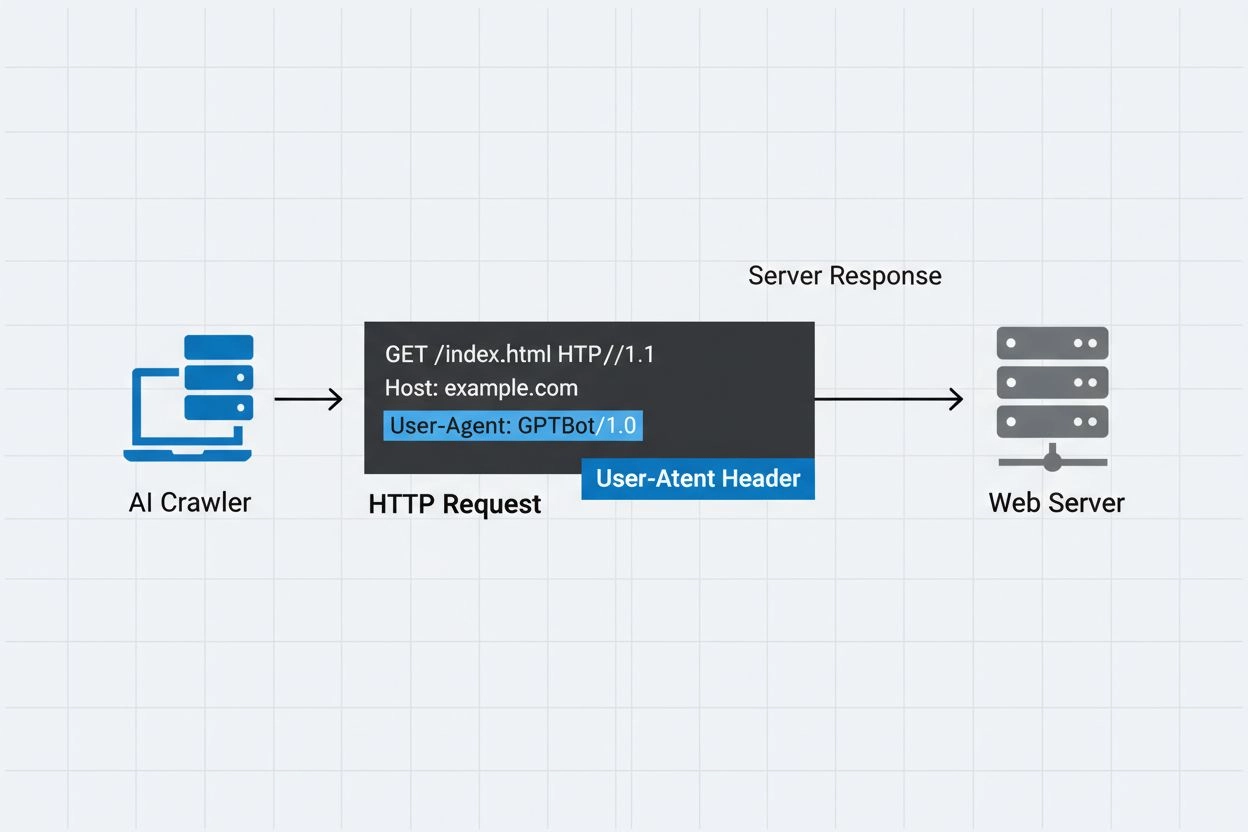
La cadena de identificación que los rastreadores de IA envían a los servidores web en los encabezados HTTP, utilizada para el control de acceso, seguimiento analítico y para distinguir bots legítimos de IA de scrapers maliciosos. Identifica el propósito, versión y origen del rastreador.
Agente de usuario de rastreador de IA
La cadena de identificación que los rastreadores de IA envían a los servidores web en los encabezados HTTP, utilizada para el control de acceso, seguimiento analítico y para distinguir bots legítimos de IA de scrapers maliciosos. Identifica el propósito, versión y origen del rastreador.
