Server-Side Rendering (SSR)
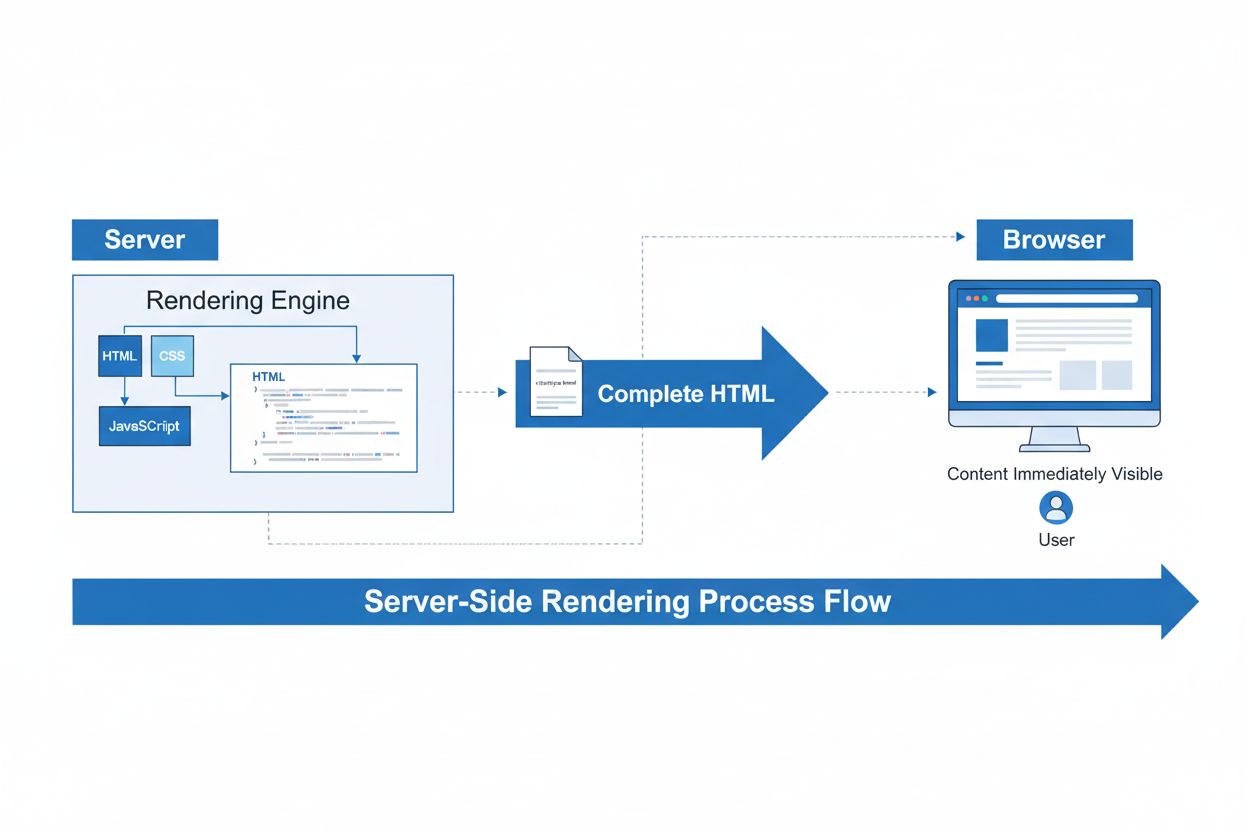
Server-Side Rendering (SSR) is a web technique where servers render complete HTML pages before sending them to browsers. Learn how SSR improves SEO, page speed,...
11 min read

Learn how server-side rendering enables efficient AI processing, model deployment, and real-time inference for AI-powered applications and LLM workloads.
Server-side rendering for AI is an architectural approach where artificial intelligence models and inference processing occur on the server rather than on client devices. This enables efficient handling of computationally intensive AI tasks, ensures consistent performance across all users, and simplifies model deployment and updates.
Server-side rendering for AI refers to an architectural pattern where artificial intelligence models, inference processing, and computational tasks execute on backend servers rather than on client devices like browsers or mobile phones. This approach fundamentally differs from traditional client-side rendering, where JavaScript runs in the user’s browser to generate content. In AI applications, server-side rendering means that large language models (LLMs), machine learning inference, and AI-powered content generation happen centrally on powerful server infrastructure before results are sent to users. This architectural shift has become increasingly important as AI capabilities have become more computationally demanding and integral to modern web applications.
