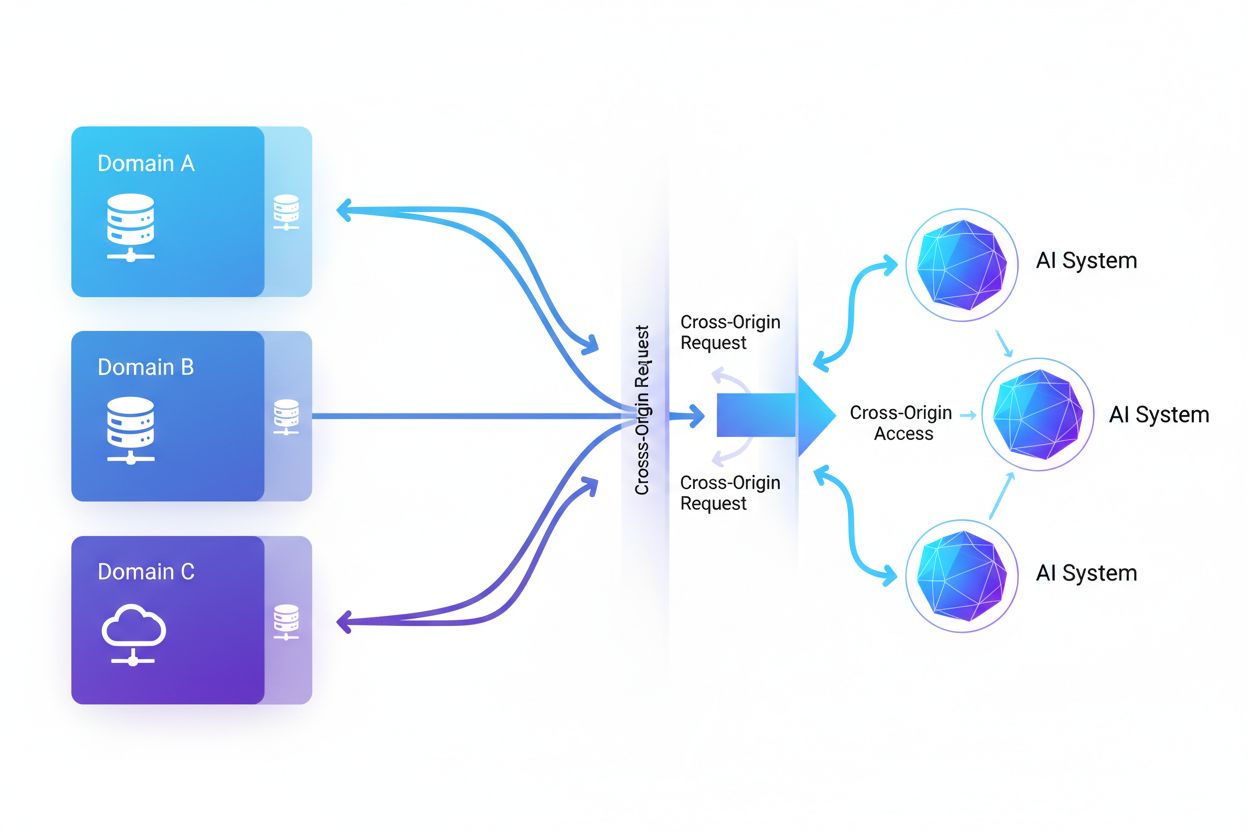
El Acceso de IA entre orígenes se refiere a la capacidad de los sistemas de inteligencia artificial y los rastreadores web para solicitar y recuperar contenido de dominios distintos a su origen, regido por mecanismos de seguridad como CORS. Abarca cómo las empresas de IA escalan la recopilación de datos para entrenar grandes modelos de lenguaje mientras navegan las restricciones entre orígenes. Comprender este concepto es fundamental para creadores de contenido y propietarios de sitios web para proteger la propiedad intelectual y mantener el control sobre cómo los sistemas de IA utilizan su contenido. Tener visibilidad sobre la actividad de IA entre orígenes ayuda a distinguir entre acceso legítimo de IA y raspado no autorizado.