Definición de agente de usuario de rastreador de IA
Un agente de usuario de rastreador de IA es una cadena de encabezado HTTP que identifica bots automatizados que acceden a contenido web con fines de entrenamiento de inteligencia artificial, indexación o investigación. Esta cadena funciona como la identidad digital del rastreador, comunicando a los servidores web quién está haciendo la solicitud y cuáles son sus intenciones. El agente de usuario es crucial para los rastreadores de IA porque permite a los propietarios de sitios web reconocer, rastrear y controlar cómo sus contenidos están siendo accedidos por distintos sistemas de IA. Sin una identificación adecuada de agente de usuario, distinguir entre rastreadores de IA legítimos y bots maliciosos se vuelve mucho más difícil, lo que lo convierte en un componente esencial de las prácticas responsables de scraping web y recolección de datos.
Comunicación HTTP y encabezados de agente de usuario
El encabezado de agente de usuario es un componente crítico de las solicitudes HTTP, apareciendo en los encabezados de todas las solicitudes que envía cada navegador y bot al acceder a un recurso web. Cuando un rastreador realiza una solicitud a un servidor web, incluye metadatos sobre sí mismo en los encabezados HTTP, siendo la cadena de agente de usuario uno de los identificadores más importantes. Esta cadena normalmente contiene información sobre el nombre del rastreador, versión, la organización que lo opera y, a menudo, una URL de contacto o correo electrónico para fines de verificación. El agente de usuario permite a los servidores identificar el cliente solicitante y tomar decisiones sobre si servir el contenido, limitar la frecuencia de solicitudes o bloquear el acceso por completo. A continuación se muestran ejemplos de cadenas de agente de usuario de los principales rastreadores de IA:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
Nombre del rastreador
Propósito
Ejemplo de agente de usuario
Verificación IP
GPTBot
Recolección de datos de entrenamiento
Mozilla/5.0…compatible; GPTBot/1.3
Rangos de IP de OpenAI
ClaudeBot
Entrenamiento de modelos
Mozilla/5.0…compatible; ClaudeBot/1.0
Rangos de IP de Anthropic
OAI-SearchBot
Indexación de búsqueda
Mozilla/5.0…compatible; OAI-SearchBot/1.3
Rangos de IP de OpenAI
PerplexityBot
Indexación de búsqueda
Mozilla/5.0…compatible; PerplexityBot/1.0
Rangos de IP de Perplexity
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Varias empresas destacadas de IA operan sus propios rastreadores con identificadores de agente de usuario y propósitos específicos. Estos rastreadores representan distintos casos de uso dentro del ecosistema de IA:
GPTBot (OpenAI): Recopila datos de entrenamiento para ChatGPT y otros modelos de OpenAI, respeta las directivas de robots.txt
ClaudeBot (Anthropic): Recoge contenido para entrenar modelos Claude, puede bloquearse mediante robots.txt
OAI-SearchBot (OpenAI): Indexa contenido web específicamente para funciones de búsqueda y búsquedas potenciadas por IA
PerplexityBot (Perplexity AI): Rastrea la web para proporcionar resultados de búsqueda y capacidades de investigación en su plataforma
Gemini-Deep-Research (Google): Realiza tareas de investigación profunda para el modelo Gemini de Google
Meta-ExternalAgent (Meta): Recoge datos para iniciativas de entrenamiento e investigación en IA de Meta
Bingbot (Microsoft): Cumple doble propósito de indexación tradicional y generación de respuestas potenciadas por IA
Cada rastreador tiene rangos de IP específicos y documentación oficial a la que los propietarios de sitios pueden recurrir para verificar legitimidad e implementar controles de acceso adecuados.
