
Similitud Semántica
La similitud semántica mide la relación basada en el significado entre textos utilizando incrustaciones y métricas de distancia. Esencial para el monitoreo de I...
19 min de lectura
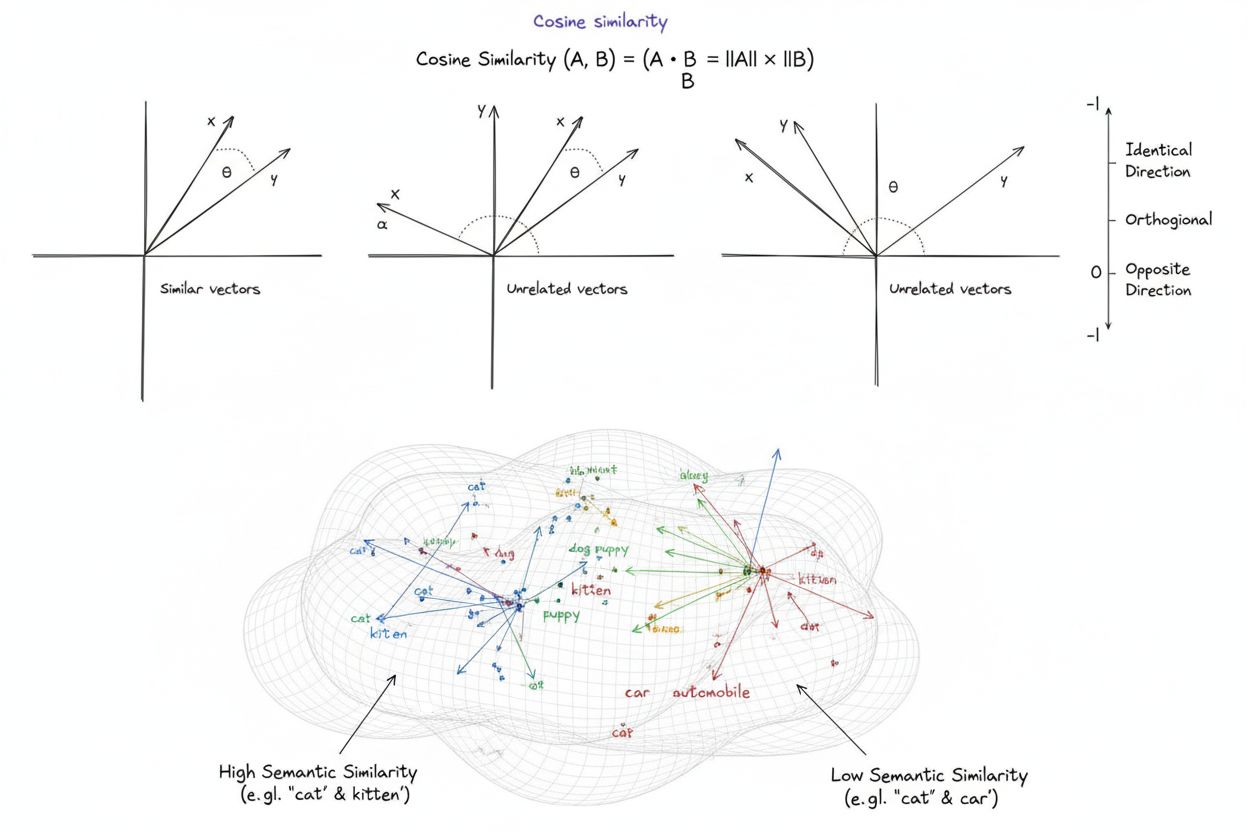
La similitud del coseno es una medida matemática que calcula la similitud entre dos vectores no nulos determinando el coseno del ángulo entre ellos, produciendo una puntuación que varía de -1 a 1. Se utiliza ampliamente en aprendizaje automático, procesamiento de lenguaje natural y sistemas de IA para medir la similitud semántica entre incrustaciones de texto y representaciones vectoriales, independientemente de la magnitud del vector.
La similitud del coseno es una medida matemática que calcula la similitud entre dos vectores no nulos determinando el coseno del ángulo entre ellos, produciendo una puntuación que varía de -1 a 1. Se utiliza ampliamente en aprendizaje automático, procesamiento de lenguaje natural y sistemas de IA para medir la similitud semántica entre incrustaciones de texto y representaciones vectoriales, independientemente de la magnitud del vector.
