Definición de Mecanismo de Atención
El mecanismo de atención es una técnica de aprendizaje automático que dirige a los modelos de aprendizaje profundo para priorizar (o “atender a”) las partes más relevantes de los datos de entrada al hacer predicciones. En lugar de tratar todos los elementos de entrada por igual, los mecanismos de atención calculan pesos de atención que reflejan la importancia relativa de cada elemento para la tarea en cuestión, y luego aplican esos pesos para enfatizar o desestimar dinámicamente entradas específicas. Esta innovación fundamental se ha convertido en la piedra angular de las arquitecturas transformadoras modernas y de los grandes modelos de lenguaje (LLMs) como ChatGPT, Claude y Perplexity, permitiéndoles procesar datos secuenciales con una eficiencia y precisión sin precedentes. El mecanismo se inspira en la atención cognitiva humana: la capacidad de enfocarse selectivamente en detalles sobresalientes mientras se filtra la información irrelevante, y traduce este principio biológico en un componente de red neuronal matemáticamente riguroso y entrenable.
Contexto Histórico y Evolución
El concepto de mecanismos de atención fue introducido por primera vez por Bahdanau y colegas en 2014 para abordar limitaciones críticas en las redes neuronales recurrentes (RNNs) usadas para traducción automática. Antes de la atención, los modelos Seq2Seq dependían de un solo vector de contexto para codificar oraciones fuente completas, creando un cuello de botella informativo que limitaba severamente el desempeño en secuencias largas. El mecanismo de atención original permitió que el decodificador accediera a todos los estados ocultos del codificador en lugar de solo al final, seleccionando dinámicamente qué partes de la entrada eran más relevantes en cada paso de decodificación. Este avance mejoró drásticamente la calidad de la traducción, especialmente en oraciones largas. En 2015, Luong y colegas introdujeron la atención por producto punto, que reemplazó la costosa atención aditiva por una multiplicación matricial eficiente. El momento decisivo llegó en 2017 con la publicación de “Attention is All You Need”, que introdujo la arquitectura