Acceso de IA entre orígenes
El Acceso de IA entre orígenes se refiere a la capacidad de los sistemas de inteligencia artificial y los rastreadores web para solicitar y recuperar contenido de dominios distintos a su origen, regido por mecanismos de seguridad como CORS. Abarca cómo las empresas de IA escalan la recopilación de datos para entrenar grandes modelos de lenguaje mientras navegan las restricciones entre orígenes. Comprender este concepto es fundamental para creadores de contenido y propietarios de sitios web para proteger la propiedad intelectual y mantener el control sobre cómo los sistemas de IA utilizan su contenido. Tener visibilidad sobre la actividad de IA entre orígenes ayuda a distinguir entre acceso legítimo de IA y raspado no autorizado.
Comprendiendo el Acceso de IA entre orígenes
El Acceso de IA entre orígenes se refiere a la capacidad de los sistemas de inteligencia artificial y los rastreadores web para solicitar y recuperar contenido de dominios distintos a su origen, regido por mecanismos de seguridad como el Intercambio de Recursos de Origen Cruzado (CORS). A medida que las empresas de IA amplían sus esfuerzos de recopilación de datos para entrenar grandes modelos de lenguaje y otros sistemas de IA, comprender cómo estos sistemas navegan las restricciones entre orígenes se ha vuelto fundamental para los creadores de contenido y propietarios de sitios web. El desafío radica en distinguir entre el acceso legítimo de IA para la indexación de búsqueda y el raspado no autorizado para el entrenamiento de modelos, por lo que la visibilidad sobre la actividad de IA entre orígenes es esencial para proteger la propiedad intelectual y mantener el control sobre el uso del contenido.
Mecanismo CORS y rastreadores de IA
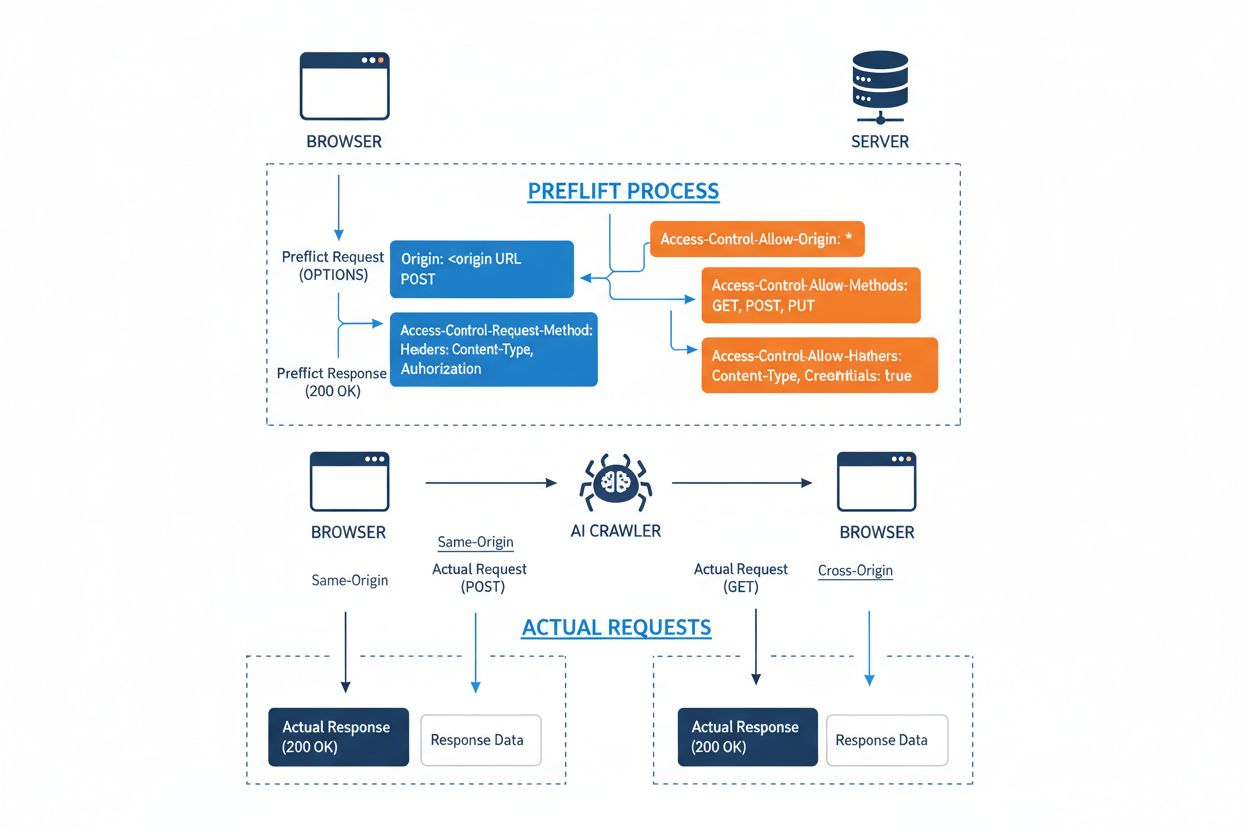
El Intercambio de Recursos de Origen Cruzado (CORS) es un mecanismo de seguridad basado en cabeceras HTTP que permite a los servidores especificar qué orígenes (dominios, esquemas o puertos) pueden acceder a sus recursos. Cuando un rastreador de IA o cualquier cliente intenta acceder a un recurso desde un origen diferente, el navegador o cliente inicia una solicitud de preflight utilizando el método HTTP OPTIONS para verificar si el servidor permite la solicitud real. El servidor responde con cabeceras CORS específicas que dictan los permisos de acceso, incluyendo qué orígenes están permitidos, qué métodos HTTP se permiten, qué cabeceras pueden incluirse y si pueden enviarse credenciales como cookies o tokens de autenticación con la solicitud.