The concept emerged from recognizing a critical mismatch between what modern AI applications require and what client devices can realistically provide. Traditional web development frameworks like React, Angular, and Vue.js popularized client-side rendering throughout the 2010s, but this approach creates significant challenges when applied to AI-intensive workloads. Server-side rendering for AI addresses these challenges by leveraging specialized hardware, centralized model management, and optimized infrastructure that client devices simply cannot match. This represents a fundamental paradigm shift in how developers architect AI-powered applications.
The computational requirements of modern AI systems make server-side rendering not just beneficial but often necessary. Client devices, particularly smartphones and budget laptops, lack the processing power to handle real-time AI inference efficiently. When AI models run on client devices, users experience noticeable delays, increased battery drain, and inconsistent performance depending on their hardware capabilities. Server-side rendering eliminates these problems by centralizing AI processing on infrastructure equipped with GPUs, TPUs, and specialized AI accelerators that provide orders of magnitude better performance than consumer devices.
Beyond raw performance, server-side rendering for AI provides critical advantages in model management, security, and consistency. When AI models run on servers, developers can update, fine-tune, and deploy new versions instantly without requiring users to download updates or manage different model versions locally. This is particularly important for large language models and machine learning systems that evolve rapidly with frequent improvements and security patches. Additionally, keeping AI models on servers prevents unauthorized access, model extraction, and intellectual property theft that becomes possible when models are distributed to client devices.
| Aspect | Client-Side AI | Server-Side AI |
|---|---|---|
| Processing Location | User’s browser or device | Backend servers |
| Hardware Requirements | Limited to device capabilities | Specialized GPUs, TPUs, AI accelerators |
| Performance | Variable, device-dependent | Consistent, optimized |
| Model Updates | Requires user downloads | Instant deployment |
| Security | Models exposed to extraction | Models protected on servers |
| Latency | Depends on device power | Optimized infrastructure |
| Scalability | Limited per device | Highly scalable across users |
| Development Complexity | High (device fragmentation) | Lower (centralized management) |
Network Overhead and Latency represent significant challenges in AI applications. Modern AI systems require constant communication with servers for model updates, training data retrieval, and hybrid processing scenarios. Client-side rendering ironically increases network requests compared to traditional applications, reducing the performance benefits that client-side processing was supposed to provide. Server-side rendering consolidates these communications, reducing round-trip delays and enabling real-time AI features like live translation, content generation, and computer vision processing to function smoothly without the latency penalties of client-side inference.
Synchronization Complexity emerges when AI applications need to maintain state consistency across multiple AI services simultaneously. Modern applications often use embeddings services, completion models, fine-tuned models, and specialized inference engines that must coordinate with each other. Managing this distributed state on client devices introduces significant complexity and creates potential for data inconsistencies, especially in real-time collaborative AI features. Server-side rendering centralizes this state management, ensuring all users see consistent results and eliminating the engineering overhead of maintaining complex client-side state synchronization.
Device Fragmentation creates substantial development challenges for client-side AI. Different devices have varying AI capabilities including Neural Processing Units, GPU acceleration, WebGL support, and memory constraints. Creating consistent AI experiences across this fragmented landscape requires substantial engineering effort, graceful degradation strategies, and multiple code paths for different device capabilities. Server-side rendering eliminates this fragmentation entirely by ensuring all users access the same optimized AI processing infrastructure, regardless of their device specifications.
Server-side rendering enables simplified and more maintainable AI application architectures by centralizing critical functionality. Rather than distributing AI models and inference logic across thousands of client devices, developers maintain a single, optimized implementation on servers. This centralization provides immediate benefits including faster deployment cycles, easier debugging, and more straightforward performance optimization. When an AI model needs improvement or a bug is discovered, developers fix it once on the server rather than attempting to push updates to millions of client devices with varying adoption rates.
Resource efficiency improves dramatically with server-side rendering. Server infrastructure allows efficient resource sharing across all users, with connection pooling, caching strategies, and load balancing optimizing hardware utilization. A single GPU on a server can process inference requests from thousands of users sequentially, whereas distributing the same capability to client devices would require millions of GPUs. This efficiency translates to lower operational costs, reduced environmental impact, and better scalability as applications grow.
Security and intellectual property protection become significantly easier with server-side rendering. AI models represent substantial investments in research, training data, and computational resources. Keeping models on servers prevents model extraction attacks, unauthorized access, and intellectual property theft that becomes possible when models are distributed to client devices. Additionally, server-side processing enables fine-grained access control, audit logging, and compliance monitoring that would be impossible to enforce on distributed client devices.
Modern frameworks have evolved to support server-side rendering for AI workloads effectively. Next.js leads this evolution with Server Actions that enable seamless AI processing directly from server components. Developers can call AI APIs, process large language models, and stream responses back to clients with minimal boilerplate code. The framework handles the complexity of managing server-client communication, enabling developers to focus on AI logic rather than infrastructure concerns.