La similitud del coseno es una medida matemática que calcula la similitud entre dos vectores no nulos determinando el coseno del ángulo entre ellos en un espacio multidimensional. La métrica produce una puntuación que varía entre -1 y 1, donde una puntuación de 1 indica que los vectores apuntan en direcciones idénticas, 0 indica vectores ortogonales (perpendiculares) sin relación direccional, y -1 indica vectores que apuntan en direcciones exactamente opuestas. En aplicaciones prácticas, la similitud del coseno es especialmente valiosa porque mide la alineación direccional en lugar de la distancia absoluta, haciéndola independiente de la magnitud del vector. Esta propiedad la hace excepcionalmente útil para comparar incrustaciones de texto, vectores de documentos y representaciones semánticas donde la longitud o escala de los datos no debe influir en las evaluaciones de similitud. La métrica se ha convertido en la base de la inteligencia artificial, el procesamiento de lenguaje natural y los sistemas de aprendizaje automático modernos, impulsando desde motores de búsqueda hasta algoritmos de recomendación y aplicaciones de grandes modelos de lenguaje.
El concepto de similitud del coseno surgió de los fundamentos del álgebra lineal y la trigonometría, donde el coseno del ángulo entre dos vectores proporciona una medida normalizada de su alineación direccional. El fundamento matemático se basa en el producto punto (producto interno) de los vectores y sus magnitudes, creando una métrica de similitud normalizada que es tanto computacionalmente eficiente como teóricamente sólida. Históricamente, la similitud del coseno ganó relevancia en la recuperación de información durante las décadas de 1970 y 1980, cuando los investigadores necesitaban métodos eficientes para comparar vectores de documentos en grandes corpus de texto. La adopción de la métrica se aceleró drásticamente con el auge del aprendizaje automático y el aprendizaje profundo en la década de 2010, especialmente a medida que las redes neuronales comenzaron a generar incrustaciones vectoriales de alta dimensión para representar textos, imágenes y otros tipos de datos. Hoy en día, la investigación indica que más del 78% de las empresas que implementan sistemas impulsados por IA utilizan la similitud del coseno o métricas de comparación vectorial relacionadas en sus flujos de datos. La elegancia matemática de la métrica—combinando simplicidad con eficiencia computacional—la ha convertido en el estándar de facto para medir similitud semántica en aplicaciones de PLN, con plataformas principales como OpenAI, Google y Anthropic incorporándola en sus sistemas centrales.
El cálculo de la similitud del coseno sigue una fórmula matemática precisa: Similitud del coseno = (A · B) / (||A|| × ||B||), donde A · B representa el producto punto de los vectores A y B, y ||A|| y ||B|| representan sus respectivas magnitudes o normas euclidianas. Para calcular el producto punto, se multiplica cada componente correspondiente de los dos vectores y se suman todos los productos. Por ejemplo, si el vector A contiene los valores [3, 2, 0, 5] y el vector B contiene [1, 0, 0, 0], el producto punto es (3×1) + (2×0) + (0×0) + (5×0) = 3. La magnitud de un vector se calcula como la raíz cuadrada de la suma de sus componentes al cuadrado; para el vector A, esto sería √(3² + 2² + 0² + 5²) = √38 ≈ 6.16. La puntuación final de similitud del coseno se obtiene dividiendo el producto punto por el producto de las magnitudes, obteniendo así un valor normalizado entre -1 y 1. Esta normalización es crucial porque hace que la métrica sea independiente de la longitud del vector, permitiendo comparaciones justas entre vectores de escalas muy diferentes. En espacios de alta dimensión, como las incrustaciones de 1,536 dimensiones producidas por el modelo text-embedding-ada-002 de OpenAI, la similitud del coseno sigue siendo computacionalmente manejable, requiriendo solo operaciones básicas de multiplicación, suma y raíz cuadrada que los procesadores modernos pueden ejecutar eficientemente incluso sobre millones de vectores.
