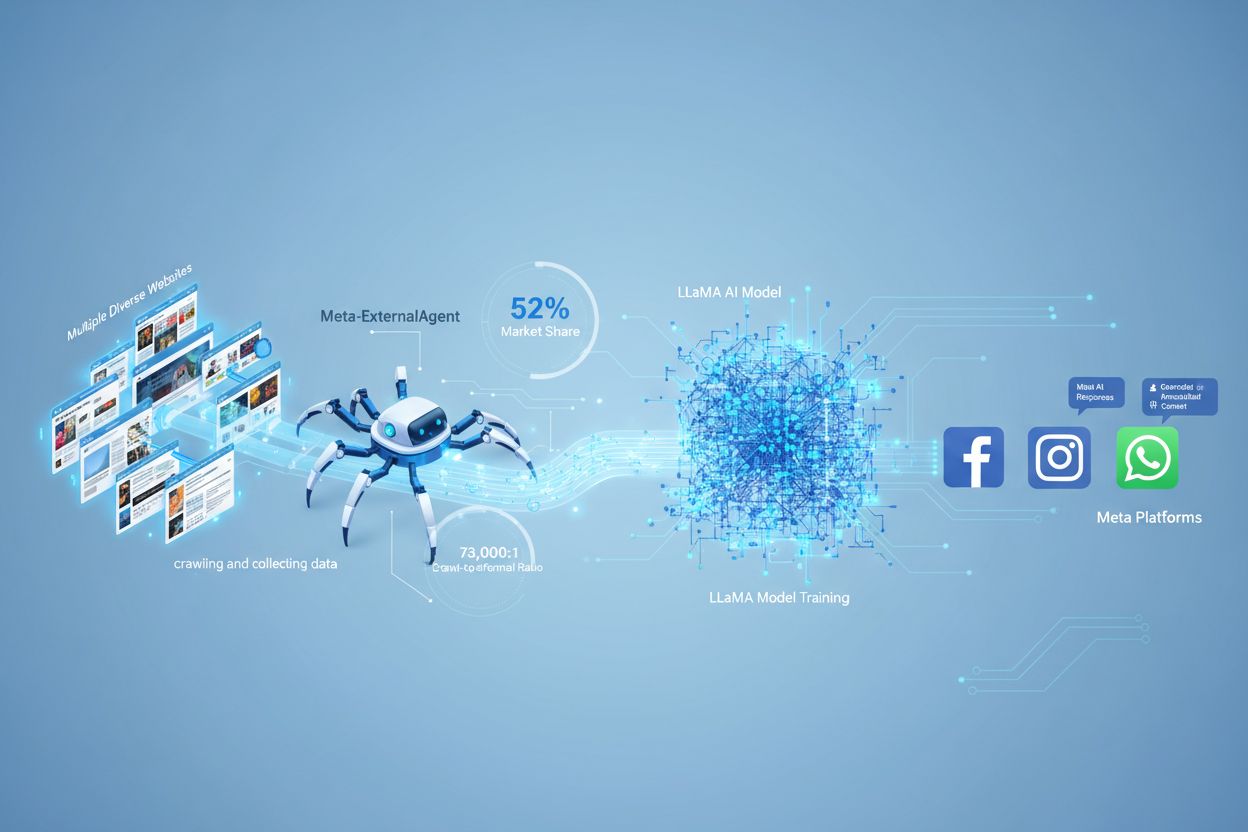
Meta-ExternalAgent es el bot rastreador web de Meta lanzado en julio de 2024 para recopilar contenido público disponible con el fin de entrenar modelos de IA como LLaMA. Se identifica con la cadena User-Agent meta-externalagent/1.1 y controla si el contenido aparece en las respuestas de Meta AI en Facebook, Instagram y WhatsApp. Los editores pueden bloquearlo a través de robots.txt o configuraciones a nivel de servidor, aunque el cumplimiento es voluntario y no tiene carácter legal.
Meta-ExternalAgent
Meta-ExternalAgent es el bot rastreador web de Meta lanzado en julio de 2024 para recopilar contenido público disponible con el fin de entrenar modelos de IA como LLaMA. Se identifica con la cadena User-Agent meta-externalagent/1.1 y controla si el contenido aparece en las respuestas de Meta AI en Facebook, Instagram y WhatsApp. Los editores pueden bloquearlo a través de robots.txt o configuraciones a nivel de servidor, aunque el cumplimiento es voluntario y no tiene carácter legal.
