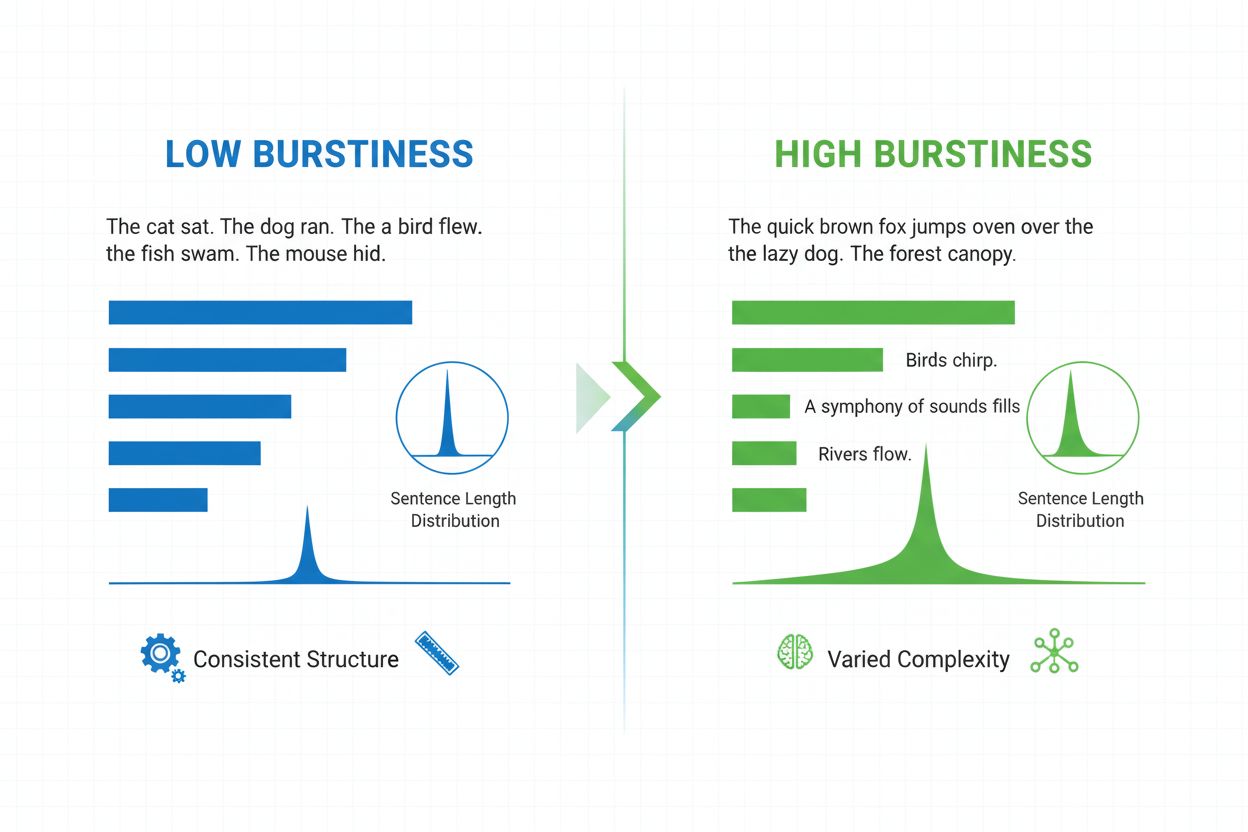
Definición de Burstiness
Burstiness es una métrica lingüística cuantificable que mide la variabilidad y fluctuación de la longitud, estructura y complejidad de las oraciones a lo largo de un documento o pasaje escrito. El término proviene del concepto de “ráfagas” de patrones de oraciones variables—alternando entre oraciones cortas y concisas y otras más largas e intrincadas. En el contexto del procesamiento de lenguaje natural y la detección de contenido por IA, burstiness sirve como un indicador crítico para determinar si un texto fue escrito por un humano o generado por un sistema de inteligencia artificial. Los escritores humanos producen naturalmente textos con alta burstiness porque varían instintivamente su construcción de oraciones según el énfasis, el ritmo y la intención estilística. Por el contrario, el texto generado por IA suele exhibir baja burstiness porque los modelos de lenguaje se entrenan en patrones estadísticos que favorecen la consistencia y la previsibilidad. Comprender la burstiness es esencial para creadores de contenido, educadores, investigadores y organizaciones que monitorean contenido generado por IA en plataformas como ChatGPT, Perplexity, Google AI Overviews y Claude.
