Pagination
Pagination divides large content sets into manageable pages for better UX and SEO. Learn how pagination works, its impact on search rankings, and best practices...
9 min read

Learn how pagination impacts AI visibility. Discover why traditional page division helps AI systems find your content while infinite scroll hides it, and how to optimize pagination for AI answer generators.
Pagination is the practice of dividing large content sets into multiple linked pages. Yes, it significantly affects AI systems—pagination creates distinct, crawlable URLs that help AI search engines like ChatGPT, Perplexity, and Google's SGE discover and index your content more effectively, while infinite scroll implementations often hide content from AI crawlers.
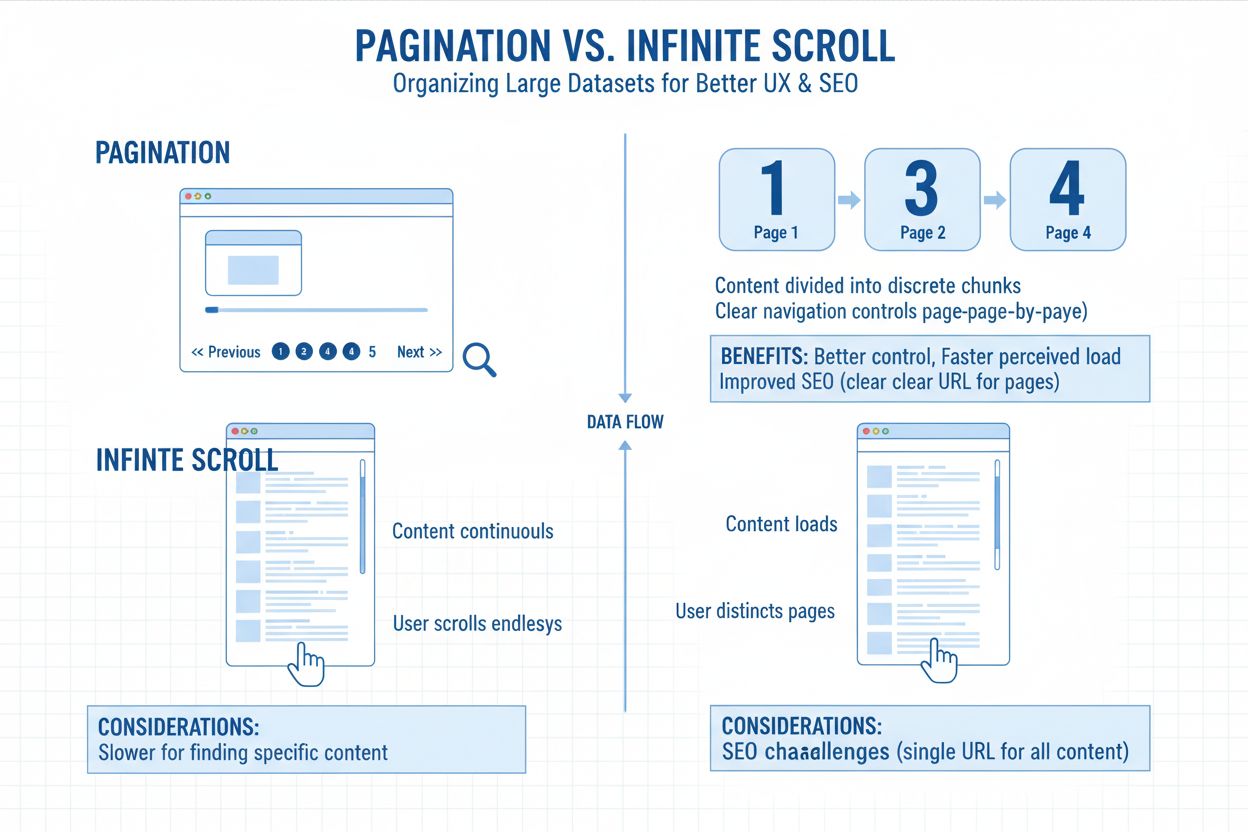
Pagination refers to the practice of dividing large sets of content into multiple linked pages rather than displaying everything on a single, endless screen. Think of it like chapters in a book—each page contains a manageable portion of total content, connected through numbered links or “next/previous” buttons. This structural approach appears everywhere from product listings in eCommerce stores to blog archives, forum threads, and search results. The URL structure typically reflects this division through parameters like ?page=2 or clean paths like /category/page/2/, allowing both users and search engines to understand their position within the content series. Pagination serves as a fundamental organizational tool that balances user experience with technical requirements for content accessibility.
