Definición de Grafo de Conocimiento
Un grafo de conocimiento es una base de datos de información interconectada que representa entidades del mundo real—como personas, lugares, organizaciones y conceptos—y muestra las relaciones semánticas entre ellas. A diferencia de las bases de datos tradicionales que organizan la información en formatos tabulares rígidos, los grafos de conocimiento estructuran los datos como redes de nodos (entidades) y aristas (relaciones), permitiendo que los sistemas comprendan significado y contexto en vez de solo hacer coincidir palabras clave. El Grafo de Conocimiento de Google, lanzado en 2012, revolucionó la búsqueda al introducir la comprensión basada en entidades, permitiendo que el motor de búsqueda responda preguntas fácticas como “¿Cuánto mide la Torre Eiffel?” o “¿Dónde se celebraron los Juegos Olímpicos de Verano 2016?” entendiendo lo que los usuarios realmente buscan, no solo las palabras que usan. En mayo de 2024, el Grafo de Conocimiento de Google contiene más de 1.6 billones de hechos sobre 54 mil millones de entidades, representando una expansión enorme desde los 500 mil millones de hechos sobre 5 mil millones de entidades en 2020. Este crecimiento refleja la creciente importancia del conocimiento estructurado y semántico para potenciar la búsqueda moderna, los sistemas de IA y aplicaciones inteligentes en todas las industrias.
Contexto y desarrollo histórico
El concepto de grafos de conocimiento surgió tras décadas de investigación en inteligencia artificial, tecnologías de web semántica y representación del conocimiento. Sin embargo, el término ganó reconocimiento generalizado cuando Google introdujo su Grafo de Conocimiento en 2012, cambiando fundamentalmente la forma en que los motores de búsqueda entregan resultados. Antes del Grafo de Conocimiento, los motores de búsqueda usaban principalmente coincidencia de palabras clave—si buscabas “foca”, Google devolvía resultados para todos los posibles significados de la palabra, sin entender a qué entidad realmente te referías. El Grafo de Conocimiento cambió este paradigma aplicando principios de ontología—un marco formal para definir entidades, sus atributos y relaciones—a escala masiva. Este cambio de “cadenas de texto a cosas” supuso un gran avance en la tecnología de búsqueda, permitiendo a los algoritmos entender que “foca” puede referirse a un mamífero marino, un artista musical, una unidad militar o un dispositivo de seguridad, y determinar cuál es el significado más relevante según el contexto. El mercado global de grafos de conocimiento refleja esta importancia, con proyecciones de crecimiento desde 1.490 millones de dólares en 2024 hasta 6.940 millones en 2030, lo que representa una tasa de crecimiento anual compuesta de aproximadamente 35%. Este crecimiento explosivo está impulsado por la adopción empresarial en finanzas, salud, comercio minorista y gestión de cadenas de suministro, donde las organizaciones reconocen cada vez más que entender las relaciones de entidades es clave para la toma de decisiones, la detección de fraudes y la eficiencia operativa.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Cómo funcionan los grafos de conocimiento: arquitectura técnica
Los grafos de conocimiento operan mediante una sofisticada combinación de estructuras de datos, tecnologías semánticas y algoritmos de aprendizaje automático. En su núcleo, los grafos de conocimiento usan un modelo de datos estructurado en grafo compuesto por tres elementos fundamentales: nodos (que representan entidades como personas, organizaciones o conceptos), aristas (que representan relaciones entre entidades) y etiquetas (que describen la naturaleza de esas relaciones). Por ejemplo, en un grafo de conocimiento simple, “Seal” podría ser un nodo, “es-un” una etiqueta de arista y “Artista musical” otro nodo, creando la relación semántica “Seal es-un Artista musical”. Esta estructura es fundamentalmente diferente de las bases de datos relacionales, que fuerzan los datos en filas y columnas con esquemas predefinidos. Los grafos de conocimiento se construyen usando grafos de propiedades etiquetadas (que almacenan propiedades directamente en nodos y aristas) o almacenes triples RDF (Resource Description Framework) (que representan toda la información como triples sujeto-predicado-objeto). El poder de los grafos de conocimiento surge de su capacidad para integrar datos de múltiples fuentes con diferentes estructuras y formatos. Cuando se ingieren datos en un grafo de conocimiento, los procesos de enriquecimiento semántico utilizan procesamiento de lenguaje natural (PLN) y aprendizaje automático para identificar entidades, extraer relaciones y comprender el contexto. Esto permite a los grafos de conocimiento reconocer automáticamente que “IBM”, “International Business Machines” y “Big Blue” se refieren a la misma entidad, y entender cómo esa entidad se relaciona con otras como “Watson”, “Computación en la nube” e “Inteligencia artificial”. La estructura resultante permite consultas sofisticadas y razonamiento que serían imposibles en bases de datos tradicionales, permitiendo a los sistemas responder preguntas complejas al recorrer relaciones e inferir nuevo conocimiento a partir de conexiones existentes.
