
PerplexityBot: Lo que todo propietario de sitio web debe saber
Guía completa sobre el rastreador PerplexityBot: entiende cómo funciona, gestiona el acceso, monitorea citas y optimiza para la visibilidad en Perplexity AI. Ap...
10 min de lectura

El rastreador web de Amazon utilizado para mejorar productos y servicios, incluidos Alexa, el asistente de compras Rufus y las funciones de búsqueda potenciadas por IA de Amazon. Respeta el Protocolo de Exclusión de Robots y puede ser controlado mediante directivas en robots.txt. Puede utilizarse para el entrenamiento de modelos de IA.
El rastreador web de Amazon utilizado para mejorar productos y servicios, incluidos Alexa, el asistente de compras Rufus y las funciones de búsqueda potenciadas por IA de Amazon. Respeta el Protocolo de Exclusión de Robots y puede ser controlado mediante directivas en robots.txt. Puede utilizarse para el entrenamiento de modelos de IA.
Amazonbot es el rastreador web oficial de Amazon diseñado para mejorar los productos y servicios de la compañía mediante la recopilación y el análisis de contenido web. Este sofisticado rastreador impulsa funciones clave de Amazon, incluidos el asistente de voz Alexa, el asistente de compras Rufus con IA y las experiencias de búsqueda potenciadas por inteligencia artificial de Amazon. Amazonbot opera usando la cadena de agente de usuario Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36, que lo identifica ante los servidores web. Los datos recopilados por Amazonbot pueden utilizarse para entrenar los modelos de inteligencia artificial de Amazon, lo que lo convierte en un componente crucial de la infraestructura de IA de Amazon y de su estrategia de desarrollo de productos.
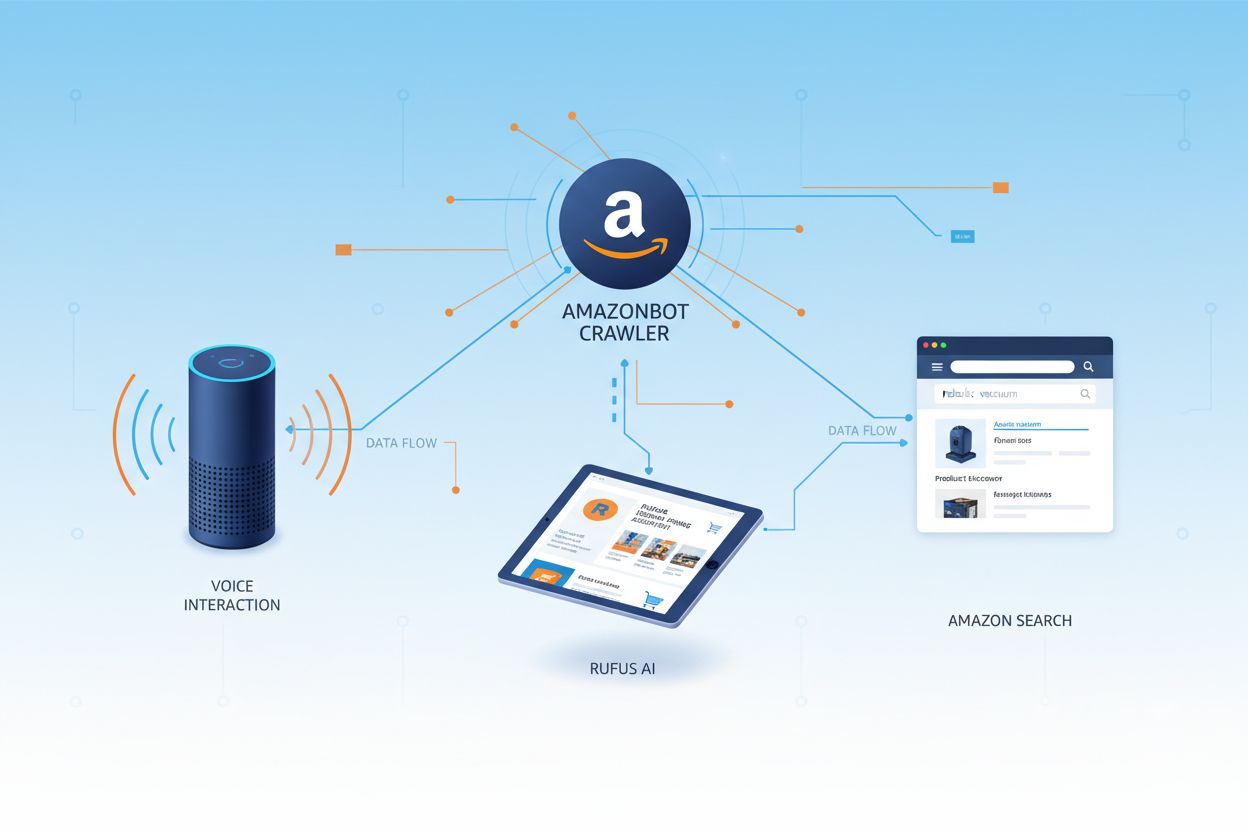
Amazon opera tres rastreadores web distintos, cada uno con propósitos específicos dentro de su ecosistema. Amazonbot es el rastreador principal utilizado para la mejora general de productos y servicios, y puede emplearse para entrenamiento de modelos de IA. Amzn-SearchBot está diseñado específicamente para mejorar las experiencias de búsqueda en productos de Amazon como Alexa y Rufus, pero, de manera importante, NO rastrea contenido para entrenamiento de modelos generativos de IA. Amzn-User respalda acciones