
Datos de entrenamiento
Los datos de entrenamiento son el conjunto de datos utilizado para enseñar a los modelos de ML patrones y relaciones. Descubre cómo la calidad de los datos de e...
14 min de lectura

El entrenamiento con datos sintéticos es el proceso de entrenar modelos de IA utilizando datos generados artificialmente en lugar de información real creada por humanos. Este enfoque aborda la escasez de datos, acelera el desarrollo de modelos y preserva la privacidad, aunque introduce desafíos como el colapso del modelo y las alucinaciones, que requieren una gestión y validación cuidadosas.
El entrenamiento con datos sintéticos es el proceso de entrenar modelos de IA utilizando datos generados artificialmente en lugar de información real creada por humanos. Este enfoque aborda la escasez de datos, acelera el desarrollo de modelos y preserva la privacidad, aunque introduce desafíos como el colapso del modelo y las alucinaciones, que requieren una gestión y validación cuidadosas.
El entrenamiento con datos sintéticos se refiere al proceso de entrenar modelos de inteligencia artificial utilizando datos generados artificialmente en lugar de información real creada por humanos. A diferencia del entrenamiento tradicional de IA, que depende de conjuntos de datos auténticos recolectados a través de encuestas, observaciones o minería web, los datos sintéticos se crean mediante algoritmos y métodos computacionales que aprenden patrones estadísticos de datos existentes o generan datos completamente nuevos desde cero. Este cambio fundamental en la metodología de entrenamiento aborda un desafío crítico en el desarrollo moderno de IA: el crecimiento exponencial de las demandas computacionales ha superado la capacidad humana para generar suficientes datos reales, con investigaciones que indican que los datos de entrenamiento generados por humanos podrían agotarse en los próximos años. El entrenamiento con datos sintéticos ofrece una alternativa escalable y rentable que puede generarse infinitamente sin los procesos que consumen mucho tiempo de recolección, etiquetado y limpieza de datos que absorben hasta el 80% de los plazos tradicionales de desarrollo de IA.
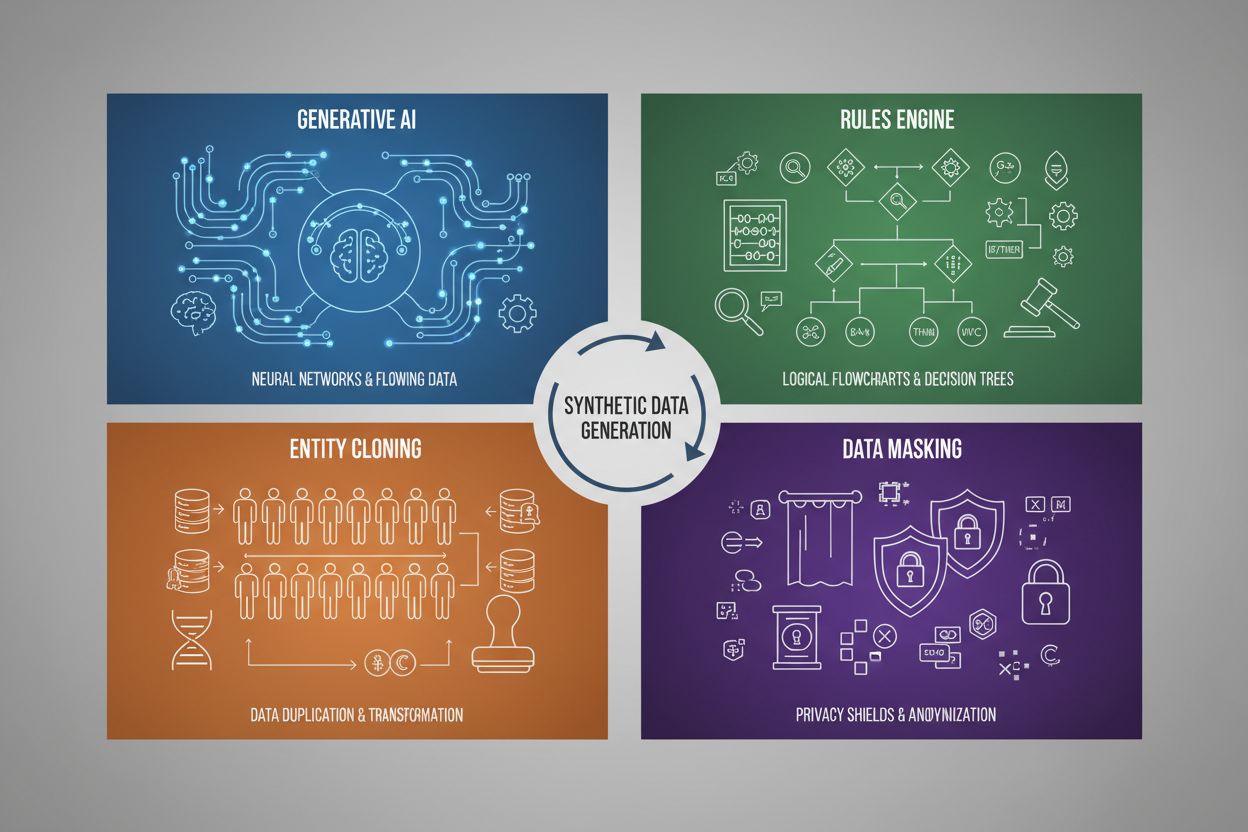
La generación de datos sintéticos emplea cuatro técnicas principales, cada una con mecanismos y aplicaciones distintos:
| Técnica | Cómo Funciona | Caso de Uso |
|---|---|---|
| IA Generativa (GANs, VAEs, GPT) | Utiliza modelos de aprendizaje profundo para aprender patrones y distribuciones estadísticas de datos reales, y luego genera nuevas muestras sintéticas que mantienen las mismas propiedades y relaciones estadísticas. Las GANs emplean redes adversarias donde un generador crea datos falsos y un discriminador evalúa la autenticidad, creando resultados cada vez más realistas. | Entrenamiento de grandes modelos de lenguaje como ChatGPT, generación de imágenes sintéticas con DALL-E, creación de conjuntos de datos diversos de texto para tareas de procesamiento de lenguaje natural |
