
Modèles et outils comme aimants à citations IA
Découvrez comment les modèles et outils optimisent votre contenu pour les citations IA. Découvrez des stratégies pour augmenter la visibilité dans ChatGPT, Perp...
7 min de lecture
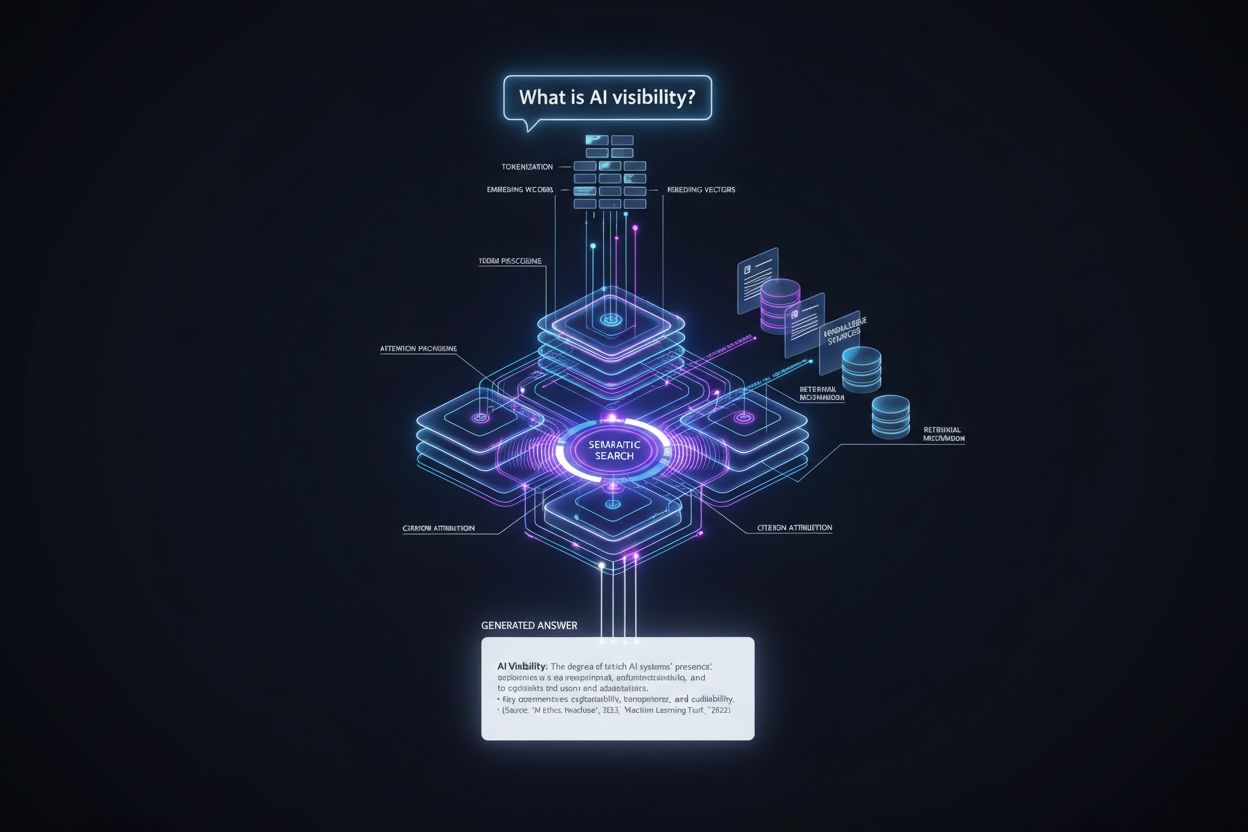
Découvrez comment les modèles d’IA génèrent des réponses et placent les citations. Apprenez où votre contenu apparaît dans ChatGPT, Perplexity et les réponses de Google AI, et comment optimiser votre visibilité auprès de l’IA.
Les réponses générées par l’IA sont devenues la principale méthode de découverte pour des millions d’utilisateurs, bouleversant fondamentalement la circulation de l’information sur Internet. Selon des recherches récentes, l’adoption de l’IA chez les chercheurs est passée à 84 % en 2025, avec 62 % utilisant spécifiquement des outils d’IA pour des tâches de recherche et de publication — une hausse spectaculaire par rapport à seulement 57 % d’utilisation globale de l’IA en 2024. Pourtant, la plupart des créateurs de contenu ignorent que le placement des citations dans ces réponses générées par l’IA n’est pas aléatoire ; il suit une architecture technique sophistiquée qui détermine quelles sources gagnent en visibilité et lesquelles restent invisibles. Comprendre où et pourquoi les citations apparaissent est désormais essentiel pour quiconque souhaite maintenir sa visibilité dans le paysage de découverte piloté par l’IA.