Grafo de conocimiento vs. bases de datos tradicionales: tabla comparativa
| Aspecto | Grafo de conocimiento | Base de datos relacional tradicional | Base de datos de grafos |
|---|
| Estructura de datos | Nodos, aristas y etiquetas que representan entidades y relaciones | Tablas, filas y columnas con esquemas predefinidos | Nodos y aristas optimizados para el recorrido de relaciones |
| Flexibilidad de esquema | Muy flexible; evoluciona a medida que se descubre nueva información | Rígido; requiere definir el esquema antes de ingresar datos | Flexible; soporta evolución dinámica del esquema |
| Gestión de relaciones | Soporte nativo para relaciones complejas y de múltiples saltos | Requiere uniones entre varias tablas; costoso computacionalmente | Optimizado para consultas eficientes de relaciones |
| Lenguaje de consulta | SPARQL (para RDF), Cypher (para grafos de propiedades), o APIs personalizadas | SQL | Cypher, Gremlin o SPARQL |
| Comprensión semántica | Énfasis en significado y contexto mediante ontologías | Enfocado en almacenamiento y recuperación de datos | Enfocado en recorridos eficientes y patrones |
| Casos de uso | Búsqueda semántica, descubrimiento de conocimiento, sistemas de IA, resolución de entidades | Transacciones empresariales, informes, sistemas OLTP | Motores de recomendación, detección de fraude, análisis de redes |
| Integración de datos | Excelente para integrar datos heterogéneos de múltiples fuentes | Requiere ETL y transformación de datos significativos | Bueno para datos conectados pero con menor enfoque semántico |
| Escalabilidad | Escala a miles de millones de entidades y billones de hechos | Escala bien para datos estructurados y transaccionales | Escala bien para consultas centradas en relaciones |
| Capacidad de inferencia | Razonamiento avanzado y derivación de conocimiento mediante ontologías | Limitada; requiere programación explícita | Limitada; centrada en coincidencia de patrones |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
El papel de los grafos de conocimiento en SEO y visibilidad en IA
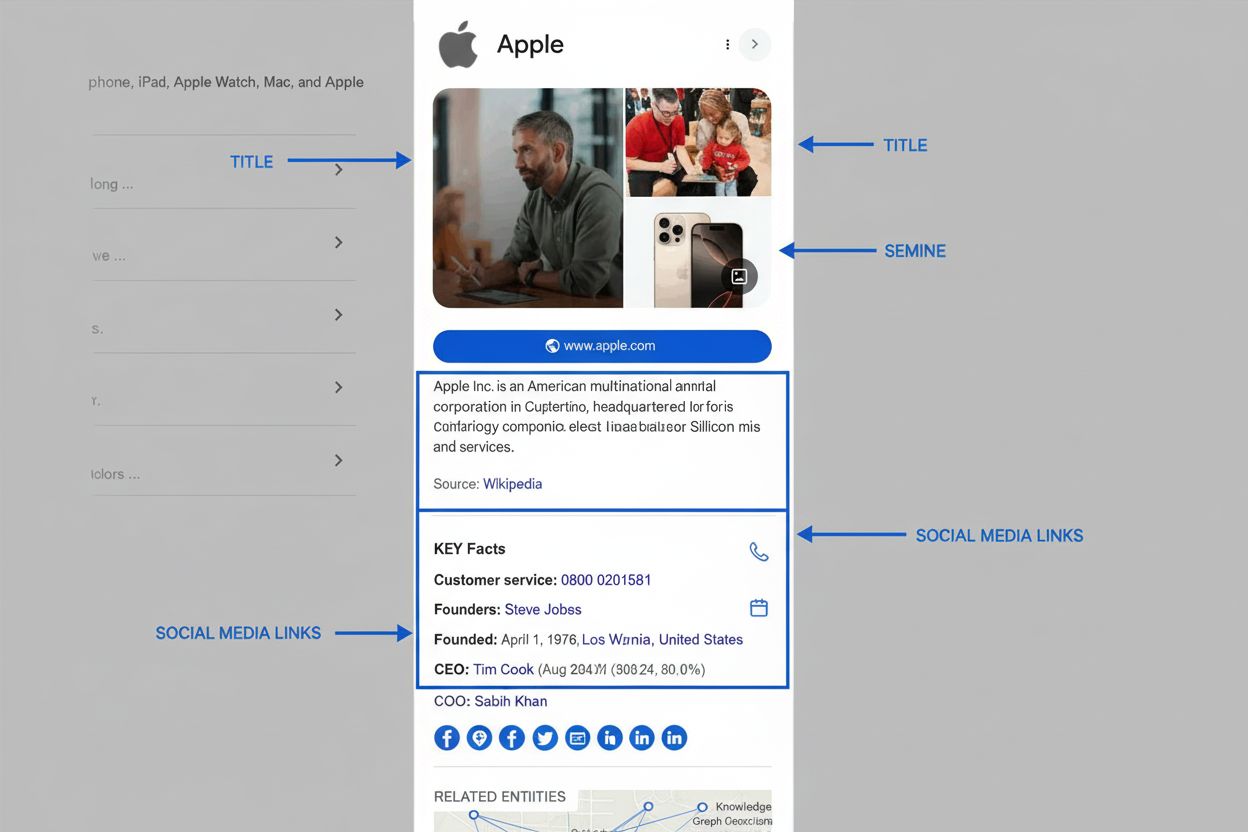