SvelteKit provides a performance-first approach to server-side AI rendering with its load functions that execute on the server before rendering. This enables pre-processing of AI data, generating recommendations, and preparing AI-enhanced content before sending HTML to clients. The resulting applications have minimal JavaScript footprints while maintaining full AI capabilities, creating exceptionally fast user experiences.
Specialized tools like the Vercel AI SDK abstract away the complexity of streaming AI responses, managing token counting, and handling various AI provider APIs. These tools enable developers to build sophisticated AI applications without deep infrastructure knowledge. Infrastructure options including Vercel Edge Functions, Cloudflare Workers, and AWS Lambda provide globally distributed server-side AI processing, reducing latency by processing requests closer to users while maintaining centralized model management.
Effective server-side AI rendering requires sophisticated caching strategies to manage computational costs and latency. Redis caching stores frequently requested AI responses and user sessions, eliminating redundant processing for similar queries. CDN caching distributes static AI-generated content globally, ensuring users receive responses from geographically nearby servers. Edge caching strategies distribute AI-processed content across edge networks, providing ultra-low latency responses while maintaining centralized model management.
These caching approaches work together to create efficient AI systems that scale to millions of users without proportional increases in computational costs. By caching AI responses at multiple levels, applications can serve the vast majority of requests from cache while only computing new responses for genuinely novel queries. This dramatically reduces infrastructure costs while improving user experience through faster response times.
The evolution toward server-side rendering represents a maturation of web development practices in response to AI requirements. As AI becomes central to web applications, computational realities demand server-centric architectures. The future involves sophisticated hybrid approaches that automatically decide where to render based on content type, device capabilities, network conditions, and AI processing requirements. Frameworks will progressively enhance applications with AI capabilities, ensuring core functionality works universally while enhancing experiences where possible.
This paradigm shift incorporates lessons from the Single Page Application era while addressing AI-native application challenges. The tools and frameworks are ready for developers to leverage AI-era server-side rendering benefits, enabling the next generation of intelligent, responsive, and efficient web applications.
Track how your domain and brand appear in AI-generated answers across ChatGPT, Perplexity, and other AI search engines. Get real-time insights into your AI visibility.
Server-Side Rendering (SSR) is a web technique where servers render complete HTML pages before sending them to browsers. Learn how SSR improves SEO, page speed,...
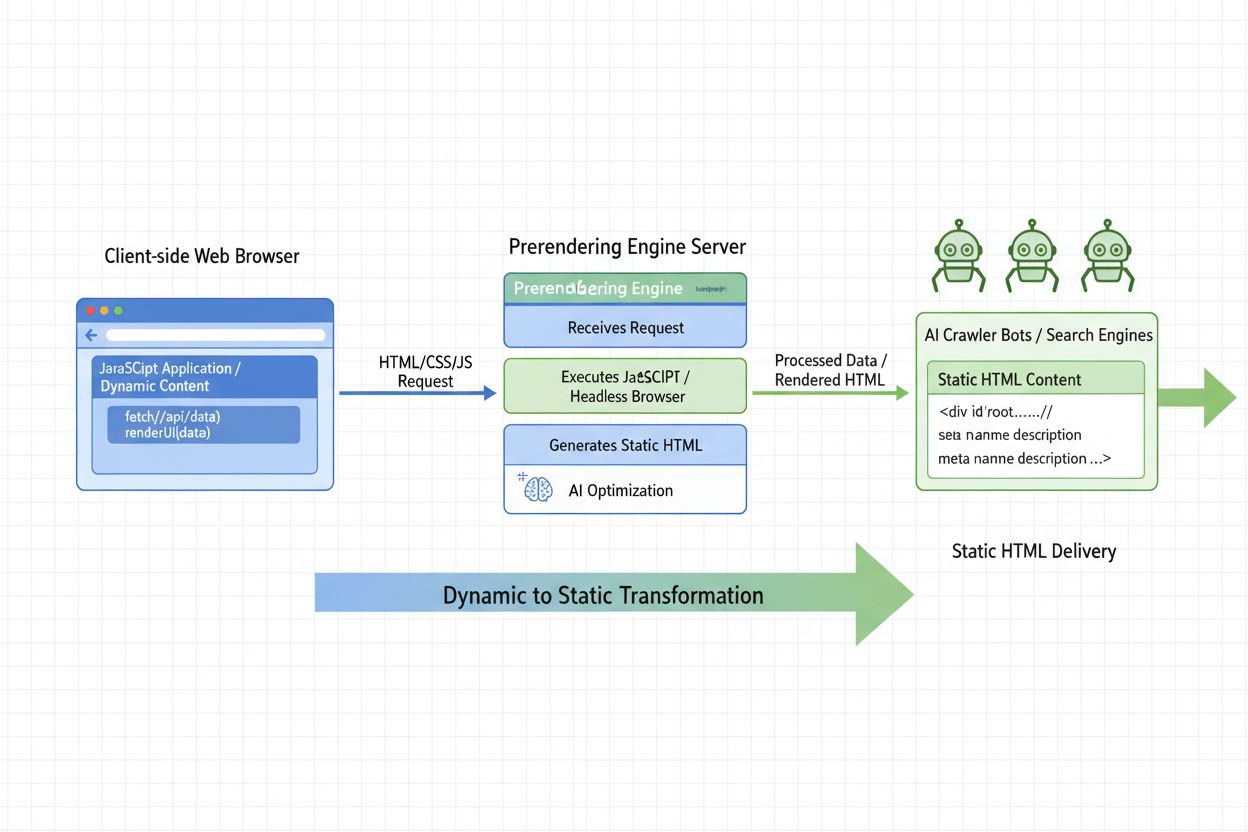
Learn what AI Prerendering is and how server-side rendering strategies optimize your website for AI crawler visibility. Discover implementation strategies for C...
