Content Pruning
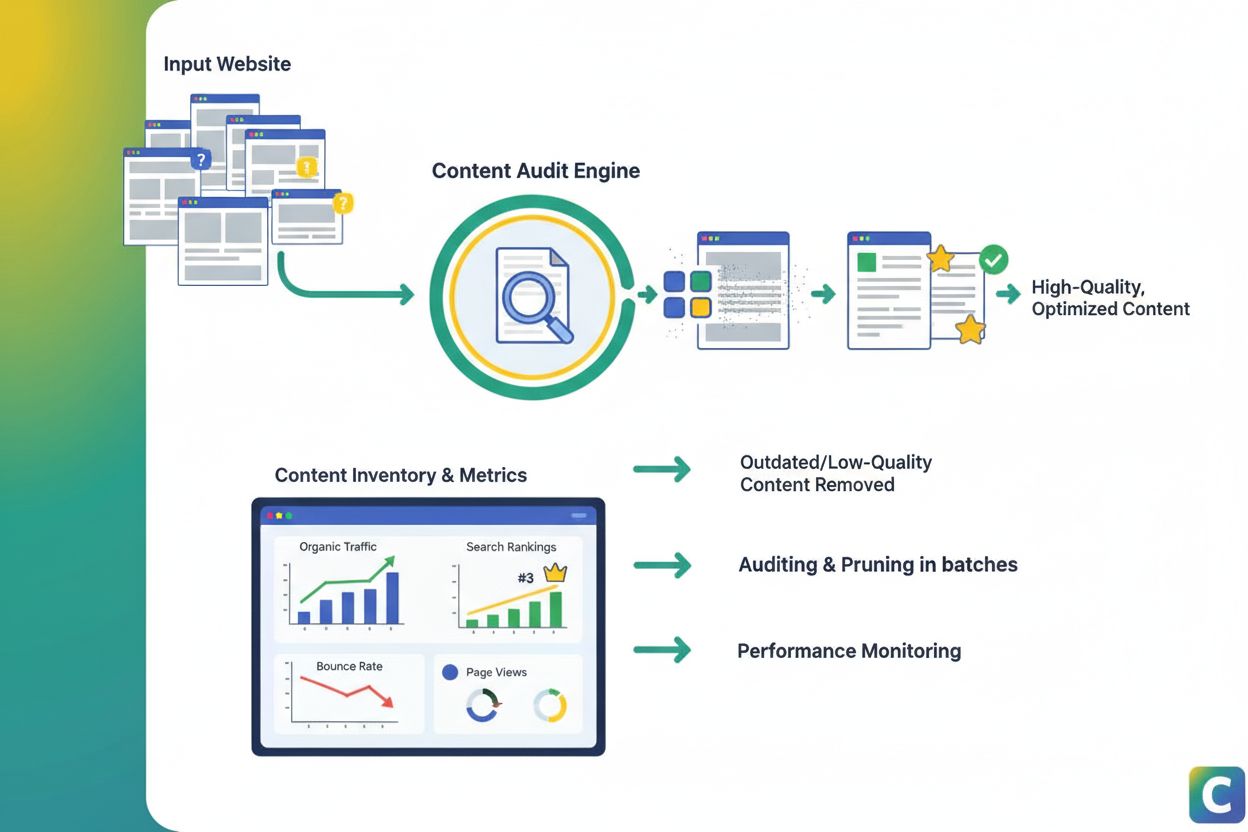
Content pruning is the strategic removal or updating of underperforming content to improve SEO, user experience, and search visibility. Learn how to identify an...
15 min read

Learn what content pruning for AI is, how it works, different pruning methods, and why it’s essential for deploying efficient AI models on edge devices and resource-constrained environments.
Content pruning for AI is a technique that selectively removes redundant or less important parameters, weights, or tokens from AI models to reduce their size, improve inference speed, and lower memory consumption while maintaining performance quality.
Content pruning for AI is a fundamental optimization technique used to reduce the computational complexity and memory footprint of artificial intelligence models without significantly compromising their performance. This process involves systematically identifying and removing redundant or less important components from neural networks, including individual weights, entire neurons, filters, or even tokens in language models. The primary goal is to create leaner, faster, and more efficient models that can be deployed effectively on resource-constrained devices such as smartphones, edge computing systems, and IoT devices.
The concept of pruning draws inspiration from biological systems, specifically synaptic pruning in the human brain, where unnecessary neural connections are eliminated during development. Similarly, AI pruning recognizes that trained neural networks often contain many parameters that contribute minimally to the final output. By removing these redundant components, developers can achieve substantial reductions in model size while maintaining or even improving accuracy through careful fine-tuning processes.
Content pruning operates on the principle that not all parameters in a neural network are equally important for making predictions. During the training process, neural networks develop complex interconnections, many of which become redundant or contribute negligibly to the model’s decision-making process. Pruning identifies these less critical components and removes them, resulting in a sparse network architecture that requires fewer computational resources to operate.