iniciadas por el usuario, como obtener información en tiempo real cuando los clientes hacen preguntas a Alexa que requieren datos web actualizados, y tampoco rastrea para fines de entrenamiento de IA. Los tres rastreadores respetan el Protocolo de Exclusión de Robots y obedecen directivas en robots.txt, lo que permite a los propietarios de sitios web controlar su acceso. Amazon publica las direcciones IP de cada rastreador en su portal para desarrolladores, permitiendo a los propietarios de sitios verificar el tráfico legítimo. Además, todos los rastreadores de Amazon respetan las directivas a nivel de enlace rel=nofollow y las metaetiquetas robots a nivel de página, incluyendo noarchive (impide el uso para entrenamiento de modelos), noindex (impide la indexación) y none (impide ambos).
| Nombre del Rastreador | Propósito Principal | Entrenamiento de IA | Agente de Usuario | Casos de Uso Clave |
|---|---|---|---|---|
| Amazonbot | Mejora general de productos/servicios | Sí | Amazonbot/0.1 | Mejora general de servicios de Amazon, entrenamiento de IA |
| Amzn-SearchBot | Mejora de experiencia de búsqueda | No | Amzn-SearchBot/0.1 | Búsqueda en Alexa, indexación del asistente de compras Rufus |
| Amzn-User | Obtención de datos en vivo iniciada por el usuario | No | Amzn-User/0.1 | Consultas en tiempo real de Alexa, solicitudes de información actual |
Amazon respeta el Protocolo de Exclusión de Robots estándar de la industria (RFC 9309), lo que significa que los propietarios de sitios web pueden controlar el acceso de Amazonbot mediante el archivo robots.txt. Amazon obtiene los archivos robots.txt a nivel de host desde la raíz de tu dominio (por ejemplo, example.com/robots.txt) y utilizará una copia en caché de los últimos 30 días si no puede obtener el archivo. Los cambios en tu archivo robots.txt normalmente se reflejan en los sistemas de Amazon tras unas 24 horas. El protocolo admite las directivas estándar de user-agent y allow/disallow, permitiendo un control granular sobre qué rastreadores pueden acceder a directorios o archivos específicos. Sin embargo, es importante notar que los rastreadores de Amazon NO admiten la directiva crawl-delay, por lo que este parámetro será ignorado si se incluye en el archivo robots.txt.