Suplantación del agente de usuario y desafíos de verificación
Las cadenas de agente de usuario pueden ser fácilmente falsificadas por cualquier cliente que realice una solicitud HTTP, por lo que no son suficientes como único mecanismo de autenticación para identificar rastreadores de IA legítimos. Los bots maliciosos suelen suplantar cadenas populares de agente de usuario para disfrazar su verdadera identidad y eludir las medidas de seguridad del sitio web o las restricciones de robots.txt. Para abordar esta vulnerabilidad, los expertos en seguridad recomiendan usar la verificación por IP como una capa adicional de autenticación, comprobando que las solicitudes provengan de los rangos de IP oficiales publicados por las empresas de IA. El emergente estándar RFC 9421 de Firmas de Mensajes HTTP proporciona capacidades de verificación criptográfica, permitiendo a los rastreadores firmar digitalmente sus solicitudes para que los servidores puedan verificar criptográficamente su autenticidad. Sin embargo, distinguir entre rastreadores reales y falsos sigue siendo un reto, ya que atacantes determinados pueden suplantar tanto cadenas de agente de usuario como direcciones IP a través de proxies o infraestructuras comprometidas. Este juego del gato y el ratón entre operadores de rastreadores y propietarios de sitios web preocupados por la seguridad sigue evolucionando a medida que se desarrollan nuevas técnicas de verificación.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Uso de robots.txt con directivas de agente de usuario
Los propietarios de sitios web pueden controlar el acceso de rastreadores especificando directivas de agente de usuario en su archivo robots.txt, permitiendo un control granular sobre qué rastreadores pueden acceder a qué partes de su sitio. El archivo robots.txt utiliza identificadores de agente de usuario para dirigir reglas personalizadas a rastreadores específicos, haciendo posible permitir algunos rastreadores mientras se bloquean otros. Aquí tienes un ejemplo de configuración de robots.txt:
Aunque robots.txt ofrece un mecanismo conveniente para control de rastreadores, tiene importantes limitaciones:
Robots.txt es puramente informativo y no es exigible; los rastreadores pueden ignorarlo
Los agentes de usuario suplantados pueden eludir completamente las restricciones de robots.txt
La verificación del lado del servidor mediante listas blancas de IP brinda una protección más sólida
Las reglas de Firewall de Aplicaciones Web (WAF) pueden bloquear solicitudes de rangos de IP no autorizados
Combinar robots.txt con verificación de IP crea una estrategia de control de acceso más robusta
Análisis de la actividad de rastreadores mediante registros del servidor
Los propietarios de sitios web pueden aprovechar los registros del servidor para rastrear y analizar la actividad de los rastreadores de IA, obteniendo visibilidad sobre qué sistemas de IA acceden a su contenido y con qué frecuencia. Al examinar los registros de solicitudes HTTP y filtrar por agentes de usuario conocidos de rastreadores de IA, los administradores pueden entender el impacto en el ancho de banda y los patrones de recolección de datos de diferentes empresas de IA. Herramientas como plataformas de análisis de registros, servicios de analítica web y scripts personalizados pueden analizar estos registros para identificar tráfico de rastreadores, medir la frecuencia de solicitudes y calcular volúmenes de transferencia de datos. Esta visibilidad es especialmente importante para creadores de contenido y editores que desean entender cómo se utiliza su trabajo para el entrenamiento de IA y si deberían implementar restricciones de acceso. Servicios como AmICited.com juegan un papel crucial en este ecosistema al monitorizar y rastrear cómo los sistemas de IA citan y referencian contenido de toda la web, brindando transparencia a los creadores sobre el uso de su contenido en el entrenamiento de IA. Comprender la actividad de los rastreadores ayuda a los propietarios de sitios a tomar decisiones informadas sobre sus políticas de contenido y negociar con empresas de IA sobre derechos de uso de datos.
Mejores prácticas para la gestión del acceso de rastreadores de IA
Implementar una gestión eficaz del acceso de rastreadores de IA requiere un enfoque por capas que combine varias técnicas de verificación y monitorización:
Combina la comprobación de agente de usuario con la verificación de IP – Nunca confíes solo en las cadenas de agente de usuario; cruza siempre con los rangos de IP oficiales publicados por las empresas de IA
Mantén listas blancas de IP actualizadas – Revisa y actualiza periódicamente tus reglas de firewall con los rangos de IP más recientes de OpenAI, Anthropic, Google y otros proveedores de IA
Implementa análisis regular de registros – Programa revisiones periódicas de los registros del servidor para identificar actividad sospechosa de rastreadores e intentos de acceso no autorizado
Distingue entre tipos de rastreadores – Diferencia entre rastreadores de entrenamiento (GPTBot, ClaudeBot) y rastreadores de búsqueda (OAI-SearchBot, PerplexityBot) para aplicar políticas adecuadas
Considera las implicaciones éticas – Equilibra las restricciones de acceso con la realidad de que el entrenamiento de IA se beneficia de fuentes de contenido diversas y de alta calidad
Utiliza servicios de monitorización – Aprovecha plataformas como AmICited.com para rastrear cómo tu contenido es usado y citado por sistemas de IA, asegurando la atribución adecuada y entendiendo el impacto de tu contenido
Siguiendo estas prácticas, los propietarios de sitios web pueden mantener el control sobre su contenido mientras apoyan el desarrollo responsable de los sistemas de IA.
