La práctica estratégica de permitir o bloquear selectivamente rastreadores de IA para controlar cómo se utiliza el contenido para entrenamiento frente a recuperación en tiempo real. Esto implica el uso de archivos robots.txt, controles a nivel de servidor y herramientas de monitoreo para gestionar qué sistemas de IA pueden acceder a tu contenido y para qué fines.
Gestión de rastreadores de IA
La práctica estratégica de permitir o bloquear selectivamente rastreadores de IA para controlar cómo se utiliza el contenido para entrenamiento frente a recuperación en tiempo real. Esto implica el uso de archivos robots.txt, controles a nivel de servidor y herramientas de monitoreo para gestionar qué sistemas de IA pueden acceder a tu contenido y para qué fines.
¿Qué es la gestión de rastreadores de IA?
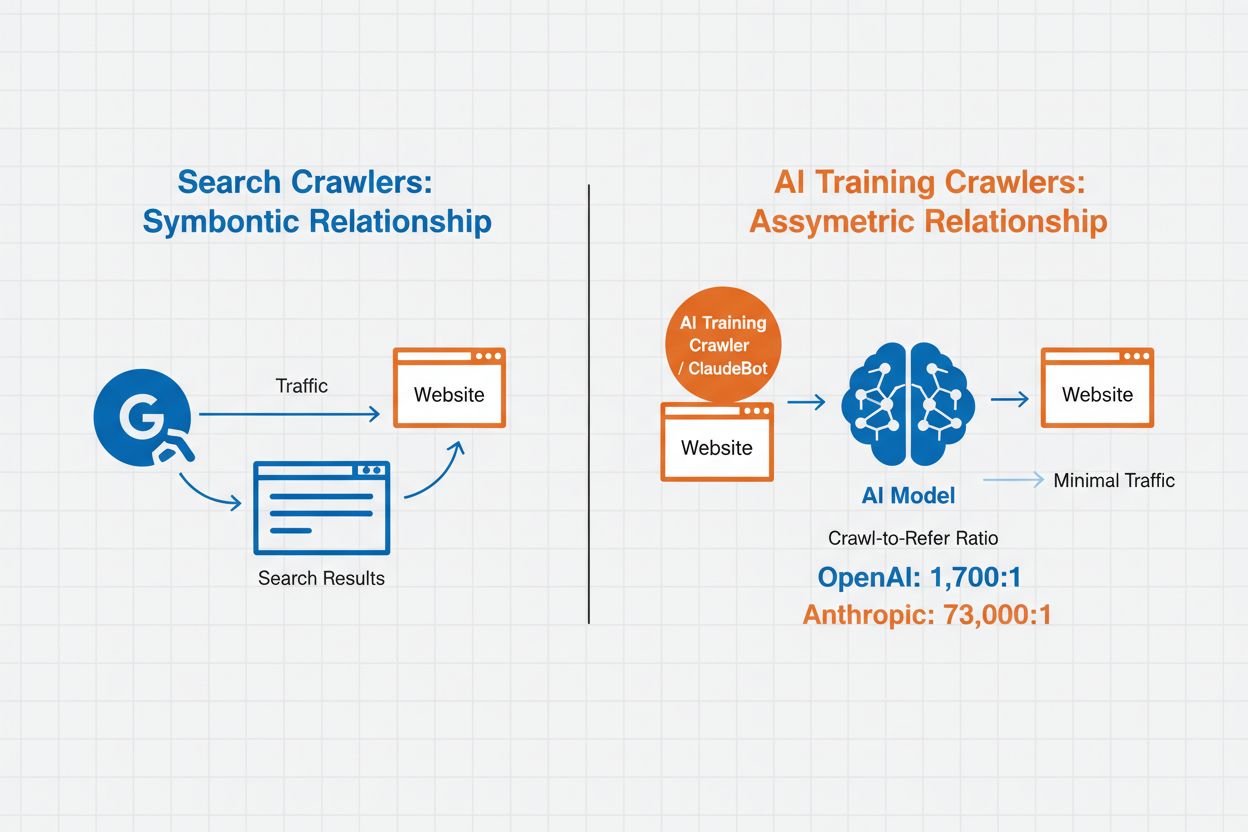
La gestión de rastreadores de IA se refiere a la práctica de controlar y monitorear cómo los sistemas de inteligencia artificial acceden y utilizan el contenido de un sitio web para fines de entrenamiento y búsqueda. A diferencia de los rastreadores de motores de búsqueda tradicionales que indexan contenido para resultados de búsqueda web, los rastreadores de IA están diseñados específicamente para recopilar datos para entrenar grandes modelos de lenguaje o para potenciar funciones de búsqueda impulsadas por IA. La escala de esta actividad varía drásticamente entre organizaciones: los rastreadores de OpenAI operan con una proporción de rastreo a referencia de 1,700:1, es decir, acceden al contenido 1,700 veces por cada referencia que proporcionan, mientras que la proporción de Anthropic alcanza 73,000:1, lo que resalta el enorme consumo de datos que requieren los sistemas modernos de IA. Una gestión eficaz de rastreadores permite a los propietarios de sitios web decidir si su contenido contribuye al entrenamiento de IA, aparece en resultados de búsqueda de IA o permanece protegido contra el acceso automatizado.
Tipos de rastreadores de IA
