Definición de Algoritmo Sonar
Algoritmo Sonar es el sistema propietario de ranking de generación aumentada por recuperación (RAG) de Perplexity que impulsa su motor de respuestas combinando búsqueda híbrida semántica y por palabras clave, re-ranqueo neuronal y generación de citas en tiempo real. A diferencia de los motores de búsqueda tradicionales que clasifican páginas para mostrarlas en una lista de resultados, Sonar clasifica fragmentos de contenido para sintetizarlos en una sola respuesta unificada con citas en línea a los documentos fuente. El algoritmo prioriza la actualidad del contenido, la relevancia semántica y la citabilidad para entregar respuestas fundamentadas y respaldadas por fuentes mientras minimiza las alucinaciones. Sonar representa un cambio fundamental en cómo los sistemas de IA recuperan y clasifican la información—pasando de señales de autoridad basadas en enlaces a métricas de utilidad centradas en la respuesta que enfatizan si el contenido satisface directamente la intención del usuario y puede ser citado limpiamente en respuestas sintetizadas. Esta distinción es crítica para entender cómo la visibilidad en motores de respuestas de IA difiere del SEO tradicional, ya que Sonar evalúa el contenido no por su capacidad de posicionarse en una lista, sino por su capacidad de ser extraído, sintetizado y atribuido dentro de una respuesta generada por IA.
Contexto y Antecedentes: La Evolución del Ranking Potenciado por IA
La aparición del Algoritmo Sonar refleja un cambio de la industria hacia la generación aumentada por recuperación como la arquitectura dominante para motores de respuestas con IA. Cuando Perplexity se lanzó a finales de 2022, la empresa identificó una brecha crítica en el panorama de la IA: mientras que ChatGPT ofrecía potentes capacidades conversacionales, carecía de acceso a