Preguntas frecuentes
¿Qué es una cadena de agente de usuario?
Un agente de usuario es una cadena en el encabezado HTTP que identifica al cliente que realiza una solicitud web. Contiene información sobre el software, el sistema operativo y la versión de la aplicación solicitante, ya sea un navegador, rastreador o bot. Esta cadena permite a los servidores web identificar y rastrear los diferentes tipos de clientes que acceden a su contenido.
¿Por qué los rastreadores de IA necesitan cadenas de agente de usuario?
Las cadenas de agente de usuario permiten a los servidores web identificar qué rastreador está accediendo a su contenido, permitiendo a los propietarios de sitios web controlar el acceso, rastrear la actividad de los rastreadores y distinguir entre diferentes tipos de bots. Esto es esencial para gestionar el ancho de banda, proteger el contenido y comprender cómo los sistemas de IA están usando tus datos.
¿Se pueden falsificar las cadenas de agente de usuario?
Sí, las cadenas de agente de usuario pueden ser fácilmente suplantadas ya que solo son valores de texto en los encabezados HTTP. Por eso, la verificación de IP y las Firmas de Mensajes HTTP son métodos adicionales importantes para confirmar la verdadera identidad de un rastreador y evitar que bots maliciosos se hagan pasar por rastreadores legítimos.
¿Cómo puedo bloquear rastreadores de IA específicos?
Puedes usar robots.txt con directivas de agente de usuario para solicitar a los rastreadores que no accedan a tu sitio, pero esto no es exigible. Para un control más fuerte, utiliza verificación del lado del servidor, listas blancas/negras de IP, o reglas WAF que verifiquen tanto el agente de usuario como la dirección IP simultáneamente.
¿Cuál es la diferencia entre GPTBot y OAI-SearchBot?
GPTBot es el rastreador de OpenAI para recopilar datos de entrenamiento para modelos de IA como ChatGPT, mientras que OAI-SearchBot está diseñado para la indexación de búsqueda y para potenciar las funciones de búsqueda en ChatGPT. Tienen diferentes propósitos, tasas de rastreo y rangos de IP, por lo que requieren diferentes estrategias de control de acceso.
¿Cómo puedo verificar si un rastreador es legítimo?
Verifica la dirección IP del rastreador con la lista oficial de IP publicada por el operador del rastreador (por ejemplo, openai.com/gptbot.json para GPTBot). Los rastreadores legítimos publican sus rangos de IP, y puedes verificar que las solicitudes provienen de esos rangos usando reglas de firewall o configuraciones WAF.
¿Qué es la verificación de Firmas de Mensajes HTTP?
Las Firmas de Mensajes HTTP (RFC 9421) son un método criptográfico en el que los rastreadores firman sus solicitudes con una clave privada. Los servidores pueden verificar la firma usando la clave pública del rastreador desde su directorio .well-known, demostrando que la solicitud es auténtica y no ha sido manipulada.
¿Cómo ayuda AmICited.com con la monitorización de rastreadores de IA?
AmICited.com monitoriza cómo los sistemas de IA referencian y citan tu marca en GPTs, Perplexity, Google AI Overviews y otras plataformas de IA. Rastrea la actividad de los rastreadores y las menciones de IA, ayudándote a entender tu visibilidad en respuestas generadas por IA y cómo se está usando tu contenido.
Monitorea tu marca en sistemas de IA
Sigue cómo los rastreadores de IA referencian y citan tu contenido en ChatGPT, Perplexity, Google AI Overviews y otras plataformas de IA con AmICited.
Cómo identificar rastreadores de IA en los registros del servidor: Guía completa de detección
Aprende a identificar y monitorear rastreadores de IA como GPTBot, PerplexityBot y ClaudeBot en los registros de tu servidor. Descubre cadenas de user-agent, mé...
¿A qué rastreadores de IA debo permitir el acceso? Guía completa para 2025
Descubre qué rastreadores de IA permitir o bloquear en tu robots.txt. Guía completa que cubre GPTBot, ClaudeBot, PerplexityBot y más de 25 rastreadores de IA co...
Explicación de los rastreadores de IA: GPTBot, ClaudeBot y más
Comprende cómo funcionan los rastreadores de IA como GPTBot y ClaudeBot, sus diferencias con los rastreadores de búsqueda tradicionales y cómo optimizar tu siti...
16 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.