Aquí tienes un ejemplo de cómo controlar el acceso de Amazonbot:
# Bloquear Amazonbot para que no rastree todo tu sitio
User-agent: Amazonbot
Disallow: /
# Permitir Amzn-SearchBot para visibilidad en búsquedas
User-agent: Amzn-SearchBot
Allow: /
# Bloquear un directorio específico para Amazonbot
User-agent: Amazonbot
Disallow: /private/
# Permitir todos los demás rastreadores
User-agent: *
Disallow: /admin/
Los propietarios de sitios web preocupados por el tráfico de bots deben verificar que los rastreadores que dicen ser Amazonbot sean realmente rastreadores legítimos de Amazon. Amazon proporciona un proceso de verificación usando búsquedas DNS para confirmar el tráfico auténtico de Amazonbot. Para verificar la legitimidad de un rastreador, primero localiza la dirección IP de acceso en los registros de tu servidor, luego realiza una búsqueda inversa de DNS en esa IP usando el comando host. El nombre de dominio obtenido debe ser un subdominio de crawl.amazonbot.amazon. Después, realiza una búsqueda directa de DNS en el nombre de dominio obtenido para verificar que resuelva en la IP original. Este proceso de verificación bidireccional ayuda a prevenir ataques de suplantación, ya que actores maliciosos podrían modificar los registros DNS inversos para hacerse pasar por Amazonbot. Amazon publica las direcciones IP verificadas de todos sus rastreadores en el portal de desarrolladores en developer.amazon.com/amazonbot/ip-addresses/, proporcionando un punto de referencia adicional para la verificación.
Ejemplo de proceso de verificación:
$ host 12.34.56.789
789.56.34.12.in-addr.arpa domain name pointer 12-34-56-789.crawl.amazonbot.amazon.
$ host 12-34-56-789.crawl.amazonbot.amazon
12-34-56-789.crawl.amazonbot.amazon has address 12.34.56.789
Si tienes preguntas sobre Amazonbot o necesitas reportar actividad sospechosa, contacta directamente con Amazon a través de amazonbot@amazon.com e incluye los nombres de dominio relevantes en tu mensaje.
Existe una distinción crítica entre los rastreadores de Amazon respecto al entrenamiento de modelos de IA. Amazonbot puede utilizarse para entrenar los modelos de inteligencia artificial de Amazon, por lo que es relevante para los creadores de contenido preocupados por el uso de su trabajo en el entrenamiento de IA. Por el contrario, Amzn-SearchBot y Amzn-User explícitamente NO rastrean contenido para entrenamiento de modelos generativos de IA, enfocándose únicamente en mejorar las experiencias de búsqueda y en respaldar las consultas de los usuarios. Si deseas evitar que tu contenido se utilice para el entrenamiento de modelos de IA, puedes usar la metaetiqueta robots noarchive en el encabezado HTML de tu página, que indica a Amazonbot que no utilice la página con fines de entrenamiento de modelos. Esta distinción es importante para editores, creadores y propietarios de sitios web que desean mantener el control sobre cómo se utiliza su contenido en la cadena de entrenamiento de IA, mientras permiten que su contenido aparezca en los resultados de búsqueda de Amazon y en las recomendaciones de Rufus.
