
Gráfico
Descubre qué son los gráficos, sus tipos y cómo transforman datos en bruto en información procesable. Guía esencial sobre formatos de visualización de datos par...
10 min de lectura
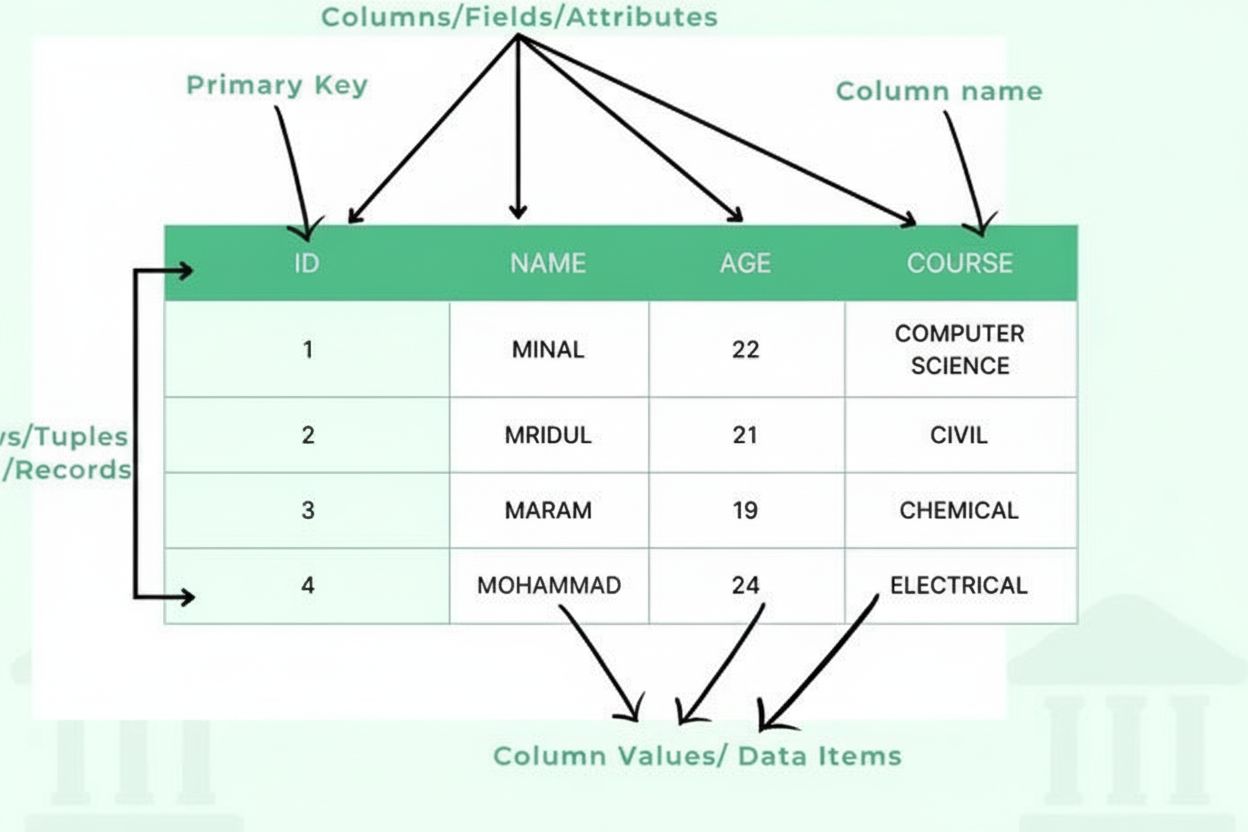
Una tabla es un método de organización de datos estructurados que dispone la información en un formato de cuadrícula bidimensional compuesto por filas horizontales y columnas verticales, lo que permite un almacenamiento, recuperación y análisis de datos eficiente. Las tablas constituyen el bloque fundamental de las bases de datos relacionales, hojas de cálculo y sistemas de presentación de datos, permitiendo a los usuarios localizar y comparar rápidamente información relacionada a través de múltiples dimensiones.