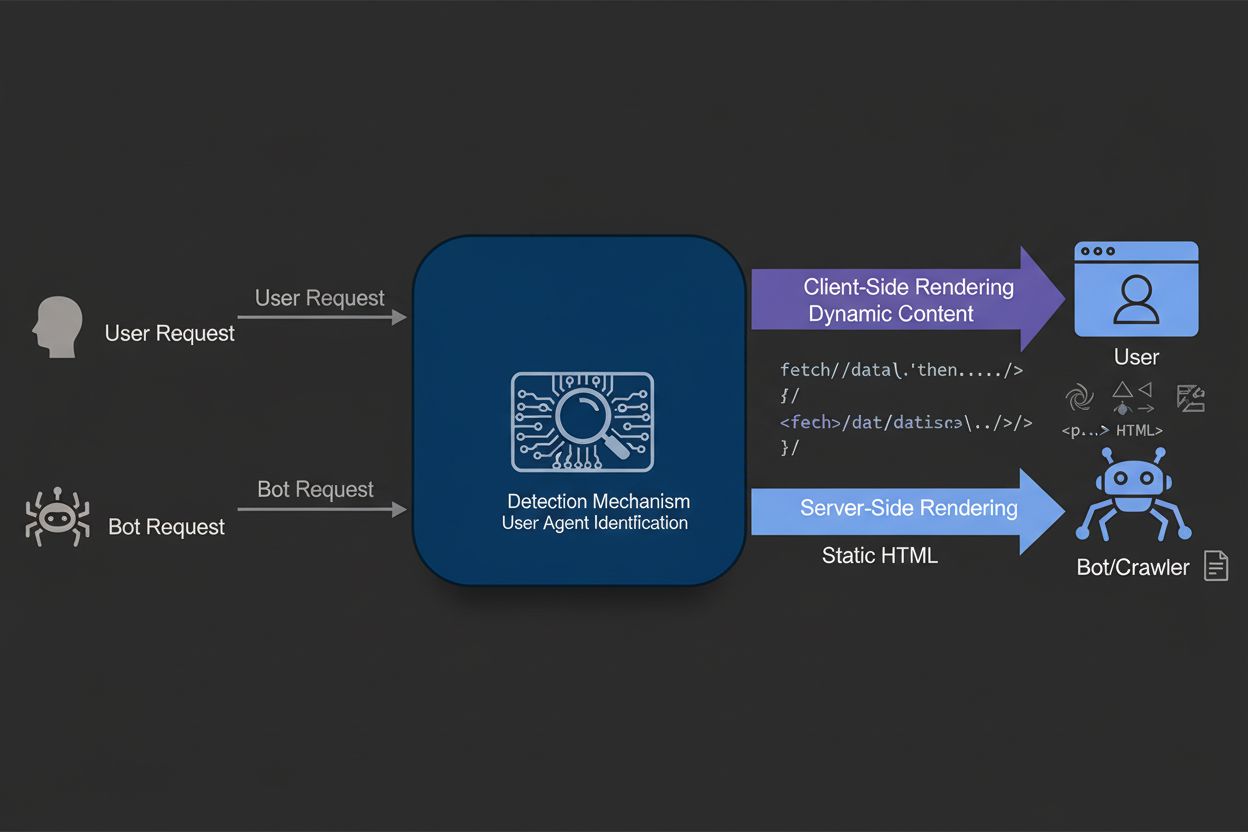
Dynamic rendering serves static HTML to search engine bots while delivering client-side rendered content to users. Learn how this technique improves SEO, crawl ...