
Búsqueda de IA Multimodal
Descubre cómo los sistemas de búsqueda de IA multimodal procesan texto, imágenes, audio y video juntos para ofrecer resultados más precisos y relevantes en cont...
7 min de lectura
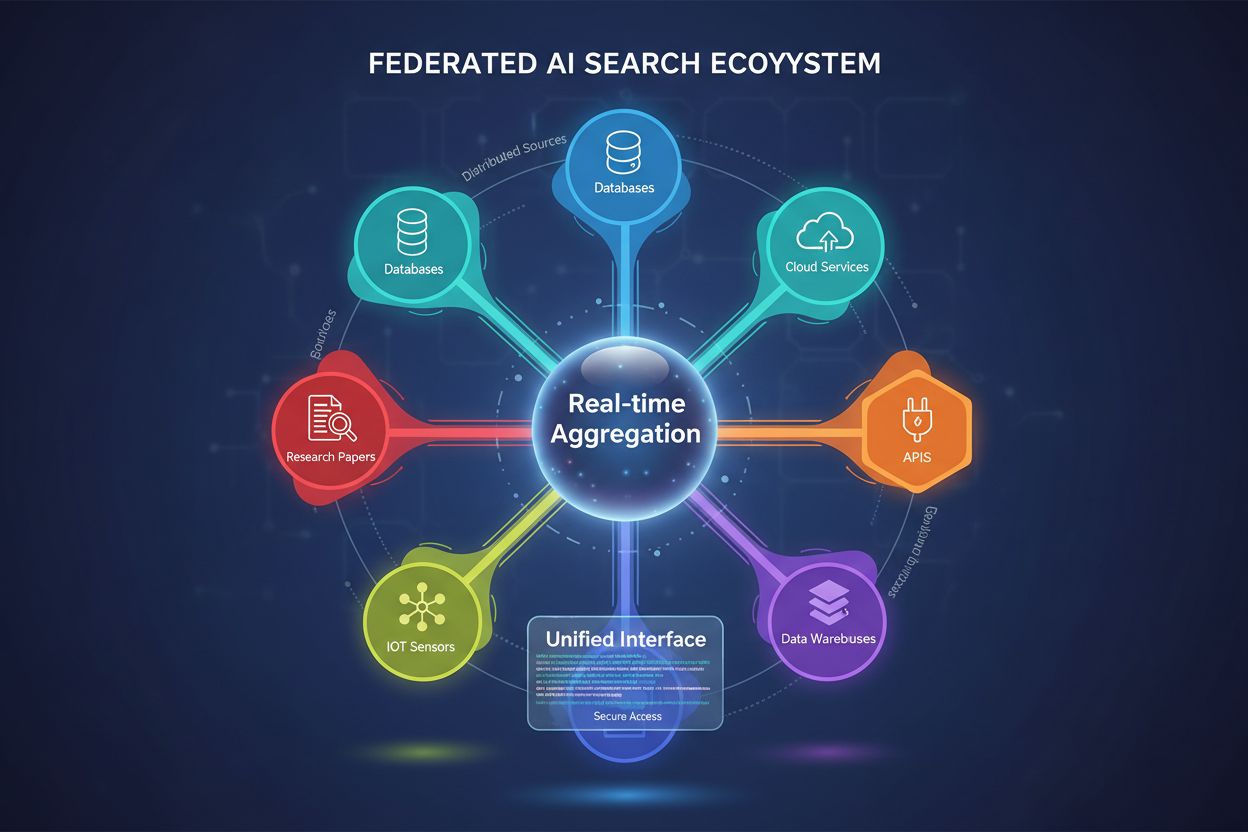
La Búsqueda Federada de IA es un sistema que consulta múltiples fuentes de datos independientes simultáneamente utilizando una sola consulta de búsqueda y agrega los resultados en tiempo real sin mover ni duplicar los datos. Permite a las organizaciones acceder a información distribuida a través de bases de datos, APIs y servicios en la nube, manteniendo la seguridad y el cumplimiento normativo de los datos. A diferencia de los motores de búsqueda centralizados tradicionales, los sistemas federados preservan la autonomía de los datos al tiempo que ofrecen un descubrimiento de información unificado. Este enfoque es especialmente valioso para empresas que gestionan fuentes de datos diversas en diferentes departamentos, geografías u organizaciones.
La Búsqueda Federada de IA es un sistema que consulta múltiples fuentes de datos independientes simultáneamente utilizando una sola consulta de búsqueda y agrega los resultados en tiempo real sin mover ni duplicar los datos. Permite a las organizaciones acceder a información distribuida a través de bases de datos, APIs y servicios en la nube, manteniendo la seguridad y el cumplimiento normativo de los datos. A diferencia de los motores de búsqueda centralizados tradicionales, los sistemas federados preservan la autonomía de los datos al tiempo que ofrecen un descubrimiento de información unificado. Este enfoque es especialmente valioso para empresas que gestionan fuentes de datos diversas en diferentes departamentos, geografías u organizaciones.
