
Puntuación de relevancia de contenido
Descubre cómo la puntuación de relevancia de contenido utiliza algoritmos de IA para medir qué tan bien el contenido coincide con las consultas e intenciones de...
9 min de lectura

La puntuación de recuperación por IA es el proceso de cuantificar la relevancia y calidad de los documentos o fragmentos recuperados en relación con una consulta de usuario. Emplea algoritmos sofisticados para evaluar el significado semántico, la adecuación contextual y la calidad de la información, determinando qué fuentes se pasan a los modelos de lenguaje para la generación de respuestas en sistemas RAG.
La puntuación de recuperación por IA es el proceso de cuantificar la relevancia y calidad de los documentos o fragmentos recuperados en relación con una consulta de usuario. Emplea algoritmos sofisticados para evaluar el significado semántico, la adecuación contextual y la calidad de la información, determinando qué fuentes se pasan a los modelos de lenguaje para la generación de respuestas en sistemas RAG.
La puntuación de recuperación por IA es el proceso de cuantificar la relevancia y calidad de los documentos o fragmentos recuperados en relación con una consulta o tarea de usuario. A diferencia de la simple coincidencia de palabras clave, que solo identifica la coincidencia superficial de términos, la puntuación de recuperación emplea algoritmos sofisticados para evaluar el significado semántico, la adecuación contextual y la calidad de la información. Este mecanismo de puntuación es fundamental para los sistemas de Generación Aumentada por Recuperación (RAG), donde determina qué fuentes se pasan a los modelos de lenguaje para la generación de respuestas. En las aplicaciones modernas de LLM, la puntuación de recuperación impacta directamente en la precisión de la respuesta, la reducción de alucinaciones y la satisfacción del usuario, al asegurar que solo la información más relevante llegue a la etapa de generación. Por lo tanto, la calidad de la puntuación de recuperación es un componente crítico del rendimiento y la fiabilidad general del sistema.
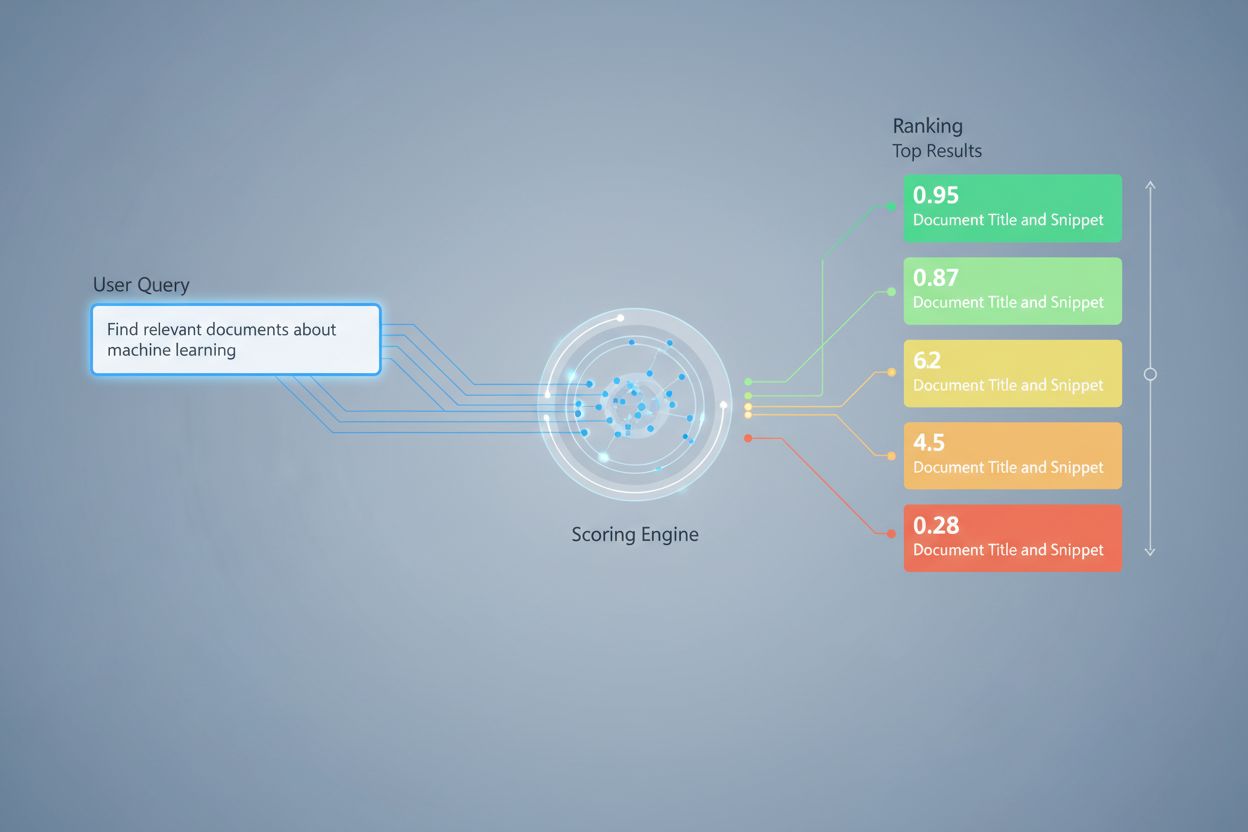
La puntuación de recuperación emplea múltiples enfoques algorítmicos, cada uno con fortalezas distintas para diferentes casos de uso. La puntuación por similitud semántica utiliza modelos de embedding para medir la alineación conceptual entre consultas y documentos en el espacio vectorial, capturando el significado más allá de las palabras clave superficiales. BM25 (Best Matching 25) es una función de clasificación probabilística que considera la frecuencia de los términos, la frecuencia inversa de los documentos y la normalización de la longitud del documento, lo que la hace muy efectiva para la recuperación de texto tradicional. TF-IDF (Frecuencia de Término-Frecuencia Inversa de Documento) pondera los términos según su importancia dentro de los documentos y en toda la colección, aunque carece de comprensión semántica. Los enfoques híbridos combinan varios métodos—como la fusión de puntuaciones BM25 y semánticas—para aprovechar