
Cobertura de Índice de IA
Descubre qué es la Cobertura de Índice de IA y por qué es importante para la visibilidad de tu marca en ChatGPT, Google AI Overviews y Perplexity. Descubre fact...
10 min de lectura

La cobertura de índice se refiere al porcentaje y estado de las páginas de un sitio web que han sido descubiertas, rastreadas e incluidas en el índice de un motor de búsqueda. Mide qué páginas son elegibles para aparecer en los resultados de búsqueda e identifica problemas técnicos que impiden la indexación.
La cobertura de índice se refiere al porcentaje y estado de las páginas de un sitio web que han sido descubiertas, rastreadas e incluidas en el índice de un motor de búsqueda. Mide qué páginas son elegibles para aparecer en los resultados de búsqueda e identifica problemas técnicos que impiden la indexación.
Cobertura de índice es la medida de cuántas páginas de tu sitio web han sido descubiertas, rastreadas e incluidas en el índice de un motor de búsqueda. Representa el porcentaje de páginas de tu sitio que son elegibles para aparecer en los resultados de búsqueda e identifica qué páginas están experimentando problemas técnicos que impiden la indexación. En esencia, la cobertura de índice responde a la pregunta crítica: “¿Cuánto de mi sitio web pueden realmente encontrar y posicionar los motores de búsqueda?” Esta métrica es fundamental para entender la visibilidad de tu sitio web en los motores de búsqueda y se controla mediante herramientas como Google Search Console, que ofrece informes detallados sobre páginas indexadas, excluidas y con errores. Sin una cobertura de índice adecuada, incluso el contenido mejor optimizado permanece invisible tanto para los motores de búsqueda como para los usuarios que buscan tu información.
La cobertura de índice no se trata simplemente de cantidad, sino de garantizar que se indexen las páginas correctas. Un sitio web puede tener miles de páginas, pero si muchas son duplicadas, de contenido escaso o están bloqueadas por robots.txt, la cobertura de índice real podría ser significativamente menor de lo esperado. Esta distinción entre el total de páginas y las páginas indexadas es crucial para desarrollar una estrategia SEO efectiva. Las organizaciones que monitorean la cobertura de índice con regularidad pueden identificar y corregir problemas técnicos antes de que afecten el tráfico orgánico, convirtiéndola en una de las métricas más accionables en SEO técnico.
El concepto de cobertura de índice surgió a medida que los motores de búsqueda evolucionaron de simples rastreadores a sofisticados sistemas capaces de procesar millones de páginas diariamente. En los primeros días del SEO, los webmasters tenían poca visibilidad sobre cómo los motores de búsqueda interactuaban con sus sitios. Google Search Console, lanzado originalmente como Google Webmaster Tools en 2006, revolucionó esta transparencia al proporcionar retroalimentación directa sobre el estado de rastreo e indexación. El Informe de cobertura de índice (anteriormente denominado “Informe de indexación de páginas”) se convirtió en la herramienta principal para entender qué páginas había indexado Google y por qué otras eran excluidas.
A medida que los sitios web se volvieron más complejos con contenido dinámico, parámetros y páginas duplicadas, los problemas de cobertura de índice se hicieron cada vez más comunes. Las investigaciones indican que aproximadamente el 40-60% de los sitios web tienen problemas significativos de cobertura de índice, con muchas páginas permaneciendo sin descubrir o excluidas deliberadamente del índice. El auge de los sitios web con JavaScript y las aplicaciones de una sola página complicó aún más la indexación, ya que los motores de búsqueda necesitaban renderizar el contenido antes de determinar su indexabilidad. Hoy en día, la monitorización de la cobertura de índice es esencial para cualquier organización que dependa del tráfico orgánico, y los expertos de la industria recomiendan auditorías mensuales como mínimo.