¿Qué es Meta-ExternalAgent?
Meta-ExternalAgent es un rastreador web operado por Meta Platforms que fue lanzado en julio de 2024 para recopilar datos destinados al entrenamiento de modelos de inteligencia artificial. Identificado por la cadena User-Agent meta-externalagent/1.1, este rastreador es distinto del antiguo facebookexternalhit de Meta, que se utilizaba principalmente para vistas previas de enlaces y funciones de compartir en redes sociales. Meta-ExternalAgent representa un cambio significativo en la forma en que Meta recopila datos de entrenamiento para sus iniciativas de IA, incluyendo los modelos de lenguaje LLaMA y el chatbot Meta AI integrado en Facebook, Instagram y WhatsApp. A diferencia de rastreadores anteriores de Meta, este agente opera con mínima transparencia y fue desplegado sin un anuncio público formal.
Cómo Funciona Meta-ExternalAgent
Meta-ExternalAgent funciona como un bot automatizado que rastrea sistemáticamente sitios web en internet para extraer texto y contenido con fines de entrenamiento de modelos de IA. El rastreador opera enviando solicitudes HTTP a servidores web, identificándose por su encabezado User-Agent único y descargando el contenido de las páginas para su procesamiento. Una vez recopilado, los sistemas de Meta analizan y tokenizan el texto, convirtiéndolo en datos de entrenamiento que ayudan a mejorar las capacidades de sus modelos de lenguaje de gran tamaño. El rastreador respeta el archivo robots.txt de manera voluntaria, aunque esto es un sistema de honor y no un requisito legal. Según datos de Cloudflare, Meta-ExternalAgent representa aproximadamente el 52% de todo el tráfico de rastreadores de IA en internet, lo que lo convierte en una de las operaciones de recopilación de datos más agresivas en la industria de la IA. El rastreador opera continuamente, con algunos editores reportando frecuencias de rastreo que sugieren que Meta prioriza la cobertura exhaustiva del contenido web sobre la recopilación selectiva y dirigida.
Meta-ExternalAgent vs Otros Rastreadores de Meta
Nombre del Rastreador
Cadena User-Agent
Propósito Principal
Fecha de Lanzamiento
Uso de Datos
Meta-ExternalAgent
meta-externalagent/1.1
Entrenamiento de modelos de IA (LLaMA, Meta AI)
Julio 2024
Datos de entrenamiento para IA generativa
facebookexternalhit
facebookexternalhit/1.1
Vistas previas de enlaces y compartir en redes sociales
~2010
Metadatos Open Graph, miniaturas
Facebot
facebot/1.0
Verificación de contenido para la app de Facebook
~2015
Validación de contenido para apps móviles
Applebot
Applebot/0.1
Siri de Apple e indexación de búsqueda
~2015
Indexación de búsqueda y asistente de voz
Googlebot
Googlebot/2.1
Indexación de búsqueda en Google
~1998
Construcción del índice de motores de búsqueda
Por Qué Meta-ExternalAgent Es Importante para los Editores
Meta-ExternalAgent representa una preocupación crítica para creadores de contenido y editores porque opera a una escala sin precedentes y ofrece una visibilidad mínima sobre cómo se utiliza el contenido. Según investigaciones de Cloudflare, Meta-ExternalAgent representa el 52% de todo el tráfico de rastreadores de IA, superando ampliamente a competidores como GPTBot de OpenAI y los rastreadores de IA de Google. Este dominio significa que Meta recopila más datos de entrenamiento que cualquier otra compañía de IA, pero los editores no reciben compensación ni atribución cuando su contenido es utilizado para entrenar los modelos de IA de Meta. La proporción de rastreo a referencia de 73,000:1 demuestra que Meta extrae enormes cantidades de contenido mientras envía prácticamente ningún tráfico de regreso a los sitios de origen, un desequilibrio fundamental en el intercambio de valor. A pesar de estas preocupaciones, solo el 2% de los sitios web bloquean activamente a Meta-ExternalAgent, en comparación con el 25% que bloquea a GPTBot, lo que sugiere que muchos editores desconocen la presencia del rastreador o sus implicaciones. Con una inversión de 40 mil millones de dólares en infraestructura de IA, el compromiso de Meta con la recopilación agresiva de datos probablemente se intensificará, por lo que es esencial que los editores comprendan y gestionen activamente su relación con este rastreador.