tanto las señales léxicas como semánticas. Más allá de los métodos de puntuación, las métricas de evaluación como Precisión@k (porcentaje de los k mejores resultados que son relevantes), Recall@k (porcentaje de todos los documentos relevantes encontrados en los k mejores), NDCG (Ganancia Cumulativa Descontada Normalizada, que considera la posición en la clasificación) y MRR (Rango Recíproco Medio) proporcionan medidas cuantitativas de la calidad de la recuperación. Comprender las fortalezas y debilidades de cada enfoque—como la eficiencia de BM25 frente a la comprensión más profunda de la puntuación semántica—es esencial para seleccionar los métodos apropiados para aplicaciones específicas.
| Método de Puntuación | Cómo Funciona | Mejor Para | Ventaja Clave |
|---|---|---|---|
| Similitud Semántica | Compara embeddings usando similitud de coseno u otras métricas de distancia | Significado conceptual, sinónimos, paráfrasis | Captura relaciones semánticas más allá de palabras clave |
| BM25 | Clasificación probabilística considerando frecuencia de término y longitud de documento | Coincidencia exacta de frases, consultas por palabras clave | Rápido, eficiente, probado en sistemas de producción |
| TF-IDF | Pondera términos según su frecuencia en el documento y rareza en la colección | Recuperación de información tradicional | Simple, interpretable, ligero |
| Puntuación Híbrida | Combina enfoques semánticos y basados en palabras clave con fusión ponderada | Recuperación general, consultas complejas | Aprovecha fortalezas de varios métodos |
| Puntuación basada en LLM | Utiliza modelos de lenguaje para juzgar la relevancia con prompts personalizados | Evaluación de contexto complejo, tareas de dominio específico | Captura relaciones semánticas matizadas |
En los sistemas RAG, la puntuación de recuperación opera en múltiples niveles para asegurar la calidad de la generación. El sistema normalmente puntúa fragmentos individuales dentro de los documentos, permitiendo una evaluación de relevancia más detallada en lugar de tratar documentos completos como unidades atómicas. Esta puntuación de relevancia por fragmento permite al sistema extraer solo los segmentos de información más pertinentes, reduciendo el ruido y el contexto irrelevante que podría confundir al modelo de lenguaje. Los sistemas RAG suelen implementar umbrales de puntuación o mecanismos de corte que filtran los resultados con baja puntuación antes de que lleguen a la etapa de generación, evitando que fuentes de baja calidad influyan en la respuesta final. La calidad del contexto recuperado se correlaciona directamente con la calidad de la generación—los fragmentos relevantes y con alta puntuación conducen a respuestas más precisas y fundamentadas, mientras que recuperaciones de baja calidad introducen alucinaciones y errores fácticos. El monitoreo de las puntuaciones de recuperación proporciona señales de advertencia temprana de degradación del sistema, convirtiéndose en una métrica clave para el monitoreo de respuestas de IA y la garantía de calidad en sistemas de producción.