La Búsqueda Federada de IA es un sistema distribuido de recuperación de información que consulta simultáneamente múltiples fuentes de datos heterogéneas y agrega inteligentemente los resultados utilizando técnicas de inteligencia artificial. A diferencia de los motores de búsqueda centralizados tradicionales que mantienen un único repositorio indexado, la búsqueda federada de IA opera sobre redes descentralizadas de bases de datos independientes, bases de conocimiento y sistemas de información sin requerir consolidación de datos ni indexación centralizada.
El principio fundamental que subyace a la búsqueda federada de IA es la consulta independiente de la fuente (source-agnostic querying), donde una única consulta de usuario se enruta de forma inteligente a las fuentes de datos relevantes, es procesada de forma independiente por cada fuente y luego se sintetiza en un conjunto de resultados unificado. Este enfoque preserva la autonomía de los datos y permite un descubrimiento de información integral a través de fronteras organizacionales y técnicas.
Las características clave de los sistemas de búsqueda federada de IA incluyen:
Arquitectura Distribuida: Los datos permanecen en su ubicación original a través de múltiples repositorios, eliminando la necesidad de migración o almacenamiento centralizado. Cada fuente mantiene su propio índice, controles de acceso y mecanismos de actualización de forma independiente.
Enrutamiento Inteligente de Consultas: Los algoritmos de IA analizan las consultas entrantes para determinar qué fuentes son más propensas a contener información relevante, optimizando la eficiencia de búsqueda y reduciendo consultas innecesarias a bases de datos irrelevantes.
Agregación y Clasificación de Resultados: Los modelos de aprendizaje automático sintetizan los resultados de múltiples fuentes aplicando algoritmos de clasificación sofisticados que consideran la credibilidad de la fuente, la relevancia del resultado, la frescura y el contexto del usuario.
Soporte de Fuentes Heterogéneas: Los sistemas federados acomodan diversos formatos de datos, esquemas, lenguajes de consulta y protocolos de acceso, incluyendo bases de datos relacionales, almacenes de documentos, grafos de conocimiento, APIs y repositorios de texto no estructurado.
Integración en Tiempo Real: A diferencia de los enfoques de almacenamiento de datos por lotes, la búsqueda federada proporciona acceso casi en tiempo real a la información actual de todas las fuentes conectadas, garantizando la frescura y precisión de los resultados.
Comprensión Semántica: La búsqueda federada de IA moderna aprovecha el procesamiento de lenguaje natural y el análisis semántico para entender la intención de la consulta más allá de la coincidencia de palabras, permitiendo una selección de fuentes y una interpretación de resultados más precisas.
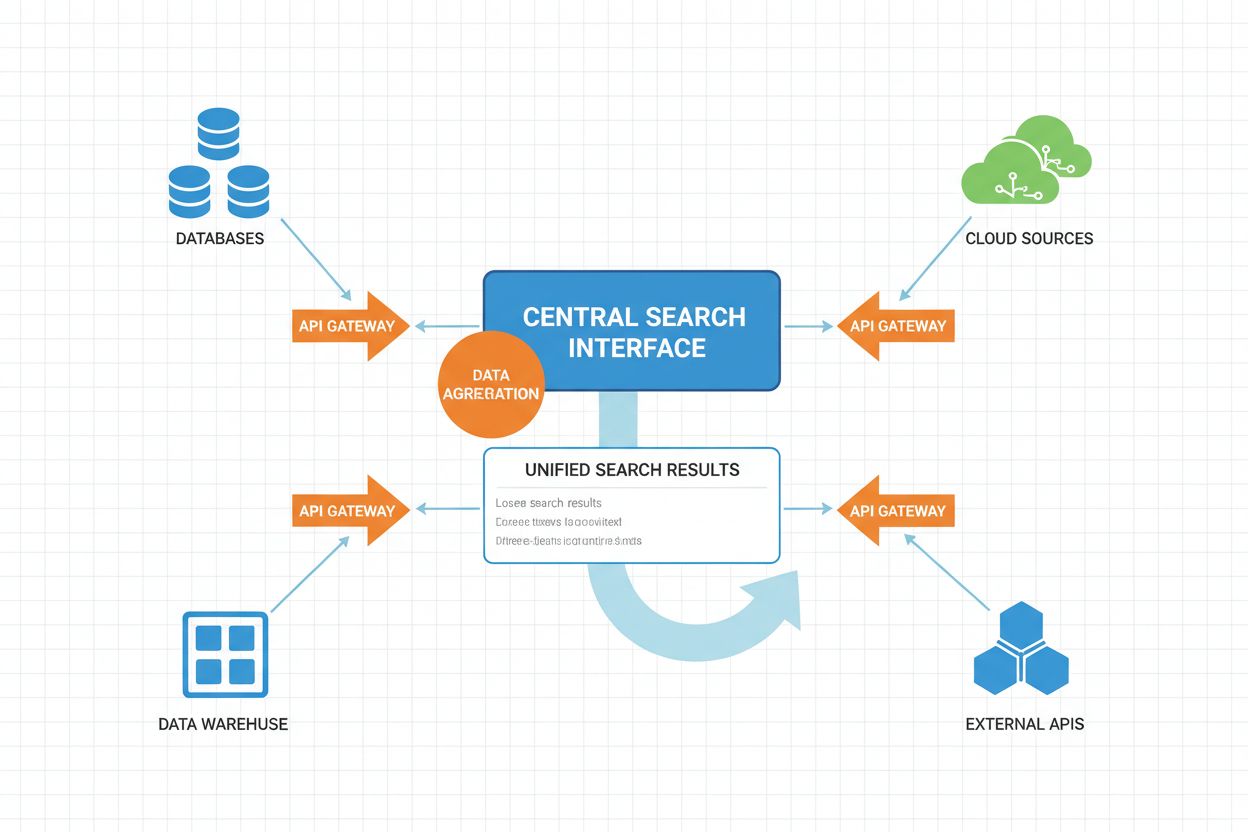
El flujo operativo de la búsqueda federada de IA implica múltiples etapas coordinadas, cada una mejorada por inteligencia artificial para optimizar el rendimiento y la calidad de los resultados.