Rufus es el avanzado asistente de compras con IA de Amazon que aprovecha la tecnología de rastreo web e inteligencia artificial para proporcionar recomendaciones y asistencia de compra personalizadas. Mientras Amazonbot contribuye a la infraestructura general de IA de Amazon, Rufus utiliza específicamente Amzn-SearchBot para indexar información de productos y contenido web relevante para consultas de compras. Rufus está construido sobre Amazon Bedrock y utiliza modelos de lenguaje avanzados como Claude Sonnet de Anthropic y Amazon Nova, combinados con un modelo personalizado entrenado en el extenso catálogo de productos de Amazon, opiniones de clientes, preguntas y respuestas de la comunidad e información web. El asistente de compras ayuda a los clientes a investigar productos, comparar opciones, seguir precios, encontrar ofertas e incluso realizar compras automáticas cuando los precios alcanzan el objetivo deseado. Desde su lanzamiento, Rufus se ha vuelto sumamente popular, con más de 250 millones de clientes utilizándolo, usuarios activos mensuales creciendo un 149% e interacciones aumentando un 210% interanual. Los clientes que usan Rufus durante sus compras tienen más de un 60% de probabilidad de realizar una compra durante esa sesión, lo que demuestra el enorme impacto de la asistencia de compras basada en IA en el comportamiento del consumidor.
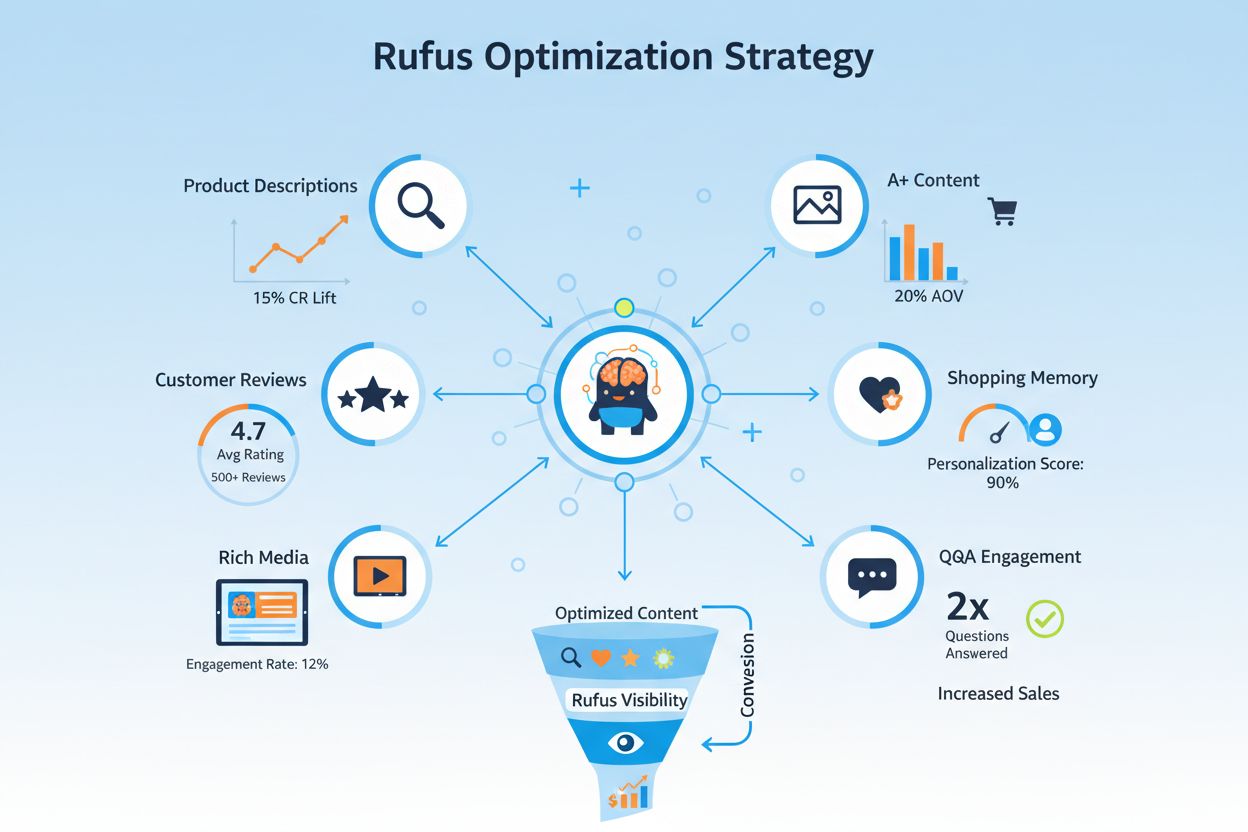
Los propietarios de sitios web deben desarrollar un enfoque estratégico para gestionar los rastreadores de Amazon según sus objetivos comerciales y políticas de contenido:
noarchive o bloquéalo completamente vía robots.txtamazonbot@amazon.com proporcionando información de tu dominio para obtener asesoría personalizada si tienes inquietudes o preguntas específicas sobre cómo los rastreadores de Amazon interactúan con tu sitioAmazonbot es el rastreador de propósito general de Amazon utilizado para mejorar productos y servicios, y puede emplearse para el entrenamiento de modelos de IA. Amzn-SearchBot está diseñado específicamente para experiencias de búsqueda en Alexa y Rufus, y explícitamente NO rastrea para entrenamiento de modelos de IA. Si deseas evitar el uso para entrenamiento de IA, bloquea Amazonbot pero permite Amzn-SearchBot para visibilidad en búsquedas.