The effectiveness of pruning depends on several factors, including the pruning method employed, the aggressiveness of the pruning strategy, and the subsequent fine-tuning process. Different pruning approaches target different aspects of neural networks. Some methods focus on individual weights (unstructured pruning), while others remove entire neurons, filters, or channels (structured pruning). The choice of method significantly impacts both the resulting model efficiency and the compatibility with modern hardware accelerators.
| Pruning Type | Target | Benefits | Challenges |
|---|---|---|---|
| Weight Pruning | Individual connections/weights | Maximum compression, sparse networks | May not accelerate hardware execution |
| Structured Pruning | Neurons, filters, channels | Hardware-friendly, faster inference | Less compression than unstructured |
| Dynamic Pruning | Context-dependent parameters | Adaptive efficiency, real-time adjustment | Complex implementation, higher overhead |
| Layer Pruning | Entire layers or blocks | Significant size reduction | Risk of accuracy loss, requires careful validation |
Unstructured pruning, also known as weight pruning, operates at the granular level by removing individual weights from the network’s weight matrices. This approach typically uses magnitude-based criteria, where weights with values close to zero are considered less important and are eliminated. The resulting network becomes sparse, meaning that only a fraction of the original connections remain active during inference. While unstructured pruning can achieve impressive compression ratios—sometimes reducing parameter counts by 90% or more—the resulting sparse networks may not always translate to proportional speed improvements on standard hardware without specialized sparse computation support.
Structured pruning takes a different approach by removing entire groups of parameters simultaneously, such as complete filters in convolutional layers, entire neurons in fully connected layers, or whole channels. This method is particularly valuable for practical deployment because the resulting models are naturally compatible with modern hardware accelerators like GPUs and TPUs. When entire filters are pruned from convolutional layers, the computational savings are immediately realized without requiring specialized sparse matrix operations. Research has demonstrated that structured pruning can reduce model size by 50-90% while maintaining comparable accuracy to the original models.
Dynamic pruning represents a more sophisticated approach where the pruning process adapts during model inference based on the specific input being processed. This technique leverages external context such as speaker embeddings, event cues, or language-specific information to dynamically adjust which parameters are active. In retrieval-augmented generation systems, dynamic pruning can reduce context size by approximately 80% while simultaneously improving answer accuracy by filtering out irrelevant information. This adaptive approach is particularly valuable for multimodal AI systems that must process diverse input types efficiently.
Iterative pruning and fine-tuning represents one of the most widely adopted approaches in practice. This method involves a cyclical process: prune a portion of the network, fine-tune the remaining parameters to recover lost accuracy, evaluate performance, and repeat. The iterative nature of this approach allows developers to carefully balance model compression with performance maintenance. Rather than removing all unnecessary parameters at once—which could catastrophically damage model performance—iterative pruning gradually reduces network complexity while allowing the model to adapt and learn which remaining parameters are most critical.
One-shot pruning offers a faster alternative where the entire pruning operation occurs in a single step after training, followed by a fine-tuning phase. While this approach is computationally more efficient than iterative methods, it carries higher risk of accuracy degradation if too many parameters are removed simultaneously. One-shot pruning is particularly useful when computational resources for iterative processes are limited, though it typically requires more extensive fine-tuning to recover performance.
Sensitivity analysis-based pruning employs a more sophisticated ranking mechanism by measuring how much the model’s loss function increases when specific weights or neurons are removed. Parameters that have minimal impact on the loss function are identified as safe candidates for pruning. This data-driven approach provides more nuanced pruning decisions compared to simple magnitude-based methods, often resulting in better accuracy preservation at equivalent compression levels.
The Lottery Ticket Hypothesis presents an intriguing theoretical framework suggesting that within large neural networks exists a smaller, sparse sub-network—the “winning ticket”—that can achieve comparable accuracy to the original network when trained from the same initialization. This hypothesis has profound implications for understanding network redundancy and has inspired new pruning methodologies that attempt to identify and isolate these efficient sub-networks.
Content pruning has become indispensable across numerous AI applications where computational efficiency is paramount. Mobile and embedded device deployment represents one of the most significant use cases, where pruned models enable sophisticated AI capabilities on smartphones and IoT devices with limited processing power and battery capacity. Image recognition, voice assistants, and real-time translation applications all benefit from pruned models that maintain accuracy while consuming minimal resources.
Autonomous systems including self-driving vehicles and drones require real-time decision-making with minimal latency. Pruned neural networks enable these systems to process sensor data and make critical decisions within strict time constraints. The reduced computational overhead directly translates to faster response times, which is essential for safety-critical applications.