| Motor de Reglas | Aplica reglas lógicas y restricciones predefinidas para generar datos que sigan una lógica empresarial específica, conocimiento del dominio o requisitos regulatorios. Este enfoque determinista garantiza que los datos generados cumplan con patrones y relaciones conocidas sin requerir aprendizaje automático. | Datos de transacciones financieras, registros médicos con requisitos de cumplimiento específicos, datos de sensores industriales con parámetros operativos conocidos |
| Clonación de Entidades | Duplica y modifica registros reales existentes aplicando transformaciones, perturbaciones o variaciones para crear nuevas instancias mientras se conservan las propiedades estadísticas y relaciones principales. Esta técnica mantiene la autenticidad de los datos mientras expande el tamaño del conjunto. | Expansión de conjuntos de datos limitados en industrias reguladas, creación de datos de entrenamiento para diagnóstico de enfermedades raras, aumento de conjuntos de datos con ejemplos insuficientes de clases minoritarias |
| Enmascaramiento y Anonimización de Datos | Oculta información sensible de identificación personal (PII) mientras preserva la estructura y relaciones estadísticas de los datos mediante técnicas como tokenización, cifrado o sustitución de valores. Esto crea versiones sintéticas y privadas de los datos reales. | Conjuntos de datos de salud y finanzas, datos de comportamiento de clientes, información personal sensible en contextos de investigación |
El entrenamiento con datos sintéticos ofrece reducciones sustanciales de costos al eliminar procesos costosos de recolección, anotación y limpieza de datos que tradicionalmente consumen importantes recursos y tiempo. Las organizaciones pueden generar muestras de entrenamiento ilimitadas bajo demanda, acelerando drásticamente los ciclos de desarrollo de modelos y permitiendo iteraciones y experimentación rápidas sin esperar a la recolección de datos reales. La técnica proporciona potentes capacidades de aumento de datos, permitiendo a los desarrolladores expandir conjuntos de datos limitados y crear conjuntos de entrenamiento equilibrados que aborden problemas de desbalance de clases, un problema crítico donde ciertas categorías están subrepresentadas en los datos reales. Los datos sintéticos resultan especialmente valiosos para enfrentar la escasez de datos en dominios especializados como la imagenología médica, el diagnóstico de enfermedades raras o las pruebas de vehículos autónomos, donde recolectar suficientes ejemplos reales es prohibitivamente costoso o éticamente complicado. La preservación de la privacidad representa una ventaja fundamental, ya que los datos sintéticos pueden generarse sin exponer información personal sensible, lo que los hace ideales para entrenar modelos con registros médicos, datos financieros u otra información regulada. Además, los datos sintéticos permiten la reducción sistemática de sesgo al posibilitar la creación intencionada de conjuntos de datos equilibrados y diversos que contrarrestan patrones discriminatorios presentes en los datos reales; por ejemplo, generando representaciones demográficas diversas en imágenes de entrenamiento para evitar que los modelos de IA perpetúen estereotipos de género o raza en aplicaciones de contratación, préstamos o justicia penal.