La relación entre la cobertura de índice y el presupuesto de rastreo se ha vuelto cada vez más importante a medida que los sitios web escalan. El presupuesto de rastreo se refiere al número de páginas que Googlebot rastreará en tu sitio en un periodo determinado. Los sitios grandes con mala arquitectura o contenido duplicado en exceso pueden desperdiciar el presupuesto de rastreo en páginas de poco valor, dejando contenido importante sin descubrir. Los estudios muestran que más del 78% de las empresas utilizan algún tipo de herramienta de monitorización de contenido para rastrear su visibilidad en motores de búsqueda y plataformas de IA, reconociendo que la cobertura de índice es fundamental para cualquier estrategia de visibilidad.
| Concepto | Definición | Control principal | Herramientas utilizadas | Impacto en rankings |
|---|---|---|---|---|
| Cobertura de índice | Porcentaje de páginas indexadas por motores de búsqueda | Metaetiquetas, robots.txt, calidad del contenido | Google Search Console, Bing Webmaster Tools | Directo—solo las páginas indexadas pueden posicionar |
| Rastreabilidad | Capacidad de los bots para acceder y navegar por las páginas | robots.txt, estructura del sitio, enlaces internos | Screaming Frog, ZentroAudit, registros del servidor | Indirecto—las páginas deben ser rastreables para ser indexadas |
| Indexabilidad | Capacidad de las páginas rastreadas para añadirse al índice | Directivas noindex, etiquetas canónicas, contenido | Google Search Console, herramienta de inspección de URLs | Directo—determina si las páginas aparecen en resultados |
| Presupuesto de rastreo | Número de páginas que Googlebot rastrea en un periodo | Autoridad del sitio, calidad de página, errores de rastreo | Google Search Console, registros del servidor | Indirecto—afecta a qué páginas se les da prioridad de rastreo |
| Contenido duplicado | Varias páginas con contenido idéntico o similar | Etiquetas canónicas, redirecciones 301, noindex | Herramientas de auditoría SEO, revisión manual | Negativo—diluye el potencial de posicionamiento |
La cobertura de índice opera mediante un proceso de tres etapas: descubrimiento, rastreo e indexación. En la fase de descubrimiento, los motores de búsqueda encuentran URLs a través de diversos medios como sitemaps XML, enlaces internos, backlinks externos y envíos directos mediante Google Search Console. Una vez descubiertas, las URLs se ponen en cola para su rastreo, donde Googlebot solicita la página y analiza su contenido. Finalmente, durante la indexación, Google procesa el contenido de la página, determina su relevancia y calidad, y decide si la incluye en el índice de búsqueda.
El Informe de cobertura de índice en Google Search Console categoriza las páginas en cuatro estados principales: Válidas (páginas indexadas), Válidas con advertencias (indexadas pero con problemas), Excluidas (intencionalmente no indexadas) y Error (páginas que no pudieron ser indexadas). Dentro de cada estado existen tipos de problemas específicos que brindan información detallada sobre por qué las páginas están o no indexadas. Por ejemplo, las páginas pueden excluirse porque contienen una metaetiqueta noindex, están bloqueadas por robots.txt, son duplicadas sin etiquetas canónicas adecuadas o devuelven códigos de estado HTTP 4xx o 5xx.
Comprender los mecanismos técnicos detrás de la cobertura de índice requiere conocer varios componentes clave. El archivo robots.txt es un archivo de texto en el directorio raíz de tu sitio que indica a los rastreadores qué directorios y archivos pueden o no pueden acceder. Una configuración incorrecta de robots.txt es una de las causas más comunes de problemas de cobertura de índice—bloquear accidentalmente directorios importantes impide que Google incluso descubra esas páginas. La metaetiqueta robots, ubicada en la sección head del HTML de una página, brinda instrucciones a nivel de página usando directivas como index, noindex, follow y nofollow. La etiqueta canónica (rel=“canonical”) indica a los motores de búsqueda cuál versión de una página es la preferida cuando existen duplicados, previniendo sobrecarga del índice y consolidando señales de posicionamiento.
Para las empresas que dependen del tráfico orgánico, la cobertura de índice impacta directamente en los ingresos y la visibilidad. Cuando las páginas importantes no están indexadas, no pueden aparecer en los resultados de búsqueda, lo que significa que los clientes potenciales no pueden encontrarlas a través de Google. Sitios de comercio electrónico con mala cobertura de índice pueden tener páginas de productos atascadas en el estado “Descubierta, actualmente no indexada”, lo que resulta en ventas perdidas. Plataformas de marketing de contenidos con miles de artículos necesitan una cobertura de índice robusta para asegurar que su contenido llegue a la audiencia. Las empresas SaaS dependen de documentación y blogs indexados para captar leads orgánicos.