La re-clasificación sirve como un mecanismo de filtrado de segunda pasada que refina los resultados iniciales de recuperación, mejorando a menudo la precisión de la clasificación de manera significativa. Tras una primera recuperación que genera resultados candidatos con puntuaciones preliminares, un re-clasificador aplica una lógica de puntuación más sofisticada para reordenar o filtrar estos candidatos, normalmente usando modelos más costosos computacionalmente que pueden permitirse un análisis más profundo. La Fusión de Rango Recíproco (RRF) es una técnica popular que combina clasificaciones de múltiples recuperadores asignando puntuaciones según la posición del resultado, fusionando luego estas puntuaciones para producir una clasificación unificada que a menudo supera a los recuperadores individuales. La normalización de puntuaciones se vuelve crítica al combinar resultados de diferentes métodos, ya que las puntuaciones en bruto de BM25, similitud semántica y otros enfoques operan en diferentes escalas y deben calibrarse a rangos comparables. Los enfoques de recuperadores en conjunto aprovechan varias estrategias de recuperación simultáneamente, con la re-clasificación determinando el orden final basado en la evidencia combinada. Este enfoque de múltiples etapas mejora significativamente la precisión y robustez de la clasificación frente a la recuperación de una sola etapa, especialmente en dominios complejos donde diferentes métodos capturan señales de relevancia complementarias.
Precisión@k: Mide la proporción de documentos relevantes entre los k mejores resultados; útil para evaluar si los resultados recuperados son confiables (por ejemplo, Precisión@5 = 4/5 significa que el 80% de los 5 mejores resultados son relevantes)
Recall@k: Calcula el porcentaje de todos los documentos relevantes encontrados dentro de los k mejores resultados; importante para asegurar una cobertura integral de la información relevante disponible
Tasa de aciertos (Hit Rate): Métrica binaria que indica si al menos un documento relevante aparece en los k mejores resultados; útil para revisiones rápidas de calidad en sistemas de producción
NDCG (Ganancia Cumulativa Descontada Normalizada): Considera la posición en la clasificación asignando mayor valor a los documentos relevantes que aparecen antes; oscila entre 0-1 y es ideal para evaluar la calidad de la clasificación
MRR (Rango Recíproco Medio): Mide la posición promedio del primer resultado relevante a través de múltiples consultas; especialmente útil para evaluar si el documento más relevante ocupa un lugar alto
F1 Score: Media armónica de precisión y recall; proporciona una evaluación equilibrada cuando tanto los falsos positivos como los falsos negativos tienen igual importancia
MAP (Precisión Media Promediada): Promedia los valores de precisión en cada posición donde se encuentra un documento relevante; métrica integral para la calidad de la clasificación en múltiples consultas
La puntuación de relevancia basada en LLM aprovecha los propios modelos de lenguaje como jueces de la relevancia de los documentos, ofreciendo una alternativa flexible a los enfoques algorítmicos tradicionales. En este paradigma, prompts cuidadosamente diseñados instruyen a un LLM para evaluar si un fragmento recuperado responde a una consulta dada, produciendo puntuaciones binarias de relevancia (relevante/no relevante) o puntuaciones numéricas (por ejemplo, escala de 1-5 que indica la fuerza de la relevancia). Este enfoque capta relaciones semánticas matizadas y relevancia específica de dominio que los algoritmos tradicionales pueden pasar por alto, especialmente en consultas complejas que requieren comprensión profunda. Sin embargo, la puntuación basada en LLM presenta desafíos como el costo computacional (la inferencia de LLM es costosa en comparación con la similitud de embeddings), la posible inconsistencia entre diferentes prompts y modelos, y la necesidad de calibración con etiquetas humanas para asegurar que las puntuaciones se alineen con la relevancia real. A pesar de estas limitaciones, la puntuación basada en LLM ha demostrado ser valiosa para evaluar la calidad de los sistemas RAG y para crear datos de entrenamiento para modelos de puntuación especializados, convirtiéndose en una herramienta importante en el kit de monitoreo de IA para evaluar la calidad de las respuestas.