transformadora que prescindió completamente de la recurrencia en favor de mecanismos de atención puros. Este artículo revolucionó el aprendizaje profundo, permitiendo el desarrollo de BERT, modelos GPT y todo el ecosistema moderno de IA generativa. Hoy en día, los mecanismos de atención son omnipresentes en el procesamiento de lenguaje natural, visión por computadora y sistemas de IA multimodales, con más del 85% de los modelos de última generación incorporando algún tipo de arquitectura basada en atención.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Arquitectura Técnica y Componentes
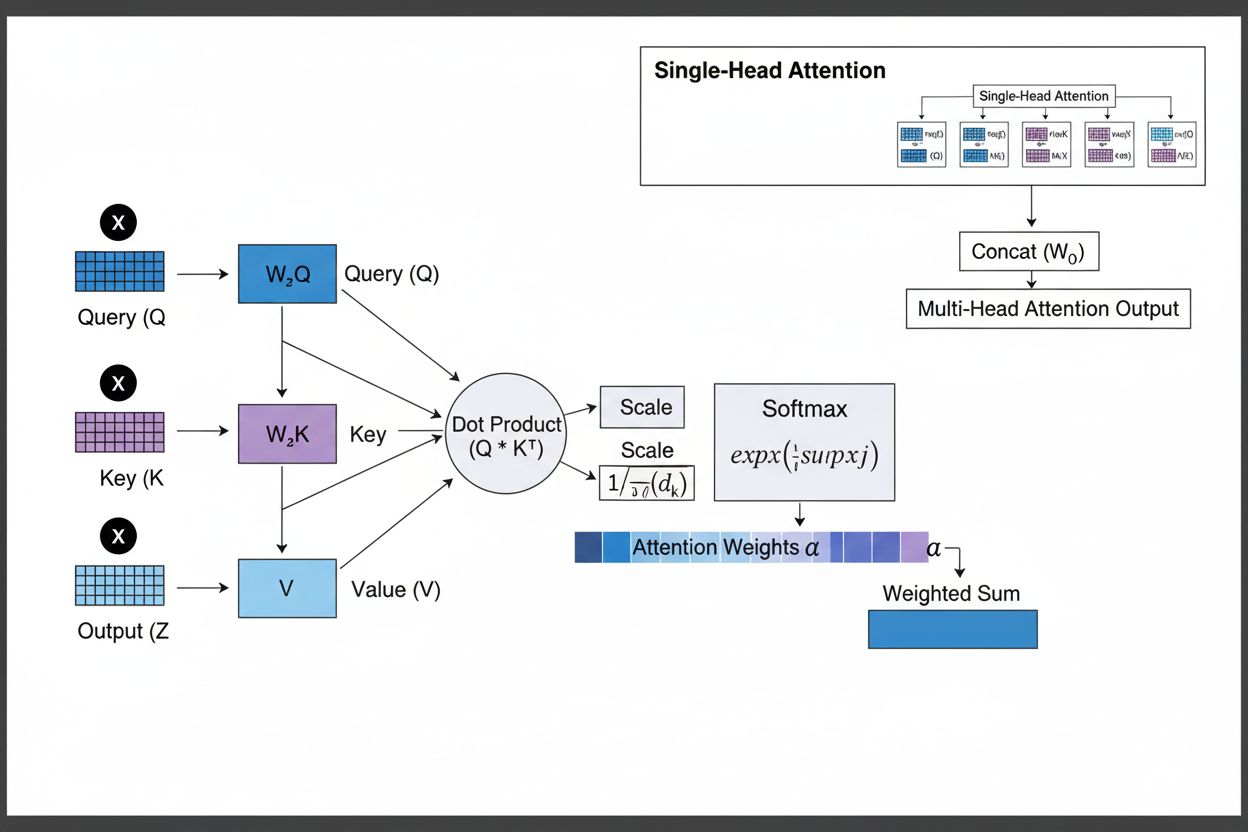
El mecanismo de atención opera mediante una sofisticada interacción de tres componentes matemáticos fundamentales: consultas (Q), claves (K) y valores (V). Cada elemento de entrada se transforma en estas tres representaciones mediante proyecciones lineales aprendidas, creando una estructura similar a una base de datos relacional donde las claves son identificadores y los valores contienen la información real. El mecanismo calcula puntajes de alineación midiendo la similitud entre una consulta y todas las claves, normalmente usando atención escalada por producto punto donde la puntuación se calcula como QK^T/√d_k. Estas puntuaciones brutas se normalizan usando la función softmax, que las convierte en una distribución de probabilidad donde todos los pesos suman 1, asegurando que cada elemento reciba un peso entre 0 y 1. El paso final consiste en calcular una suma ponderada de los vectores de valor usando estos pesos de atención, produciendo un vector de contexto que representa la información más relevante de toda la secuencia de entrada. Este vector de contexto se combina luego con la entrada original mediante conexiones residuales y se pasa por capas feedforward, permitiendo que el modelo refine iterativamente su comprensión de la entrada. La elegancia matemática de este diseño—combinando transformaciones aprendibles, cálculos de similitud y ponderación probabilística—permite a los mecanismos de atención capturar dependencias complejas mientras permanecen completamente diferenciables para la optimización por gradiente.