Las implicaciones prácticas van más allá de la búsqueda tradicional. Con el auge de plataformas de IA generativa como ChatGPT, Perplexity y Google AI Overviews, la cobertura de índice también se ha vuelto relevante para la visibilidad en IA. Estos sistemas suelen basarse en contenido web indexado para datos de entrenamiento y fuentes de citación. Si tus páginas no están correctamente indexadas por Google, es menos probable que se incluyan en los conjuntos de datos de entrenamiento de IA o sean citadas en respuestas generadas por IA. Esto crea un problema de visibilidad acumulativo: una mala cobertura de índice afecta tanto al posicionamiento en buscadores tradicionales como a la visibilidad en contenidos generados por IA.
Las organizaciones que monitorean proactivamente la cobertura de índice ven mejoras medibles en el tráfico orgánico. Un escenario típico implica descubrir que el 30-40% de las URLs enviadas están excluidas debido a etiquetas noindex, contenido duplicado o errores de rastreo. Tras la corrección—eliminación de etiquetas noindex innecesarias, implementación de canónicas adecuadas y solución de errores de rastreo—la cantidad de páginas indexadas suele aumentar entre un 20 y un 50%, correlacionándose directamente con una mejor visibilidad orgánica. El costo de la inacción es significativo: cada mes que una página permanece sin indexar es un mes de tráfico y conversiones potenciales perdidos.
Google Search Console sigue siendo la herramienta principal para monitorizar la cobertura de índice, proporcionando los datos más confiables sobre las decisiones de indexación de Google. El Informe de cobertura de índice muestra páginas indexadas, con advertencias, excluidas y con errores, con desgloses detallados de tipos de problemas específicos. Google también ofrece la herramienta de inspección de URLs, que permite verificar el estado de indexación de páginas individuales y solicitar la indexación de contenido nuevo o actualizado. Esta herramienta es invaluable para solucionar problemas concretos y entender por qué Google no ha indexado determinadas páginas.
Bing Webmaster Tools ofrece funcionalidades similares a través de su Index Explorer y envío de URLs. Aunque la cuota de mercado de Bing es menor que la de Google, sigue siendo importante para llegar a usuarios que prefieren esta búsqueda. Los datos de cobertura de índice de Bing a veces difieren de los de Google, revelando problemas específicos de los algoritmos de rastreo o indexación de Bing. Las organizaciones con sitios grandes deberían monitorear ambas plataformas para asegurar una cobertura integral.
Para la monitorización de IA y visibilidad de marca, plataformas como AmICited rastrean cómo aparece tu marca y dominio en ChatGPT, Perplexity, Google AI Overviews y Claude. Estas plataformas correlacionan la cobertura de índice tradicional con la visibilidad en IA, ayudando a las organizaciones a comprender cómo su contenido indexado se traduce en menciones en respuestas generadas por IA. Esta integración es crucial para la estrategia SEO moderna, ya que la visibilidad en sistemas de IA influye cada vez más en el reconocimiento de marca y el tráfico.
Las herramientas de auditoría SEO de terceros como Ahrefs, SEMrush y Screaming Frog proporcionan información adicional sobre la cobertura de índice rastreando tu sitio de manera independiente y comparando sus hallazgos con la cobertura de índice reportada por Google. Las discrepancias entre tu rastreo y el de Google pueden revelar problemas como renderizado de JavaScript, problemas del lado del servidor o limitaciones del presupuesto de rastreo. Estas herramientas también identifican páginas huérfanas (sin enlaces internos), que suelen tener dificultades de indexación.
Mejorar la cobertura de índice requiere un enfoque sistemático que aborde tanto problemas técnicos como estratégicos. Primero, audita tu estado actual usando el Informe de cobertura de índice de Google Search Console. Identifica los principales tipos de problemas que afectan tu sitio—etiquetas noindex, bloqueos en robots.txt, contenido duplicado o errores de rastreo. Prioriza los problemas según su impacto: las páginas que deberían estar indexadas pero no lo están tienen mayor prioridad que las que están correctamente excluidas.