información en tiempo real y atribución de fuentes, lo que generaba alucinaciones y respuestas desactualizadas. El equipo fundador de Perplexity, que inicialmente trabajaba en una herramienta de traducción de consultas de bases de datos, pivotó completamente para construir un motor de respuestas que pudiera combinar búsqueda web en vivo con síntesis de LLM. Esta decisión estratégica moldeó la arquitectura de Sonar desde su inicio—el algoritmo fue diseñado no para clasificar páginas para la navegación humana, sino para recuperar y clasificar fragmentos de contenido para síntesis y citación por máquina. En los últimos dos años, Sonar ha evolucionado hasta convertirse en uno de los sistemas de ranking más sofisticados del ecosistema IA, con los modelos Sonar de Perplexity logrando los puestos del 1 al 4 en la Search Arena Evaluation, superando significativamente a modelos competidores de Google y OpenAI. Actualmente, el algoritmo procesa más de 400 millones de consultas de búsqueda al mes, indexando más de 200 mil millones de URLs únicas y manteniendo la actualidad en tiempo real mediante decenas de miles de actualizaciones de índice por segundo. Esta escala y sofisticación subrayan la importancia de Sonar como paradigma definitorio de ranking en la era de búsqueda por IA.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Cómo Funciona el Algoritmo Sonar: La Canalización RAG de Múltiples Etapas
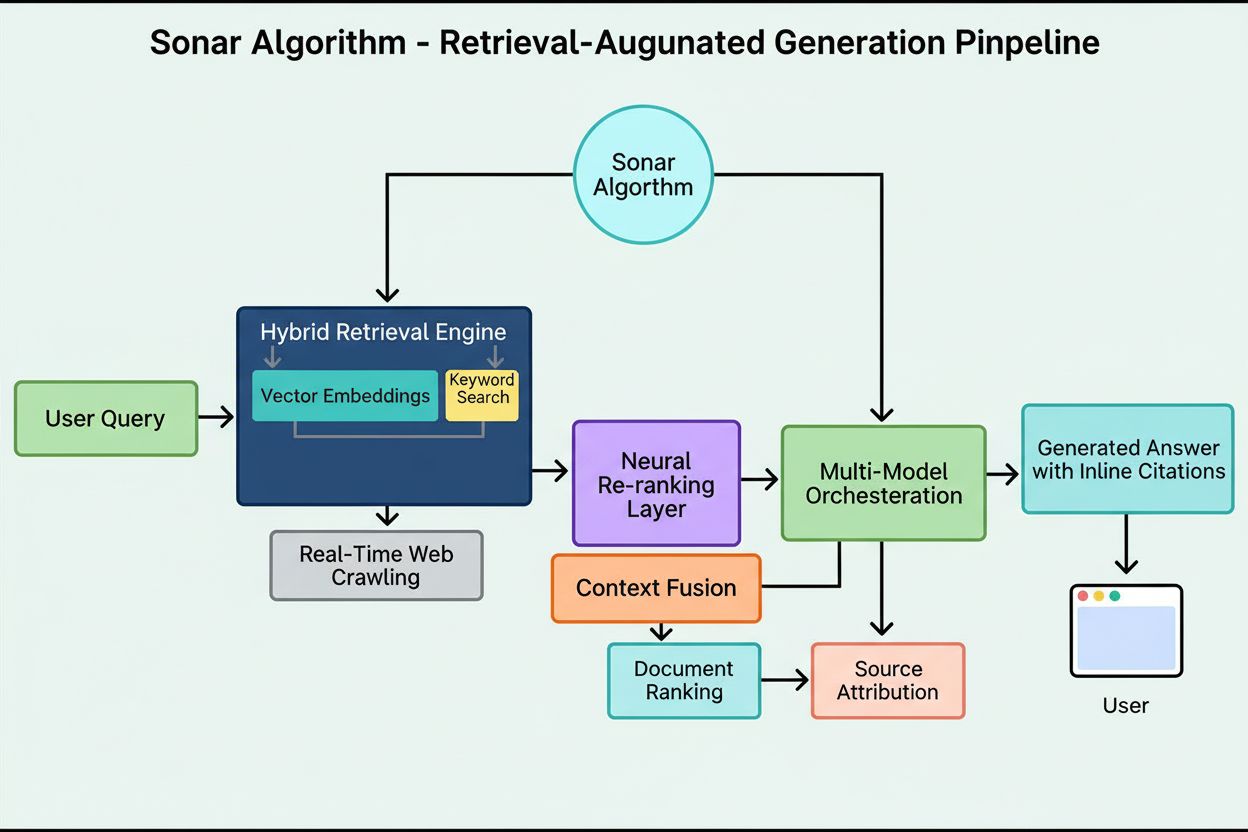
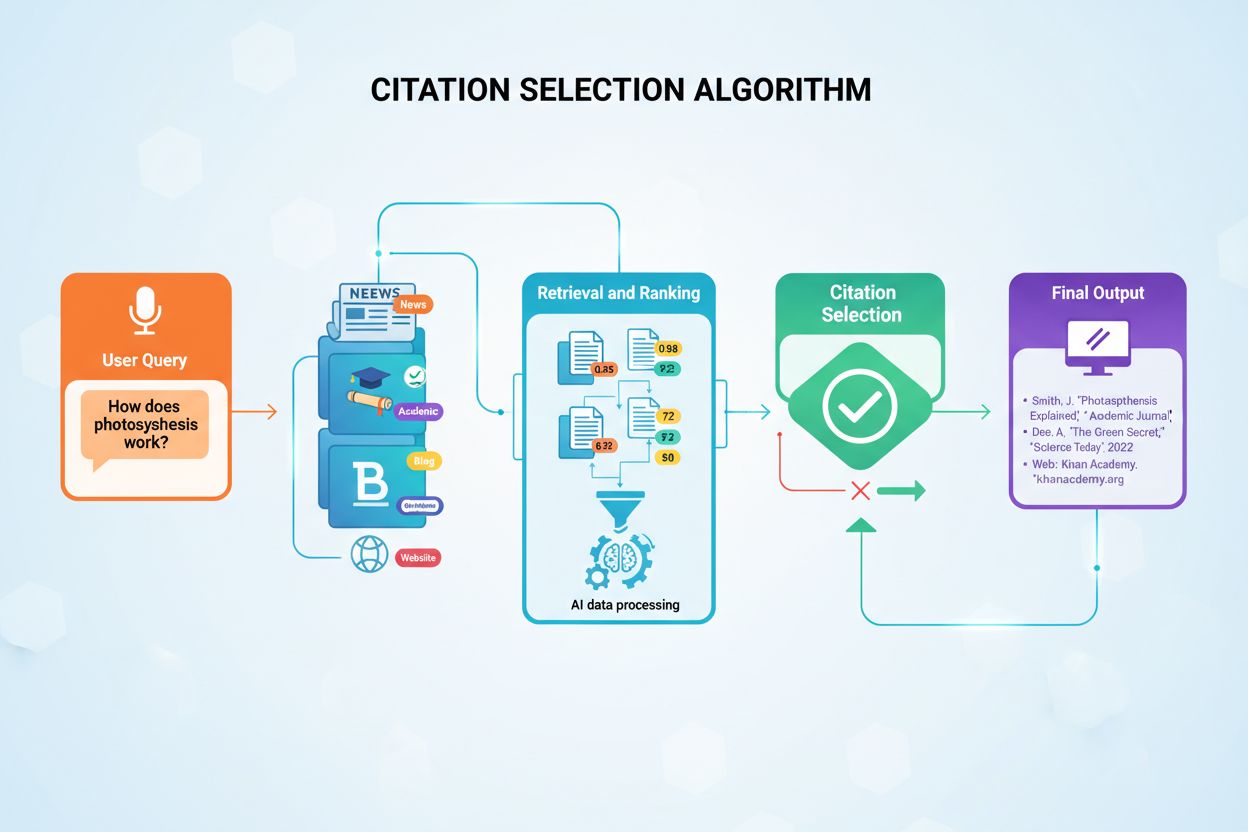
El sistema de ranking de Sonar opera mediante una canalización meticulosamente orquestada de generación aumentada por recuperación de cinco etapas que transforma las consultas de usuario en respuestas fundamentadas y citadas. La primera etapa, Análisis de Intención de Consulta, emplea un LLM para ir más allá de la simple coincidencia de palabras