Controlando el Acceso de Meta-ExternalAgent
Los editores pueden controlar el acceso de Meta-ExternalAgent a través del archivo robots.txt, aunque es importante entender que este mecanismo funciona de manera voluntaria y no es legalmente vinculante. Para bloquear a Meta-ExternalAgent, agrega la siguiente directiva en tu archivo robots.txt:
User-agent: meta-externalagent
Disallow: /
Alternativamente, si deseas permitir el rastreador pero restringirlo a directorios específicos, puedes usar:
Sin embargo, algunos editores han reportado que Meta-ExternalAgent sigue rastreando sus sitios incluso después de implementar bloqueos en robots.txt, lo que sugiere que Meta no siempre respeta estas directivas. Para una protección más completa, los editores pueden implementar bloqueos basados en encabezados HTTP o usar reglas de Content Delivery Network (CDN) para identificar y rechazar solicitudes de Meta-ExternalAgent según la cadena User-Agent. Además, los editores pueden monitorear los registros de su servidor buscando la cadena User-Agent meta-externalagent/1.1 para verificar si el rastreador está accediendo a su contenido. Herramientas como AmICited.com pueden ayudar a los editores a rastrear si su contenido es citado o referenciado en respuestas de Meta AI, proporcionando visibilidad sobre cómo su trabajo es utilizado por los sistemas de IA de Meta.
Respuestas de Meta AI y Visibilidad del Contenido
Cuando los usuarios interactúan con los chatbots de Meta AI en Facebook, Instagram o WhatsApp, las respuestas generadas se basan en parte en contenido recopilado por Meta-ExternalAgent. Sin embargo, las respuestas de Meta AI normalmente no incluyen citas visibles ni atribución a los sitios de origen, lo que significa que los usuarios pueden no saber qué contenido de qué editores contribuyó a la respuesta que recibieron. Esta falta de transparencia crea un desafío importante para los creadores de contenido que desean entender el valor que su trabajo aporta a los sistemas de IA de Meta. A diferencia de algunos competidores que incluyen citas en las respuestas generadas por IA, el enfoque de Meta prioriza la experiencia del usuario por encima de la atribución a los editores. La ausencia de citas visibles también significa que los editores no pueden rastrear fácilmente con qué frecuencia su contenido influye en las respuestas de Meta AI, lo que dificulta evaluar el impacto empresarial del uso de su contenido para el entrenamiento de IA. Esta brecha de visibilidad es una de las razones principales por las que las soluciones de monitoreo son cada vez más importantes para los editores que buscan comprender su papel en el ecosistema de la IA.
Monitoreo y Verificación
Los editores pueden verificar la actividad de Meta-ExternalAgent mediante el análisis de los registros del servidor, donde se revelan las direcciones IP del rastreador, los patrones de solicitud y la frecuencia de acceso al contenido. Al examinar los registros de acceso, los editores pueden identificar solicitudes con la cadena User-Agent meta-externalagent/1.1 y determinar qué páginas se rastrean con mayor frecuencia. Las herramientas de monitoreo avanzadas pueden rastrear los patrones de rastreo a lo largo del tiempo, revelando si Meta prioriza ciertos tipos de contenido o secciones de un sitio web. Los editores también deben monitorear el uso de ancho de banda, ya que un rastreo agresivo por parte de Meta-ExternalAgent puede consumir recursos significativos del servidor, especialmente en sitios con grandes bibliotecas de contenido. Además, los editores pueden usar herramientas como AmICited.com para monitorear si su contenido aparece en respuestas de Meta AI y rastrear patrones de citación en las plataformas de Meta. Configurar alertas para actividad de rastreo inusual puede ayudar a los editores a detectar cambios en el comportamiento de recopilación de datos de Meta y responder de manera proactiva. Auditorías regulares de los registros del servidor deben formar parte de cualquier estrategia de gestión de rastreadores de IA, asegurando que los editores mantengan conciencia sobre cómo se accede y utiliza su contenido.