Segundo, corrige las configuraciones erróneas de robots.txt revisando tu archivo robots.txt y asegurándote de no bloquear accidentalmente directorios importantes. Un error común es bloquear /admin/, /staging/ o /temp/ (que sí deberían bloquearse), pero también bloquear accidentalmente /blog/, /productos/ u otro contenido público. Usa el probador de robots.txt de Google Search Console para verificar que las páginas importantes no estén bloqueadas.
Tercero, implementa canónicas adecuadas para el contenido duplicado. Si tienes varias URLs que muestran contenido similar (por ejemplo, páginas de producto accesibles por diferentes rutas de categorías), implementa canónicas autorreferenciales en cada página o usa redirecciones 301 para consolidar en una sola versión. Esto previene la sobrecarga del índice y consolida las señales de posicionamiento en la versión preferida.
Cuarto, elimina etiquetas noindex innecesarias de las páginas que deseas indexar. Audita tu sitio en busca de directivas noindex, especialmente en entornos de pruebas que puedan haberse desplegado accidentalmente en producción. Usa la herramienta de inspección de URLs para verificar que las páginas importantes no tengan etiquetas noindex.
Quinto, envía un sitemap XML a Google Search Console que contenga solo URLs indexables. Mantén tu sitemap limpio excluyendo páginas con etiquetas noindex, redirecciones o errores 404. Para sitios grandes, considera dividir los sitemaps por tipo de contenido o sección para mantener una mejor organización y recibir informes de errores más detallados.
Sexto, corrige errores de rastreo incluyendo enlaces rotos (404), errores de servidor (5xx) y cadenas de redirección. Usa Google Search Console para identificar las páginas afectadas y resuelve sistemáticamente cada problema. Para errores 404 en páginas importantes, restaura el contenido o implementa redirecciones 301 a alternativas relevantes.
El futuro de la cobertura de índice está evolucionando junto con los cambios en la tecnología de búsqueda y la aparición de sistemas de IA generativa. A medida que Google sigue perfeccionando sus requisitos de Core Web Vitals y los estándares E-E-A-T (Experiencia, Especialización, Autoridad, Confianza), la cobertura de índice dependerá cada vez más de la calidad del contenido y métricas de experiencia de usuario. Las páginas con malos Core Web Vitals o contenido escaso pueden enfrentar desafíos de indexación incluso si son técnicamente rastreables.
El auge de los resultados de búsqueda generados por IA y los motores de respuesta está transformando la importancia de la cobertura de índice. Los rankings tradicionales dependen de páginas indexadas, pero los sistemas de IA pueden citar contenido indexado de manera diferente o priorizar ciertas fuentes sobre otras. Las organizaciones deberán monitorear no solo si Google indexa sus páginas, sino también si están siendo citadas y referenciadas por plataformas de IA. Este requisito de doble visibilidad implica que la monitorización de la cobertura de índice debe ampliarse más allá de Google Search Console para incluir plataformas de monitorización de IA que rastreen menciones de marca en ChatGPT, Perplexity y otros sistemas de IA generativa.
El renderizado de JavaScript y el contenido dinámico seguirán complicando la cobertura de índice. A medida que más sitios adopten frameworks JavaScript y aplicaciones de una sola página, los motores de búsqueda deben renderizar JavaScript para entender el contenido de la página. Google ha mejorado sus capacidades de renderizado de JavaScript, pero siguen existiendo problemas. Las buenas prácticas futuras probablemente enfatizarán el renderizado del lado del servidor o el renderizado dinámico para asegurar que el contenido sea accesible inmediatamente para los rastreadores sin requerir la ejecución de JavaScript.
La integración de datos estructurados y marcado schema será cada vez más importante para la cobertura de índice. Los motores de búsqueda utilizan los datos estructurados para comprender mejor el contenido y el contexto de la página, lo que puede mejorar las decisiones de indexación. Las organizaciones que implementen marcado schema completo para sus tipos de contenido—artículos, productos, eventos, FAQs—pueden ver mejorada la cobertura de índice y una mayor visibilidad en resultados enriquecidos.