clave y lograr una comprensión semántica de lo que realmente pregunta el usuario, interpretando contexto, matices e intención subyacente. La segunda etapa, Recuperación Web en Vivo, envía la consulta analizada al enorme índice distribuido de Perplexity impulsado por Vespa AI, que rastrea la web en tiempo real en busca de páginas y documentos relevantes. Este sistema de recuperación combina recuperación densa (búsqueda vectorial usando embeddings semánticos) y recuperación dispersa (búsqueda léxica/basada en palabras clave), fusionando los resultados para producir unos 50 documentos candidatos diversos. La tercera etapa, Extracción y Contextualización de Fragmentos, no pasa el texto completo de la página al modelo generativo; en cambio, los algoritmos extraen los fragmentos, párrafos o bloques más relevantes directamente relacionados con la consulta, agregándolos en una ventana de contexto enfocada. La cuarta etapa, Generación de Respuesta Sintetizada con Citas, pasa este contexto curado a un LLM elegido (de la familia propietaria Sonar de Perplexity o modelos de terceros como GPT-4 o Claude), que genera una respuesta en lenguaje natural basada estrictamente en la información recuperada. Es crucial que las citas en línea enlacen cada afirmación con los documentos fuente, garantizando transparencia y verificación. La quinta etapa, Refinamiento Conversacional, mantiene el contexto conversacional a lo largo de múltiples turnos, permitiendo que preguntas de seguimiento refinen las respuestas mediante búsquedas web iterativas. El principio definitorio de esta canalización—“no debes decir nada que no hayas recuperado”—asegura que las respuestas impulsadas por Sonar estén fundamentadas en fuentes verificables, reduciendo fundamentalmente las alucinaciones en comparación con modelos que dependen solo de datos de entrenamiento.
