respuestas a los clientes con un mínimo de código repetitivo. El framework gestiona la complejidad de la comunicación servidor-cliente, permitiendo centrarse en la lógica de IA en vez de en cuestiones de infraestructura.
SvelteKit ofrece un enfoque orientado al rendimiento para el renderizado de IA del lado del servidor con sus funciones load, que se ejecutan en el servidor antes del renderizado. Esto permite preprocesar datos de IA, generar recomendaciones y preparar contenido enriquecido por IA antes de enviar el HTML al cliente. Las aplicaciones resultantes tienen una huella de JavaScript mínima mientras mantienen todas las capacidades de IA, creando experiencias de usuario excepcionalmente rápidas.
Herramientas especializadas como el Vercel AI SDK abstraen la complejidad de transmitir respuestas de IA, gestionar el conteo de tokens y manejar diversas APIs de proveedores de IA. Estas herramientas permiten a los desarrolladores construir aplicaciones de IA sofisticadas sin necesidad de conocimientos profundos de infraestructura. Las opciones de infraestructura, incluyendo Vercel Edge Functions, Cloudflare Workers y AWS Lambda, ofrecen procesamiento de IA del lado del servidor distribuido globalmente, reduciendo la latencia al manejar solicitudes más cerca de los usuarios y manteniendo la gestión centralizada de modelos.
El renderizado efectivo de IA en el servidor requiere estrategias avanzadas de caché para gestionar costos computacionales y latencia. El caché en Redis almacena respuestas de IA solicitadas frecuentemente y sesiones de usuario, eliminando procesamiento redundante para consultas similares. El caché CDN distribuye contenido estático generado por IA a nivel global, asegurando que los usuarios reciban respuestas desde servidores cercanos geográficamente. Las estrategias de caché en el edge distribuyen contenido procesado por IA a través de redes de borde, ofreciendo respuestas de ultra baja latencia mientras se mantiene la gestión centralizada de modelos.
Estos enfoques de caché trabajan juntos para crear sistemas de IA eficientes que escalan a millones de usuarios sin incrementos proporcionales en los costos computacionales. Al almacenar respuestas de IA en varios niveles de caché, las aplicaciones pueden servir la gran mayoría de solicitudes desde caché y solo calcular nuevas respuestas para consultas verdaderamente novedosas. Esto reduce de forma drástica los costos de infraestructura y mejora la experiencia del usuario con tiempos de respuesta más rápidos.
La evolución hacia el renderizado del lado del servidor representa una maduración de las prácticas de desarrollo web en respuesta a los requerimientos de la IA. A medida que la IA se vuelve central en las aplicaciones web, las realidades computacionales exigen arquitecturas centradas en el servidor. El futuro implica enfoques híbridos sofisticados que decidan automáticamente dónde renderizar según el tipo de contenido, capacidades del dispositivo, condiciones de red y necesidades de procesamiento de IA. Los frameworks mejorarán progresivamente las aplicaciones con capacidades de IA, garantizando que la funcionalidad principal funcione universalmente y enriqueciendo la experiencia donde sea posible.
Este cambio de paradigma incorpora lecciones de la era de las Single Page Applications mientras aborda los retos de las aplicaciones nativas de IA. Las herramientas y frameworks ya están listos para que los desarrolladores aprovechen los beneficios del renderizado del lado del servidor en la era de la IA, habilitando la próxima generación de aplicaciones web inteligentes, receptivas y eficientes.
Haz seguimiento de cómo aparecen tu dominio y marca en respuestas generadas por IA en ChatGPT, Perplexity y otros motores de búsqueda con IA. Obtén información en tiempo real sobre tu visibilidad en IA.
El Renderizado del lado del servidor (SSR) es una técnica web donde los servidores renderizan páginas HTML completas antes de enviarlas a los navegadores. Descu...
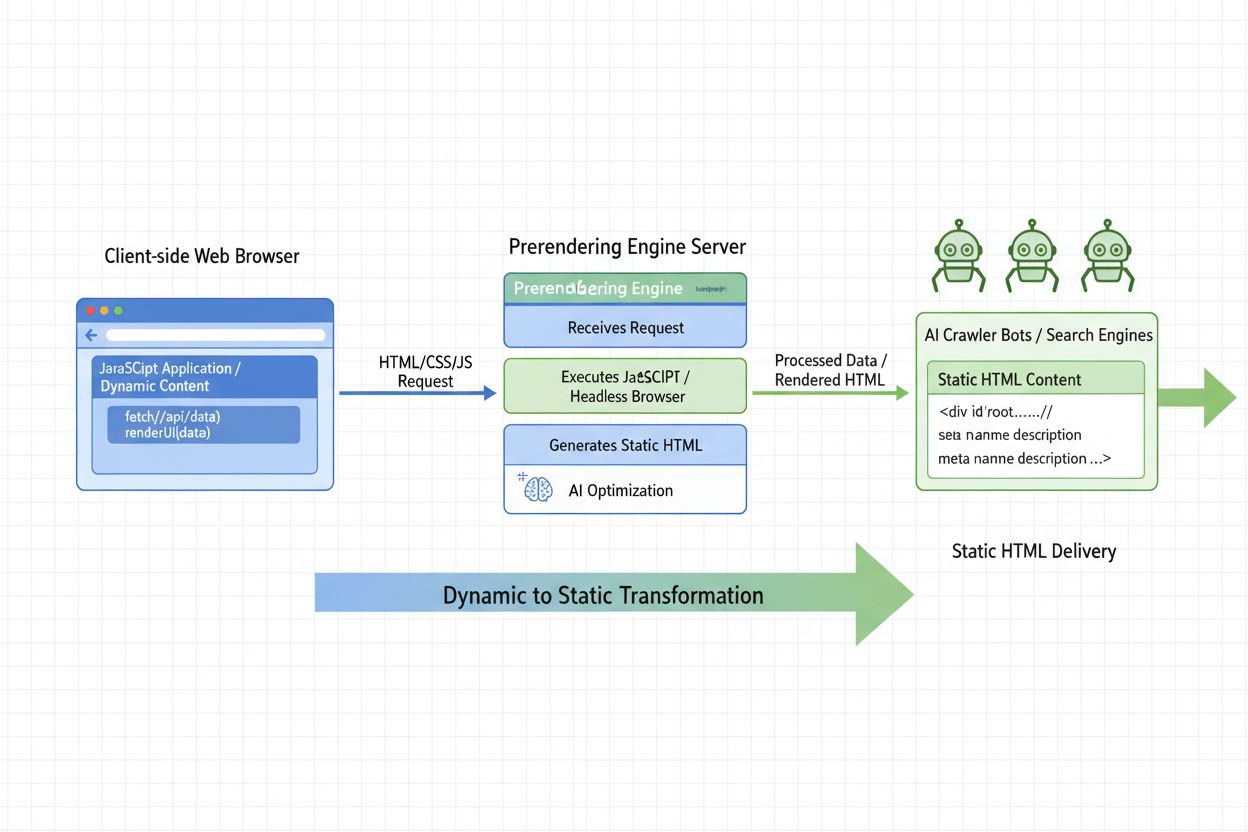
Aprende qué es el prerenderizado para IA y cómo las estrategias de renderizado del lado del servidor optimizan tu sitio web para la visibilidad de rastreadores ...

Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.