Una tabla es un método de organización de datos estructurados que dispone la información en un formato de cuadrícula bidimensional compuesto por filas horizontales y columnas verticales, lo que permite un almacenamiento, recuperación y análisis de datos eficiente. Las tablas constituyen el bloque fundamental de las bases de datos relacionales, hojas de cálculo y sistemas de presentación de datos, permitiendo a los usuarios localizar y comparar rápidamente información relacionada a través de múltiples dimensiones.
Una tabla es una estructura de datos fundamental que organiza la información en un formato de cuadrícula bidimensional compuesto por filas horizontales y columnas verticales. En su forma más básica, una tabla representa una colección de datos relacionados dispuestos de manera estructurada donde cada intersección de una fila y una columna contiene un único dato o celda. Las tablas sirven como la piedra angular de las bases de datos relacionales, hojas de cálculo, almacenes de datos y prácticamente cualquier sistema que requiera almacenamiento y recuperación de información organizada. La potencia de las tablas radica en su capacidad para permitir un escaneo visual rápido, comparaciones lógicas de datos a través de múltiples dimensiones y acceso programático a información específica mediante lenguajes de consulta estandarizados. Ya sea en análisis de negocios, investigación científica o plataformas de monitoreo de IA, las tablas proporcionan un formato universalmente comprendido para presentar datos estructurados que pueden ser fácilmente interpretados tanto por humanos como por máquinas.
El concepto de organizar información en filas y columnas es anterior a la computación moderna por siglos. Las civilizaciones antiguas usaban formatos tabulares para registrar inventarios, transacciones financieras y observaciones astronómicas. Sin embargo, la formalización de las estructuras de tabla en computación surgió con el desarrollo de la teoría de bases de datos relacionales por Edgar F. Codd en 1970, lo que revolucionó la forma en que los datos podían almacenarse y consultarse. El modelo relacional estableció que los datos debían organizarse en tablas con relaciones claramente definidas, cambiando fundamentalmente los principios de diseño de bases de datos. Durante los años 80 y 90, aplicaciones de hojas de cálculo como Lotus 1-2-3 y Microsoft Excel democratizaron el uso de tablas, haciendo accesible la organización de datos tabulares a usuarios no técnicos. Hoy en día, aproximadamente el 97% de las organizaciones utilizan aplicaciones de hojas de cálculo para la gestión y análisis de datos, demostrando la relevancia perdurable de la organización de datos basada en tablas. La evolución continúa con desarrollos modernos en bases de datos columnares, sistemas NoSQL y lakes de datos, que desafían los enfoques tradicionales orientados a filas mientras mantienen estructuras fundamentales similares a tablas para organizar la información.
Una tabla consta de varios componentes estructurales esenciales que trabajan en conjunto para crear un marco de datos organizado. Las columnas (también llamadas campos o atributos) corren verticalmente y representan categorías de información, como “Nombre del Cliente”, “Correo Electrónico” o “Fecha de Compra”. Cada columna tiene un tipo de dato definido que especifica qué tipo de información puede contener—enteros, cadenas de texto, fechas, decimales o estructuras más complejas. Las filas (también llamadas registros o tuplas) corren horizontalmente y representan entradas o entidades de datos individuales, cada una conteniendo un registro completo. La intersección de una fila y una columna crea una celda o dato, que contiene una sola pieza de información. Los encabezados de columna identifican cada columna y aparecen en la parte superior de la tabla, proporcionando contexto para los datos inferiores. Las claves primarias son columnas especiales que identifican de forma única cada fila, asegurando que no existan registros duplicados. Las claves foráneas establecen relaciones entre tablas al referenciar claves primarias en otras tablas. Esta organización jerárquica permite a las bases de datos mantener la integridad de los datos, prevenir la redundancia y soportar consultas complejas que recuperan información basada en múltiples criterios.