Tabla Comparativa: Algoritmo Sonar vs. Búsqueda Tradicional y Sistemas de Ranking LLM Competidores
| Aspecto | Búsqueda Tradicional (Google) | Algoritmo Sonar (Perplexity) | Ranking ChatGPT | Ranking Gemini | Ranking Claude |
|---|
| Unidad Principal | Lista ordenada de enlaces | Respuesta unificada sintetizada con citas | Menciones de entidades basadas en consenso | Contenido alineado E-E-A-T | Fuentes neutrales y basadas en hechos |
| Enfoque de Recuperación | Palabras clave, enlaces, señales ML | Búsqueda híbrida semántica + palabras clave | Datos de entrenamiento + navegación web | Integración de gráfico de conocimiento | Filtros de seguridad constitucional |
| Prioridad de Actualidad | Actualidad según consulta (QDF) | Extracciones web en tiempo real, 37% de impulso en 48 horas | Prioridad baja, dependiente de datos de entrenamiento | Moderada, integrada con Google Search | Prioridad baja, énfasis en estabilidad |
| Señales de Ranking | Backlinks, autoridad de dominio, CTR | Actualidad del contenido, relevancia semántica, citabilidad, impulsos de autoridad | Reconocimiento de entidades, menciones de consenso | E-E-A-T, alineación conversacional, datos estructurados | Transparencia, citas verificables, neutralidad |
| Mecanismo de Citación | Fragmentos de URL en resultados | Citas en línea con enlaces fuente | Implícito, a menudo sin citas | AI Overviews con atribución | Atribución explícita de fuente |
| Diversidad de Contenido | Múltiples resultados de sitios | Selección de pocas fuentes para síntesis | Sintetizado de múltiples fuentes | Múltiples fuentes en la visión general | Fuentes balanceadas y neutrales |
| Personalización | Sutil, mayormente implícita | Modos de enfoque explícitos (Web, Académico, Finanzas, Redacción, Social) | Implícito según la conversación | Implícito según el tipo de consulta | Mínima, énfasis en consistencia |
| Manejo de PDF | Indexación estándar | Ventaja del 22% en citación sobre HTML | Indexación estándar | Indexación estándar | Indexación estándar |
| Impacto de Esquema | FAQ schema en featured snippets | FAQ schema incrementa citas 41%, reduce tiempo a citación en 6 horas | Impacto directo mínimo | Impacto moderado en gráfico de conocimiento | Impacto directo mínimo |
| Optimización de Latencia | Milisegundos para ranking | Recuperación + generación en sub-segundos | Segundos para síntesis | Segundos para síntesis | Segundos para síntesis |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Arquitectura Técnica: Recuperación Híbrida y Re-Ranqueo Neuronal
La base técnica del Algoritmo Sonar se asienta sobre un motor de recuperación híbrido que combina múltiples estrategias de búsqueda para maximizar tanto el recall como la precisión. La recuperación densa (búsqueda vectorial) usa embeddings semánticos para entender el significado conceptual detrás de las consultas, encontrando documentos contextualmente similares incluso sin coincidencias exactas de palabras clave. Este enfoque aprovecha embeddings basados en transformadores que mapean consultas y documentos en espacios vectoriales de alta dimensión donde el contenido semánticamente similar se agrupa. La recuperación dispersa (búsqueda léxica) complementa la densa al aportar precisión para términos raros, nombres de productos, identificadores internos de empresa y entidades específicas donde la ambigüedad semántica es indeseable. El sistema utiliza funciones de ranking como BM25 para realizar coincidencias exactas en estos términos críticos. Estos dos métodos de recuperación se fusionan y eliminan duplicados para obtener aproximadamente 50 documentos candidatos diversos, previniendo el sobreajuste de dominios y asegurando cobertura amplia de fuentes autoritativas. Tras la recuperación inicial, la capa de re-ranqueo neuronal de Sonar emplea modelos avanzados de aprendizaje automático (como DeBERTa-v3 cross-encoders) para evaluar candidatos usando un rico conjunto de características, incluyendo puntuaciones de relevancia léxica, similitud vectorial, autoridad de documento, señales de actualidad, métricas de participación de usuario y metadatos. Esta arquitectura de ranking por fases permite a Sonar refinar progresivamente los resultados bajo estrictos presupuestos de latencia, asegurando que el conjunto final clasificado represente las fuentes de mayor calidad y relevancia para la síntesis. Toda la infraestructura de recuperación está construida sobre Vespa AI, una plataforma de búsqueda distribuida capaz de manejar indexación web a escala (200+ mil millones de URLs), actualizaciones en tiempo real (decenas de miles por segundo) y comprensión de contenido de alta granularidad mediante fragmentación de documentos. Esta elección arquitectónica permite al relativamente pequeño equipo de ingeniería de Perplexity centrarse en componentes diferenciadores—orquestación RAG, ajuste fino de modelos Sonar y optimización de inferencia—en lugar de reinventar la búsqueda distribuida desde cero.