Cabecera CORS
Propósito
Access-Control-Allow-Origin
Especifica qué orígenes pueden acceder al recurso (* para todos o dominios específicos)
Access-Control-Allow-Methods
Lista los métodos HTTP permitidos (GET, POST, PUT, DELETE, etc.)
Access-Control-Allow-Headers
Define qué cabeceras de solicitud están permitidas (Authorization, Content-Type, etc.)
Access-Control-Allow-Credentials
Determina si las credenciales (cookies, tokens de autenticación) pueden incluirse en las solicitudes
Access-Control-Max-Age
Especifica cuánto tiempo pueden ser almacenadas en caché las respuestas de preflight (en segundos)
Access-Control-Expose-Headers
Lista las cabeceras de respuesta a las que los clientes pueden acceder
Los rastreadores de IA interactúan con CORS respetando estas cabeceras cuando están correctamente configuradas, aunque muchos bots sofisticados intentan eludir estas restricciones falsificando agentes de usuario o utilizando redes proxy. La efectividad de CORS como defensa contra el acceso no autorizado de IA depende por completo de una configuración adecuada del servidor y de la disposición del rastreador a acatar las restricciones, una distinción crítica que ha cobrado cada vez más importancia a medida que las empresas de IA compiten por datos de entrenamiento.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Principales rastreadores de IA y sus patrones de acceso
El panorama de los rastreadores de IA que acceden a la web se ha expandido drásticamente, con varios actores principales dominando los patrones de acceso entre orígenes. Según el análisis del tráfico de red de Cloudflare, los rastreadores de IA más prevalentes incluyen:
Bytespider (ByteDance) - Supuestamente utilizado para recopilar datos de entrenamiento para modelos de IA chinos, incluido Doubao, accediendo a aproximadamente el 40% de los sitios web en la red de Cloudflare
GPTBot (OpenAI) - Recopila datos de entrenamiento para ChatGPT y futuros modelos, accediendo a aproximadamente el 35% de los sitios protegidos por Cloudflare
ClaudeBot (Anthropic) - Da soporte al asistente Claude AI, con volúmenes de solicitudes en aumento y accediendo a alrededor del 11% de los sitios