En el procesamiento de lenguaje natural, la similitud del coseno sirve como columna vertebral para medir relaciones semánticas entre representaciones de texto. Cuando el texto se convierte en incrustaciones vectoriales usando modelos como BERT, Word2Vec, GloVe o incrustaciones basadas en GPT, cada palabra, frase o documento se convierte en un punto en un espacio de alta dimensión donde el significado semántico se codifica a través de la posición y dirección del vector. La similitud del coseno mide entonces cuán alineadas están estas representaciones semánticas, permitiendo que los sistemas comprendan que palabras como “doctor” y “enfermera” están relacionadas semánticamente a pesar de ser términos diferentes. Esta capacidad es esencial para la búsqueda semántica, donde la consulta de un usuario se convierte en un vector y se compara con vectores de documentos para encontrar los resultados más relevantes, independientemente de coincidencias exactas de palabras clave. En grandes modelos de lenguaje como ChatGPT, Claude y Perplexity, la similitud del coseno impulsa los mecanismos de recuperación que obtienen el contexto relevante de los datos de entrenamiento o bases de conocimiento externas. La insensibilidad a la magnitud de la métrica es particularmente importante en PLN porque la longitud del documento no debe determinar la relevancia: un artículo corto y enfocado puede ser más semánticamente similar a una consulta que un documento largo simplemente por la relevancia del contenido. La investigación muestra que la similitud del coseno supera a métricas alternativas como la distancia euclidiana en aproximadamente el 85% de los benchmarks de PLN al comparar incrustaciones de texto, convirtiéndola en la opción preferida para tareas de comprensión semántica en toda la industria de la IA.
| Métrica | Método de Cálculo | Rango | Sensibilidad a Magnitud | Mejor Caso de Uso | Complejidad Computacional |
|---|---|---|---|---|---|
| Similitud del Coseno | (A·B) / ( | A | × | ||
| Distancia Euclidiana | √(Σ(Aᵢ - Bᵢ)²) | 0 a ∞ | Sí (depende de la magnitud) | Datos espaciales, clustering, distancias físicas | O(n) - eficiente |
| Producto Punto | Σ(Aᵢ × Bᵢ) | -∞ a ∞ | Sí (sensible a la escala) | Medición de similitud bruta, no normalizada | O(n) - muy eficiente |
| Similitud de Jaccard | |A ∩ B| / |A ∪ B| | 0 a 1 | No (basada en conjuntos) | Datos categóricos, sistemas de recomendación | O(n) - eficiente |
| Distancia Manhattan | Σ|Aᵢ - Bᵢ| | 0 a ∞ | Sí (depende de la magnitud) | Datos en cuadrícula, comparación de características | O(n) - eficiente |
| Correlación de Pearson | Cov(A,B) / (σₐ × σᵦ) | -1 a 1 | No (normalizada) | Relaciones estadísticas, series temporales | O(n) - eficiente |
Las bases de datos vectoriales como Pinecone, Weaviate, Milvus y Qdrant han surgido como infraestructura especializada para almacenar y consultar vectores de alta dimensión utilizando la similitud del coseno como su principal métrica de similitud. Estas bases de datos están optimizadas para manejar millones o miles de millones de vectores, permitiendo búsqueda semántica en tiempo real a gran escala. Cuando se envía una consulta a una base de datos vectorial, se convierte en una incrustación y se compara con todos los vectores almacenados utilizando la similitud del coseno, con los resultados clasificados por puntuación de similitud. Para lograr un rendimiento práctico con conjuntos de datos masivos, las bases de datos vectoriales emplean algoritmos de vecino más cercano aproximado (ANN) como Hierarchical Navigable Small World (HNSW) y DiskANN, que sacrifican precisión perfecta por mejoras drásticas de velocidad. Por ejemplo, la extensión pgvectorscale de Timescale, que implementa StreamingDiskANN, logra 28 veces menos latencia y 16 veces mayor rendimiento de consulta comparado con bases de datos vectoriales especializadas como Pinecone, manteniendo un 99% de recall a un 75% menos de coste. En aplicaciones de búsqueda semántica, la similitud del coseno permite que los sistemas comprendan la intención del usuario más allá de la coincidencia literal de palabras clave: una búsqueda de “hábitos alimenticios saludables” recuperará documentos sobre “consejos de nutrición” y “dietas equilibradas” porque sus incrustaciones apuntan en direcciones similares a pesar de usar terminología diferente. Esta capacidad ha revolucionado la recuperación de información, permitiendo que motores de búsqueda, sistemas de documentación y bases de conocimiento ofrezcan resultados contextualmente relevantes que coinciden con la intención del usuario y no solo con las palabras clave.