| Aspecto | Tablas orientadas a filas | Tablas orientadas a columnas | Enfoques híbridos |
|---|---|---|---|
| Método de almacenamiento | Datos almacenados y accedidos por registros completos | Datos almacenados y accedidos por columnas individuales | Combina beneficios de ambos enfoques |
| Rendimiento de consulta | Optimizado para consultas transaccionales que recuperan registros completos | Optimizado para consultas analíticas en columnas específicas | Rendimiento equilibrado para cargas mixtas |
| Casos de uso | OLTP (Procesamiento de transacciones en línea), operaciones empresariales | OLAP (Procesamiento analítico en línea), almacenes de datos | Analítica en tiempo real, inteligencia operativa |
| Ejemplos de bases de datos | MySQL, PostgreSQL, Oracle, SQL Server | Vertica, Cassandra, HBase, Parquet | Snowflake, BigQuery, Apache Iceberg |
| Eficiencia de compresión | Tasas de compresión más bajas debido a la diversidad de datos | Tasas de compresión más altas para valores similares en columnas | Compresión optimizada para patrones específicos |
| Rendimiento de escritura | Escrituras rápidas para registros completos | Escrituras más lentas por requerir actualización de columnas | Rendimiento de escritura equilibrado |
| Escalabilidad | Escala bien para volumen de transacciones | Escala bien para volumen de datos y complejidad de consultas | Escala en ambas dimensiones |
En los sistemas de gestión de bases de datos relacionales (RDBMS), las tablas se implementan como colecciones estructuradas de filas donde cada fila se ajusta a un esquema predefinido. El esquema define la estructura de la tabla, especificando nombres de columnas, tipos de datos, restricciones y relaciones. Cuando se insertan datos en una tabla, el sistema de gestión de bases de datos valida que cada valor coincida con el tipo de dato de su columna y cumpla las restricciones definidas. Por ejemplo, una columna definida como INTEGER rechazará valores de texto, y una columna marcada como NOT NULL rechazará entradas vacías. Se crean índices en columnas consultadas frecuentemente para acelerar la recuperación de datos, funcionando como referencias organizadas que permiten a la base de datos localizar filas específicas sin escanear toda la tabla. La normalización es un principio de diseño que organiza las tablas para minimizar la redundancia de datos y mejorar la integridad al dividir la información en tablas relacionadas unidas por claves. Las bases de datos modernas soportan transacciones, que aseguran que múltiples operaciones en tablas sean exitosas todas juntas o fracasen completamente, manteniendo la consistencia incluso ante fallos del sistema. El optimizador de consultas en los motores de bases de datos analiza las consultas SQL y determina la forma más eficiente de acceder a los datos de la tabla, considerando los índices disponibles y las estadísticas de las tablas.
Las tablas son el mecanismo principal para presentar datos estructurados a los usuarios tanto en formatos digitales como impresos. En aplicaciones de inteligencia empresarial y analítica, las tablas muestran métricas agregadas, indicadores de rendimiento y registros detallados de transacciones que permiten a los responsables de la toma de decisiones comprender conjuntos de datos complejos de un vistazo. Investigaciones indican que el 83% de los profesionales empresariales dependen de las tablas de datos como su herramienta principal para analizar información, ya que las tablas permiten comparaciones precisas de valores y reconocimiento de patrones. Las tablas HTML en sitios web utilizan marcado semántico con los elementos <table>, <tr> (fila de tabla), <td> (dato de tabla) y <th> (encabezado de tabla) para estructurar los datos tanto para su visualización como para su interpretación programática. Las aplicaciones de hojas de cálculo como Microsoft Excel, Google Sheets y LibreOffice Calc amplían la funcionalidad básica de las tablas con fórmulas, formato condicional y tablas dinámicas que permiten a los usuarios realizar cálculos y reorganizar datos de manera dinámica. Las mejores prácticas de visualización de datos recomiendan usar tablas cuando los valores precisos son más importantes que los patrones visuales, al comparar múltiples atributos de registros individuales, o cuando los usuarios necesitan realizar búsquedas o cálculos. La Iniciativa de Accesibilidad Web (W3C) destaca que las tablas correctamente estructuradas con encabezados claros y marcado apropiado son esenciales para hacer los datos accesibles a usuarios con discapacidades, en particular a quienes utilizan lectores de pantalla.