Implementar una puntuación de recuperación efectiva requiere considerar cuidadosamente múltiples factores prácticos. La selección del método depende de los requisitos del caso de uso: la puntuación semántica destaca en la captura del significado pero requiere modelos de embeddings, mientras que BM25 ofrece velocidad y eficiencia para coincidencias léxicas. El equilibrio entre velocidad y precisión es crucial—la puntuación basada en embeddings proporciona una comprensión superior de la relevancia pero incurre en costes de latencia, mientras que BM25 y TF-IDF son más rápidos pero menos sofisticados semánticamente. Las consideraciones de costo computacional incluyen el tiempo de inferencia del modelo, los requisitos de memoria y las necesidades de escalado de infraestructura, aspectos especialmente importantes para sistemas de producción de alto volumen. El ajuste de parámetros implica modificar umbrales, pesos en enfoques híbridos y cortes de re-clasificación para optimizar el rendimiento en dominios y casos de uso específicos. El monitoreo continuo del rendimiento de puntuación mediante métricas como NDCG y Precisión@k ayuda a identificar degradación con el tiempo, permitiendo mejoras proactivas del sistema y asegurando una calidad de respuesta consistente en sistemas RAG de producción.
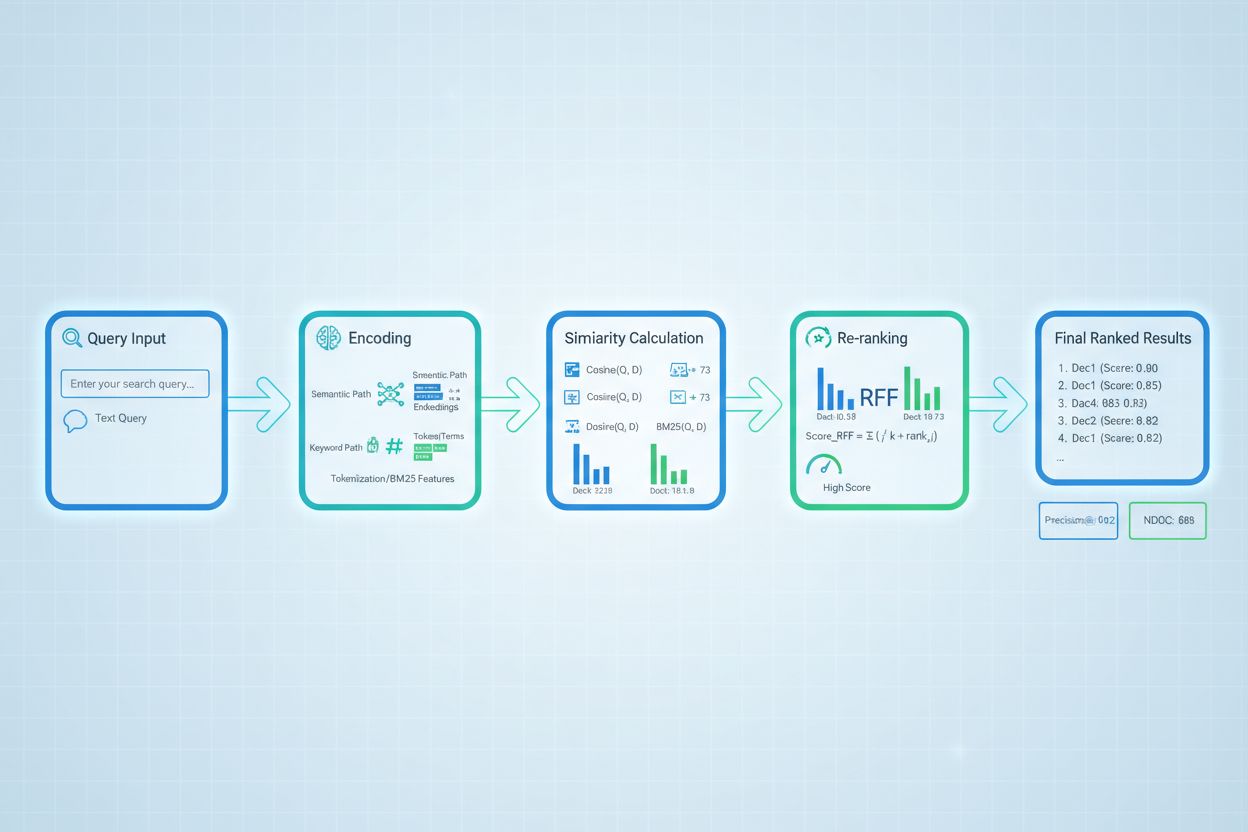
Las técnicas avanzadas de puntuación de recuperación van más allá de la evaluación básica de relevancia para capturar relaciones contextuales complejas. La reescritura de consultas puede mejorar la puntuación reformulando las consultas de usuario en múltiples formas semánticamente equivalentes, permitiendo al recuperador encontrar documentos relevantes que podrían pasarse por alto con una coincidencia literal de la consulta. Los embeddings de documentos hipotéticos (HyDE) generan documentos sintéticos relevantes a partir de consultas, y luego usan estos hipotéticos para mejorar la puntuación de recuperación al encontrar documentos reales similares al contenido relevante idealizado. Los enfoques de múltiples consultas envían varias variantes de la consulta a los recuperadores y agregan sus puntuaciones, mejorando la robustez y la cobertura en comparación con la recuperación de una sola consulta. Los modelos de puntuación específicos de dominio entrenados con datos etiquetados de industrias o dominios de conocimiento particulares pueden lograr un rendimiento superior respecto a modelos de propósito general, especialmente valiosos para aplicaciones especializadas como sistemas de IA médicos o legales. Los ajustes contextuales de puntuación consideran factores como la recencia del documento, la autoridad de la fuente y el contexto del usuario, permitiendo una evaluación de relevancia más sofisticada que va más allá de la pura similitud semántica para incorporar factores de relevancia del mundo real críticos para sistemas de IA en producción.