La Generación con Recuperación (RAG) representa un cambio de paradigma en la forma en que los grandes modelos de lenguaje acceden y utilizan la información, y la similitud del coseno es central en esta arquitectura. En un pipeline típico de RAG, cuando un usuario envía una consulta, el sistema primero convierte la consulta en una incrustación vectorial usando el mismo modelo de incrustación que se utilizó para vectorizar la base de conocimientos. La similitud del coseno luego compara este vector de consulta con todos los vectores de documentos en la base de conocimientos, clasificando los documentos por puntuación de relevancia. Los documentos mejor clasificados—aquellos con las puntuaciones de similitud del coseno más altas—se recuperan y se pasan como contexto al LLM, que genera una respuesta fundamentada en la información recuperada. Este enfoque resuelve limitaciones críticas de los LLMs independientes: sus fechas fijas de corte de conocimiento, tendencia a alucinar o generar información que parece plausible pero es incorrecta, e incapacidad para acceder a datos en tiempo real o propietarios. Al usar la similitud del coseno para la recuperación inteligente, los sistemas RAG aseguran que los LLMs generen respuestas basadas en información verificada y actualizada. Las principales implementaciones de RAG incluyen ChatGPT de OpenAI con plugins, Claude de Anthropic con recuperación, AI Overviews de Google y el motor de generación de respuestas de Perplexity. La investigación demuestra que los sistemas RAG que utilizan la similitud del coseno para la recuperación mejoran la precisión de las respuestas en aproximadamente un 40-60% comparado con LLMs independientes, y reducen las tasas de alucinación hasta en un 70%. La eficiencia de los cálculos de similitud del coseno es particularmente importante en los sistemas RAG porque deben realizar comparaciones de similitud sobre potencialmente millones de documentos en tiempo real, y la simplicidad computacional de la similitud del coseno hace esto factible incluso a gran escala.
Implementar la similitud del coseno de manera efectiva requiere prestar atención a varios factores críticos. Primero, el preprocesamiento de datos es esencial: los vectores deben ser normalizados antes del cálculo para asegurar consistencia de escala y resultados válidos, especialmente al trabajar con entradas de alta dimensión de fuentes diversas. Las organizaciones deben eliminar o marcar los vectores nulos (vectores con todos los componentes en cero) porque la similitud del coseno no está definida matemáticamente para vectores nulos, lo que provocaría errores de división por cero durante el cálculo. Al implementar la similitud del coseno en sistemas de producción, es recomendable combinarla con métricas complementarias como la similitud de Jaccard o la distancia euclidiana cuando se necesitan múltiples dimensiones de similitud, en lugar de depender únicamente de la similitud del coseno. Hacer pruebas en entornos similares a producción antes del despliegue es fundamental, especialmente para sistemas en tiempo real como APIs y motores de búsqueda donde el rendimiento y la precisión impactan directamente en la experiencia del usuario. Las bibliotecas populares facilitan la implementación: Scikit-learn ofrece sklearn.metrics.pairwise.cosine_similarity(), NumPy permite la implementación directa de la fórmula con np.dot() y np.linalg.norm(), TensorFlow y PyTorch ofrecen implementaciones aceleradas por GPU para cálculos a gran escala, y PostgreSQL con pgvector proporciona operadores nativos de similitud del coseno para consultas a nivel de base de datos. Para organizaciones que monitorizan menciones de IA y presencia de marca en plataformas como ChatGPT, Perplexity y Google AI Overviews, la similitud del coseno permite un seguimiento preciso de cómo los sistemas de IA referencian y citan su contenido comparando incrustaciones de consulta con vectores de marca y dominio almacenados.
A pesar de su adopción generalizada, la similitud del coseno presenta varios desafíos que los profesionales deben abordar. La métrica no está definida para vectores nulos, lo que requiere un preprocesamiento y validación cuidadosos de los datos para evitar errores en tiempo de ejecución. La similitud del coseno puede producir puntuaciones de similitud engañosamente altas para vectores alineados direccionalmente pero no relacionados semánticamente, particularmente cuando los modelos de incrustación están mal entrenados o cuando los datos de entrenamiento carecen de diversidad y matiz contextual. Este riesgo de falsa similitud es especialmente problemático en aplicaciones como la monitorización de IA, donde evaluaciones incorrectas de similitud podrían llevar a perder menciones de marca o a falsos positivos. La simetría de la métrica—es decir, que no puede distinguir el orden de la comparación—puede ser indeseable en ciertas aplicaciones donde la direccionalidad es importante. Además, una puntuación de similitud del coseno de 0 no siempre indica disimilitud completa en contextos del mundo real; en dominios matizados como el lenguaje, los vectores ortogonales aún pueden compartir relaciones semánticas sutiles que la métrica no captura. La dependencia de la métrica en la normalización adecuada significa que datos mal escalados pueden sesgar los resultados, y las organizaciones deben asegurar un preprocesamiento consistente en todos los vectores de sus sistemas. Finalmente, la similitud del coseno por sí sola puede ser insuficiente para evaluaciones de similitud complejas; combinarla con otras métricas y reglas de validación específicas del dominio suele producir resultados más robustos.