En el contexto de las plataformas de monitoreo de IA como AmICited, las tablas desempeñan un papel crítico en la organización y presentación de datos sobre cómo aparece el contenido en diferentes sistemas de IA. Las tablas de monitoreo rastrean métricas como la frecuencia de citación, fechas de aparición, fuentes de plataformas de IA (ChatGPT, Perplexity, Google AI Overviews, Claude) e información contextual sobre cómo se referencian dominios y URLs. Estas tablas permiten a las organizaciones entender su visibilidad de marca en las respuestas generadas por IA e identificar tendencias en cómo los distintos sistemas de IA citan o referencian su contenido. La naturaleza estructurada de las tablas de monitoreo permite filtrar, ordenar y agregar los datos de citaciones, haciendo posible responder preguntas como “¿Cuáles de nuestras URLs aparecen con mayor frecuencia en las respuestas de Perplexity?” o “¿Cómo ha cambiado nuestra tasa de citaciones en el último mes?” Las tablas de datos en sistemas de monitoreo también facilitan la comparación a través de múltiples dimensiones—comparando patrones de citación entre diferentes plataformas de IA, analizando el crecimiento de citaciones a lo largo del tiempo o identificando qué tipos de contenido reciben más referencias de IA. La capacidad de exportar datos de monitoreo de tablas hacia informes, paneles de control y herramientas de análisis adicionales hace que las tablas sean indispensables para las organizaciones que buscan entender y optimizar su presencia en contenido generado por IA.
Un diseño efectivo de tablas requiere una consideración cuidadosa de la estructura, convenciones de nomenclatura y principios de organización de datos. La nomenclatura de columnas debe usar identificadores claros y descriptivos que reflejen con precisión los datos que contienen, evitando abreviaturas que puedan confundir a usuarios o desarrolladores. La selección de tipos de datos es crítica—elegir tipos apropiados previene la entrada de datos inválidos y permite operaciones de ordenamiento y comparación correctas. La definición de clave primaria asegura que cada fila pueda ser identificada de forma única, lo cual es esencial para la integridad de los datos y el establecimiento de relaciones con otras tablas. La normalización reduce la redundancia de datos organizando la información en tablas relacionadas en lugar de almacenar datos duplicados en múltiples ubicaciones. La estrategia de indexación debe equilibrar el rendimiento de las consultas frente al coste de mantenimiento de los índices durante las modificaciones de datos. La documentación de la estructura de la tabla, incluyendo definiciones de columnas, tipos de datos, restricciones y relaciones, es esencial para el mantenimiento a largo plazo. El control de acceso debe implementarse para asegurar que los datos sensibles en las tablas estén protegidos contra accesos no autorizados. La optimización del rendimiento implica monitorear los tiempos de ejecución de las consultas y ajustar las estructuras de tabla, índices o consultas para mejorar la eficiencia. Los procedimientos de respaldo y recuperación deben establecerse para proteger los datos de las tablas frente a pérdidas o corrupción.