Los rastreadores de IA se dividen en tres categorías distintas según su propósito y patrones de uso de datos. Los rastreadores de entrenamiento están diseñados para recopilar datos para el desarrollo de modelos de aprendizaje automático, consumiendo grandes cantidades de contenido para mejorar las capacidades de la IA. Los rastreadores de búsqueda y cita indexan contenido para potenciar funciones de búsqueda impulsadas por IA y proporcionar atribución en respuestas generadas por IA, permitiendo que los usuarios descubran tu contenido a través de interfaces de IA. Los rastreadores activados por el usuario operan a demanda cuando los usuarios interactúan con herramientas de IA, como cuando un usuario de ChatGPT sube un documento o solicita el análisis de una página web específica. Comprender estas categorías te ayuda a tomar decisiones informadas sobre qué rastreadores permitir o bloquear según tu estrategia de contenido y objetivos de negocio.
Tipo de rastreador
Propósito
Ejemplos
¿Usa datos de entrenamiento?
Entrenamiento
Desarrollo y mejora de modelos
GPTBot, ClaudeBot
Sí
Búsqueda/Cita
Resultados de búsqueda de IA y atribución
Google-Extended, OAI-SearchBot, PerplexityBot
Varía
Activados por usuario
Análisis de contenido bajo demanda
ChatGPT-User, Meta-ExternalAgent, Amazonbot
Específico al contexto
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
La gestión de rastreadores de IA impacta directamente el tráfico, los ingresos y el valor de tu contenido. Cuando los rastreadores consumen tu contenido sin compensación, pierdes la oportunidad de beneficiarte de ese tráfico a través de referencias, impresiones publicitarias o participación de los usuarios. Los sitios web han reportado reducciones significativas de tráfico debido a que los usuarios obtienen respuestas directamente en respuestas generadas por IA en vez de hacer clic en la fuente original, cortando efectivamente el tráfico de referencia y los ingresos publicitarios asociados. Más allá de las implicaciones financieras, existen consideraciones legales y éticas importantes: tu contenido representa propiedad intelectual y tienes el derecho de controlar cómo se utiliza y si recibes atribución o compensación. Además, permitir el acceso irrestricto de rastreadores puede aumentar la carga del servidor y los costos de ancho de banda, especialmente por rastreadores con tasas de rastreo agresivas que no respetan directivas de limitación de velocidad.