La Actualidad del Contenido como Factor Dominante de Ranking
La actualidad del contenido es una de las señales de ranking más poderosas de Sonar, con investigaciones empíricas que demuestran que las páginas actualizadas recientemente reciben tasas de citación dramáticamente mayores. En pruebas A/B controladas durante 24 semanas y 120 URLs, los artículos actualizados en las últimas 48 horas fueron citados un 37% más frecuentemente que contenido idéntico con sellos de tiempo más antiguos. Esta ventaja se mantuvo en aproximadamente 14% después de dos semanas, indicando que la actualidad proporciona un impulso sostenido pero decreciente gradualmente. El mecanismo detrás de esta priorización está basado en la filosofía de diseño de Sonar: el algoritmo trata el contenido desactualizado como un riesgo mayor de alucinación, asumiendo que la información obsoleta puede haber sido superada por desarrollos más recientes. La infraestructura de Perplexity procesa decenas de miles de solicitudes de actualización de índice por segundo, habilitando señales de actualidad en tiempo real. Un modelo de ML predice si una URL requiere reindexación y programa actualizaciones según la importancia de la página y su frecuencia histórica de actualización, asegurando que el contenido de alto valor se refresque de manera más agresiva. Incluso ediciones cosméticas menores reinician el reloj de actualidad, siempre que el CMS publique el sello de tiempo modificado. Para los editores, esto crea un imperativo estratégico: adoptar un ritmo de sala de redacción con actualizaciones semanales o diarias, o ver cómo el contenido perenne decae gradualmente en visibilidad. La implicancia es profunda—en la era Sonar, la velocidad de contenido no es una métrica de vanidad sino un mecanismo de supervivencia. Las marcas que automaticen micro-actualizaciones semanales, agreguen registros de cambios en vivo o mantengan flujos de trabajo de optimización continua del contenido asegurarán una cuota de citación desproporcionada frente a competidores que dependen de páginas estáticas y raramente actualizadas.
Relevancia Semántica y Estructura de Contenido Centrada en la Respuesta
Sonar prioriza la relevancia semántica sobre la densidad de palabras clave, recompensando fundamentalmente el contenido que responde directamente a las consultas de los usuarios en lenguaje natural y conversacional. El sistema de recuperación del algoritmo utiliza embeddings vectoriales densos para hacer coincidir consultas con contenido a nivel conceptual, lo que significa que páginas que usan sinónimos, terminología relacionada o lenguaje rico en contexto pueden superar a páginas saturadas de palabras clave pero sin profundidad semántica. Este cambio de un ranking centrado en palabras clave a uno centrado en significado tiene profundas implicancias para la estrategia de contenido. El contenido que triunfa en Sonar exhibe varias características estructurales: comienza con un resumen breve y factual antes de profundizar, utiliza encabezados H2/H3 descriptivos y párrafos cortos para facilitar la extracción de fragmentos, incluye citas claras y enlaces a fuentes primarias, y mantiene sellos de tiempo y notas de versión visibles para señalar actualidad. Cada párrafo funciona como una unidad semántica atómica, optimizada para claridad de copiar y pegar y comprensión por LLM. Las tablas, listas y gráficos etiquetados son especialmente valiosos porque presentan información en formatos estructurados y fácilmente citables. El algoritmo también recompensa análisis originales y datos únicos sobre la mera agregación, ya que el motor de síntesis de Sonar busca fuentes que aporten ángulos novedosos, documentos primarios o ideas propias que las distingan de resúmenes genéricos. Este énfasis en riqueza semántica y estructura centrada en la respuesta representa una ruptura fundamental con el SEO tradicional, donde reinaban la colocación de palabras clave y la autoridad de enlaces. En la era Sonar, el contenido debe estar diseñado para recuperación y síntesis por máquina, no para navegación humana.