Comparación de Variantes de Mecanismo de Atención
| Tipo de Atención | Método de Cálculo | Complejidad Computacional | Mejor Caso de Uso | Ventaja Clave |
|---|
| Atención Aditiva | Red feed-forward + activación tanh | O(n·d) por consulta | Secuencias cortas, dimensiones variables | Maneja diferentes dimensiones de consulta/clave |
| Atención por Producto Punto | Multiplicación matricial simple | O(n·d) por consulta | Secuencias estándar | Computacionalmente eficiente |
| Producto Punto Escalado | QK^T/√d_k + softmax | O(n·d) por consulta | Transformadores modernos | Previene gradientes que desaparecen |
| Atención Multi-Cabeza | Varias cabezas de atención en paralelo | O(h·n·d) donde h=cabezas | Relaciones complejas | Captura aspectos semánticos diversos |
| Self-Attention | Consultas, claves y valores de la misma secuencia | O(n²·d) | Relaciones intra-secuencia | Permite procesamiento en paralelo |
| Cross-Attention | Consultas de una secuencia, claves/valores de otra | O(n·m·d) | Encoder-decoder, multimodal | Alinea diferentes modalidades |
| Atención de Consulta Agrupada | Comparte claves/valores entre cabezas de consulta | O(n·d) | Inferencia eficiente | Reduce memoria y computación |
| Atención Dispersa | Atención limitada a posiciones locales/estridadas | O(n·√n·d) | Secuencias muy largas | Maneja secuencias extremadamente largas |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Cómo Funcionan los Mecanismos de Atención en la Práctica
El mecanismo de atención opera mediante una secuencia cuidadosamente orquestada de transformaciones matemáticas que permiten a las redes neuronales enfocarse dinámicamente en información relevante. Al procesar una secuencia de entrada, cada elemento se incrusta primero en un espacio vectorial de alta dimensión, capturando información semántica y sintáctica. Estas incrustaciones se proyectan en tres espacios separados usando matrices de pesos aprendidas: el espacio de consulta (representa lo que se busca), el espacio de clave (representa la información que contiene cada elemento) y el espacio de valor (contiene la información real a agregar). Para cada posición de consulta, el mecanismo calcula una puntuación de similitud con cada clave tomando su producto punto, produciendo un vector de puntuaciones de alineación brutas. Estas puntuaciones se escalan dividiendo por la raíz cuadrada de la dimensión de la clave (√d_k), un paso crítico que evita que los productos punto sean demasiado grandes en dimensiones altas, lo que haría desaparecer los gradientes durante la retropropagación. Las puntuaciones escaladas se pasan luego a través de una función softmax, que las exponencia y normaliza para que sumen 1, creando una distribución de probabilidad sobre todas las posiciones de entrada. Finalmente, estos pesos de atención se usan para calcular un promedio ponderado de los vectores de valor, donde las posiciones con mayor peso de atención contribuyen más fuertemente al vector de contexto final. Este vector de contexto se combina luego con la entrada original mediante conexiones residuales y se procesa a través de capas feedforward, permitiendo que el modelo refine iterativamente sus representaciones. Todo el proceso es diferenciable, permitiendo que el modelo aprenda patrones de atención óptimos mediante descenso de gradiente durante el entrenamiento.
Los mecanismos de atención son el bloque fundamental de las arquitecturas transformadoras, que se han convertido en el paradigma dominante en aprendizaje profundo. A diferencia de las RNNs que procesan secuencias de manera secuencial y de las CNNs que operan sobre ventanas locales fijas, los transformadores usan la self-attention para permitir que cada posición atienda directamente a todas las demás posiciones simultáneamente, permitiendo una paralelización masiva en GPUs y TPUs. La arquitectura transformadora consiste en capas alternas de self-attention multi-cabeza y redes feedforward, donde cada capa de atención permite al modelo refinar su comprensión de la entrada al enfocarse selectivamente en diferentes aspectos. La atención multi-cabeza ejecuta múltiples mecanismos de atención en paralelo, donde cada cabeza aprende a enfocarse en diferentes tipos de relaciones: una cabeza puede especializarse en dependencias gramaticales, otra en relaciones semánticas y una tercera en coreferencia a larga distancia. Las salidas de todas las cabezas se concatenan y proyectan, permitiendo que el modelo mantenga conciencia de múltiples fenómenos lingüísticos simultáneamente. Esta arquitectura ha demostrado ser notablemente efectiva para grandes modelos de lenguaje como GPT-4, Claude 3 y Gemini, que usan arquitecturas transformadoras solo de decodificador donde cada token solo puede atender a tokens previos (enmascaramiento causal) para mantener la propiedad de generación autoregresiva. La capacidad del mecanismo de atención para capturar dependencias a largo plazo sin los problemas de gradientes que desaparecen que aquejaban a las RNNs ha sido fundamental para permitir que estos modelos procesen ventanas de contexto de más de 100,000 tokens, manteniendo coherencia y consistencia en grandes volúmenes de texto. Las investigaciones muestran que aproximadamente el 92% de los modelos de NLP de última generación ahora dependen de arquitecturas transformadoras impulsadas por mecanismos de atención, demostrando su importancia fundamental en los sistemas de IA modernos.