Robots.txt y controles técnicos
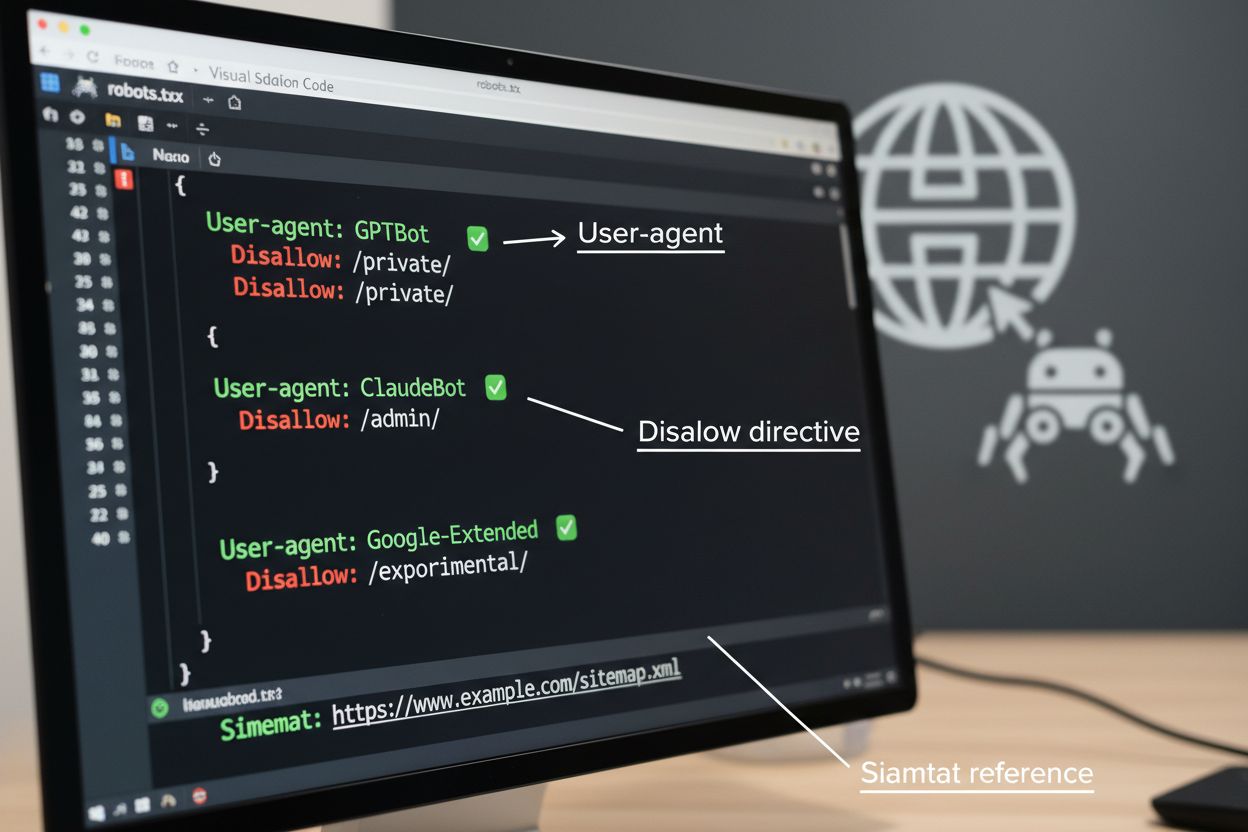
El archivo robots.txt es la herramienta fundamental para gestionar el acceso de rastreadores, colocado en el directorio raíz de tu sitio web para comunicar las preferencias de rastreo a los agentes automatizados. Este archivo utiliza directivas User-agent para dirigir a rastreadores específicos y reglas Disallow o Allow para permitir o restringir el acceso a determinadas rutas y recursos. Sin embargo, robots.txt presenta limitaciones importantes: es un estándar voluntario que depende del cumplimiento de los rastreadores, y bots maliciosos o mal diseñados pueden ignorarlo por completo. Además, robots.txt no impide que los rastreadores accedan a contenido disponible públicamente; solo solicita que respeten tus preferencias. Por estas razones, robots.txt debe formar parte de un enfoque por capas en la gestión de rastreadores y no ser tu única defensa.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Métodos avanzados de control
Más allá de robots.txt, varias técnicas avanzadas ofrecen una aplicación más fuerte y un control más granular sobre el acceso de rastreadores. Estos métodos operan en diferentes capas de tu infraestructura y pueden combinarse para una protección integral:
Reglas .htaccess: Directivas a nivel de servidor que pueden bloquear agentes de usuario o rangos de IP específicos antes de servir el contenido
Listas blancas/negra de IP: Restringen el acceso según las direcciones IP asociadas a rastreadores de IA conocidos, aunque esto requiere mantener listas de IP actualizadas
Soluciones WAF de Cloudflare: Usan reglas de firewall de aplicaciones web para identificar y bloquear tráfico de rastreadores en función de patrones de comportamiento y firmas
Encabezados HTTP (X-Robots-Tag): Envían directivas a los rastreadores directamente en los encabezados de respuesta, proporcionando control por página o recurso, más difícil de ignorar que robots.txt
Limitación de velocidad: Implementar límites de velocidad agresivos en el tráfico de rastreadores para hacer inviable económicamente la recopilación masiva de datos
Huellas digitales de bots: Analizar patrones de solicitudes, encabezados y comportamientos para identificar rastreadores sofisticados que intentan ocultar su identidad
Equilibrando protección y visibilidad