Amazonbot (Amazon) - Indexa contenido para las capacidades de respuesta de Alexa, representando el segundo mayor volumen de solicitudes
CCBot (Common Crawl) - Rastreador sin ánimo de lucro que produce conjuntos de datos abiertos de la web usados por múltiples proyectos de IA, accediendo a aproximadamente el 2% de los sitios
Google-Extended (Google) - Separado del Googlebot estándar, rastrea específicamente contenido para los productos de IA Bard y Gemini
Perplexity Bot (Perplexity AI) - Recopila contenido para el motor de búsqueda Perplexity, aunque fue sorprendido falsificando agentes de usuario para eludir restricciones
Estos rastreadores generan miles de millones de solicitudes mensualmente, con algunos como Bytespider y GPTBot accediendo a la mayoría del contenido público de Internet. El enorme volumen y la naturaleza agresiva de esta actividad han llevado a grandes plataformas como Reddit, Twitter/X, Stack Overflow y numerosos medios de comunicación a implementar medidas de bloqueo.
Vulnerabilidades y riesgos de seguridad
Las políticas CORS mal configuradas crean importantes vulnerabilidades de seguridad que los rastreadores de IA pueden explotar para acceder a datos sensibles sin autorización. Cuando los servidores establecen Access-Control-Allow-Origin: * sin validación adecuada, permiten inadvertidamente que cualquier origen, incluidos scrapers de IA maliciosos, acceda a recursos que deberían estar restringidos. Una configuración especialmente peligrosa ocurre cuando Access-Control-Allow-Credentials: true se combina con orígenes comodín, permitiendo a los atacantes robar datos de usuarios autenticados mediante solicitudes entre orígenes que incluyen cookies de sesión o tokens de autenticación.
Las configuraciones erróneas comunes de CORS incluyen reflejar dinámicamente la cabecera Origin directamente en la respuesta Access-Control-Allow-Origin sin validación, lo que permite en la práctica que cualquier origen acceda al recurso. Las listas blancas demasiado permisivas que no validan correctamente los límites de dominio pueden ser explotadas mediante ataques de subdominios o manipulación de prefijos. Además, muchas organizaciones no implementan una validación adecuada de la propia cabecera Origin, lo que las hace vulnerables a solicitudes falsificadas. Las consecuencias de estas vulnerabilidades van más allá del robo de datos, incluyendo el entrenamiento no autorizado de modelos de IA en contenido propietario, la obtención de inteligencia competitiva y la violación de derechos de propiedad intelectual, riesgos que herramientas como AmICited.com ayudan a monitorear y cuantificar.