El futuro de la organización de datos basada en tablas está evolucionando para satisfacer requerimientos de datos cada vez más complejos, manteniendo los principios fundamentales que hacen efectivas a las tablas. Los formatos de almacenamiento columnar como Apache Parquet y ORC se están convirtiendo en estándar en entornos de big data, optimizando las tablas para cargas de trabajo analíticas mientras mantienen la estructura tabular. Los datos semiestructurados en formatos JSON y XML se almacenan cada vez más dentro de columnas de tablas, permitiendo que las tablas acomoden tanto datos estructurados como flexibles. La integración del aprendizaje automático está permitiendo que las bases de datos optimicen automáticamente las estructuras de las tablas y la ejecución de consultas según los patrones de uso. Las plataformas de analítica en tiempo real están extendiendo las tablas para soportar datos en streaming y actualizaciones continuas, yendo más allá de las operaciones tradicionales por lotes. Las bases de datos nativas en la nube están rediseñando las implementaciones de tablas para aprovechar la computación distribuida, permitiendo que las tablas escalen entre múltiples servidores y regiones geográficas. Los marcos de gobernanza de datos están poniendo mayor énfasis en los metadatos de tablas, el seguimiento de linaje y métricas de calidad para garantizar la fiabilidad de los datos. La aparición de plataformas de datos impulsadas por IA está creando nuevas oportunidades para que las tablas sirvan como fuentes estructuradas para el entrenamiento de modelos de aprendizaje automático, al tiempo que plantea interrogantes sobre cómo deben diseñarse las tablas para proporcionar datos de entrenamiento de alta calidad. A medida que las organizaciones continúan generando cantidades exponencialmente mayores de datos, las tablas siguen siendo la estructura fundamental para organizar, consultar y analizar información, con innovaciones centradas en mejorar el rendimiento, la escalabilidad y la integración con tecnologías modernas de datos.
Una fila es una disposición horizontal de datos que representa un solo registro o entidad, mientras que una columna es una disposición vertical que representa un atributo o campo específico compartido entre todos los registros. En una tabla de base de datos, cada fila contiene información completa sobre una entidad (como un cliente), y cada columna contiene un tipo de información (como el nombre o correo electrónico del cliente). Juntas, las filas y columnas crean la estructura bidimensional que define una tabla.
Las tablas son la estructura organizativa fundamental en las bases de datos relacionales, permitiendo un almacenamiento, recuperación y manipulación de datos eficiente. Permiten que las bases de datos mantengan la integridad de los datos mediante esquemas estructurados, admitan consultas complejas a través de múltiples dimensiones y faciliten las relaciones entre diferentes entidades de datos mediante claves primarias y foráneas. Las tablas hacen posible organizar millones de registros de una manera eficiente computacionalmente y lógica para las operaciones empresariales.
Una tabla consta de varios componentes esenciales: columnas (campos/atributos) que definen tipos y categorías de datos, filas (registros/tuplas) que contienen entradas de datos individuales, encabezados que identifican cada columna, elementos de datos (celdas) que almacenan valores reales, claves primarias que identifican de forma única cada fila y, potencialmente, claves foráneas que establecen relaciones con otras tablas. Cada componente cumple un papel crítico en el mantenimiento de la organización e integridad de los datos.
En plataformas de monitoreo de IA como AmICited, las tablas son fundamentales para organizar y presentar datos sobre apariciones de modelos de IA, citas y menciones de marca en diferentes sistemas de IA. Las tablas permiten a los sistemas de monitoreo mostrar datos estructurados sobre cuándo y dónde aparece el contenido en las respuestas de la IA, facilitando el seguimiento de métricas, la comparación del rendimiento entre plataformas y la identificación de tendencias en cómo los sistemas de IA citan o hacen referencia a dominios y URLs específicos.
Las bases de datos orientadas a filas (como las bases de datos relacionales tradicionales) almacenan y acceden a los datos por registros completos, lo que las hace eficientes para transacciones donde se necesita toda la información sobre una entidad. Las bases de datos orientadas a columnas almacenan los datos por columna, lo que las hace más rápidas para consultas analíticas que requieren atributos específicos a través de muchos registros. La elección entre estos enfoques depende de si su caso de uso principal implica operaciones transaccionales o consultas analíticas.
Las tablas accesibles requieren un marcado HTML adecuado utilizando elementos semánticos como `
Las columnas de una tabla pueden almacenar diversos tipos de datos, incluidos enteros, números de punto flotante, cadenas/textos, fechas y horas, booleanos y tipos cada vez más complejos como JSON o XML. Cada columna tiene un tipo de dato definido que limita los valores que se pueden ingresar, garantizando la coherencia de los datos y permitiendo operaciones de ordenamiento y comparación adecuadas. Algunas bases de datos también admiten tipos especializados como datos geográficos, arreglos o tipos personalizados definidos por el usuario.