Los grafos de conocimiento se han vuelto centrales en las estrategias modernas de SEO y visibilidad en IA porque determinan fundamentalmente cómo aparece la información en los resultados de búsqueda y respuestas generadas por IA. Cuando Google procesa una consulta de búsqueda, una de sus tareas principales es identificar la entidad que busca el usuario y luego recuperar información relevante del Grafo de Conocimiento para poblar funciones en la página de resultados. Este enfoque basado en entidades ha dado lugar al surgimiento de la búsqueda semántica—la capacidad de Google de entender el significado y contexto de las consultas más allá de solo coincidir palabras clave. El Grafo de Conocimiento impulsa múltiples funciones de alta visibilidad en la página de resultados que afectan directamente la tasa de clics y la visibilidad de marcas. Los paneles de conocimiento aparecen de forma destacada en resultados de escritorio y móviles, mostrando hechos seleccionados sobre la entidad buscada extraídos del Grafo de Conocimiento. Los Resúmenes de IA (anteriormente Experiencia Generativa de Búsqueda) sintetizan información de múltiples fuentes identificadas mediante relaciones en el Grafo de Conocimiento, ofreciendo respuestas integrales que a menudo desplazan los listados orgánicos más abajo en la página. Los cuadros de Otras preguntas de los usuarios aprovechan las relaciones entre entidades para sugerir búsquedas y temas relacionados. Comprender estas funciones es fundamental para las marcas porque representan espacios privilegiados en los resultados de búsqueda, a menudo por encima de los listados tradicionales. Para organizaciones que monitorean su presencia en sistemas de IA como Perplexity, ChatGPT, Claude y Google AI Overviews, la optimización para grafos de conocimiento se vuelve esencial. Estos sistemas de IA dependen cada vez más de información estructurada de entidades y relaciones semánticas para generar respuestas precisas y contextuales. Una marca que ha optimizado adecuadamente su presencia de entidad en los grafos de conocimiento—a través de marcado de datos estructurados, paneles de conocimiento reclamados e información coherente entre fuentes—tiene más probabilidades de aparecer en respuestas generadas por IA sobre temas relevantes. Por el contrario, las marcas con información de entidad incompleta o inconsistente pueden ser pasadas por alto o mal representadas en sistemas de IA, afectando directamente su visibilidad y reputación.