Contexto Histórico y Desarrollo
El concepto de burstiness surgió de la investigación en lingüística computacional y teoría de la información, donde los científicos buscaron cuantificar las propiedades estadísticas del lenguaje natural. Los primeros trabajos en estilometría—el análisis estadístico del estilo de escritura—identificaron que la escritura humana exhibe patrones distintivos de variación que difieren fundamentalmente del texto generado por máquinas. A medida que los grandes modelos de lenguaje (LLM) se volvieron cada vez más sofisticados a inicios de la década de 2020, los investigadores reconocieron que la burstiness, combinada con la perplejidad (una medida de la previsibilidad de las palabras), podía servir como un indicador fiable de contenido generado por IA. Según investigaciones de QuillBot e instituciones académicas, aproximadamente el 78% de las empresas ahora utiliza herramientas de monitoreo de contenido impulsadas por IA que incorporan análisis de burstiness como parte de sus algoritmos de detección. El estudio de la Universidad de Stanford de 2023 sobre ensayos TOEFL demostró que los métodos de detección basados en burstiness, si bien son útiles, tienen limitaciones significativas—particularmente respecto a falsos positivos en la escritura de hablantes no nativos de inglés. Esta investigación ha impulsado el desarrollo de sistemas de detección de IA más sofisticados y multinivel que consideran la burstiness junto a otros marcadores lingüísticos, coherencia semántica y adecuación contextual.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Explicación Técnica de la Medición de Burstiness
La burstiness se calcula analizando la distribución estadística de la longitud de las oraciones y los patrones estructurales dentro de un texto. La métrica cuantifica la varianza—esencialmente mide cuánto se desvían las oraciones individuales de la longitud promedio de oración en un documento. Un documento con alta burstiness contiene oraciones que varían significativamente en longitud; por ejemplo, un escritor puede seguir una oración de tres palabras ("¿Ves?") con una oración de veinticinco palabras que incluya múltiples cláusulas y frases subordinadas. Por el contrario, la baja burstiness indica que la mayoría de las oraciones se agrupan alrededor de una longitud similar, típicamente entre doce y dieciocho palabras, creando un ritmo monótono. El cálculo implica varios pasos: primero, el sistema mide la longitud de cada oración en palabras; segundo, calcula la media (promedio) de la longitud de las oraciones; tercero, calcula la desviación estándar para determinar cuánto se desvían las oraciones individuales de esa media. Una desviación estándar mayor indica mayor variación y, por tanto, mayor burstiness. Los detectores de IA modernos como Winston AI y Pangram emplean algoritmos sofisticados que no solo cuentan palabras sino que también analizan la complejidad sintáctica—la disposición estructural de cláusulas, frases y elementos gramaticales. Este análisis profundo revela que los escritores humanos emplean estructuras de oraciones diversas (simples, compuestas, complejas y compuestas-complejas) en patrones impredecibles, mientras que los modelos de IA tienden a favorecer plantillas estructurales particulares que aparecen frecuentemente en sus datos de entrenamiento.