La decisión de bloquear rastreadores de IA conlleva importantes compensaciones entre la protección del contenido y la visibilidad. Bloquear todos los rastreadores de IA elimina la posibilidad de que tu contenido aparezca en resultados de búsqueda de IA, resúmenes impulsados por IA o sea citado por herramientas de IA, lo que podría reducir la visibilidad ante usuarios que descubren contenido a través de estos canales emergentes. Por el contrario, permitir acceso irrestricto significa que tu contenido alimenta el entrenamiento de IA sin compensación y puede reducir el tráfico de referencia al recibir los usuarios respuestas directamente de sistemas de IA. Un enfoque estratégico implica el bloqueo selectivo: permitir rastreadores de citas como OAI-SearchBot y PerplexityBot que generen tráfico de referencia mientras se bloquean rastreadores de entrenamiento como GPTBot y ClaudeBot que consumen datos sin atribución. También podrías considerar permitir Google-Extended para mantener la visibilidad en Google AI Overviews, que puede generar tráfico significativo, mientras bloqueas rastreadores de entrenamiento de la competencia. La estrategia óptima depende del tipo de contenido, el modelo de negocio y la audiencia: los sitios de noticias y editores pueden priorizar el bloqueo, mientras que los creadores de contenido educativo pueden beneficiarse de una mayor visibilidad en IA.
Monitoreo y cumplimiento
Implementar controles de rastreadores solo es efectivo si verificas que realmente cumplan con tus directivas. El análisis de registros del servidor es el método principal para monitorear la actividad de los rastreadores: revisa tus registros de acceso en busca de cadenas User-Agent y patrones de solicitud para identificar qué rastreadores acceden a tu sitio y si respetan tus reglas de robots.txt. Muchos rastreadores afirman cumplir pero continúan accediendo a rutas bloqueadas, por lo que el monitoreo continuo es esencial. Herramientas como Cloudflare Radar proporcionan visibilidad en tiempo real de los patrones de tráfico y pueden ayudar a identificar comportamientos sospechosos o rastreadores no conformes. Configura alertas automáticas para intentos de acceso a recursos bloqueados y audita periódicamente tus registros para detectar nuevos rastreadores o patrones cambiantes que puedan indicar intentos de evasión.