Fuentes de datos y construcción del grafo de conocimiento
El Grafo de Conocimiento de Google se nutre de un ecosistema diverso de fuentes de datos, cada una aportando diferentes tipos de información y cumpliendo distintos propósitos. Los proyectos de datos abiertos y comunitarios como Wikipedia y Wikidata forman la base de gran parte del contenido del Grafo de Conocimiento. Wikipedia ofrece descripciones narrativas e información resumida que a menudo aparece en los paneles de conocimiento, mientras que Wikidata—una base de conocimiento estructurada que respalda Wikipedia—proporciona datos de entidades y relaciones legibles por máquina. Google utilizó previamente Freebase, su propia base de datos editada por la comunidad, pero migró a Wikidata tras cerrar Freebase en 2016. Las fuentes de datos gubernamentales aportan información autorizada, especialmente para consultas fácticas. El CIA World Factbook proporciona información sobre países, áreas geográficas y organizaciones. Data Commons, el proyecto de datos públicos estructurados de Google, agrupa datos de organizaciones gubernamentales y multilaterales como las Naciones Unidas y la Unión Europea, proporcionando estadísticas e información demográfica. Los datos meteorológicos y de calidad del aire provienen de agencias meteorológicas nacionales e internacionales, habilitando funciones de pronóstico en Google. Los datos privados con licencia complementan el Grafo de Conocimiento con información que cambia con frecuencia o requiere experiencia especializada. Google licencia datos de mercados financieros de proveedores como Morningstar, S&P Global e Intercontinental Exchange para mostrar precios y datos de mercado. Los datos deportivos provienen de alianzas con ligas, equipos y agregadores como Stats Perform, brindando resultados en tiempo real y estadísticas históricas. Los datos estructurados de sitios web contribuyen significativamente al enriquecimiento del Grafo de Conocimiento. Cuando los sitios implementan marcado Schema.org, proveen información semántica explícita que Google puede extraer e incorporar. Por eso, implementar datos estructurados correctos—esquema de Organización, LocalBusiness, FAQPage, y otros—es clave para marcas que desean influir en su representación en el Grafo de Conocimiento. Los datos de Google Books de más de 40 millones de libros digitalizados brindan contexto histórico, información biográfica y descripciones detalladas que enriquecen el conocimiento de entidades. El feedback de usuarios y paneles de conocimiento reclamados permiten a individuos y organizaciones influir directamente en la información del Grafo de Conocimiento. Cuando los usuarios envían comentarios sobre paneles de conocimiento o representantes autorizados reclaman y actualizan paneles, esta información se procesa y puede derivar en actualizaciones. Este enfoque humano en el circuito garantiza que el Grafo de Conocimiento se mantenga preciso y representativo, aunque los sistemas automatizados de Google toman la decisión final sobre qué información mostrar.