A pesar de su potencial, el entrenamiento con datos sintéticos introduce importantes desafíos técnicos y prácticos que pueden perjudicar el rendimiento del modelo si no se gestionan cuidadosamente. La preocupación más crítica es el colapso del modelo, un fenómeno en el que los modelos de IA entrenados extensamente con datos sintéticos experimentan una degradación severa en la calidad, precisión y coherencia de los resultados. Esto ocurre porque los datos sintéticos, aunque estadísticamente similares a los reales, carecen de la complejidad y casos límite presentes en la información humana auténtica; cuando los modelos se entrenan con contenido generado por IA, comienzan a amplificar errores y artefactos, generando un problema compuesto donde cada generación de datos sintéticos es progresivamente de menor calidad.
Los desafíos clave incluyen:
Estos desafíos resaltan por qué los datos sintéticos por sí solos no pueden reemplazar a los datos reales; en cambio, deben integrarse cuidadosamente como complemento de los conjuntos de datos auténticos, con estrictos controles de calidad y supervisión humana durante todo el proceso de entrenamiento.
A medida que los datos sintéticos se vuelven cada vez más prevalentes en el entrenamiento de modelos de IA, las marcas enfrentan un nuevo desafío crítico: garantizar una representación precisa y favorable en los resultados y citas generados por IA. Cuando los grandes modelos de lenguaje y sistemas generativos de IA se entrenan con datos sintéticos, la calidad y características de esos datos influyen directamente en cómo se describen, recomiendan y citan las marcas en resultados de búsqueda de IA, respuestas de chatbots y generación automatizada de contenido. Esto genera una preocupación significativa de seguridad de marca, ya que los datos sintéticos que contienen información desactualizada, sesgo de la competencia o descripciones inexactas de marca pueden integrarse en los modelos de IA, provocando representaciones erróneas persistentes en millones de interacciones de usuarios. Para las organizaciones que utilizan plataformas como AmICited.com para monitorear la presencia de su marca en sistemas de IA, comprender el papel de los datos sintéticos en el entrenamiento de modelos resulta esencial: las marcas necesitan visibilidad sobre si las citas y menciones de IA provienen de datos de entrenamiento reales o fuentes sintéticas, ya que esto afecta la credibilidad y precisión. La brecha de transparencia sobre el uso de datos sintéticos en el entrenamiento de IA crea desafíos de responsabilidad: las empresas no pueden determinar fácilmente si la información de su marca ha sido representada con precisión en los conjuntos de datos sintéticos utilizados para entrenar modelos que influyen en la percepción del consumidor. Las marcas visionarias deben priorizar el monitoreo de IA y el seguimiento de citas para detectar representaciones erróneas a tiempo, abogar por estándares de transparencia que exijan la divulgación del uso de datos sintéticos en el entrenamiento de IA y trabajar con plataformas que brinden información sobre cómo aparece su marca en sistemas de IA entrenados tanto con datos reales como sintéticos. A medida que los datos sintéticos se conviertan en el paradigma de entrenamiento dominante para 2030, el monitoreo de marca pasará del seguimiento de medios tradicional a una inteligencia integral de citas en IA, haciendo indispensable el uso de plataformas que rastreen la representación de marca en sistemas generativos de IA para proteger la integridad y garantizar la voz precisa de la marca en el ecosistema de información impulsado por IA.
El entrenamiento tradicional de IA se basa en datos del mundo real recolectados de humanos mediante encuestas, observaciones o minería web, lo cual es un proceso lento y cada vez más escaso. El entrenamiento con datos sintéticos utiliza datos generados artificialmente por algoritmos que aprenden patrones estadísticos de datos existentes o generan nuevos datos desde cero. Los datos sintéticos pueden producirse infinitamente bajo demanda, reduciendo drásticamente el tiempo y los costos de desarrollo y abordando preocupaciones de privacidad.