Websites implement pagination primarily for performance optimization and content organization. Loading hundreds or thousands of items simultaneously would strain server resources and create sluggish page load times, particularly damaging to performance metrics that affect search rankings. Users appreciate the ability to bookmark specific pages, jump directly to page 10, or understand how much content remains available. From a technical perspective, dividing content creates distinct URLs that search engines can index individually, preserving link equity distribution across your site architecture. This structural clarity becomes increasingly important as AI systems evolve to understand content relationships and accessibility patterns.
The relationship between pagination and AI visibility represents one of the most critical technical SEO considerations in the modern search landscape. Traditional search engines like Google have long understood pagination through crawling links and following sequential page patterns. However, AI-powered search engines and answer generators operate fundamentally differently, requiring a more nuanced approach to content organization. Large language models like those powering ChatGPT, Perplexity, and Google’s Search Generative Experience (SGE) don’t necessarily crawl pages linearly or follow traditional navigation hierarchies. Instead, they work by tokenizing and summarizing textual input—often sourced from public data, APIs, or structured databases rather than crawl-depth hierarchies.
When your content is scattered across multiple, minimally structured pages, AI engines may skip over deeper entries or misunderstand their relationship to the broader content set. If there’s little variation in metadata or thin semantic signals, your paginated content looks redundant—or gets bypassed entirely. This creates a critical visibility gap: content that ranks well in traditional Google search might remain completely invisible to AI answer generators. The distinction matters because AI systems prioritize structured, complete, and easily retrievable data. They aren’t “scrolling” like a user. They’re parsing code, URLs, and metadata to summarize or cite content with speed and accuracy. If your page doesn’t expose content through crawlable URLs or rich metadata, AI engines can’t retrieve it for inclusion in generated answers.
The choice between traditional pagination and infinite scroll has become a defining factor in AI content discoverability. Infinite scroll implementations load content via JavaScript only after user interaction, creating a fundamental accessibility problem for AI crawlers. Most infinite scroll setups don’t expose content through distinct URLs—instead, they load everything on a single page through dynamic JavaScript execution. This means AI crawlers, which don’t simulate real user behavior like scrolling or clicking, often miss everything beyond the first view. If your page doesn’t expose that extra content through crawlable URLs or metadata, AI engines can’t retrieve it. You may have 200 articles, 300 products, or dozens of case studies, but if they’re buried under JavaScript-triggered load events, the AI sees only 12 items. Maybe.
Traditional pagination still wins decisively for AI indexing because it produces clean, crawlable URLs (e.g., /blog/page/4), allowing engines to access and segment your content fully. It signals topical structure through internal linking, using standardized links like “Next Page” or “Previous Page” to help engines see how content connects. Pagination limits JavaScript dependency, ensuring your content loads for crawlers regardless of how a user interacts with the page. This structural clarity directly translates to better AI visibility—when ChatGPT or Perplexity crawls your site, they can discover and index paginated content far more effectively than content hidden behind infinite scroll implementations.
| Aspect | Pagination | Infinite Scroll |
|---|---|---|
| Crawl Accessibility | Unique URLs enable deep indexing | Content often hidden behind JS loads |
| AI Discoverability | Multiple pages can rank independently | Typically one page indexed only |
| Structured Data | Easier to assign to individual pages | Often missing or diluted |
| Direct Linking | Easy to link to specific content | Difficult to direct deep links |
| Sitemap Compatibility | Compatible and complete | Often leaves out deep content |
| URL Structure | Clear, distinct URLs per page | Single URL with dynamic loading |
| Content Visibility | All content accessible to crawlers | Content requires JS execution |
The technical architecture of infinite scroll creates fundamental barriers to AI content discovery. When content loads only through JavaScript, and no URLs reflect that new content, AI engines never see it. To a crawler, the rest of your list simply doesn’t exist. This isn’t a limitation of AI systems—it’s a consequence of how infinite scroll is typically implemented. Most infinite scroll setups prioritize user experience over technical accessibility, loading content dynamically without creating corresponding URLs or metadata that AI systems can parse.
Consider a real-world scenario: a global fashion retailer redesigned their site with a glossy infinite scroll interface. Site speed improved, engagement metrics looked solid, yet traffic from AI summaries dropped dramatically. Their SKUs seemed to vanish in conversational search tools. After auditing their architecture, the issue became clear: their entire catalog was hidden behind infinite scroll without crawlable fallbacks. No secondary page URLs. No supplemental linking. Just one long, invisible product list. Google SGE and ChatGPT couldn’t access anything past the first dozen products per category. Beautiful as the site looked, its discoverability was broken for AI systems.
Proper pagination implementation requires attention to multiple technical factors that collectively determine whether AI systems can discover and cite your content. The foundation starts with clean, logical URL structures that clearly indicate sequential relationships. Whether you use query parameters (?page=2) or path-based structures (/page/2/), consistency matters more than the specific format chosen. Both approaches work equally well for AI systems when properly implemented. What matters is that each paginated URL loads distinct content and remains accessible through standard HTML links that don’t require JavaScript execution.