Grafos de conocimiento y E-E-A-T: construir autoridad y confianza
Google ha declarado explícitamente que prioriza la información de fuentes que demuestran alto E-E-A-T (Experiencia, Pericia, Autoridad y Fiabilidad) al construir y actualizar el Grafo de Conocimiento. Esta conexión entre E-E-A-T y la inclusión en el Grafo de Conocimiento no es casual—refleja el compromiso de Google con mostrar información confiable y autorizada. Si el contenido de tu sitio web aparece en funciones de la página de resultados impulsadas por el Grafo de Conocimiento, suele ser una fuerte señal de que Google reconoce tu sitio como autoridad en ese tema. Por el contrario, si tu contenido no aparece en funciones relacionadas, puede indicar problemas de E-E-A-T que se deben abordar. Construir E-E-A-T para visibilidad en el Grafo de Conocimiento requiere un enfoque multifacético. Experiencia significa demostrar que tú o tus colaboradores tienen experiencia real en el tema. Para un sitio de salud, esto puede significar presentar contenido de profesionales médicos licenciados con años de experiencia clínica. Para una empresa de tecnología, significa mostrar la pericia de ingenieros e investigadores que han desarrollado los productos de los que se habla. Pericia implica crear contenido profundamente informado y que cubra los temas de forma precisa y completa, yendo más allá de explicaciones superficiales para demostrar comprensión genuina de matices y conceptos avanzados. Autoridad requiere reconocimiento en el sector, como premios, certificaciones, menciones en medios, charlas y ser citado por fuentes autorizadas. Para organizaciones, significa establecer la marca como líder reconocido en la industria. Fiabilidad se construye sobre los otros tres elementos y se demuestra mediante transparencia, precisión, citas adecuadas, autoría clara y un servicio al cliente receptivo. Las organizaciones que destacan en señales E-E-A-T son más propensas a que su información se incluya en el Grafo de Conocimiento y a aparecer en respuestas generadas por IA, creando un ciclo virtuoso en el que la autoridad lleva a la visibilidad, reforzando aún más la autoridad.
Grafos de conocimiento en sistemas de IA y búsqueda generativa
El surgimiento de grandes modelos de lenguaje (LLM) y de la IA generativa ha dado nueva importancia a los grafos de conocimiento en el ecosistema de IA. Aunque los LLM como ChatGPT, Claude y Perplexity no están entrenados directamente con el Grafo de Conocimiento propietario de Google, dependen cada vez más de conocimientos estructurados y comprensión semántica similares. Muchos sistemas de IA emplean enfoques de generación aumentada por recuperación (RAG), donde el modelo consulta grafos de conocimiento o bases de datos estructuradas en tiempo de inferencia para fundamentar las respuestas en información factual y reducir alucinaciones. Grafos de conocimiento públicos como Wikidata se usan para afinar modelos o inyectar conocimiento estructurado, mejorando su capacidad de comprender relaciones de entidades y ofrecer información precisa. Para marcas y organizaciones, esto significa que la optimización de grafos de conocimiento tiene implicaciones más allá de la búsqueda tradicional de Google. Cuando los usuarios consultan sistemas de IA sobre tu sector, productos u organización, la capacidad del sistema para proporcionar información precisa depende en parte de cómo está representada tu entidad en fuentes de conocimiento estructurado. Una organización con una entrada bien mantenida en Wikidata, panel de conocimiento de Google reclamado e información estructurada coherente en su web es más probable que esté correctamente representada en respuestas generadas por IA. Por el contrario, organizaciones con información incompleta o contradictoria pueden verse mal representadas u omitidas en respuestas de IA. Esto crea una nueva dimensión de monitoreo de visibilidad en IA—rastrear no solo cómo aparece tu marca en los resultados de búsqueda tradicionales, sino cómo está representada en respuestas generadas por IA en múltiples plataformas. Las herramientas que monitorean la presencia de marcas en sistemas de IA se centran cada vez más en comprender relaciones de entidades y representación en grafos de conocimiento, reconociendo que estos factores influyen directamente en la visibilidad en IA.