Las cuatro técnicas principales son: 1) IA Generativa (utilizando GANs, VAEs o modelos GPT para aprender y replicar patrones de datos), 2) Motor de Reglas (aplicando lógica empresarial y restricciones predefinidas), 3) Clonación de Entidades (duplicando y modificando registros existentes preservando propiedades estadísticas), y 4) Enmascaramiento de Datos (anonimizando información sensible manteniendo la estructura de datos). Cada técnica tiene diferentes casos de uso y ventajas específicas.
El colapso del modelo ocurre cuando los modelos de IA entrenados extensamente con datos sintéticos experimentan una degradación severa en la calidad y precisión de sus resultados. Esto sucede porque los datos sintéticos, aunque estadísticamente similares a los datos reales, carecen de la complejidad y casos límite presentes en la información auténtica. Cuando los modelos se entrenan con contenido generado por IA, amplifican errores y artefactos, generando un problema compuesto donde cada generación produce resultados de menor calidad hasta volverse inutilizables.
Cuando los modelos de IA se entrenan con datos sintéticos, la calidad y características de esos datos influyen directamente en cómo se describen, recomiendan y citan las marcas en los resultados de IA. Los datos sintéticos de baja calidad que contienen información desactualizada o sesgo de la competencia pueden integrarse en los modelos de IA, provocando una representación errónea persistente de la marca en millones de interacciones. Esto genera una preocupación de seguridad de marca que requiere monitoreo y transparencia sobre el uso de datos sintéticos en el entrenamiento de IA.
No, los datos sintéticos deben complementar y no reemplazar los datos reales. Aunque ofrecen ventajas significativas en costo, velocidad y privacidad, no pueden replicar completamente la complejidad, diversidad y casos límite presentes en los datos auténticos generados por humanos. El enfoque más efectivo combina datos sintéticos y reales, con estrictos controles de calidad y supervisión humana para asegurar precisión y confiabilidad del modelo.
Los datos sintéticos proporcionan una protección superior de la privacidad porque no contienen valores reales de los conjuntos de datos originales ni relaciones uno a uno con personas reales. A diferencia de las técnicas tradicionales de enmascaramiento o anonimización de datos, que pueden presentar riesgos de reidentificación, los datos sintéticos se crean completamente desde cero a partir de patrones aprendidos. Esto los hace ideales para entrenar modelos con información sensible como registros médicos, datos financieros o información de comportamiento personal sin exponer los datos reales de los individuos.
Los datos sintéticos permiten reducir sistemáticamente el sesgo al posibilitar la creación intencionada de conjuntos de datos equilibrados y diversos que contrarrestan patrones discriminatorios en los datos del mundo real. Por ejemplo, los desarrolladores pueden generar representaciones demográficas diversas en imágenes de entrenamiento para evitar que los modelos de IA perpetúen estereotipos de género o raza. Esta capacidad es especialmente valiosa en aplicaciones como contratación, préstamos y justicia penal, donde el sesgo puede tener consecuencias graves.
A medida que los datos sintéticos se conviertan en el paradigma de entrenamiento dominante para 2030, las marcas deben comprender cómo se representa su información en los sistemas de IA. La calidad de los datos sintéticos afecta directamente las citas y menciones de la marca en los resultados de IA. Las marcas deben monitorear su presencia en los sistemas de IA, abogar por estándares de transparencia que requieran la divulgación del uso de datos sintéticos y utilizar plataformas como AmICited.com para rastrear la representación de marca y detectar representaciones erróneas de forma temprana.
Descubre cómo se representa tu marca en los sistemas de IA entrenados con datos sintéticos. Rastrea citas, monitorea la precisión y garantiza la seguridad de tu marca en el ecosistema de información impulsado por IA.
Los datos de entrenamiento son el conjunto de datos utilizado para enseñar a los modelos de ML patrones y relaciones. Descubre cómo la calidad de los datos de e...

Guía completa para excluirse de la recopilación de datos para entrenamiento de IA en ChatGPT, Perplexity, LinkedIn y otras plataformas. Aprende instrucciones pa...
Comprende la diferencia entre los datos de entrenamiento de IA y la búsqueda en vivo. Descubre cómo los límites de conocimiento, RAG y la recuperación en tiempo...