Self-referencing canonical tags represent a critical decision point for pagination strategy. Each paginated page should include a canonical tag pointing to itself, signaling that each page is the preferred version of itself. This approach preserves the independence of sequential URLs, allowing each to compete for rankings based on its specific content and relevance to different queries. Avoid the outdated practice of canonicalizing all paginated pages to page one—this consolidates signals but eliminates the ability for individual pages to rank independently in AI systems. When you canonicalize everything to page one, you’re explicitly telling AI engines to ignore potentially valuable pages that contain unique products, content, or information.
Unique metadata for each page becomes essential for AI visibility. Don’t use generic “Page 2” titles or duplicate descriptions across your sequence. Instead, write page-specific, keyword-rich metadata that reflects each page’s focus. For example, instead of “Products - Page 2,” use “Women’s Athletic Shoes Under $100 - Page 2” or “AI Trends in Retail – Case Library (Page 2).” This clarity drives visibility because AI systems understand context and can better determine when your content is relevant to specific queries. Each metadata set must follow clarity, uniqueness, and keyword alignment principles. The goal is making each page’s purpose obvious to both AI systems and human readers.
Internal linking architecture determines whether AI systems can discover and efficiently navigate through sequential pages. A linear structure (page 1 → 2 → 3) creates long crawl paths where deep pages sit many clicks from the homepage, potentially leaving valuable content undiscovered. Smart implementations include complementary links like “View All” options or category hubs linking directly to key pages, reducing crawl depth and distributing link equity more evenly. The relationship between faceted navigation and sequential pages adds complexity, as filter combinations can generate thousands of URL variations. Proper internal linking ensures priority pages receive adequate crawler attention while less critical combinations get deprioritized through strategic use of noindex tags or canonical signals.
Strategic internal linking chains from pillar content to specific paginated pages guide AI systems through your content structure. From your main category page, link directly to specific paginated pages using anchor text that guides AI understanding. Example: “Explore more ecommerce success stories in our case study series – page 3.” Make the signal meaningful and findable. This approach teaches AI systems how your content fits together and how it should be discovered. When AI crawlers encounter these contextual links, they understand the relationship between pages and can better determine which content is most relevant to specific queries.
Duplicate content issues emerge when multiple URLs display identical or substantially similar content without proper differentiation. This happens when sequential pages lack unique elements beyond the listed items, or when URL parameters create multiple paths to the same content. Search engines and AI systems struggle to determine which version to rank, potentially fragmenting visibility across multiple URLs. Additionally, if paginated pages include boilerplate text, headers, and footers with minimal unique content, they may be perceived as thin pages offering little value. Solving this requires careful canonical tag usage, unique meta descriptions for each page, and ensuring each page offers sufficient distinct value beyond navigation elements and templated sections.
JavaScript-only implementations represent perhaps the most common mistake that hides content from AI systems. If your site uses frameworks like React or Angular to render page controls client-side without server-side rendering, AI crawlers might never discover content beyond page one. Ensure that navigation links exist in the initial HTML that AI systems receive, not generated exclusively through JavaScript after page load. Use progressive enhancement—basic HTML links that JavaScript can enhance with smoother interactions and animations. Test your implementation using tools that show you exactly what crawlers see versus what JavaScript-enabled browsers display. This reveals gaps in crawlability that could be costing you AI visibility.
Tracking pagination effectiveness requires monitoring how AI systems interact with your multi-page content. Unlike traditional SEO where Google Search Console provides direct insights, AI visibility monitoring requires different approaches. Tools like Screaming Frog SEO Spider can crawl your site similarly to how AI systems might access it, mapping page structures and identifying orphaned pages or crawl depth issues. DeepCrawl and Sitebulk offer advanced analysis with visualization of page relationships. Google Search Console provides insights from Google’s perspective, showing which paginated URLs are indexed and crawl frequency patterns.
Key performance indicators for paginated content include whether deep pages appear in AI-generated answers, how often AI systems cite your paginated content, and whether different pages rank for different long-tail queries. Monitor your branded mentions in AI answers—if AI systems consistently cite your page one but never mention deeper pages, your pagination structure may need optimization. Track which paginated pages drive the most traffic from AI sources. This data reveals whether your pagination strategy effectively exposes content to AI systems or whether restructuring is needed. Regular audits catch problems before they impact visibility, particularly after site updates or framework migrations.
The landscape of AI-powered search continues to evolve rapidly, with new systems and capabilities emerging regularly. Pagination strategies that work today should remain effective as AI systems become more sophisticated, but staying ahead requires understanding emerging trends. AI-powered search algorithms have become increasingly sophisticated at understanding content relationships and determining which paginated pages deserve indexing priority. Google’s neural matching and BERT-based understanding help search engines recognize that page two of a category offers different products than page one, even if surrounding text is similar. This improved comprehension means well-structured page division with meaningful differences between pages benefits more than ever from independent indexing.