Burstiness vs. Perplejidad: Análisis Comparativo
| Métrica | Burstiness | Perplejidad | Enfoque de Medición |
|---|
| Definición | Variación en la longitud y estructura de las oraciones | Previsibilidad de palabras individuales | Nivel de oración vs. nivel de palabra |
| Escritura Humana | Alta (estructuras variadas) | Alta (palabras impredecibles) | Ritmo natural y vocabulario |
| Texto Generado por IA | Baja (estructuras uniformes) | Baja (palabras predecibles) | Consistencia estadística |
| Aplicación en Detección | Identifica monotonía estructural | Identifica patrones de elección de palabras | Métodos de detección complementarios |
| Riesgo de Falsos Positivos | Más alto para escritores ESL | Más alto para escritura técnica/ académica | Ambos tienen limitaciones |
| Método de Cálculo | Desviación estándar de la longitud de las oraciones | Análisis de distribución de probabilidades | Enfoques matemáticos diferentes |
| Fiabilidad por Sí Solo | Insuficiente para detección definitiva | Insuficiente para detección definitiva | Más efectivo cuando se combinan |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Cómo los Modelos de Lenguaje Generan Baja Burstiness
Los grandes modelos de lenguaje como ChatGPT, Claude y Google Gemini se entrenan mediante un proceso llamado predicción del siguiente token, donde el modelo aprende a predecir la palabra más estadísticamente probable que debe seguir una secuencia dada. Durante el entrenamiento, estos modelos se optimizan explícitamente para minimizar la perplejidad en sus conjuntos de datos de entrenamiento, lo que inadvertidamente genera baja burstiness como subproducto. Cuando un modelo encuentra repetidamente una estructura de oración particular en sus datos de entrenamiento, aprende a reproducir esa estructura con alta probabilidad, resultando en longitudes de oraciones consistentes y predecibles. Investigaciones de Netus AI y Winston AI revelan que los modelos de IA muestran una huella estilométrica distintiva caracterizada por construcción uniforme de oraciones, uso excesivo de frases de transición (como “Además”, “Por lo tanto”, “Adicionalmente”) y una preferencia por la voz pasiva sobre la activa. La dependencia de los modelos en distribuciones de probabilidad significa que gravitan hacia los patrones más comunes de sus datos de entrenamiento en lugar de explorar todo el espectro posible de construcciones oracionales. Esto crea una situación paradójica: cuanto más datos se utilizan para entrenar un modelo, más aprende a reproducir patrones comunes y, por tanto, menor es su burstiness. Además, los modelos de IA carecen de la espontaneidad y variación emocional que caracteriza la escritura humana—no escriben diferente cuando están emocionados, frustrados o enfatizando un punto particular. En su lugar, mantienen una línea base estilística consistente que refleja el centro estadístico de su distribución de entrenamiento.
Burstiness en los Sistemas de Detección de IA
Las plataformas de detección de IA han incorporado el análisis de burstiness como un componente central de sus algoritmos de detección, aunque con distintos niveles de sofisticación. Los sistemas de detección tempranos dependían mucho de la burstiness y la perplejidad como métricas principales, pero la investigación ha revelado limitaciones significativas en este enfoque. Según Pangram Labs, los detectores basados en perplejidad y burstiness producen falsos positivos al analizar textos de los conjuntos de entrenamiento de modelos de lenguaje—destacando que la Declaración de Independencia frecuentemente es señalada como generada por IA porque aparece tan a menudo en los datos de entrenamiento que el modelo le asigna una perplejidad uniformemente baja. Los sistemas modernos de detección como Winston AI y Pangram ahora emplean enfoques híbridos que combinan el análisis de burstiness con modelos de deep learning entrenados en muestras diversas de textos humanos y generados por IA. Estos sistemas analizan múltiples dimensiones lingüísticas simultáneamente: variación en la estructura de las oraciones, diversidad léxica (riqueza de vocabulario), patrones de puntuación, coherencia contextual y alineación semántica. La integración de burstiness en marcos de detección más amplios ha mejorado la precisión significativamente—Winston AI reporta un 99,98% de precisión al distinguir contenido generado por IA del escrito por humanos, analizando múltiples marcadores en vez de depender solo de la burstiness. Sin embargo, la métrica sigue siendo valiosa como un componente dentro de una estrategia de detección integral, especialmente al combinarse con el análisis de perplejidad, patrones estilométricos y consistencia semántica.
Aplicaciones Prácticas y Mejores Prácticas
- Creación de Contenido: Los escritores pueden variar intencionalmente la longitud y estructura de las oraciones para crear contenido más atractivo y humano que resuene con los lectores y evite que los sistemas de detección lo marquen como IA.
- Redacción Académica: Estudiantes e investigadores deben emplear construcciones oracionales diversas para demostrar habilidades de escritura sofisticadas y evitar falsos positivos de los sistemas de detección utilizados en instituciones educativas.
- SEO y Marketing de Contenidos: Los editores pueden mejorar la calidad del contenido y el posicionamiento en buscadores aumentando la burstiness, lo cual se correlaciona con mayores puntuaciones de legibilidad y mejores métricas de engagement del usuario.