| Etapa | Proceso | Componente de IA | Salida |
|---|---|---|---|
| Análisis de Consulta | La consulta de usuario se analiza para extraer intención, entidades y contexto | PLN, Reconocimiento de Entidades Nombradas, Clasificación de Intención | Representación estructurada de la consulta, entidades identificadas, señales de intención |
| Selección de Fuentes | El sistema determina qué fuentes de datos son más relevantes para la consulta | Modelos de Clasificación y Ranking, Clasificadores de Relevancia de Fuentes | Lista priorizada de fuentes objetivo, puntajes de confianza |
| Traducción de Consultas | La consulta se traduce a formatos y lenguajes específicos de cada fuente | Mapeo de Esquema, Modelos de Traducción de Consultas, Coincidencia Semántica | Consultas específicas para cada fuente (SQL, SPARQL, llamadas API, etc.) |
| Ejecución Distribuida | Las consultas se ejecutan en paralelo en las fuentes seleccionadas | Balanceo de Carga, Gestión de Tiempos de Espera, Procesamiento Paralelo | Resultados sin procesar de cada fuente, metadatos de ejecución |
| Normalización de Resultados | Los resultados de distintas fuentes se convierten a un formato común | Alineación de Esquemas, Conversión de Tipos de Datos, Estandarización de Formatos | Conjunto de resultados normalizado con estructura consistente |
| Enriquecimiento Semántico | Los resultados se enriquecen con contexto adicional y metadatos | Enlazado de Entidades, Etiquetado Semántico, Integración con Grafos de Conocimiento | Resultados enriquecidos con anotaciones semánticas |
| Clasificación y Eliminación de Duplicados | Se clasifican los resultados por relevancia y se eliminan duplicados | Modelos de Ranking, Detección de Similitud, Puntuación de Relevancia | Lista de resultados deduplicada y clasificada |
| Personalización | Resultados personalizados según el perfil y preferencias del usuario | Filtrado Colaborativo, Modelado de Usuario, Conciencia de Contexto | Ordenación personalizada de resultados |
| Presentación | Los resultados se formatean para su consumo por el usuario | Generación de Lenguaje Natural, Resumen de Resultados | Visualización de resultados para el usuario |
El flujo de trabajo opera con ejecución paralela en su núcleo, donde múltiples fuentes se consultan simultáneamente en lugar de secuencialmente. Esta paralelización reduce drásticamente la latencia de consulta, a pesar de la sobrecarga de coordinar múltiples fuentes. Los sistemas federados avanzados implementan planificación adaptativa de consultas, donde el sistema aprende de patrones históricos para optimizar la selección de fuentes y las estrategias de ejecución con el tiempo.
Mecanismos de Tiempo de Espera y Fallback son componentes cruciales para asegurar la fiabilidad del sistema. Cuando una fuente responde lentamente o falla, el sistema puede esperar con tiempos de espera adaptativos o continuar con los resultados de las fuentes disponibles, degradando de forma controlada la integridad del resultado en lugar de fallar totalmente.