Alojamiento de PDF como Ventaja Estratégica
Los PDF alojados públicamente representan una ventaja significativa y a menudo ignorada en el sistema de ranking de Sonar, con pruebas empíricas que revelan que las versiones PDF de contenido superan a los equivalentes en HTML en aproximadamente 22% en frecuencia de citación. Esta ventaja proviene de que el rastreador de Sonar trata favorablemente a los PDF frente a páginas HTML. Los PDF carecen de banners de cookies, requerimientos de renderizado JavaScript, autenticación de muros de pago y otras complicaciones HTML que pueden ocultar o retrasar el acceso al contenido. El rastreador de Sonar puede leer los PDF de manera limpia y predecible, extrayendo texto sin la ambigüedad de análisis que aqueja a las estructuras HTML complejas. Los editores pueden aprovechar estratégicamente esta ventaja alojando los PDF en directorios públicos, usando nombres de archivo semánticos que reflejen los temas del contenido y señalando el PDF como canónico mediante etiquetas <link rel="alternate" type="application/pdf"> en la cabecera HTML. Esto crea lo que los investigadores describen como una “trampa de miel para LLM”—un recurso de alta visibilidad que los scripts de seguimiento de la competencia no pueden detectar ni monitorear fácilmente. Para empresas B2B, proveedores SaaS y organizaciones orientadas a la investigación, esta estrategia es especialmente poderosa: publicar whitepapers, reportes de investigación, casos de estudio y documentación técnica como PDF puede aumentar drásticamente las tasas de citación en Sonar. La clave es tratar el PDF no como un añadido descargable, sino como una copia canónica digna de igual o mayor esfuerzo de optimización que la versión HTML. Este enfoque ha demostrado ser especialmente eficaz para contenido empresarial, donde los PDF suelen contener información más estructurada y autoritativa que las páginas web.
Esquema FAQ y Optimización de Datos Estructurados
El marcado de esquema FAQ en JSON-LD amplifica significativamente las tasas de citación en Sonar, con páginas que contienen tres o más bloques de FAQ recibiendo un 41% más de citas que las páginas de control sin esquema. Este salto dramático refleja la preferencia de Sonar por el contenido estructurado y basado en fragmentos que se alinea con su lógica de recuperación y síntesis. El esquema FAQ presenta unidades de Q&A discretas y autocontenidas que el algoritmo puede extraer, clasificar y citar como bloques semánticos atómicos. A diferencia del SEO tradicional, donde el esquema FAQ era un “nice-to-have”, Sonar trata el marcado estructurado de Q&A como un factor clave de ranking. Además, Sonar frecuentemente cita las preguntas de FAQ como texto ancla, reduciendo el riesgo de deriva de contexto que ocurre cuando el LLM resume cláusulas aleatorias a mitad de párrafo. El esquema también acelera el tiempo hasta la primera citación en aproximadamente seis horas, lo que sugiere que el parser de Sonar prioriza los bloques de Q&A estructurados al principio de la cascada de ranking. Para los editores, la estrategia de optimización es sencilla: incrustar de tres a cinco bloques de FAQ orientados bajo el pliegue, usando frases disparadoras conversacionales que reflejen preguntas reales de los usuarios. Las preguntas deben emplear frases de búsqueda de cola larga y simetría semántica con las probables consultas de Sonar. Cada respuesta debe ser concisa, factual y directamente responsiva, evitando relleno o lenguaje de marketing. Este enfoque ha demostrado ser especialmente eficaz para empresas SaaS, clínicas de salud y despachos profesionales, donde el contenido de FAQ se alinea naturalmente con la intención del usuario y las necesidades de síntesis de Sonar.