- Monitoreo de Marcas: Las organizaciones que usan plataformas como AmICited pueden analizar los patrones de burstiness en respuestas generadas por IA para determinar si las menciones de su marca aparecen en contenido auténtico escrito por humanos o en texto generado por máquinas.
- Detección y Verificación de IA: Educadores, editores y moderadores de contenido pueden utilizar el análisis de burstiness como una de varias señales para identificar posibles envíos generados por IA y mantener estándares de autenticidad en el contenido.
- Mejora en la Escritura: Los autores pueden usar las métricas de burstiness como retroalimentación para refinar su estilo de escritura, asegurando que mantengan el engagement del lector mediante un ritmo natural y variedad en la construcción de oraciones.
- Aprendizaje de Idiomas: Los instructores de ESL pueden ayudar a los estudiantes a entender que desarrollar estructuras de oraciones variadas es una habilidad avanzada que contribuye a una escritura en inglés más natural y auténtica.
Burstiness y Métricas de Legibilidad
La relación entre burstiness y legibilidad está bien establecida en la investigación lingüística. Las puntuaciones Flesch Reading Ease y Flesch-Kincaid Grade Level, que miden la accesibilidad del texto, se correlacionan fuertemente con los patrones de burstiness. Un texto con mayor burstiness tiende a lograr mejores puntuaciones de legibilidad porque la variedad en la longitud de las oraciones previene la fatiga cognitiva y mantiene la atención del lector. Cuando los lectores encuentran un ritmo consistente de oraciones de tamaño similar, sus cerebros se adaptan a un patrón predecible, lo que puede llevar a la desconexión y a una menor comprensión. Por el contrario, una alta burstiness crea un efecto de flujo y reflujo que mantiene al lector mentalmente activo al variar la carga cognitiva—las oraciones cortas proporcionan información rápida y digerible, mientras que las largas permiten desarrollar ideas complejas y matices. Investigaciones de Metrics Masters indican que una alta burstiness genera aproximadamente un 15-20% más de retención de memoria en comparación con textos de baja burstiness, ya que el ritmo variado ayuda a codificar la información más efectivamente en la memoria a largo plazo. Este principio se aplica a todos los tipos de contenido: entradas de blogs, artículos académicos, textos de marketing y documentación técnica se benefician de la burstiness estratégica. Sin embargo, la relación no es lineal—una burstiness excesiva que antepone la variación a la claridad puede hacer que el texto sea entrecortado y difícil de seguir. El enfoque óptimo implica variación intencionada, donde las elecciones de estructura oracional sirven al significado del contenido y a la intención comunicativa del escritor, y no existen solo para aumentar una métrica.
Limitaciones y Críticas a la Detección Basada en Burstiness
A pesar de su adopción generalizada en sistemas de detección de IA, la detección basada en burstiness tiene limitaciones significativas que los investigadores y profesionales deben comprender. Pangram Labs publicó una investigación exhaustiva que detalla cinco principales deficiencias: en primer lugar, el texto proveniente de los conjuntos de entrenamiento de IA es clasificado erróneamente como generado por IA porque los modelos están optimizados para minimizar la perplejidad en los datos de entrenamiento; en segundo lugar, los valores de burstiness son relativos a modelos lingüísticos específicos, por lo que diferentes modelos producen distintos perfiles de perplejidad; en tercer lugar, los modelos comerciales de código cerrado como ChatGPT no exponen las probabilidades de tokens, lo que hace imposible calcular la perplejidad; en cuarto lugar, los hablantes no nativos de inglés son desproporcionadamente marcados como generados por IA debido a sus estructuras oracionales más uniformes; y en quinto lugar, los detectores basados en burstiness no pueden auto-mejorarse iterativamente con datos adicionales. El estudio de Stanford 2023 sobre ensayos TOEFL encontró que aproximadamente el 26% de la escritura de hablantes no nativos de inglés fue incorrectamente señalada como generada por IA por los detectores basados en perplejidad y burstiness, en comparación con solo un 2% de falsos positivos en textos de hablantes nativos. Este sesgo plantea serios problemas éticos en entornos educativos donde se utiliza la detección de IA para evaluar el trabajo de los estudiantes. Además, el contenido basado en plantillas en marketing, escritura académica y documentación técnica naturalmente exhibe burstiness baja debido a los requisitos de estilo y convenciones estructurales, lo que lleva a falsos positivos en estos ámbitos. Estas limitaciones han impulsado el desarrollo de enfoques de detección más sofisticados que consideran la burstiness como una señal entre muchas, en lugar de un indicador definitivo de generación por IA.