Comienza a rastrear cómo los chatbots de IA mencionan tu marca en ChatGPT, Perplexity y otras plataformas. Obtén información procesable para mejorar tu presencia en IA.
Descubre qué son los gráficos, sus tipos y cómo transforman datos en bruto en información procesable. Guía esencial sobre formatos de visualización de datos par...
La visualización de datos es la representación gráfica de datos mediante gráficos, diagramas y paneles. Descubre cómo los datos visuales transforman información...
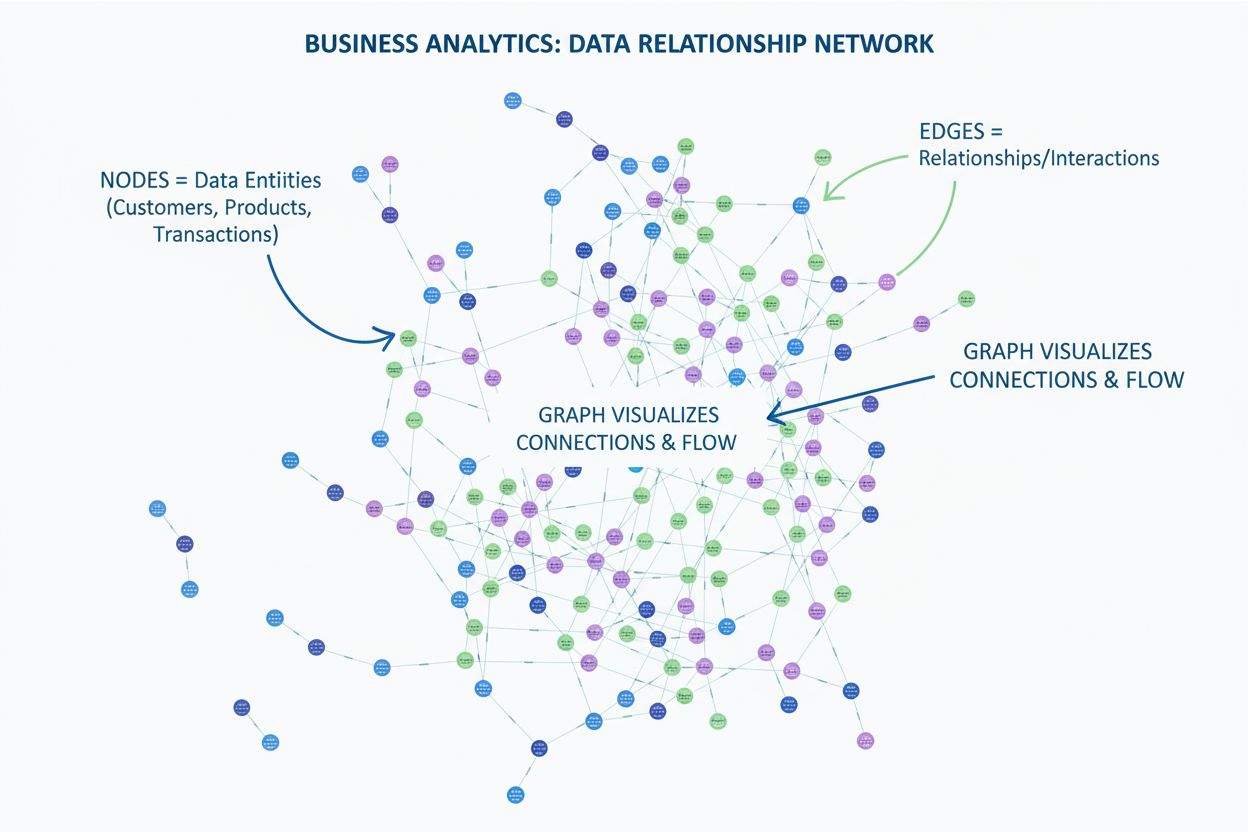
Aprende qué es un gráfico en la visualización de datos. Descubre cómo los gráficos muestran relaciones entre datos utilizando nodos y aristas, y por qué son ese...