La distinction entre synthèse native du modèle et génération augmentée par la récupération (RAG) façonne fondamentalement la manière dont les citations apparaissent dans les réponses de l’IA. La synthèse native du modèle s’appuie exclusivement sur les connaissances encodées lors de l’entraînement, tandis que RAG récupère dynamiquement des sources externes pour ancrer les réponses dans des informations actualisées. Cette différence a des implications profondes sur le placement et la visibilité des citations.
| Caractéristique | Synthèse native du modèle | RAG |
|---|---|---|
| Définition | Réponses générées uniquement à partir des données d’entraînement | Réponses ancrées dans des sources récupérées en temps réel |
| Vitesse | Plus rapide (pas de surcharge de récupération) | Plus lent (nécessite une étape de récupération) |
| Précision | Sujette aux hallucinations et informations obsolètes | Précision plus élevée avec sources actuelles |
| Capacité de citation | Citations limitées ou absentes | Citations riches et traçables |
| Cas d’usage | Connaissance générale, tâches créatives | Actualités, recherche, vérification des faits, données propriétaires |
Les systèmes basés sur RAG, comme Perplexity et les AI Overviews de Google, produisent naturellement plus de citations car ils doivent référencer leurs sources de récupération, tandis que les approches natives du modèle, comme les réponses traditionnelles de ChatGPT, citent moins fréquemment. Comprendre l’approche utilisée par une plateforme aide les créateurs de contenu à anticiper la probabilité de citation et à optimiser en conséquence.
Le parcours de la question utilisateur à la réponse citée suit un pipeline technique précis qui détermine le placement des citations à différentes étapes. Voici comment se déroule le processus :
Traitement de la requête : La question de l’utilisateur est tokenisée — découpée en unités que le modèle comprend — puis analysée pour l’intention, les entités et la signification sémantique via des vecteurs d’embedding.
Récupération d’informations : Le système interroge sa base de connaissances (données d’entraînement, documents indexés ou sources en temps réel) via une recherche sémantique, faisant correspondre le sens de la requête plutôt que les mots-clés exacts, et retourne des sources candidates classées par pertinence.
Assemblage du contexte : Les informations récupérées sont organisées dans une fenêtre de contexte — la quantité de texte que le modèle peut traiter simultanément — avec les sources les plus pertinentes placées en évidence pour influencer les mécanismes d’attention.
Génération des tokens : Le modèle génère la réponse un token à la fois, utilisant des mécanismes d’auto-attention pour déterminer quels tokens précédents et quelles informations sources doivent influencer chaque nouveau token, créant des réponses cohérentes et contextuellement ancrées.
Attribution des citations : Au fil de la génération, le modèle suit quels documents sources influencent des affirmations spécifiques, attribue des scores de crédibilité et décide d’inclure ou non des citations explicites selon les niveaux de confiance et les exigences de la plateforme.
Livraison du résultat : La réponse finale est formatée selon les spécifications de la plateforme — citations en ligne, notes de bas de page, panneaux de sources ou liens au survol — puis délivrée à l’utilisateur avec des métadonnées sur l’autorité et la pertinence des sources.
Le placement des citations varie énormément d’une plateforme IA à l’autre, créant des opportunités de visibilité différentes pour les créateurs de contenu. Voici comment les principales plateformes gèrent les citations :
ChatGPT : Les citations apparaissent dans un panneau « Sources » distinct sous la réponse, nécessitant un clic de l’utilisateur. Les sources sont généralement limitées à 3-5 liens, privilégiant les domaines à forte autorité.
Perplexity : Les citations sont intégrées dans la réponse via des numéros en exposant et une liste complète des sources en bas de page. Chaque affirmation est traçable, faisant de Perplexity la plateforme la plus transparente sur les citations.
Google Gemini : Les citations apparaissent sous forme de liens en ligne dans le texte de la réponse, avec une section « Sources » regroupant tous les documents référencés. L’intégration au knowledge graph de Google influence le choix des sources.
Claude : Les citations sont présentées au format note de bas de page avec des références entre crochets, permettant de voir les sources sans quitter le flux de la réponse. Claude met l’accent sur la diversité et la crédibilité des sources.