Mejores prácticas e implementación
Implementar una gestión efectiva de rastreadores de IA requiere un enfoque sistemático que equilibre la protección con la visibilidad estratégica. Sigue estos ocho pasos para establecer una estrategia integral de gestión de rastreadores:
Audita el acceso actual: Analiza los registros de tu servidor para identificar qué rastreadores de IA acceden actualmente a tu sitio, su frecuencia y los recursos que buscan
Define tu política: Decide qué rastreadores se alinean con tus objetivos de negocio—considera rastreadores de entrenamiento vs. búsqueda, impacto en el tráfico y valor del contenido
Documenta tus decisiones: Crea documentación clara de tu política de rastreadores y el razonamiento detrás de cada decisión para futuras referencias y alineación del equipo
Implementa controles: Despliega reglas en robots.txt, encabezados HTTP y controles avanzados como limitación de velocidad o bloqueo por IP según tu política
Monitorea el cumplimiento: Revisa regularmente los registros del servidor y utiliza herramientas de monitoreo para verificar que los rastreadores respeten tus directivas
Configura alertas: Establece alertas automáticas para accesos de rastreadores no conformes o intentos de burlar tus controles
Revisa trimestralmente: Reevalúa tu estrategia de gestión de rastreadores cada trimestre a medida que surgen nuevos rastreadores y evolucionan tus necesidades de negocio
Actualiza ante nuevos rastreadores: Mantente informado sobre nuevos rastreadores de IA y actualiza tus controles de forma proactiva en lugar de reactiva
AmICited.com: monitorea tus referencias de IA
AmICited.com ofrece una plataforma especializada para monitorear cómo los sistemas de IA referencian y utilizan tu contenido en diferentes modelos y aplicaciones. El servicio proporciona seguimiento en tiempo real de tus citas en respuestas generadas por IA, ayudándote a entender qué rastreadores usan más activamente tu contenido y con qué frecuencia aparece tu trabajo en resultados de IA. Analizando patrones de rastreadores y datos de citas, AmICited.com permite tomar decisiones basadas en datos sobre tu estrategia de gestión de rastreadores: puedes ver exactamente qué rastreadores aportan valor a través de citas y referencias frente a aquellos que consumen contenido sin atribución. Esta inteligencia convierte la gestión de rastreadores de una práctica defensiva en una herramienta estratégica para optimizar la visibilidad y el impacto de tu contenido en la web impulsada por IA.
Preguntas frecuentes
¿Cuál es la diferencia entre bloquear rastreadores de entrenamiento de IA y rastreadores de búsqueda?
Los rastreadores de entrenamiento como GPTBot y ClaudeBot recopilan contenido para construir conjuntos de datos para el desarrollo de grandes modelos de lenguaje, consumiendo tu contenido sin proporcionar tráfico de referencia. Los rastreadores de búsqueda como OAI-SearchBot y PerplexityBot indexan contenido para resultados de búsqueda impulsados por IA y pueden enviar visitantes de regreso a tu sitio mediante citas. Bloquear rastreadores de entrenamiento protege tu contenido de ser incorporado en modelos de IA, mientras que bloquear rastreadores de búsqueda puede reducir tu visibilidad en plataformas de descubrimiento impulsadas por IA.
¿Bloquear rastreadores de IA perjudicará mi posicionamiento SEO?
No. Bloquear rastreadores de entrenamiento de IA como GPTBot, ClaudeBot y CCBot no afecta tu posicionamiento en Google o Bing. Los motores de búsqueda tradicionales utilizan rastreadores diferentes (Googlebot, Bingbot) que operan independientemente de los bots de entrenamiento de IA. Solo bloquea rastreadores de búsqueda tradicionales si quieres desaparecer completamente de los resultados de búsqueda, lo cual sí dañaría tu SEO.
¿Cómo sé qué rastreadores están accediendo a mi sitio?
Examina los registros de acceso de tu servidor para identificar las cadenas User-Agent de los rastreadores. Busca entradas que contengan 'bot', 'crawler' o 'spider' en el campo User-Agent. Herramientas como Cloudflare Radar ofrecen visibilidad en tiempo real sobre qué rastreadores de IA acceden a tu sitio y sus patrones de tráfico. También puedes usar plataformas de analítica que diferencian el tráfico de bots del de visitantes humanos.