El papel de la similitud del coseno en los sistemas de IA sigue evolucionando a medida que los modelos de incrustación se vuelven más sofisticados y las arquitecturas basadas en vectores dominan el aprendizaje automático. Las tendencias emergentes incluyen la integración de la similitud del coseno con enfoques de búsqueda híbrida que combinan similitud vectorial con búsqueda tradicional de texto completo, permitiendo que los sistemas aprovechen tanto la comprensión semántica como la coincidencia de palabras clave. Las incrustaciones multimodales—que representan texto, imágenes, audio y video en un espacio vectorial compartido—dependen cada vez más de la similitud del coseno para medir relaciones entre modalidades, habilitando aplicaciones como búsqueda de imagen a texto y comprensión de video. El desarrollo de algoritmos de vecino más cercano aproximado más eficientes como DiskANN y HNSW sigue mejorando la escalabilidad de las búsquedas de similitud del coseno, haciendo posible la búsqueda semántica en tiempo real a escalas sin precedentes. Técnicas de cuantización que reducen la dimensionalidad del vector preservando las relaciones de similitud del coseno permiten el despliegue de búsquedas de similitud a gran escala en dispositivos de borde y entornos con recursos limitados. En el contexto de monitorización de IA y seguimiento de marca, la similitud del coseno está cobrando cada vez más importancia a medida que las organizaciones buscan entender cómo sistemas de IA como ChatGPT, Perplexity, Claude y Google AI Overviews referencian y citan su contenido. Los desarrollos futuros pueden incluir métricas adaptativas de similitud del coseno que ajusten su comportamiento según características específicas del dominio, e integración con marcos de explicabilidad que ayuden a los usuarios a entender por qué ciertos vectores se consideran similares. A medida que las bases de datos vectoriales maduran y se convierten en infraestructura estándar para aplicaciones de IA, la similitud del coseno probablemente seguirá siendo la métrica dominante para la comparación semántica, aunque podría complementarse con medidas de similitud específicas del dominio adaptadas a aplicaciones y casos de uso particulares.
Para plataformas como AmICited que rastrean menciones de marca y dominio en sistemas de IA, la similitud del coseno sirve como una base técnica crítica. Al monitorizar cómo ChatGPT, Perplexity, Google AI Overviews y Claude referencian dominios o marcas específicas, la similitud del coseno permite la medición precisa de la relevancia semántica entre las consultas de los usuarios y las respuestas de la IA. Al convertir menciones de marcas, URLs de dominio y contenido de consultas en incrustaciones vectoriales, la similitud del coseno puede determinar si la respuesta de un sistema de IA realmente cita o referencia una marca en lugar de solo mencionar conceptos relacionados. Esta capacidad es esencial para las organizaciones que buscan entender su visibilidad en el contenido generado por IA y rastrear cómo su propiedad intelectual es atribuida o citada por los sistemas de IA. La eficiencia de la métrica la hace práctica para la monitorización en tiempo real de millones de interacciones de IA, permitiendo que las organizaciones reciban alertas inmediatas cuando se referencia su contenido. Además, la similitud del coseno permite el análisis comparativo: las organizaciones pueden rastrear no solo si son mencionadas, sino cómo la frecuencia y relevancia de sus menciones se compara con la de los competidores, proporcionando inteligencia competitiva sobre el comportamiento de los sistemas de IA y los patrones de atribución de contenido.
Una puntuación de similitud del coseno de 1 indica que dos vectores apuntan exactamente en la misma dirección, lo que significa que son perfectamente similares. Una puntuación de 0 significa que los vectores son ortogonales (perpendiculares), lo que indica que no hay relación direccional ni similitud. Una puntuación de -1 indica que los vectores apuntan en direcciones exactamente opuestas, representando una disimilitud completa. En aplicaciones prácticas de PLN, puntuaciones cercanas a 1 indican textos semánticamente similares, mientras que puntuaciones cercanas a 0 sugieren contenido no relacionado.