However, AI also better detects truly thin or duplicate content on paginated pages, making it harder to game the system with barely-differentiated pages. Machine learning algorithms predict user intent more accurately, potentially surfacing deep pagination for specific long-tail queries when those pages best match search intent. The practical implication is to ensure each paginated page offers genuine unique value—distinctive products, different content, or meaningful variations—rather than just mechanical divisions of identical information. As AI systems continue evolving, the core principles remain constant: distinct URLs, crawlable links, unique value per page, and clear metadata will continue determining pagination effectiveness for AI visibility.
Track how your content appears in AI-generated answers across ChatGPT, Perplexity, and other AI search engines. Ensure your brand gets cited when AI systems answer questions about your industry.
Pagination divides large content sets into manageable pages for better UX and SEO. Learn how pagination works, its impact on search rankings, and best practices...
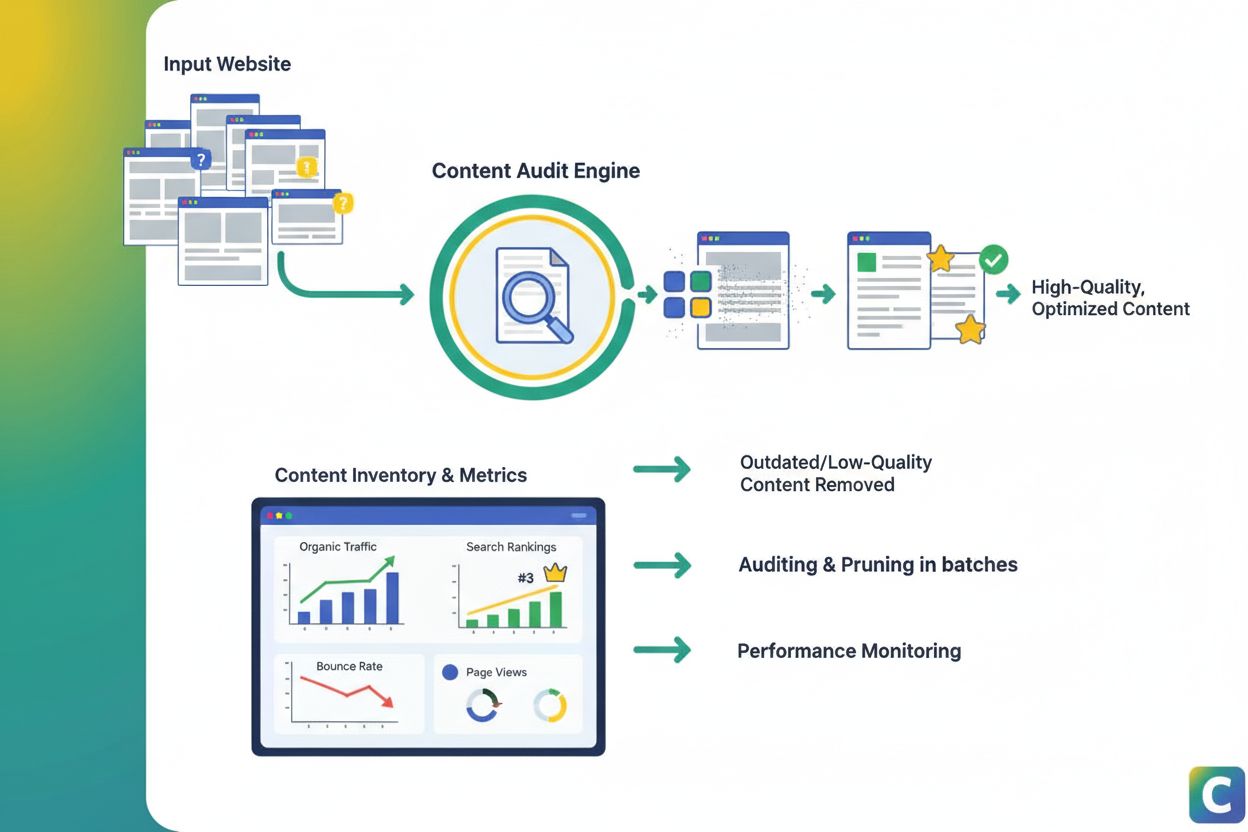
Content pruning is the strategic removal or updating of underperforming content to improve SEO, user experience, and search visibility. Learn how to identify an...
Pages Per Session measures average pages viewed per visit. Learn how this engagement metric impacts user behavior, conversion rates, and SEO performance with in...