La puntuación de recuperación asigna valores numéricos de relevancia a los documentos según su relación con una consulta, mientras que la clasificación ordena los documentos en función de esas puntuaciones. La puntuación es el proceso de evaluación, la clasificación es el resultado del ordenamiento. Ambos son esenciales para que los sistemas RAG ofrezcan respuestas precisas.
La puntuación de recuperación determina qué fuentes llegan al modelo de lenguaje para la generación de respuestas. Una puntuación de alta calidad asegura que se seleccione información relevante, reduciendo alucinaciones y mejorando la precisión de las respuestas. Una mala puntuación conduce a contexto irrelevante y respuestas de IA poco confiables.
La puntuación semántica utiliza embeddings para entender el significado conceptual y capta sinónimos y conceptos relacionados. La puntuación basada en palabras clave (como BM25) coincide con términos y frases exactas. La puntuación semántica es mejor para comprender la intención, mientras que la puntuación por palabras clave destaca en encontrar información específica.
Las métricas clave incluyen Precisión@k (precisión de los mejores resultados), Recall@k (cobertura de documentos relevantes), NDCG (calidad de la clasificación) y MRR (posición del primer resultado relevante). Elige métricas según tu caso de uso: Precisión@k para sistemas enfocados en calidad, Recall@k para cobertura integral.
Sí, la puntuación basada en LLM utiliza modelos de lenguaje como jueces para evaluar la relevancia. Este enfoque capta relaciones semánticas matizadas pero es computacionalmente costoso. Es valioso para evaluar la calidad de RAG y crear datos de entrenamiento, aunque requiere calibración con etiquetas humanas.
La re-clasificación aplica un filtrado de segunda pasada usando modelos más sofisticados para refinar los resultados iniciales. Técnicas como la Fusión de Rango Recíproco combinan múltiples métodos de recuperación, mejorando la precisión y robustez. La re-clasificación supera significativamente la recuperación de una sola etapa en dominios complejos.
BM25 y TF-IDF son rápidos y ligeros, adecuados para sistemas en tiempo real. La puntuación semántica requiere inferencia de modelos de embedding, agregando latencia. La puntuación basada en LLM es la más costosa. Elige según tus requerimientos de latencia y recursos computacionales disponibles.
Considera tus prioridades: puntuación semántica para tareas centradas en significado, BM25 para velocidad y eficiencia, enfoques híbridos para rendimiento equilibrado. Evalúa en tu dominio específico usando métricas como NDCG y Precisión@k. Prueba múltiples métodos y mide su impacto en la calidad de la respuesta final.
Sigue cómo los sistemas de IA como ChatGPT, Perplexity y Google AI hacen referencia a tu marca y evalúan la calidad de su recuperación y clasificación de fuentes. Asegura que tu contenido esté correctamente citado y clasificado por los sistemas de IA.
Descubre cómo la puntuación de relevancia de contenido utiliza algoritmos de IA para medir qué tan bien el contenido coincide con las consultas e intenciones de...

Descubre cómo RAG combina LLMs con fuentes de datos externas para generar respuestas de IA precisas. Comprende el proceso de cinco etapas, los componentes y por...

Descubre qué es la Generación Aumentada por Recuperación (RAG), cómo funciona y por qué es esencial para respuestas precisas de IA. Explora la arquitectura, ben...