Finalmente, el concepto de cobertura de índice se expandirá más allá de las páginas para incluir entidades y temas. Más que simplemente rastrear si las páginas están indexadas, el monitoreo futuro se enfocará en si tu marca, productos y temas están debidamente representados en los gráficos de conocimiento de motores de búsqueda y en los datos de entrenamiento de IA. Esto representa un cambio fundamental del seguimiento a nivel de página a la visibilidad a nivel de entidad, requiriendo nuevos enfoques y estrategias de monitorización.
+++
La rastreabilidad se refiere a si los bots de los motores de búsqueda pueden acceder y navegar por las páginas de tu sitio web, controlado por factores como robots.txt y la estructura del sitio. Sin embargo, la indexabilidad determina si las páginas rastreadas se agregan realmente al índice del motor de búsqueda, controlado por metaetiquetas robots, etiquetas canónicas y la calidad del contenido. Una página debe ser rastreable para ser indexable, pero ser rastreable no garantiza la indexación.
Para la mayoría de los sitios web, revisar la cobertura de índice mensualmente es suficiente para detectar problemas importantes. Sin embargo, si realizas cambios significativos en la estructura del sitio, publicas nuevo contenido regularmente o llevas a cabo migraciones, monitorea el informe semanal o quincenalmente. Google envía notificaciones por correo electrónico sobre problemas urgentes, pero a menudo llegan con retraso, por lo que la monitorización proactiva es esencial para mantener una visibilidad óptima.
Este estado indica que Google ha encontrado una URL (generalmente a través de sitemaps o enlaces internos) pero aún no la ha rastreado. Esto puede ocurrir debido a limitaciones del presupuesto de rastreo, donde Google prioriza otras páginas de tu sitio. Si páginas importantes permanecen en este estado durante períodos prolongados, puede indicar problemas con el presupuesto de rastreo o baja autoridad del sitio que deben abordarse.
Sí, enviar un sitemap XML a Google Search Console ayuda a que los motores de búsqueda descubran y prioricen tus páginas para rastreo e indexación. Un sitemap bien mantenido que contenga solo URLs indexables puede mejorar significativamente la cobertura de índice al dirigir el presupuesto de rastreo de Google hacia tu contenido más importante y reducir el tiempo necesario para su descubrimiento.
Los problemas comunes incluyen páginas bloqueadas por robots.txt, metaetiquetas noindex en páginas importantes, contenido duplicado sin la canónica adecuada, errores de servidor (5xx), cadenas de redirección y contenido escaso. Además, los errores 404, los soft 404 y las páginas con requisitos de autorización (errores 401/403) aparecen frecuentemente en los informes de cobertura de índice y requieren solución para mejorar la visibilidad.
La cobertura de índice impacta directamente en si tu contenido aparece en respuestas generadas por IA de plataformas como ChatGPT, Perplexity y Google AI Overviews. Si tus páginas no están correctamente indexadas por Google, es menos probable que se incluyan en los datos de entrenamiento o sean citadas por sistemas de IA. Monitorear la cobertura de índice asegura que el contenido de tu marca sea descubrible y citable tanto en la búsqueda tradicional como en plataformas de IA generativa.
El presupuesto de rastreo es el número de páginas que Googlebot rastreará en tu sitio en un periodo determinado. Los sitios con baja eficiencia en el presupuesto de rastreo pueden tener muchas páginas atascadas en el estado 'Descubierta, actualmente no indexada'. Optimizar el presupuesto de rastreo corrigiendo errores de rastreo, eliminando URLs duplicadas y utilizando robots.txt estratégicamente garantiza que Google se enfoque en indexar tu contenido más valioso.
No, no todas las páginas deben ser indexadas. Páginas como entornos de pruebas, variantes de producto duplicadas, resultados de búsqueda internos y archivos de políticas de privacidad suelen excluirse mejor del índice utilizando etiquetas noindex o robots.txt. El objetivo es indexar solo el contenido de alto valor y único que responda a la intención del usuario y contribuya al rendimiento SEO general de tu sitio.