Consideraciones Legales y Éticas
El estatus legal de Meta-ExternalAgent sigue siendo motivo de controversia, con demandas en curso de creadores de contenido, artistas y editores que cuestionan el derecho de Meta a utilizar su trabajo para el entrenamiento de IA sin consentimiento explícito ni compensación. Mientras que Meta argumenta que el rastreo web se encuentra dentro del ámbito de uso justo, los críticos sostienen que la escala y naturaleza comercial de la recopilación de datos, combinada con la falta de atribución, constituyen una infracción de derechos de autor. El archivo robots.txt, aunque ampliamente respetado como estándar de la industria, no tiene fuerza legal, lo que significa que Meta no está legalmente obligada a respetar las directivas de bloqueo. Varias jurisdicciones están desarrollando regulaciones sobre la recopilación de datos para el entrenamiento de IA, como la Ley de IA de la Unión Europea y legislaciones propuestas en otras regiones que podrían imponer requisitos más estrictos a empresas como Meta. Desde una perspectiva ética, la cuestión fundamental es si los creadores de contenido deberían tener el derecho de controlar cómo se usa su trabajo para el entrenamiento comercial de IA y si el sistema actual compensa adecuadamente a los creadores por el valor que aporta su contenido. Los editores deben mantenerse informados sobre la evolución de los marcos legales y considerar consultar con asesores legales sobre sus derechos y obligaciones respecto al acceso de rastreadores de IA. El equilibrio entre habilitar la innovación en IA y proteger los derechos de los creadores sigue sin resolverse, siendo esta un área de desarrollo legal y regulatorio activo.
Mejores Prácticas para Creadores de Contenido
Audita regularmente tu archivo robots.txt para asegurarte de que refleje tu política actual sobre el acceso de rastreadores de IA y verifica que tus directivas se respetan monitoreando los registros del servidor
Implementa soluciones de monitoreo como AmICited.com para rastrear si tu contenido aparece en respuestas de Meta AI y entender cómo tu trabajo contribuye a respuestas generadas por IA
Documenta tu proceso de creación de contenido y mantén registros de las fechas originales de publicación, ya que esta evidencia puede ser valiosa en caso de disputas legales sobre el uso de datos para entrenamiento de IA
Considera estrategias de bloqueo selectivo que permitan rastreadores beneficiosos mientras bloquean aquellos que aportan poco valor, equilibrando la innovación en IA con los intereses de tu negocio
Mantente informado sobre los desarrollos legales en regulación de IA y derechos de autor, ya que nuevas legislaciones podrían ofrecer protecciones o requisitos adicionales para la recopilación de datos de entrenamiento de IA
Participa en grupos de la industria y asociaciones de editores que abogan por estándares de compensación y atribución justa para los datos de entrenamiento de IA
Usa encabezados HTTP y reglas de CDN como capas adicionales de protección más allá de robots.txt, especialmente para contenido sensible o premium
Monitorea tu analítica para detectar cambios en el tráfico de referencia proveniente de propiedades de Meta, ya que esto puede indicar cambios en cómo Meta AI utiliza tu contenido
Futuro de los Rastreadores de IA y la Protección de Contenidos
El panorama de la gestión de rastreadores de IA está evolucionando rápidamente a medida que editores, reguladores y empresas de IA negocian los términos de la recopilación y el uso de datos. El despliegue agresivo de Meta-ExternalAgent indica que las grandes empresas tecnológicas consideran el contenido web como material esencial para entrenar sistemas de IA competitivos, y esta tendencia probablemente se acelerará a medida que las capacidades de IA sean cada vez más centrales en la estrategia empresarial. Los desarrollos futuros pueden incluir protecciones legales más sólidas para los creadores, marcos de licenciamiento obligatorio para datos de entrenamiento de IA y estándares técnicos que faciliten a los editores controlar y monetizar el uso de su contenido en sistemas de IA. La aparición de herramientas como AmICited.com refleja la creciente demanda de transparencia y responsabilidad en cómo los sistemas de IA utilizan contenido publicado, lo que sugiere que el monitoreo y la verificación serán la práctica estándar para los creadores de contenido. A medida que la industria de la IA madura, es probable que veamos negociaciones más sofisticadas entre creadores de contenido y empresas de IA, lo que podría llevar a nuevos modelos de negocio que compensen de manera justa a los editores por sus contribuciones al entrenamiento de IA.
Preguntas frecuentes
¿Qué es Meta-ExternalAgent y en qué se diferencia de otros rastreadores de Meta?
Meta-ExternalAgent es el rastreador dedicado al entrenamiento de IA de Meta lanzado en julio de 2024, identificado por la cadena User-Agent meta-externalagent/1.1. Se diferencia de facebookexternalhit, que genera vistas previas de enlaces para compartir en redes sociales. Meta-ExternalAgent recopila específicamente contenido para entrenar modelos LLaMA y Meta AI, mientras que facebookexternalhit se usa para funciones sociales desde aproximadamente 2010.