Implementación práctica: optimización para grafos de conocimiento
Las organizaciones que buscan optimizar su presencia en grafos de conocimiento deben seguir un enfoque sistemático que parte de los fundamentos SEO y suma estrategias específicas de entidades. El primer paso es implementar marcado de datos estructurados usando el vocabulario de Schema.org. Esto significa añadir marcado JSON-LD, Microdatos o RDFa en tu sitio web que describa explícitamente tu organización, productos, personas y otras entidades relevantes. Los esquemas clave incluyen Organization (para información de empresa), LocalBusiness (para información local), Person (para perfiles individuales), Product (para productos) y FAQPage (para preguntas frecuentes). Tras implementar el esquema, es esencial probar y validar el marcado usando la herramienta de prueba de datos estructurados de Google para asegurar que esté correctamente formateado y reconocido. El segundo paso implica auditar y optimizar información en Wikidata y Wikipedia. Si tu organización o entidades clave tienen páginas en Wikipedia, asegúrate de que sean precisas, completas y estén bien referenciadas. Para Wikidata, verifica que tu entidad exista y que sus propiedades y relaciones estén correctamente representadas. No obstante, editar Wikipedia o Wikidata requiere atención cuidadosa a sus políticas y normas comunitarias—la autopromoción directa o conflictos de interés no declarados pueden resultar en la reversión de ediciones y dañar tu reputación. El tercer paso es reclamar y optimizar tu Perfil de Negocio de Google (para negocios locales) y paneles de conocimiento (para personas y organizaciones). Un panel de conocimiento reclamado te da mayor control sobre cómo aparece tu entidad en los resultados y te permite sugerir ediciones más rápidamente. El cuarto paso implica asegurar la consistencia en todas tus propiedades—tu sitio web, Perfil de Negocio de Google, redes sociales y directorios de empresas. La información contradictoria entre fuentes confunde a los sistemas de Google y puede impedir una representación precisa en el Grafo de Conocimiento. El quinto paso es crear contenido centrado en entidades en vez de solo en palabras clave. En lugar de redactar artículos separados sobre “mejor software CRM”, “características de Salesforce” y “precios de HubSpot”, crea un clúster de contenido integral que establezca claras relaciones de entidades: Salesforce es una plataforma CRM, compite con HubSpot, se integra con Slack, etc. Este enfoque ayuda a los grafos de conocimiento a comprender el significado semántico y las relaciones de tu contenido.
Aspectos clave de la optimización e implementación de grafos de conocimiento
- Implementación de datos estructurados: Añade marcado Schema.org en todas las páginas relevantes, incluyendo los esquemas Organization, LocalBusiness, Product, Person y FAQPage, y valida usando las herramientas de Google
- Consistencia de entidades: Mantén información de negocio idéntica (nombre, dirección, teléfono, descripción) en tu web, Perfil de Negocio de Google, redes sociales y directorios para evitar señales contradictorias
- Reclamo de panel de conocimiento: Reclama tu panel para tener control directo sobre la información de entidad y la capacidad de sugerir ediciones que Google procesa más rápido
- Optimización en Wikidata: Asegúrate de que tu organización o entidades clave tengan entradas precisas y completas en Wikidata con propiedades y relaciones adecuadas, siguiendo las directrices de la comunidad
- Señales E-E-A-T: Construye autoridad mediante contenido experto, credenciales de autores, reconocimiento en la industria, premios, menciones en medios y fuentes transparentes para aumentar la inclusión en el Grafo de Conocimiento
- Estrategia de contenido basada en entidades: Organiza el contenido en torno a entidades y sus relaciones en vez de solo palabras clave, creando clústeres de contenido que establecen conexiones semánticas
- Perfiles en redes sociales: Crea y optimiza perfiles en plataformas reconocidas por Google (Facebook, Instagram, LinkedIn, YouTube, TikTok, X, Pinterest, Snapchat) y enlázalos usando la propiedad “sameAs” en Schema.org