Mecanismos de Atención en Búsqueda y Monitoreo por IA
En el contexto de plataformas de búsqueda por IA como ChatGPT, Perplexity, Claude y Google AI Overviews, los mecanismos de atención juegan un papel crucial para determinar qué partes de los documentos recuperados y bases de conocimiento son más relevantes para las consultas de los usuarios. Cuando estos sistemas generan respuestas, sus mecanismos de atención ponderan dinámicamente diferentes fuentes y pasajes según su relevancia, permitiéndoles sintetizar respuestas coherentes de múltiples fuentes mientras mantienen precisión factual. Los pesos de atención calculados durante la generación pueden analizarse para entender qué información priorizó el modelo, proporcionando información sobre cómo los sistemas de IA interpretan y responden a las consultas. Para el monitoreo de marca y la GEO (Optimización para Motores Generativos), comprender los mecanismos de atención es esencial porque determinan qué contenido y fuentes reciben énfasis en las respuestas generadas por IA. El contenido estructurado para alinearse con la forma en que los mecanismos de atención ponderan la información—mediante definiciones claras de entidades, fuentes autorizadas y relevancia contextual—tiene más probabilidades de ser citado y aparecer de manera destacada en las respuestas de IA. AmICited aprovecha los conocimientos sobre mecanismos de atención para rastrear cómo aparecen marcas y dominios en las plataformas de IA, reconociendo que las citas ponderadas por atención representan las menciones más influyentes en el contenido generado por IA. A medida que las empresas monitorean cada vez más su presencia en respuestas de IA, entender que los mecanismos de atención impulsan los patrones de citación se vuelve crítico para optimizar la estrategia de contenido y asegurar la visibilidad de la marca en la era de la IA generativa.
Aspectos Clave y Consideraciones de Implementación
- Eficiencia Computacional: La atención escalada por producto punto permite una complejidad de O(n²) con paralelización masiva, haciéndola práctica para secuencias de miles de tokens en GPUs modernas
- Flujo de Gradiente: El factor de escalado (1/√d_k) previene que los gradientes desaparezcan, permitiendo el entrenamiento estable de redes muy profundas con muchas capas de atención
- Interpretabilidad: Los pesos de atención proporcionan visualizaciones interpretables que muestran qué elementos de entrada influyeron en predicciones específicas, mejorando la transparencia del modelo
- Codificación Posicional: Los transformadores requieren información posicional explícita mediante codificaciones sinusoidales o rotatorias ya que la atención no preserva inherentemente el orden de la secuencia
- Enmascaramiento Causal: Los modelos autoregresivos como GPT utilizan enmascaramiento causal para evitar que los tokens atiendan a posiciones futuras, manteniendo la propiedad de generación
- Eficiencia de Memoria: Variantes como la atención de consulta agrupada y la atención dispersa reducen los requerimientos de memoria de O(n²) a O(n·√n) para secuencias muy largas
- Atención Multi-Escala: Diferentes cabezas de atención aprenden a enfocarse en diferentes escalas de contexto, desde relaciones locales de palabras hasta temas a nivel de documento
- Alineación Cruzada de Modalidades: La cross-attention permite que modelos como Stable Diffusion alineen indicaciones de texto con generación de imágenes y que modelos visión-lenguaje anclen el lenguaje en información visual
Evolución y Direcciones Futuras