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Métodos de detección para el acceso de IA entre orígenes
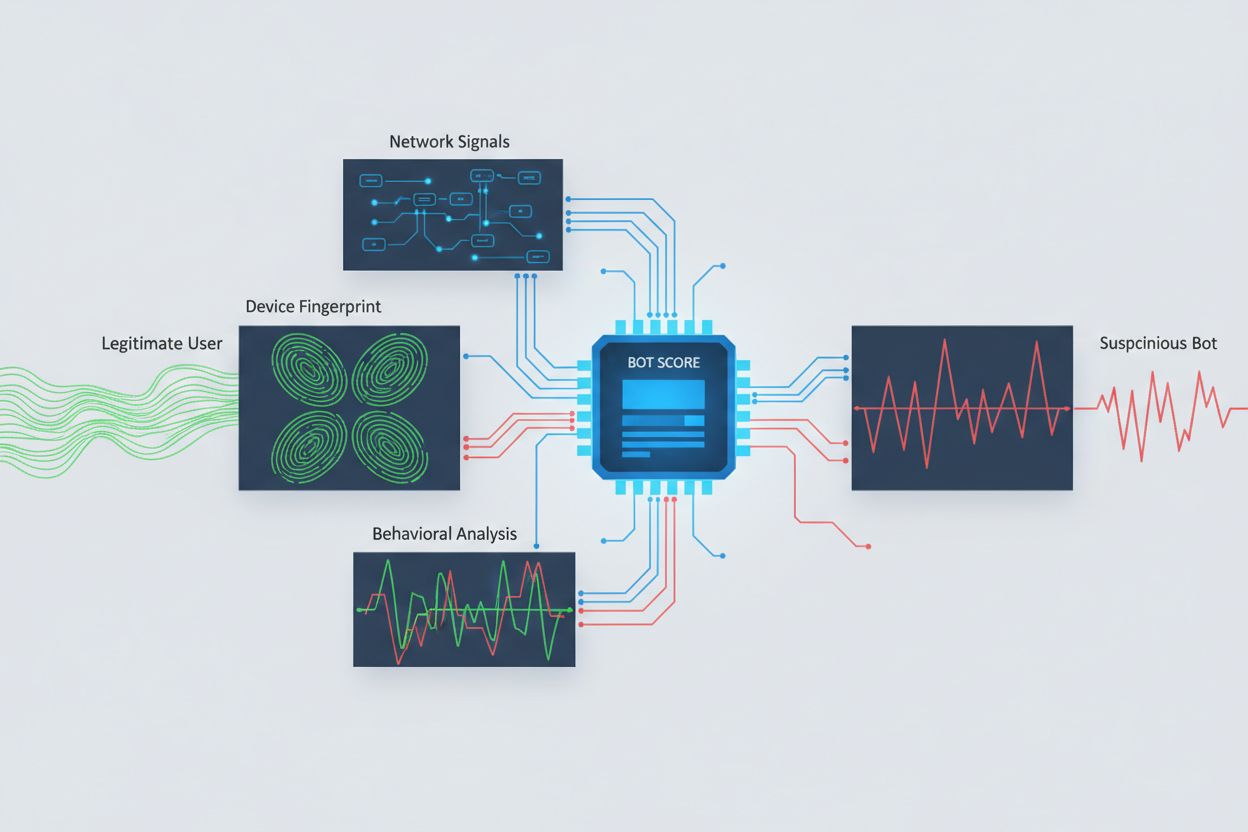
Identificar rastreadores de IA que intentan acceder entre orígenes requiere analizar múltiples señales más allá de las simples cadenas de agente de usuario, que son trivialmente falsificables. El análisis del agente de usuario sigue siendo un método de detección de primera línea, ya que muchos rastreadores de IA se identifican mediante cadenas de agente de usuario específicas como “GPTBot/1.0” o “ClaudeBot/1.0”, aunque rastreadores sofisticados enmascaran deliberadamente su identidad haciéndose pasar por navegadores legítimos. La huella de comportamiento analiza cómo se realizan las solicitudes, examinando patrones como el tiempo entre peticiones, la secuencia de páginas accedidas, la presencia o ausencia de ejecución de JavaScript y patrones de interacción que difieren fundamentalmente del comportamiento humano.
El análisis de señales de red proporciona capacidades de detección más profundas al examinar firmas de handshake TLS, reputación de IP, patrones de resolución DNS y características de conexión que revelan actividad de bots incluso cuando los agentes de usuario son falsificados. La huella de dispositivo agrega docenas de señales, incluyendo versión del navegador, resolución de pantalla, fuentes instaladas, detalles del sistema operativo y huellas TLS JA3 para crear identificadores únicos para cada fuente de solicitud. Los sistemas avanzados de detección pueden identificar cuándo múltiples sesiones se originan desde el mismo dispositivo o script, detectando intentos de scraping distribuido que intentan evadir la limitación de velocidad distribuyendo solicitudes en muchas direcciones IP. Las organizaciones pueden aprovechar estos métodos de detección mediante plataformas de seguridad y servicios de monitoreo para obtener visibilidad sobre qué sistemas de IA acceden a su contenido y cómo intentan eludir las restricciones.