¿Cómo puedo bloquear a Meta-ExternalAgent para que no acceda a mi sitio web?
Puedes bloquear a Meta-ExternalAgent agregando directivas en tu archivo robots.txt. Añade 'User-agent: meta-externalagent' seguido de 'Disallow: /' para bloquearlo completamente. Para una protección más completa, implementa bloqueos a nivel de servidor usando .htaccess (Apache) o reglas de configuración en Nginx. Sin embargo, robots.txt es voluntario y no tiene carácter legal, por lo que algunos editores reportan rastreo continuo a pesar de los bloqueos.
¿Bloquear a Meta-ExternalAgent afectará las vistas previas de enlaces en Facebook?
No, bloquear a Meta-ExternalAgent no afectará las vistas previas de enlaces en Facebook. El rastreador facebookexternalhit se encarga de las vistas previas y funciones para compartir en redes sociales. Puedes bloquear meta-externalagent y permitir que facebookexternalhit siga generando vistas previas atractivas cuando se comparta tu contenido en plataformas de Meta.
¿Cuál es la proporción de rastreo a referencia de Meta-ExternalAgent?
Meta-ExternalAgent tiene una proporción de rastreo a referencia de aproximadamente 73,000:1, lo que significa que Meta extrae contenido a una escala enorme mientras envía prácticamente ningún tráfico de regreso a los sitios de origen. Esto representa un desequilibrio fundamental en comparación con motores de búsqueda tradicionales, que rastrean contenido a cambio de generar tráfico de referencia.
¿Es efectivo robots.txt para bloquear a Meta-ExternalAgent?
robots.txt es un sistema de honor y no tiene carácter legal. Aunque muchos rastreadores respetan las directivas de robots.txt, algunos editores han reportado que Meta-ExternalAgent sigue rastreando sus sitios a pesar de bloqueos explícitos en robots.txt. Para una protección garantizada, implementa bloqueos a nivel de servidor usando encabezados HTTP, reglas de CDN o configuraciones de firewall.
¿Cómo puedo monitorear si Meta-ExternalAgent está rastreando mi sitio?
Revisa los registros de acceso de tu servidor para detectar solicitudes con la cadena User-Agent 'meta-externalagent/1.1'. También puedes usar herramientas de monitoreo como AmICited.com para rastrear si tu contenido aparece en respuestas de Meta AI. Herramientas como Dark Visitors y Cloudflare Analytics ofrecen información adicional sobre la actividad de rastreadores de IA en tu sitio web.
¿Qué porcentaje del tráfico de rastreadores de IA representa Meta-ExternalAgent?
Según datos de Cloudflare, Meta-ExternalAgent representa aproximadamente el 52% de todo el tráfico de rastreadores de IA en internet, convirtiéndose en la operación de recopilación de datos de IA más agresiva. Esto supera con creces a competidores como GPTBot de OpenAI y los rastreadores de IA de Google, lo que indica la posición dominante de Meta en la recopilación de contenido web para el entrenamiento de IA.
¿Debo bloquear o permitir a Meta-ExternalAgent?
La decisión depende de tus prioridades de negocio. Si el tráfico de Meta AI es valioso para tu audiencia, podrías permitirlo. Sin embargo, considera que Meta no ofrece compensación ni atribución por el contenido utilizado en el entrenamiento de IA. Muchos editores implementan estrategias de bloqueo selectivo que detienen el entrenamiento de IA pero conservan la funcionalidad de vista previa de enlaces para compartir en redes sociales.
Monitorea Tu Contenido en Respuestas de Meta AI
Haz seguimiento de cómo aparece tu contenido en las respuestas de Meta AI en Facebook, Instagram y WhatsApp. Obtén visibilidad sobre las citas de IA y entiende la presencia de tu marca en respuestas generadas por IA.
Etiquetas Meta NoAI: Controlando el Acceso de la IA a Través de Encabezados
Aprende cómo implementar las etiquetas meta noai y noimageai para controlar el acceso de rastreadores de IA al contenido de tu sitio web. Guía completa sobre en...
Meta AI es el asistente de IA de Meta integrado en Facebook, Instagram, WhatsApp y Messenger. Descubre cómo funciona, sus capacidades y su papel en la monitoriz...
Optimización de Meta AI: El Asistente de IA de Facebook e Instagram
Descubre cómo la optimización con Meta AI transforma la publicidad en Facebook e Instagram con automatización impulsada por IA, pujas en tiempo real y segmentac...
8 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.