Los sistemas de búsqueda federada de IA pueden clasificarse en varias dimensiones:
Por Modelo de Arquitectura:
Por Tipo de Fuente de Datos:
Por Alcance y Escala:
Por Nivel de Inteligencia:
Autonomía de Datos y Gobernanza: Las organizaciones mantienen el control sobre sus datos, eliminando la necesidad de transferir información sensible a repositorios centralizados. Así se preservan políticas de gobernanza, requisitos de cumplimiento y controles de seguridad a nivel de fuente.
Escalabilidad Sin Consolidación: Los sistemas federados escalan añadiendo nuevas fuentes sin requerir migración de datos ni reestructuración de almacenes. Esto permite integrar nuevas fuentes de datos de manera incremental según evolucionan las necesidades del negocio.
Acceso a Información en Tiempo Real: Al consultar directamente las fuentes, la búsqueda federada permite acceder a información actual sin la latencia inherente a los almacenes de datos por lotes. Es especialmente valioso para aplicaciones sensibles al tiempo.
Eficiencia de Costes: Elimina los altos costes de infraestructura y operación asociados a la creación y mantenimiento de almacenes de datos centralizados. Se evita la duplicación de datos, almacenamiento redundante y procesos ETL complejos.
Reducción de Redundancia de Datos: A diferencia de los enfoques de warehousing que duplican datos entre sistemas, la búsqueda federada mantiene fuentes únicas de verdad, reduciendo el almacenamiento y asegurando la consistencia.
Flexibilidad y Adaptabilidad: Se pueden integrar nuevas fuentes sin modificar la infraestructura existente ni reindexar repositorios centralizados. Esta flexibilidad permite una respuesta ágil ante cambios en el negocio.
Mejora de la Calidad de Datos: Al consultar directamente las fuentes autorizadas, la búsqueda federada reduce la obsolescencia y la inconsistencia que surgen de la sincronización periódica de datos en enfoques de warehousing.
Mayor Seguridad: Los datos sensibles nunca abandonan su ubicación original, reduciendo el riesgo de accesos no autorizados o filtraciones. Los controles de acceso permanecen gestionados a nivel de fuente.
Soporte de Fuentes Heterogéneas: Los sistemas federados soportan tecnologías, formatos y protocolos diversos sin requerir estandarización ni migración a plataformas comunes.
Síntesis Inteligente de Resultados: El ranking y la agregación potenciados por IA producen resultados de mayor calidad que las fusiones simples, considerando la credibilidad de la fuente, la relevancia y el contexto del usuario.
Los sistemas modernos de búsqueda federada de IA constan de varios componentes técnicos interconectados que trabajan en conjunto para proporcionar capacidades de búsqueda integradas.
Motor de Procesamiento de Consultas: El componente central que recibe las consultas de los usuarios y orquesta el flujo de trabajo federado. Incluye módulos de análisis, comprensión semántica y reconocimiento de intención. Implementaciones avanzadas utilizan modelos de lenguaje basados en transformadores para entender consultas complejas e intenciones implícitas.
Registro de Fuentes y Gestión de Metadatos: Mantiene metadatos completos sobre las fuentes disponibles, como información de esquemas, características de contenido, frecuencia de actualización, patrones de disponibilidad y métricas de rendimiento. Este registro posibilita la selección inteligente de fuentes y la optimización de consultas. Modelos de aprendizaje automático analizan patrones históricos para predecir la relevancia de fuentes ante nuevas consultas.
Módulo de Selección Inteligente de Fuentes: Utiliza clasificadores de aprendizaje automático para determinar qué fuentes tienen más probabilidades de contener información relevante para una consulta. Considera cobertura de contenido, tasas históricas de éxito, disponibilidad y tiempos de respuesta estimados. Sistemas avanzados emplean aprendizaje por refuerzo para optimizar estrategias de selección de fuentes según los resultados obtenidos.
Capa de Traducción y Adaptación de Consultas: Convierte consultas de usuario en formatos y lenguajes específicos de cada fuente. Incluye generación de SQL para bases relacionales, SPARQL para grafos, llamadas REST para APIs y consultas en lenguaje natural para texto no estructurado. El mapeo semántico asegura que se mantenga la intención de la consulta en diferentes modelos de datos.
Coordinador de Ejecución Distribuida: Gestiona la ejecución paralela de consultas en múltiples fuentes, controlando tiempos de espera, balanceo de carga y recuperación ante fallos. Implementa estrategias adaptativas de timeout según patrones de respuesta y carga del sistema.
Motor de Normalización de Resultados: Convierte los resultados de fuentes heterogéneas a un formato común para su agregación y ranking. Incluye alineación de esquemas, conversión de tipos de datos y estandarización de formatos. Gestiona campos ausentes, datos conflictivos y diferencias estructurales.
Módulo de Enriquecimiento Semántico: Enriquece los resultados con contexto y semántica adicional. Incluye enlazado de entidades a bases de conocimiento, etiquetado semántico con ontologías y extracción de relaciones en texto no estructurado. Estos enriquecimientos mejoran la precisión del ranking y la comprensibilidad de los resultados.