Bloqueo y control del acceso de IA
Las organizaciones emplean múltiples estrategias complementarias para bloquear o controlar el acceso de IA entre orígenes, reconociendo que ningún método único brinda protección completa:
Reglas Disallow en robots.txt - Agregar directivas de desautorización para agentes de usuario de IA conocidos (por ejemplo, User-agent: GPTBot seguido de Disallow: /) proporciona un mecanismo cortés pero voluntario; efectivo para rastreadores bien comportados, pero fácilmente ignorado por scrapers determinados
Filtrado de agente de usuario - Configurar servidores web o firewalls para bloquear o redirigir cadenas de agente de usuario específicas; más efectivo que robots.txt pero vulnerable a falsificaciones, ya que los agentes de usuario son fáciles de forjar
Bloqueo de direcciones IP - Bloquear rangos de IP asociados a scrapers conocidos o proveedores de nube; efectivo contra ataques distribuidos pero puede ser eludido mediante rotación de proxies y redes de IP residenciales
Limitación y reducción de velocidad - Implementar límites de velocidad de solicitudes que ralentizan a los scrapers; reduce el impacto, pero bots sofisticados pueden distribuir solicitudes entre muchas IPs para mantenerse por debajo de los umbrales
Honeypots y trampas - Crear enlaces ocultos o laberintos de enlaces infinitos que solo los bots exploran, agotando recursos de los rastreadores; experimental, pero puede degradar la calidad de los conjuntos de datos de los scrapers
Autenticación y muros de pago - Requerir credenciales de inicio de sesión o pago para acceder al contenido; altamente efectivo, pero inconveniente para usuarios legítimos y no viable para todo tipo de contenido
Huellas avanzadas de dispositivo - Analizar señales de comportamiento y de red para identificar bots independientemente de la falsificación de agente de usuario; el enfoque más sofisticado, pero requiere integración con plataformas de seguridad
La defensa más efectiva combina múltiples capas, ya que los atacantes determinados explotarán debilidades de cualquier enfoque monometódico. Las organizaciones deben monitorear continuamente qué métodos de bloqueo funcionan y adaptarse a medida que los rastreadores evolucionan sus técnicas de evasión.
Mejores prácticas para gestionar el acceso de IA entre orígenes
La gestión efectiva del acceso de IA entre orígenes requiere un enfoque integral y por capas que equilibre la seguridad con las necesidades operativas. Las organizaciones deben implementar una estrategia escalonada comenzando con controles básicos como robots.txt y filtrado de agente de usuario, añadiendo luego mecanismos de detección y bloqueo más sofisticados según las amenazas observadas. El monitoreo continuo es esencial: rastrear qué sistemas de IA acceden a tu contenido, con qué frecuencia realizan solicitudes y si respetan tus restricciones brinda la visibilidad necesaria para tomar decisiones informadas sobre las políticas de acceso.
La documentación de las políticas de acceso debe ser clara y exigible, con términos de servicio explícitos que prohíban el scraping no autorizado y especifiquen consecuencias para las violaciones. Auditorías regulares de las configuraciones de CORS ayudan a identificar errores antes de que sean explotados, mientras que mantener un inventario actualizado de agentes de usuario e IPs de rastreadores de IA conocidos permite responder rápidamente a nuevas amenazas. Las organizaciones también deben considerar las implicaciones comerciales de bloquear el acceso de IA: algunos rastreadores de IA aportan valor mediante la indexación de búsqueda o asociaciones legítimas, por lo que las políticas deben distinguir entre patrones de acceso beneficiosos y perjudiciales. Implementar estas prácticas requiere coordinación entre equipos de seguridad, legales y de negocio para asegurar que las políticas se alineen con los objetivos organizacionales y los requisitos regulatorios.