Comienza a rastrear cómo los chatbots de IA mencionan tu marca en ChatGPT, Perplexity y otras plataformas. Obtén información procesable para mejorar tu presencia en IA.
Descubre qué es la Cobertura de Índice de IA y por qué es importante para la visibilidad de tu marca en ChatGPT, Google AI Overviews y Perplexity. Descubre fact...
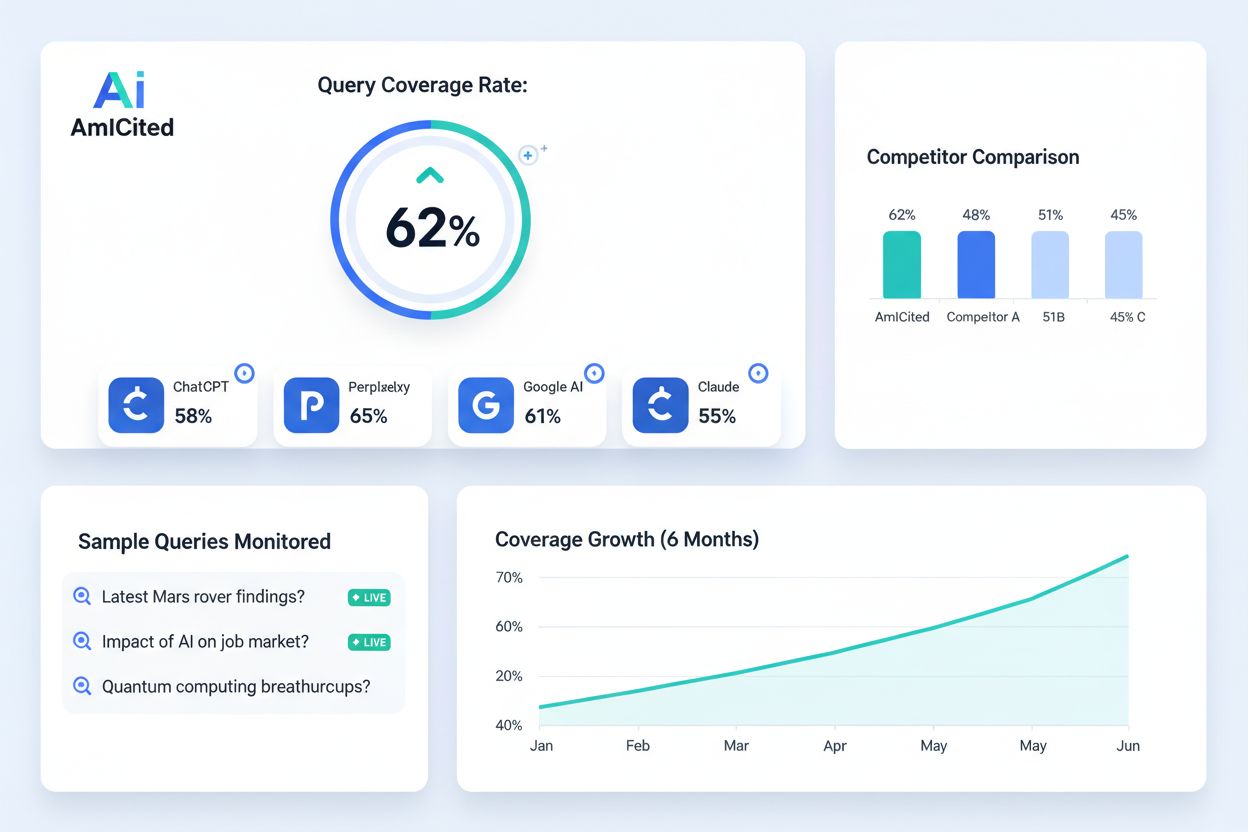
Aprende qué es la Tasa de Cobertura de Consultas, cómo medirla y por qué es crítica para la visibilidad de marca en búsquedas impulsadas por IA. Descubre refere...

La indexabilidad es la capacidad de los motores de búsqueda para incluir páginas en su índice. Descubre cómo el rastreo, factores técnicos y la calidad del cont...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.