Modelo Learning-to-Rank: Modelo de aprendizaje automático entrenado con pares consulta-resultado históricos para predecir relevancia. Considera cientos de características como credibilidad de la fuente, frescura del contenido, alineación con el perfil de usuario y similitud semántica. Implementaciones modernas usan boosting o modelos neuronales de ranking.
Motor de Deduplicación: Identifica y elimina resultados duplicados o casi duplicados entre fuentes. Utiliza métricas de similitud como coincidencia exacta, comparación difusa y similitud semántica basada en embeddings.
Motor de Personalización: Personaliza el orden de resultados según el perfil del usuario, preferencias históricas e información contextual. Implementa filtrado colaborativo y técnicas de recomendación basadas en contenido para mejorar la relevancia individual.
Capa de Caché y Optimización: Aplica estrategias inteligentes de caché para reducir consultas redundantes. Incluye caché de resultados de consulta, metadatos de fuentes y patrones aprendidos para anticipar necesidades futuras.
Módulo de Monitorización y Analítica: Supervisa el rendimiento del sistema, la fiabilidad de fuentes, patrones de consultas y métricas de calidad de resultados. Esta información retroalimenta los componentes de optimización para la mejora continua.
Sanidad e Investigación Médica: La búsqueda federada integra historiales de pacientes entre sistemas hospitalarios, bases de datos de investigación, registros de ensayos clínicos y repositorios de literatura médica. Los médicos pueden consultar historiales integrales sin centralizar datos sensibles. Los investigadores acceden a datos clínicos distribuidos cumpliendo HIPAA y privacidad.
Servicios Financieros: Bancos y firmas de inversión utilizan la búsqueda federada para consultar datos de mercado, información regulatoria y registros internos de transacciones simultáneamente. Permite evaluación de riesgos, monitoreo de cumplimiento y análisis de mercado en tiempo real sin consolidar datos financieros sensibles.
Legal y Cumplimiento: Firmas legales y departamentos corporativos buscan en bases de jurisprudencia, repositorios regulatorios, sistemas internos y bases de contratos. La búsqueda federada facilita una investigación legal integral preservando el privilegio abogado-cliente y la confidencialidad documental.
E-Commerce y Retail: Comercios online integran catálogos de productos entre almacenes, sistemas de proveedores y plataformas de marketplace. La búsqueda federada posibilita el descubrimiento unificado de productos mientras los proveedores mantienen sistemas e inventarios independientes.
Gobierno y Administración Pública: Agencias gubernamentales buscan en bases distribuidas como datos censales, registros fiscales, sistemas de permisos y documentos públicos sin centralizar información sensible de ciudadanos. Facilita servicios públicos integrales manteniendo seguridad y privacidad.
Manufactura y Cadena de Suministro: Fabricantes integran bases de proveedores, sistemas de inventarios, registros de producción y plataformas logísticas. La búsqueda federada otorga visibilidad de cadena de suministro permitiendo a los socios mantener sistemas e información propietaria independiente.
Educación e Investigación: Universidades buscan en repositorios institucionales, bibliotecas, bases de investigación y publicaciones abiertas. Permite descubrimiento académico integral respetando la autonomía institucional y derechos de propiedad intelectual.
Telecomunicaciones: Proveedores consultan bases de clientes, registros de infraestructura, sistemas de facturación y catálogos de servicios. La búsqueda federada permite atención al cliente unificada manteniendo sistemas independientes por líneas y regiones.
Energía y Utilities: Compañías energéticas buscan entre instalaciones de generación, redes de distribución, bases de clientes y sistemas regulatorios. La búsqueda federada otorga visibilidad operativa permitiendo a operadores regionales mantener sistemas independientes.
Medios y Publicación: Organizaciones de medios buscan en repositorios de contenido, archivos, sistemas de derechos y plataformas de distribución. Permite descubrimiento integral de contenido preservando la propiedad y restricciones de licencia.
Heterogeneidad de Fuentes y Complejidad de Integración: Integrar fuentes diversas con esquemas, lenguajes de consulta y protocolos distintos requiere gran esfuerzo de ingeniería. El mapeo de esquemas y alineación semántica siguen siendo desafíos, especialmente si las fuentes representan conceptos de manera diferente.
Latencia de Consulta y Rendimiento: La búsqueda federada implica consultar múltiples fuentes, introduciendo mayor latencia que los sistemas centralizados. Fuentes lentas o no disponibles pueden degradar el rendimiento global. La gestión de tiempos de espera debe equilibrar integridad y rapidez.
Fiabilidad y Disponibilidad de Fuentes: Los sistemas federados dependen de que las fuentes externas estén disponibles y respondan. Fallos de red, caídas de fuentes o degradación afectan directamente la calidad de búsqueda. Se requiere degradación controlada si las fuentes fallan.