Herramientas y soluciones para la gestión de acceso de IA
Han surgido herramientas y plataformas especializadas para ayudar a las organizaciones a monitorear y controlar el acceso de IA entre orígenes con mayor precisión y visibilidad. AmICited.com proporciona un monitoreo integral de cómo los sistemas de IA referencian y acceden a tu marca en GPTs, Perplexity, Google AI Overviews y otras plataformas de IA, ofreciendo visibilidad sobre qué modelos de IA están usando tu contenido y con qué frecuencia aparece tu marca en respuestas generadas por IA. Esta capacidad de monitoreo se extiende al seguimiento de patrones de acceso entre orígenes y la comprensión del ecosistema más amplio de sistemas de IA que interactúan con tus propiedades digitales.
Más allá del monitoreo, Cloudflare ofrece funciones de gestión de bots con bloqueo con un solo clic de rastreadores de IA conocidos, utilizando modelos de aprendizaje automático entrenados en patrones de tráfico de toda la red para identificar bots incluso cuando falsifican agentes de usuario. AWS WAF (Firewall de Aplicaciones Web) proporciona reglas personalizables para bloquear agentes de usuario e IPs específicos, mientras que Imperva ofrece detección avanzada de bots combinando análisis de comportamiento con inteligencia de amenazas. Bright Data se especializa en comprender patrones de tráfico de bots y puede ayudar a las organizaciones a distinguir entre diferentes tipos de rastreadores. La elección de herramientas depende del tamaño de la organización, el nivel técnico y los requisitos específicos, desde la gestión simple de robots.txt para sitios pequeños hasta plataformas de gestión de bots de nivel empresarial para grandes organizaciones que manejan datos sensibles. Independientemente de la selección de herramientas, el principio fundamental sigue siendo: la visibilidad sobre el acceso de IA entre orígenes es la base para un control y protección efectivos de los activos digitales.
Preguntas frecuentes
¿Cuál es la diferencia entre CORS y Acceso de IA entre orígenes?
CORS (Intercambio de Recursos de Origen Cruzado) es un mecanismo de seguridad que controla qué orígenes pueden acceder a los recursos en un servidor. El Acceso de IA entre orígenes se refiere específicamente a cómo los sistemas de IA y los rastreadores interactúan con CORS para solicitar contenido de diferentes dominios. Mientras que CORS es el marco técnico, el Acceso de IA entre orígenes describe el desafío práctico de gestionar el comportamiento de los rastreadores de IA dentro de ese marco, incluyendo la detección y el bloqueo de accesos no autorizados de IA.
¿Cómo se identifican los rastreadores de IA al acceder al contenido?
La mayoría de los rastreadores de IA bien comportados se identifican a través de cadenas de agente de usuario específicas como 'GPTBot/1.0' o 'ClaudeBot/1.0' que indican claramente su propósito. Sin embargo, muchos rastreadores sofisticados falsifican deliberadamente los agentes de usuario al hacerse pasar por navegadores legítimos como Chrome o Safari para evadir el bloqueo basado en agente de usuario. Por eso son necesarios métodos avanzados de detección usando huellas de comportamiento y análisis de señales de red para identificar bots independientemente de la identidad que afirmen.
¿Puede robots.txt bloquear eficazmente a los rastreadores de IA?
robots.txt proporciona un mecanismo voluntario para solicitar que los rastreadores respeten las restricciones de acceso, y los rastreadores de IA bien comportados como GPTBot suelen acatar estas directivas. Sin embargo, robots.txt no es exigible: los scrapers determinados pueden simplemente ignorarlo. Muchas empresas de IA han sido sorprendidas eludiendo las restricciones de robots.txt, por lo que es una defensa necesaria pero insuficiente que debe combinarse con métodos técnicos de bloqueo como el filtrado de agente de usuario, limitación de velocidad y huellas de dispositivo.
¿Cuáles son los principales riesgos de seguridad de una configuración incorrecta de CORS para el acceso de IA?