Factores de Ranking y Mecánica de Citación: Un Marco Integral
El sistema de ranking de Sonar integra múltiples señales en un marco unificado de citación, con investigaciones que identifican ocho factores principales que influyen en la selección de fuentes y frecuencia de citación. Primero, la relevancia semántica para la pregunta domina la recuperación, priorizando el algoritmo el contenido que responde claramente a la consulta en lenguaje natural. Segundo, la autoridad y credibilidad importan significativamente, con asociaciones editoriales de Perplexity e impulsos algorítmicos favoreciendo medios consolidados, instituciones académicas y expertos reconocidos. Tercero, la actualidad recibe un peso excepcional, como se discutió, con actualizaciones recientes que disparan incrementos de citación del 37%. Cuarto, la diversidad y cobertura son valoradas, ya que Sonar prefiere múltiples fuentes de alta calidad a respuestas de una sola fuente, reduciendo el riesgo de alucinación mediante validación cruzada. Quinto, el modo y alcance determinan qué índices busca Sonar—los modos de enfoque como Académico, Finanzas, Redacción y Social restringen tipos de fuentes, mientras que los selectores de fuente (Web, Org Files, Web + Org Files, Ninguno) determinan si la recuperación se realiza desde la web abierta, documentos internos o ambos. Sexto, citabilidad y acceso son críticos; si PerplexityBot puede rastrear e indexar el contenido, es más fácil de citar, haciendo esencial el cumplimiento de robots.txt y la velocidad de carga de la página. Séptimo, filtros de fuentes personalizados vía API permiten a implementaciones empresariales restringir o preferir ciertos dominios, alterando el ranking dentro de colecciones en lista blanca. Octavo, el contexto conversacional influye en las preguntas de seguimiento, donde páginas que coinciden con la intención evolutiva superan a referencias genéricas. Juntos, estos factores crean un espacio multidimensional de ranking donde el éxito requiere optimización simultánea en múltiples dimensiones, no sólo una palanca como backlinks o densidad de palabras clave.
Conclusiones Clave e Implicancias Estratégicas para la Optimización de Contenido
- La actualidad es innegociable: Automatiza actualizaciones semanales de contenido o micro-ediciones para reiniciar el reloj de actualidad y mantener la visibilidad de citación.
- La claridad semántica supera la densidad de palabras clave: Escribe con significado y estructura centrada en la respuesta, usando lenguaje natural y encabezados claros para facilitar la extracción por LLM.
- Los PDF son un activo estratégico: Aloja PDFs accesibles públicamente con enlaces canónicos para ganar un 22% de ventaja en citación sobre equivalentes en HTML.
- El esquema FAQ impulsa citaciones: Incluye tres o más bloques FAQ en JSON-LD con preguntas conversacionales para aumentar las tasas de citación un 41% y reducir el tiempo hasta la citación en seis horas.
- La citabilidad importa: Asegura que PerplexityBot pueda rastrear tu contenido, las páginas carguen rápido y el contenido esté estructurado para fácil extracción y cita.
- Los impulsos de autoridad son reales: Consigue menciones en plataformas de alta autoridad, establece alianzas editoriales y construye señales de experiencia verificable para activar impulsos algorítmicos.
- La diversidad es valorada: Proporciona datos únicos, análisis originales y documentos primarios que distingan tu contenido de agregaciones genéricas.
- Rastrea citaciones por separado: Monitorea la visibilidad en Sonar independientemente de los rankings de Google, ya que los patrones de citación difieren fundamentalmente entre sistemas de ranking.