Calidad de Resultados y Precisión de Ranking: Agregar resultados de fuentes con diferentes niveles de calidad, cobertura y criterios de relevancia es complejo. Los modelos de ranking deben considerar variaciones en la credibilidad de fuentes y evitar sesgos hacia ciertas fuentes.
Frescura y Consistencia de Datos: El acceso es a datos actuales, pero las fuentes pueden tener distintas frecuencias de actualización y garantías de consistencia. Reconciliar información conflictiva requiere estrategias sofisticadas de resolución de conflictos.
Limitaciones de Escalabilidad: A medida que crecen las fuentes, aumenta la sobrecarga de coordinación. Seleccionar fuentes relevantes entre miles de opciones se vuelve costoso computacionalmente. La ejecución paralela a gran escala exige infraestructura robusta.
Seguridad y Control de Acceso: Deben aplicarse controles de acceso a nivel de fuente y ofrecer interfaces unificadas. Asegurar que los usuarios vean solo lo autorizado en múltiples fuentes es complejo, especialmente en entornos multi-tenant.
Privacidad y Protección de Datos: Debe cumplirse con normativas como GDPR, CCPA y requisitos sectoriales. Evitar filtraciones de datos sensibles mediante agregación o análisis de metadatos requiere diseño cuidadoso.
Descubrimiento y Gestión de Fuentes: Identificar, catalogar y mantener fuentes disponibles, metadatos precisos y gestionar el ciclo de vida (alta, baja, actualización) exige esfuerzo operativo continuo.
Interoperabilidad Semántica: Lograr interoperabilidad semántica real entre fuentes con diferentes ontologías y modelos de datos sigue siendo un reto. Las técnicas automáticas de mapeo y resolución de entidades tienen limitaciones.
Coste de Coordinación: Aunque elimina costes de consolidación de datos, la búsqueda federada introduce sobrecarga de coordinación. Gestionar ejecución distribuida, fallos y optimizar el enrutamiento de consultas exige infraestructura sofisticada.
Estandarización Limitada: La falta de estándares universales para protocolos e interfaces federados dificulta la integración y favorece el lock-in de proveedores.
Búsqueda Federada de IA vs. Almacenamiento de Datos: El almacenamiento centraliza datos de múltiples fuentes para consultas rápidas pero requiere esfuerzo ETL y genera latencia. La búsqueda federada consulta fuentes directamente, dando acceso en tiempo real pero con mayor latencia. El almacenamiento es para análisis históricos; la federada sobresale en descubrimiento actual.
Búsqueda Federada de IA vs. Data Lakes: Los data lakes almacenan datos brutos de múltiples fuentes en un lugar central con mínima transformación. Son flexibles pero requieren mucho almacenamiento y gobernanza. La búsqueda federada evita la consolidación y preserva la autonomía, requiriendo procesamiento de consultas más sofisticado.
Búsqueda Federada de IA vs. APIs y Microservicios: Las APIs ofrecen acceso programático a servicios individuales pero requieren conocimiento explícito de cada interfaz. La búsqueda federada abstrae detalles específicos, permitiendo consultas unificadas. Las APIs son para integración entre aplicaciones; la federada permite descubrimiento entre servicios.
Búsqueda Federada de IA vs. Grafos de Conocimiento: Los grafos de conocimiento representan información como entidades y relaciones, permitiendo razonamiento semántico. La búsqueda federada puede consultar grafos distribuidos, pero sin requerir un grafo centralizado. Los grafos ofrecen comprensión profunda; la federada prioriza la autonomía de fuentes.
Búsqueda Federada de IA vs. Motores de Búsqueda: Los motores tradicionales mantienen índices centralizados de contenido rastreado. La búsqueda federada consulta fuentes directamente, sin pre-indexación. Los motores cubren contenido público; la federada integra fuentes privadas, propietarias o especializadas.
Búsqueda Federada de IA vs. Gestión Maestra de Datos (MDM): Los sistemas MDM consolidan datos creando registros maestros. La búsqueda federada consulta fuentes sin crear dichos registros. El MDM es para gobernanza y consistencia; la federada enfatiza autonomía y acceso en tiempo real.
Búsqueda Federada de IA vs. Búsqueda Empresarial: La búsqueda empresarial indexa documentos y bases internas en un índice central. La federada consulta fuentes directamente, sin indexar. La empresarial es rápida en texto completo; la federada soporta diversidad y actualizaciones en tiempo real.
Búsqueda Federada de IA vs. Blockchain y Ledgers Distribuidos: Blockchain mantiene consenso distribuido, asegurando integridad e inmutabilidad. La federada coordina consultas entre fuentes independientes sin consenso. Blockchain es para confianza y verificación; la federada para descubrimiento de información.