Políticas CORS mal configuradas pueden permitir que rastreadores de IA no autorizados accedan a datos sensibles, roben información de usuarios autenticados mediante solicitudes con credenciales habilitadas y extraigan contenido propietario para el entrenamiento no autorizado de modelos de IA. Las configuraciones más peligrosas combinan ajustes de origen comodín con permisos de credenciales, permitiendo en la práctica que cualquier origen acceda a recursos protegidos. Estas configuraciones erróneas pueden llevar al robo de propiedad intelectual, obtención de inteligencia competitiva y violación de acuerdos de licencia de contenido.
¿Cómo puedo detectar si los sistemas de IA están accediendo a mi contenido?
La detección requiere analizar múltiples señales más allá de las cadenas de agente de usuario. Puedes examinar los registros del servidor para encontrar agentes de usuario de rastreadores de IA conocidos, implementar huellas de comportamiento para identificar bots por sus patrones de interacción, analizar señales de red como handshakes TLS y patrones DNS, y usar huellas de dispositivo para identificar intentos de scraping distribuido. Herramientas como AmICited.com proporcionan monitoreo integral de cómo los sistemas de IA referencian tu marca, mientras que plataformas como Cloudflare ofrecen detección de bots basada en aprendizaje automático que identifica incluso rastreadores falsificados.
¿Cuál es la forma más efectiva de bloquear rastreadores de IA no deseados?
Ningún método único brinda protección completa, por lo que un enfoque por capas es el más eficaz. Comienza con robots.txt y filtrado de agente de usuario como defensa básica, añade limitación de velocidad para reducir el impacto, implementa huellas de dispositivo para atrapar bots sofisticados y considera autenticación o muros de pago para contenido sensible. Las organizaciones más efectivas combinan múltiples técnicas y monitorean continuamente cuáles métodos funcionan, adaptándose a medida que los rastreadores evolucionan sus técnicas de evasión.
¿Todas las empresas de IA respetan las restricciones de acceso entre orígenes?
No. Aunque grandes empresas como OpenAI y Anthropic afirman respetar robots.txt y las restricciones de CORS, investigaciones han revelado que muchos rastreadores de IA eluden estas restricciones. Perplexity AI fue sorprendida falsificando agentes de usuario para evadir bloqueos, y la investigación muestra que rastreadores de OpenAI y Anthropic han accedido a contenido a pesar de reglas explícitas de robots.txt que lo prohíben. Esta inconsistencia es la razón por la que los métodos de bloqueo técnicos y la aplicación legal son cada vez más necesarios.
¿Cómo ayuda AmICited.com a monitorear el acceso de IA a mi contenido?
AmICited.com proporciona monitoreo integral de cómo los sistemas de IA referencian y acceden a tu marca en GPTs, Perplexity, Google AI Overviews y otras plataformas de IA. Rastrea qué modelos de IA usan tu contenido, con qué frecuencia aparece tu marca en respuestas generadas por IA y te da visibilidad sobre el ecosistema más amplio de sistemas de IA que interactúan con tus propiedades digitales. Este monitoreo te ayuda a comprender el alcance del acceso de IA y tomar decisiones informadas sobre tu estrategia de protección de contenido.
Monitorea cómo los sistemas de IA acceden a tu contenido
Obtén visibilidad completa sobre qué sistemas de IA están accediendo a tu marca en GPTs, Perplexity, Google AI Overviews y otras plataformas. Rastrea patrones de acceso de IA entre orígenes y comprende cómo tu contenido se utiliza en el entrenamiento e inferencia de IA.
¿Puede la IA acceder a contenido restringido? Métodos e implicaciones
Descubre cómo los sistemas de IA acceden a contenido con muro de pago y restringido, las técnicas que utilizan y cómo proteger tu contenido mientras mantienes l...
Descubre cómo los sistemas de IA deciden entre citar múltiples fuentes o concentrarse en las autorizadas. Comprende los patrones de citación en ChatGPT, Google ...
¿Qué es la atribución de visibilidad en IA y cómo impacta en tu marca?
Descubre qué es la atribución de visibilidad en IA, en qué se diferencia del SEO tradicional y por qué monitorizar la aparición de tu marca en respuestas genera...
13 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.