Evolución Futura: Decodificación Especulativa, Ranking en Tiempo Real y el Imperativo de Velocidad
El Algoritmo Sonar está evolucionando rápidamente en respuesta a avances en inferencia LLM y tecnología de recuperación. El blog de ingeniería de Perplexity destacó recientemente la decodificación especulativa, una técnica que reduce a la mitad la latencia de tokens prediciendo múltiples tokens futuros simultáneamente. Bucles de generación más rápidos permiten al sistema permitirse conjuntos de recuperación más actuales en cada consulta, acortando la ventana en la que pueden competir páginas obsoletas. Se rumorea que un modelo Sonar-Reasoning-Pro ya supera a Gemini 2.0 Flash y GPT-4o Search en las evaluaciones de arena, lo que sugiere que la sofisticación del ranking de Sonar continuará avanzando. A medida que la latencia se aproxima a la velocidad del pensamiento humano, la competencia por las citas se convierte en un juego de alta frecuencia donde la velocidad de contenido es el diferenciador definitivo. Se esperan innovaciones de infraestructura emergentes como “APIs de frescura LLM” que auto-incrementen sellos de tiempo como antes lo hacía el ad-tech con precios de puja, creando nuevas dinámicas competitivas en torno a actualizaciones de contenido en tiempo real. También surgirán desafíos legales y éticos a medida que piratas de PDF exploten la preferencia de Sonar por PDF para absorber autoridad de e-books cerrados y estudios propietarios, lo que podría desencadenar nuevos controles de acceso o requisitos de autenticación. La implicancia general es clara: la era Sonar recompensa a los editores dispuestos a tratar cada párrafo como un manifiesto atómico, envuelto en esquema y con sello de tiempo, listo para el consumo de máquinas. Las marcas que se obsesionan con el ranking en la primera página de Google pero ignoran la visibilidad en Sonar están pintando vallas publicitarias en una ciudad cuyos habitantes acaban de adquirir visores de realidad virtual. El futuro pertenece a quienes optimizan por “porcentaje de answer boxes que contienen nuestra URL”, no por métricas tradicionales de CTR.
Conclusión: Algoritmo Sonar como Paradigma Definitorio de Ranking en la Búsqueda IA
El Algoritmo Sonar representa una reinvención fundamental de cómo los sistemas de ranking evalúan y priorizan el contenido en la era de los motores de respuestas potenciados por IA. Al combinar recuperación híbrida, re-ranqueo neuronal, señales de actualidad en tiempo real y estrictos requisitos de citación, Sonar ha creado un entorno de ranking donde señales SEO tradicionales como backlinks y densidad de palabras clave importan mucho menos que la relevancia semántica, la actualidad del contenido y la citabilidad. El énfasis del algoritmo en fundamentar las respuestas en fuentes verificables aborda uno de los desafíos más críticos de la IA generativa—las alucinaciones—al imponer el principio estricto de que los LLM no pueden afirmar nada que no hayan recuperado. Para editores y marcas, comprender los factores de ranking de Sonar ya no es opcional; es esencial para asegurar visibilidad en un panorama informativo cada vez más mediado por IA. El cambio de autoridad basada en enlaces a métricas de utilidad centradas en la respuesta requiere repensar fundamentalmente la estrategia de contenido, pasando de la optimización por palabras clave a la riqueza semántica, de páginas estáticas a activos continuamente actualizados, y de diseño centrado en humanos a estructura legible por máquinas. A medida que la cuota de mercado de Perplexity crece y otros motores de respuestas IA adoptan arquitecturas RAG similares, la influencia de Sonar solo se expandirá. Las marcas que prosperen en esta nueva era serán las que reconozcan a Sonar no como una amenaza para el SEO tradicional, sino como un sistema de ranking complementario que requiere estrategias de optimización distintas. Al tratar el contenido como unidades atómicas, con sello de tiempo y alineadas a esquemas, diseñadas para recuperación y síntesis por máquina, los editores pueden asegurar su lugar en las answer boxes potenciadas por IA que cada vez más median cómo los usuarios descubren y consumen información en línea.