¿Pueden los rastreadores de IA ignorar las directivas de robots.txt?
Sí. robots.txt es un estándar de orientación que depende del cumplimiento del rastreador—no es exigible. Los rastreadores bien comportados de grandes empresas como OpenAI, Anthropic y Google generalmente respetan las directivas de robots.txt, pero algunos rastreadores las ignoran por completo. Para una protección más fuerte, implementa bloqueos a nivel de servidor mediante .htaccess, reglas de firewall o restricciones basadas en IP.
¿Debo bloquear todos los rastreadores de IA o usar un bloqueo selectivo?
Esto depende de tus prioridades empresariales. Bloquear todos los rastreadores de entrenamiento protege tu contenido de ser incorporado en modelos de IA mientras potencialmente permite rastreadores de búsqueda que pueden generar tráfico de referencia. Muchos editores usan bloqueos selectivos que apuntan a rastreadores de entrenamiento permitiendo rastreadores de búsqueda y de citas. Considera el tipo de contenido, fuentes de tráfico y modelo de monetización al decidir tu estrategia.
¿Con qué frecuencia debo actualizar mi política de gestión de rastreadores?
Revisa y actualiza tu política de gestión de rastreadores al menos trimestralmente. Surgen nuevos rastreadores de IA regularmente y los existentes actualizan sus user agents sin previo aviso. Sigue recursos como el proyecto ai.robots.txt en GitHub para listas mantenidas por la comunidad y revisa tus registros de servidor mensualmente para identificar nuevos rastreadores que accedan a tu sitio.
¿Cuál es el impacto de los rastreadores de IA en el tráfico y los ingresos de mi sitio web?
Los rastreadores de IA pueden impactar significativamente tu tráfico y tus ingresos. Cuando los usuarios obtienen respuestas directamente de sistemas de IA en lugar de visitar tu sitio, pierdes tráfico de referencia y las impresiones de anuncios asociadas. Investigaciones muestran ratios de rastreo a referencia de hasta 73,000:1 en algunas plataformas de IA, es decir, acceden a tu contenido miles de veces por cada visitante que envían de regreso. Bloquear rastreadores de entrenamiento puede proteger tu tráfico, mientras que permitir rastreadores de búsqueda puede aportar algunos beneficios de referencia.
¿Cómo puedo verificar que mi configuración de robots.txt está funcionando?
Revisa tus registros de servidor para ver si los rastreadores bloqueados aún aparecen en tus logs de acceso. Usa herramientas de prueba como el probador de robots.txt de Google Search Console o el Robots.txt Tester de Merkle para validar tu configuración. Accede directamente a tu archivo robots.txt en tu sitio para verificar que el contenido sea correcto. Monitorea tus registros regularmente para detectar rastreadores que deberían estar bloqueados pero siguen apareciendo.
Monitorea cómo los sistemas de IA referencian tu contenido
AmICited.com rastrea en tiempo real las referencias de IA a tu marca en ChatGPT, Perplexity, Google AI Overviews y otros sistemas de IA. Toma decisiones basadas en datos sobre tu estrategia de gestión de rastreadores.
Cómo identificar rastreadores de IA en los registros del servidor: Guía completa de detección
Aprende a identificar y monitorear rastreadores de IA como GPTBot, PerplexityBot y ClaudeBot en los registros de tu servidor. Descubre cadenas de user-agent, mé...
Cómo los rastreadores de IA priorizan páginas: presupuesto de rastreo y factores de posicionamiento
Aprende cómo los rastreadores de IA priorizan páginas utilizando capacidad y demanda de rastreo. Entiende la optimización del presupuesto de rastreo para ChatGP...
¿A qué rastreadores de IA debo permitir el acceso? Guía completa para 2025
Descubre qué rastreadores de IA permitir o bloquear en tu robots.txt. Guía completa que cubre GPTBot, ClaudeBot, PerplexityBot y más de 25 rastreadores de IA co...
12 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.