Agrega las siguientes líneas a tu archivo robots.txt en la raíz de tu dominio: User-agent: Amazonbot seguido de Disallow: /. Esto evitará que Amazonbot rastree todo tu sitio. También puedes usar Disallow: /ruta-específica/ para bloquear solo ciertos directorios.
Sí, Amazonbot puede usarse para entrenar los modelos de inteligencia artificial de Amazon. Si deseas evitar esto, utiliza la metaetiqueta robots en el encabezado HTML de tu página, lo que indica a Amazonbot que no utilice la página para entrenamiento de modelos.
Realiza una búsqueda inversa de DNS en la dirección IP del rastreador y verifica que el dominio sea un subdominio de crawl.amazonbot.amazon. Luego realiza una búsqueda directa de DNS para confirmar que el dominio resuelve en la IP original. También puedes consultar las direcciones IP publicadas por Amazon en developer.amazon.com/amazonbot/ip-addresses/.
Utiliza la sintaxis estándar de robots.txt: User-agent: Amazonbot para dirigir la regla al rastreador, seguido de Disallow: / para bloquear todo el acceso o Disallow: /ruta/ para bloquear directorios específicos. También puedes usar Allow: / para permitir explícitamente el acceso.
Normalmente, Amazon refleja los cambios en robots.txt en aproximadamente 24 horas. Amazon obtiene tu archivo robots.txt de forma regular y mantiene una copia en caché durante hasta 30 días, por lo que los cambios pueden tardar un día completo en propagarse por sus sistemas.
Sí, absolutamente. Puedes crear reglas separadas para cada rastreador en tu archivo robots.txt. Por ejemplo, permite Amzn-SearchBot con User-agent: Amzn-SearchBot y Allow: /, mientras bloqueas Amazonbot con User-agent: Amazonbot y Disallow: /.
Contacta directamente con Amazon en amazonbot@amazon.com. Siempre incluye tu nombre de dominio y detalles relevantes sobre tu consulta en el mensaje. El equipo de soporte de Amazon puede brindarte orientación personalizada para tu situación específica.
Haz seguimiento de las menciones de tu marca en sistemas de IA como Alexa, Rufus y Google AI Overviews con AmICited: la plataforma líder de monitoreo de respuestas de IA.
Guía completa sobre el rastreador PerplexityBot: entiende cómo funciona, gestiona el acceso, monitorea citas y optimiza para la visibilidad en Perplexity AI. Ap...
Domina las estrategias de optimización para Amazon Rufus y aumenta la visibilidad de tus productos en el asistente de compras con IA de Amazon. Aprende cómo opt...

Descubre qué es PerplexityBot, el rastreador web de Perplexity que indexa contenido para su motor de respuestas de IA. Comprende cómo funciona, su cumplimiento ...