In cloud and edge computing environments, pruning reduces both computational costs and storage requirements for deploying large-scale models. Organizations can serve more users with the same infrastructure, or alternatively, reduce their computational expenses significantly. Edge computing scenarios particularly benefit from pruned models, as they enable sophisticated AI processing on devices far from centralized data centers.
Evaluating pruning effectiveness requires careful consideration of multiple metrics beyond simple parameter count reduction. Inference latency—the time required for a model to generate output from input—is a critical metric that directly impacts user experience in real-time applications. Effective pruning should substantially reduce inference latency, enabling faster response times for end users.
Model accuracy and F1 scores must be maintained throughout the pruning process. The fundamental challenge in pruning is achieving significant compression without sacrificing predictive performance. Well-designed pruning strategies maintain accuracy within 1-5% of the original model while achieving 50-90% parameter reduction. Memory footprint reduction is equally important, as it determines whether models can be deployed on resource-constrained devices.
Research comparing large-sparse models (large networks with many parameters removed) against small-dense models (smaller networks trained from scratch) with identical memory footprints consistently shows that large-sparse models outperform their small-dense counterparts. This finding underscores the value of starting with larger, well-trained networks and pruning them strategically rather than attempting to train smaller networks from the beginning.
Accuracy degradation remains the primary challenge in content pruning. Aggressive pruning can substantially reduce model performance, requiring careful calibration of pruning intensity. Developers must find the optimal balance point where compression gains are maximized without unacceptable accuracy loss. This balance point varies depending on the specific application, model architecture, and acceptable performance thresholds.
Hardware compatibility issues can limit the practical benefits of pruning. While unstructured pruning creates sparse networks with fewer parameters, modern hardware is optimized for dense matrix operations. Sparse networks may not execute significantly faster on standard GPUs without specialized sparse computation libraries and hardware support. Structured pruning addresses this limitation by maintaining dense computation patterns, though at the cost of less aggressive compression.
Computational overhead of pruning methods themselves can be substantial. Iterative pruning and sensitivity analysis-based approaches require multiple training passes and careful evaluation, consuming significant computational resources. Developers must weigh the one-time cost of pruning against the ongoing savings from deploying more efficient models.
Generalization concerns arise when pruning is too aggressive. Models pruned excessively may perform well on training and validation data but generalize poorly to new, unseen data. Proper validation strategies and careful testing on diverse datasets are essential to ensure pruned models maintain robust performance in production environments.
Successful content pruning requires a systematic approach grounded in best practices developed through extensive research and practical experience. Start with larger, well-trained networks rather than attempting to train smaller networks from scratch. Larger networks provide more redundancy and flexibility for pruning, and research consistently demonstrates that pruned large networks outperform small networks trained from the beginning.
Use iterative pruning with careful fine-tuning to gradually reduce model complexity while maintaining performance. This approach provides better control over the accuracy-efficiency tradeoff and allows the model to adapt to parameter removal. Employ structured pruning for practical deployment when hardware acceleration is important, as it produces models that execute efficiently on standard hardware without requiring specialized sparse computation support.
Validate extensively on diverse datasets to ensure pruned models generalize well beyond training data. Monitor multiple performance metrics including accuracy, inference latency, memory usage, and power consumption to comprehensively evaluate pruning effectiveness. Consider the target deployment environment when selecting pruning strategies, as different devices and platforms have different optimization characteristics.
The field of content pruning continues to evolve with emerging techniques and methodologies. Contextually Adaptive Token Pruning (CATP) represents a cutting-edge approach that uses semantic alignment and feature diversity to selectively retain only the most relevant tokens in language models. This technique is particularly valuable for large language models and multimodal systems where context management is critical.
Integration with vector databases like Pinecone and Weaviate enables more sophisticated context pruning strategies by efficiently storing and retrieving relevant information. These integrations support dynamic pruning decisions based on semantic similarity and relevance scoring, enhancing both efficiency and accuracy.
Combination with other compression techniques such as quantization and knowledge distillation creates synergistic effects, enabling even more aggressive model compression. Models that are simultaneously pruned, quantized, and distilled can achieve 100x or greater compression ratios while maintaining acceptable performance levels.
As AI models continue to grow in complexity and deployment scenarios become increasingly diverse, content pruning will remain a critical technique for making advanced AI accessible and practical across the full spectrum of computing environments, from powerful data centers to resource-constrained edge devices.
Discover how AmICited helps you track when your content appears in AI-generated answers across ChatGPT, Perplexity, and other AI search engines. Ensure your brand visibility in the AI-powered future.
Content pruning is the strategic removal or updating of underperforming content to improve SEO, user experience, and search visibility. Learn how to identify an...

Learn essential strategies to optimize your support content for AI systems like ChatGPT, Perplexity, and Google AI Overviews. Discover best practices for clarit...
Community discussion on content pruning for AI visibility. When to remove old content, when to consolidate, and when to leave content alone.