- Perfiles en directorios de empresas: Mantén perfiles en directorios empresariales autorizados como Crunchbase, Forbes y Fortune, que Google usa como fuentes para el Grafo de Conocimiento
- Monitoreo de precisión de datos: Audita regularmente la información de tu entidad en todas las fuentes y corrige datos desactualizados o inexactos, incluyendo contactar sitios de terceros cuando sea necesario
- Envío de feedback: Usa los mecanismos de comentarios de Google en paneles de conocimiento y resultados de búsqueda para reportar inexactitudes y sugerir mejoras en la información del Grafo de Conocimiento
- Seguimiento de visibilidad en IA: Monitorea cómo aparece tu marca en respuestas generadas por IA en Perplexity, ChatGPT, Claude y Google AI Overviews para entender tu representación en sistemas de IA
El futuro de los grafos de conocimiento: evolución e implicaciones estratégicas
Los grafos de conocimiento evolucionan rápidamente en respuesta a los avances en inteligencia artificial, cambios en el comportamiento de búsqueda y el surgimiento de nuevas plataformas y tecnologías. Una tendencia significativa es la expansión de grafos de conocimiento multimodales que integran texto, imágenes, audio y video. A medida que la búsqueda por voz y visual se vuelve más común, los grafos de conocimiento se adaptan para entender y representar información en múltiples modalidades. El trabajo de Google en búsqueda multimodal con productos como Google Lens ejemplifica esta evolución—el sistema debe comprender no solo consultas de texto sino también entradas visuales, requiriendo grafos de conocimiento capaces de conectar información entre distintos tipos de medios. Otro avance importante es la creciente sofisticación del enriquecimiento semántico y el procesamiento de lenguaje natural en la construcción de grafos de conocimiento. A medida que las capacidades de PLN mejoran, los grafos pueden extraer relaciones semánticas más matizadas de texto no estructurado, reduciendo la dependencia de datos marcados manualmente o explícitamente. Esto significa que las organizaciones con contenido de alta calidad y bien redactado pueden ver su información incorporada en grafos de conocimiento incluso sin marcado estructurado explícito, aunque el marcado sigue siendo importante para garantizar una representación precisa. La integración de grafos de conocimiento con grandes modelos de lenguaje e IA generativa representa quizá la evolución más relevante. A medida que los sistemas de IA se vuelven centrales para la forma en que las personas descubren información, la importancia de la optimización para grafos de conocimiento se extiende más allá de la búsqueda tradicional para abarcar la visibilidad en IA en múltiples plataformas. Las organizaciones que entiendan y optimicen para grafos de conocimiento tendrán ventajas tanto en la búsqueda tradicional como en respuestas generadas por IA. Además, el auge de los grafos de conocimiento empresariales refleja el reconocimiento creciente de que los principios de grafos de conocimiento se aplican también a la gestión interna de información en las organizaciones. Las empresas están creando grafos internos para romper silos de datos, mejorar la toma de decisiones y potenciar mejores aplicaciones de IA. Esta tendencia sugiere que la alfabetización en grafos de conocimiento será cada vez más importante para líderes empresariales, científicos de datos y profesionales del marketing. Finalmente, las dimensiones regulatorias y éticas de los grafos de conocimiento cobran mayor relevancia. A medida que los grafos de conocimiento influyen en cómo se presenta la información a miles de millones de usuarios, surgen preguntas sobre precisión, sesgo, representación y quién controla esa información. Las organizaciones deben ser conscientes de que su representación de entidad en los grafos de conocimiento tiene consecuencias reales para su visibilidad, reputación y resultados de negocio, y deben abordar la optimización de grafos de conocimiento con el mismo rigor y ética que aplican a otros aspectos de su presencia digital.