Evaluación Exhaustiva de Fuentes: Antes de integrar, evalúa calidad de datos, frecuencia de actualización, disponibilidad, complejidad de esquema y protocolos de acceso. Esta evaluación guía los algoritmos de selección y las expectativas de rendimiento.
Integración Incremental: Comienza con pocas fuentes bien conocidas y expande gradualmente. Así se adquiere experiencia, se detectan desafíos temprano y se perfeccionan procesos antes de escalar.
Gestión Robusta de Metadatos: Invierte en metadatos completos de fuentes: esquemas, cobertura, métricas de calidad y rendimiento. Mantén la precisión mediante monitorización y validaciones periódicas.
Selección Inteligente de Fuentes: Implementa selección basada en aprendizaje automático que aprende de los resultados de consulta. Rastrea qué fuentes son más relevantes para cada tipo de consulta y optimiza estrategias continuamente.
Gestión Adaptativa de Tiempos de Espera: Adapta los tiempos de espera según patrones de respuesta y carga. Evita tiempos fijos que esperen demasiado a fuentes lentas o abandonen prematuramente a fuentes rápidas.
Aseguramiento de Calidad de Resultados: Establece métricas de calidad como relevancia, frescura y completitud. Implementa mecanismos de feedback de usuarios para alimentar los modelos de ranking.
Monitorización Integral: Supervisa disponibilidad de fuentes, tiempos de respuesta, calidad y satisfacción de usuarios. Usa estos datos para identificar problemas, optimizar rutas de consulta y mejorar el sistema.
Seguridad y Control de Acceso: Aplica controles de acceso a nivel de fuente que hagan cumplir políticas de autorización en todo el sistema. Asegúrate de que los usuarios solo accedan a lo autorizado, incluso consultando múltiples fuentes.
Estrategias de Caché: Implementa caché inteligente a varios niveles: resultados de consulta, metadatos de fuentes y patrones aprendidos. Equilibra frescura y rendimiento.
Optimización de Experiencia de Usuario: Diseña interfaces que comuniquen claramente el origen, nivel de confianza y frescura de los resultados. Da transparencia sobre qué fuentes se consultaron y por qué ciertos resultados se clasifican más alto.
Optimización de Rendimiento: Perfila la ejecución de consultas para identificar cuellos de botella. Optimiza selección de fuentes, traducción y agregación. Considera precomputar patrones de consulta comunes.
Aprendizaje Continuo: Implementa ciclos de feedback que capturen interacciones de usuarios. Usa esos datos para mejorar la selección de fuentes, modelos de ranking y presentación de resultados.
Documentación y Gobernanza: Mantén documentación completa de fuentes, enfoques de integración y arquitectura. Establece políticas para alta, baja y modificación de fuentes.
Pruebas y Validación: Implementa pruebas unitarias, de integración y de extremo a extremo para validar calidad de resultados respecto a una verdad base conocida.
Comprensión Avanzada de Lenguaje Natural: Los sistemas federados futuros usarán modelos de lenguaje grandes y PLN avanzado para comprender consultas complejas y contextos implícitos, permitiendo selección e interpretación más precisa de fuentes y resultados.
Descubrimiento Autónomo de Fuentes: Sistemas de aprendizaje automático descubrirán y catalogarán fuentes disponibles, evaluarán relevancia y calidad, e integrarán con mínima intervención humana, resolviendo el reto actual de gestión manual.
Integración con la Web Semántica: A medida que maduren tecnologías semánticas, los sistemas federados aprovecharán ontologías y estándares de linked data para interoperabilidad semántica profunda, permitiendo razonamiento sofisticado y manejo de modelos heterogéneos.
IA Explicable y Transparencia: Los sistemas ofrecerán explicaciones detalladas sobre decisiones de ranking, selección de fuentes y agregación, construyendo confianza y comprensión del usuario.
Integración de Aprendizaje Federado: Técnicas de aprendizaje federado permitirán entrenar modelos de IA sobre fuentes distribuidas sin centralizar los datos, combinando autonomía y capacidad predictiva.
Integración de Streams en Tiempo Real: Los sistemas federados integrarán cada vez más flujos de datos en tiempo real junto a bases tradicionales, permitiendo búsqueda sobre información en continua actualización.
Búsqueda Multimodal: Los sistemas federados futuros buscarán entre texto, imágenes, video y audio. Modelos de IA multimodal habilitarán búsqueda y síntesis de resultados entre modalidades.
Personalización y Conciencia de Contexto: Modelado avanzado de usuarios y comprensión de contexto permitirán experiencias altamente personalizadas, entendiendo nivel de experiencia, necesidades y preferencias.
Aplicaciones de Computación Cuántica: A medida que madure, los sistemas federados podrán usar algoritmos cuánticos para optimización de selección de fuentes y ranking, acelerando el procesamiento de consultas.