El campo de los mecanismos de atención continúa evolucionando rápidamente, con investigadores desarrollando variantes cada vez más sofisticadas para abordar limitaciones computacionales y mejorar el rendimiento. Los patrones de atención dispersa limitan la atención a vecindarios locales o posiciones estridadas, reduciendo la complejidad de O(n²) a O(n·√n) mientras mantienen el rendimiento en secuencias muy largas. Mecanismos de atención eficiente como FlashAttention optimizan los patrones de acceso a memoria de la atención, logrando aceleraciones de 2-4x mediante un mejor uso de la GPU. La atención de consulta agrupada y la atención multi-consulta reducen la cantidad de cabezas de clave-valor manteniendo el rendimiento, disminuyendo significativamente los requerimientos de memoria durante la inferencia, una consideración crítica para desplegar modelos grandes en producción. Las arquitecturas Mixture of Experts combinan atención con ruteo disperso, permitiendo que los modelos escalen a billones de parámetros manteniendo la eficiencia computacional. La investigación emergente explora patrones de atención aprendidos que se adaptan dinámicamente según las características de entrada, y atención jerárquica que opera en múltiples niveles de abstracción. La integración de mecanismos de atención con generación aumentada por recuperación (RAG) permite que los modelos atiendan dinámicamente a conocimiento externo relevante, mejorando la factualidad y reduciendo alucinaciones. A medida que los sistemas de IA se despliegan cada vez más en aplicaciones críticas, los mecanismos de atención se están mejorando con características de explicabilidad que ofrecen una visión más clara sobre las decisiones del modelo. El futuro probablemente implique arquitecturas híbridas que combinen atención con mecanismos alternativos como modelos de espacio de estado (ejemplificados por Mamba), que ofrecen complejidad lineal manteniendo un rendimiento competitivo. Entender estos mecanismos de atención en evolución es esencial para los profesionales que construyen sistemas de IA de próxima generación y para las organizaciones que monitorean su presencia en contenido generado por IA, ya que los mecanismos que determinan los patrones de citación y la prominencia del contenido continúan avanzando.
Mecanismos de Atención y Patrones de Citación en IA
Para las organizaciones que usan AmICited para monitorear la visibilidad de su marca en respuestas de IA, comprender los mecanismos de atención proporciona un contexto crucial para interpretar los patrones de citación. Cuando ChatGPT, Claude o Perplexity citan tu dominio en sus respuestas, los pesos de atención calculados durante la generación determinaron que tu contenido era el más relevante para la consulta del usuario. El contenido de alta calidad y bien estructurado que define claramente entidades y proporciona información autorizada recibe naturalmente mayores pesos de atención, lo que lo hace más probable de ser seleccionado para citación. Las visualizaciones de atención en algunas plataformas de IA revelan qué fuentes recibieron mayor enfoque durante la generación de la respuesta, mostrando efectivamente qué citas fueron más influyentes. Este conocimiento permite a las organizaciones optimizar su estrategia de contenido entendiendo que los mecanismos de atención recompensan la claridad, relevancia y fuentes autorizadas. A medida que la búsqueda por IA crece—con más del 60% de las empresas invirtiendo ahora en iniciativas de IA generativa—la capacidad de entender y optimizar para los mecanismos de atención se vuelve cada vez más valiosa para mantener la visibilidad de la marca y asegurar una representación precisa en contenido generado por IA. La intersección entre mecanismos de atención y monitoreo de marca representa una frontera en la GEO, donde entender los fundamentos matemáticos de cómo los sistemas de IA ponderan y citan información se traduce directamente en mayor visibilidad e influencia en el ecosistema de IA generativa.