Burstiness en Diferentes Contextos de Escritura
Los patrones de burstiness varían considerablemente entre diferentes géneros y contextos de escritura, reflejando los distintos propósitos comunicativos y las expectativas de la audiencia en cada dominio. La escritura académica, especialmente en áreas STEM, tiende a mostrar menor burstiness porque los autores siguen guías de estilo estrictas y emplean plantillas estructurales consistentes para lograr claridad y precisión. Documentos legales, especificaciones técnicas y artículos científicos priorizan la consistencia y la previsibilidad sobre la variación estilística, resultando en puntuaciones de burstiness naturalmente más bajas. Por el contrario, la escritura creativa, el periodismo y el copy de marketing suelen demostrar alta burstiness porque estos géneros priorizan el engagement del lector y el impacto emocional mediante el ritmo y la variedad en la redacción. La ficción literaria, en particular, emplea cambios dramáticos en la longitud de las oraciones para crear énfasis, construir tensión y controlar el ritmo narrativo. La comunicación empresarial ocupa un punto intermedio—emails profesionales e informes mantienen una burstiness moderada para equilibrar claridad y engagement. La métrica Flesch-Kincaid Grade Level revela que la escritura académica destinada a públicos universitarios suele emplear oraciones más largas y complejas, lo que podría parecer que reduce la burstiness; sin embargo, la variación en la estructura de cláusulas y patrones de subordinación aún crea burstiness significativa. Comprender estas variaciones contextuales es crucial para los sistemas de detección de IA, ya que deben considerar las convenciones de escritura específicas de cada género para evitar falsos positivos. Un manual técnico con oraciones uniformemente largas no debe ser marcado como generado por IA solo porque exhiba baja burstiness—la baja burstiness refleja elecciones estilísticas apropiadas para el género, no evidencia de generación automática.
Evolución Futura e Implicaciones Estratégicas
El futuro del análisis de burstiness en la detección de IA avanza hacia enfoques más sofisticados y conscientes del contexto, que reconocen las limitaciones de la métrica y aprovechan sus aportes. A medida que los grandes modelos de lenguaje se vuelven más avanzados, comienzan a incorporar variación en la burstiness en sus salidas, haciendo que la detección basada solo en esta métrica sea menos fiable. Los investigadores están desarrollando sistemas de detección adaptativos que analizan la burstiness junto con coherencia semántica, precisión factual y adecuación contextual. El surgimiento de herramientas de humanización de IA que incrementan deliberadamente la burstiness y otras características humanas representa una carrera armamentista continua entre la detección y la evasión tecnológica. Sin embargo, los expertos predicen que la detección de IA realmente confiable dependerá finalmente de métodos de verificación criptográfica y seguimiento de procedencia más que de análisis lingüístico exclusivamente. Para creadores de contenido y organizaciones, la implicación estratégica es clara: en vez de ver la burstiness como una métrica para manipular o explotar, los escritores deberían enfocarse en desarrollar estilos de escritura auténticos y variados que reflejen naturalmente los patrones comunicativos humanos. La plataforma de monitoreo de AmICited representa una nueva frontera en este ámbito, rastreando cómo aparecen las marcas en respuestas generadas por IA y analizando las características lingüísticas de esas apariciones. A medida que los sistemas de IA se vuelven más prevalentes en la generación y distribución de contenido, comprender la burstiness y métricas relacionadas cobra mayor importancia para mantener la autenticidad de marca, garantizar la integridad académica y preservar la distinción entre contenido escrito por humanos y generado por máquinas. La evolución hacia enfoques de detección multisignales sugiere que la burstiness seguirá siendo relevante como un componente dentro de los sistemas integrales de monitoreo de IA, aunque su papel será cada vez más matizado y dependiente del contexto.