Integración Blockchain: La federada podrá integrar blockchain para verificación de fuentes, trazabilidad de resultados y coordinación descentralizada en aplicaciones críticas para la confianza.
Edge Computing y Procesamiento Distribuido: La búsqueda federada aprovechará el edge computing para procesar consultas cerca de las fuentes, reduciendo latencia y mejorando privacidad.
Optimización Autónoma: Sistemas federados auto-optimizables aprenderán continuamente de patrones, características de fuentes y feedback de usuarios para mejorar el rendimiento sin intervención humana.
Integración de Conocimiento entre Dominios: Los sistemas futuros integrarán conocimiento entre dominios tradicionalmente separados, permitiendo descubrimiento de conexiones e insights inesperados combinando fuentes diversas.
La búsqueda centralizada tradicional consolida todos los datos en un solo repositorio indexado, requiriendo migración de datos e introduciendo latencia. La búsqueda federada de IA consulta múltiples fuentes independientes directamente en tiempo real sin mover ni duplicar datos, preservando la autonomía de la fuente y proporcionando acceso unificado. Esto hace que la búsqueda federada sea ideal para organizaciones con fuentes de datos distribuidas y requisitos estrictos de gobernanza de datos.
La búsqueda federada de IA mantiene los datos en su ubicación original y respeta los controles de acceso y políticas de seguridad de cada fuente. Los usuarios solo acceden a la información para la que están autorizados, y los datos sensibles nunca salen de su sistema de origen. Este enfoque simplifica el cumplimiento de regulaciones como GDPR y HIPAA al eliminar los riesgos asociados con la centralización de información sensible.
Los principales desafíos incluyen gestionar fuentes de datos heterogéneas con diferentes esquemas y formatos, manejar la latencia de consulta de múltiples fuentes, asegurar una clasificación coherente de resultados entre fuentes y mantener la fiabilidad del sistema cuando las fuentes no están disponibles. Las organizaciones también deben invertir en una gestión robusta de metadatos y en algoritmos inteligentes de selección de fuentes para optimizar el rendimiento.
Sí, la búsqueda federada de IA escala añadiendo nuevas fuentes sin requerir migración de datos ni reestructuración de almacenes. Sin embargo, a medida que aumenta el número de fuentes, crece la sobrecarga de coordinación de consultas. Los sistemas modernos utilizan aprendizaje automático para la selección inteligente de fuentes e implementan estrategias de caché para mantener el rendimiento a escala.
El almacenamiento de datos consolida la información en un repositorio centralizado, permitiendo consultas rápidas pero requiriendo un esfuerzo significativo de ETL y generando latencia de datos. La búsqueda federada consulta las fuentes directamente, proporcionando acceso en tiempo real pero con mayor latencia de consulta. El almacenamiento es adecuado para análisis históricos y reportes, mientras que la búsqueda federada es óptima para el descubrimiento de información actual en fuentes distribuidas.
Sanidad, finanzas, comercio electrónico, gobierno y organizaciones de investigación se benefician significativamente de la búsqueda federada. Sanidad la utiliza para integrar historiales de pacientes entre proveedores, finanzas para cumplimiento y evaluación de riesgos, comercio electrónico para descubrimiento unificado de productos y organizaciones de investigación para buscar en bases de datos académicas distribuidas.
La IA mejora la búsqueda federada mediante procesamiento de lenguaje natural para entender consultas, aprendizaje automático para selección inteligente de fuentes, análisis semántico para mejor clasificación de resultados y deduplicación automatizada. Los modelos de IA aprenden de los patrones de consultas para optimizar continuamente la selección de fuentes y la agregación de resultados, mejorando el rendimiento del sistema con el tiempo.
La comprensión semántica permite a los sistemas federados comprender la intención de la consulta más allá de la coincidencia de palabras clave, identificar fuentes relevantes con mayor precisión y clasificar resultados según el significado y no solo por coincidencias de palabras. Esto incluye reconocimiento de entidades, extracción de relaciones e integración con grafos de conocimiento, resultando en resultados de búsqueda más relevantes y contextualmente apropiados.
AmICited rastrea cómo sistemas de IA como ChatGPT, Perplexity y Google AI Overviews citan y mencionan tu marca. Comprende tu visibilidad en IA y optimiza tu presencia en respuestas generadas por IA.
Descubre cómo los sistemas de búsqueda de IA multimodal procesan texto, imágenes, audio y video juntos para ofrecer resultados más precisos y relevantes en cont...

Descubre cómo la búsqueda semántica utiliza la IA para comprender la intención y el contexto del usuario. Aprende en qué se diferencia de la búsqueda por palabr...
Estrategia de búsqueda empresarial con IA: integración, gobernanza, métricas de ROI. Descubre cómo las grandes organizaciones implementan plataformas de búsqued...