Se prefiere la similitud del coseno para las incrustaciones de texto porque mide el ángulo entre los vectores en lugar de su distancia absoluta, haciéndola insensible a la magnitud del vector. Esto es crucial para el PLN porque la longitud del documento no debería afectar la similitud semántica: una consulta corta y un artículo largo pueden ser igualmente relevantes. La distancia euclidiana, en cambio, es sensible a la magnitud y funciona mal en espacios de alta dimensión donde los vectores tienden a converger. La similitud del coseno también es computacionalmente más eficiente y está naturalmente acotada entre -1 y 1, evitando problemas de desbordamiento.
En los sistemas RAG, la similitud del coseno impulsa la fase de recuperación comparando las incrustaciones de las consultas con las incrustaciones de documentos en una base de datos vectorial. Cuando un usuario envía una consulta, se convierte en un vector utilizando el mismo modelo de incrustación que los documentos almacenados. La similitud del coseno luego clasifica los documentos por relevancia, siendo las puntuaciones más altas las que indican mejores coincidencias. Los documentos mejor clasificados se recuperan y se pasan al LLM como contexto, permitiendo respuestas más precisas y fundamentadas en hechos. Este proceso permite que los sistemas RAG superen limitaciones de los LLM como conocimiento desactualizado y alucinaciones.
La similitud del coseno tiene varias limitaciones: no está definida cuando los vectores tienen magnitud cero, lo que requiere un preprocesamiento para eliminar vectores nulos. Puede producir puntuaciones de similitud engañosamente altas para vectores alineados direccionalmente pero no relacionados semánticamente, especialmente con incrustaciones mal entrenadas. La métrica también es simétrica, lo que significa que no puede distinguir el orden de la comparación, lo que puede ser problemático en ciertas aplicaciones. Además, una puntuación de similitud de 0 no siempre indica disimilitud completa en contextos del mundo real, particularmente en dominios matizados como el lenguaje donde los vectores ortogonales aún pueden compartir relaciones semánticas.
La similitud del coseno se calcula utilizando la fórmula: (A · B) / (||A|| × ||B||), donde A · B es el producto punto de los vectores A y B, y ||A|| y ||B|| son sus magnitudes (normas euclidianas). El producto punto se calcula multiplicando los componentes correspondientes de los vectores y sumando los resultados. La magnitud de un vector es la raíz cuadrada de la suma de sus componentes al cuadrado. Esta fórmula produce una puntuación normalizada entre -1 y 1, lo que la hace independiente de la longitud del vector y adecuada para comparar vectores de diferentes tamaños.
En plataformas de monitorización de IA como AmICited, la similitud del coseno es esencial para rastrear menciones de marcas y dominios en sistemas de IA como ChatGPT, Perplexity y Google AI Overviews. Al convertir menciones de marcas y consultas en incrustaciones vectoriales, la similitud del coseno mide cuán alineadas están las respuestas generadas por la IA con el contenido rastreado. Esto permite a las organizaciones monitorizar si sus dominios aparecen en respuestas de IA, evaluar la relevancia semántica de las menciones y rastrear cómo los sistemas de IA hacen referencia a su contenido en comparación con los competidores. La eficiencia de la métrica la hace práctica para la monitorización en tiempo real de millones de interacciones de IA.
Las principales plataformas y herramientas de IA que aprovechan la similitud del coseno incluyen los modelos de incrustación de OpenAI, los algoritmos de búsqueda semántica de Google, el sistema de generación de respuestas de Perplexity y los mecanismos de recuperación de Claude. Bases de datos vectoriales como Pinecone, Weaviate y Milvus utilizan la similitud del coseno como su principal métrica de similitud. Bibliotecas de código abierto como Scikit-learn, TensorFlow, PyTorch y NumPy proporcionan funciones integradas de similitud del coseno. PostgreSQL con la extensión pgvector permite cálculos de similitud del coseno a escala. Estas herramientas en conjunto impulsan sistemas de recomendación, chatbots, motores de búsqueda semántica y aplicaciones RAG en todo el ecosistema de IA.
Comienza a rastrear cómo los chatbots de IA mencionan tu marca en ChatGPT, Perplexity y otras plataformas. Obtén información procesable para mejorar tu presencia en IA.
La similitud semántica mide la relación basada en el significado entre textos utilizando incrustaciones y métricas de distancia. Esencial para el monitoreo de I...
La co-ocurrencia es cuando los términos relacionados aparecen juntos en el contenido, señalando relevancia semántica para motores de búsqueda y sistemas de IA. ...

Descubre cómo la coincidencia semántica de consultas permite que los sistemas de IA comprendan la intención del usuario y ofrezcan resultados relevantes más all...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.