DeepSeek : Les citations apparaissent comme des liens hypertextes intégrés avec peu de distinction visuelle, reflétant une approche où les sources sont tissées dans le récit de façon transparente.
Ces différences signifient qu’une source citée par Perplexity peut recevoir du trafic direct, tandis que la même source citée par ChatGPT peut rester invisible sauf si l’utilisateur clique sur le panneau des sources. Les schémas de citation propres à chaque plateforme ont un impact direct sur le trafic et la visibilité.

C’est au niveau du système de récupération que les décisions d’emplacement de citation commencent, bien avant la génération de la réponse. La recherche sémantique convertit à la fois la requête utilisateur et les documents indexés en embeddings vectoriels — des représentations numériques qui capturent la signification plutôt que les mots-clés. Le système calcule ensuite des scores de similarité entre l’embedding de la requête et ceux des documents, identifiant quelles sources sont les plus proches sémantiquement de l’intention de l’utilisateur.
Des algorithmes de classement réordonnent ensuite ces candidats sur la base de plusieurs signaux : score de pertinence, autorité du domaine, fraîcheur du contenu, engagement des utilisateurs et qualité des données structurées. Les sources les mieux classées lors de cette phase de récupération ont plus de chances d’être incluses dans la fenêtre de contexte alimentant le modèle de génération, donc d’être citées. C’est pourquoi un article bien optimisé, clair sémantiquement et publié par un domaine reconnu sera récupéré et cité bien plus souvent qu’un article mal structuré d’un domaine récent, même si les deux sont exacts. La phase de récupération prédétermine ainsi le pool de citations avant même la génération.
La structure du contenu n’est pas seulement une question d’UX — elle détermine directement si les systèmes d’IA peuvent extraire, comprendre et citer votre contenu. Les modèles d’IA s’appuient sur des indices de formatage pour identifier les frontières de l’information et les relations. Voici les éléments structurels qui maximisent la probabilité de citation :
Structure réponse en premier : Commencez par la réponse directe aux questions courantes, permettant aux systèmes IA d’identifier et d’extraire rapidement l’information la plus pertinente sans parcourir les introductions.
Titres clairs : Utilisez des titres H2 et H3 descriptifs qui précisent explicitement le sujet de chaque section, aidant les IA à comprendre l’organisation et à extraire les passages pertinents selon la requête.
Paragraphes courts : Limitez les paragraphes à 3–5 phrases, facilitant l’identification de chaque affirmation et son attribution sans ambiguïté à une source.
Listes et tableaux : Les données structurées en listes à puces ou en tableaux sont plus faciles à analyser et à citer que le texte courant, car les IA peuvent aisément isoler les affirmations.
Clarté des entités : Nommez explicitement personnes, entreprises, produits et concepts plutôt qu’utiliser des pronoms, permettant à l’IA de savoir précisément ce que chaque affirmation désigne et de la citer correctement.
Balisage schema : Implémentez des données structurées (Schema.org) pour fournir des métadonnées explicites sur le type de contenu, l’auteur, la date de publication et les affirmations, offrant ainsi des signaux supplémentaires aux IA pour l’évaluation et la citation.
Un contenu respectant ces principes structurels est cité 2 à 3 fois plus souvent qu’un contenu mal structuré, quelle que soit sa qualité, car il est tout simplement plus facile à extraire et à attribuer pour l’IA.
Une fois les sources récupérées et assemblées dans la fenêtre de contexte, le modèle évalue chacune d’elles via plusieurs filtres de crédibilité avant de décider de la citer. L’évaluation de la crédibilité s’appuie sur l’autorité du domaine (profils de liens, ancienneté du domaine, notoriété de la marque), l’expertise de l’auteur (signature, biographie, signaux de diplôme), et la pertinence thématique (adéquation du sujet à la requête).
Le score de pertinence mesure à quel point la source répond directement à la question, les réponses exactes étant mieux notées que les informations tangentielles. Les facteurs de fraîcheur favorisent les sources récentes pour l’actualité, la recherche ou l’innovation. Les signaux d’autorité incluent les citations par d’autres sources reconnues, les mentions dans des bases de données académiques et la présence dans les knowledge graphs. L’influence des métadonnées provient des balises title, des meta descriptions et des données structurées qui communiquent explicitement l’objectif et la crédibilité du contenu. Enfin, les données structurées (balisage Schema.org) apportent des signaux de crédibilité explicites interprétables par la machine, comme les diplômes de l’auteur, la date de publication, les notes d’évaluation et le statut de vérification. Les sources avec balisage schema complet sont citées plus régulièrement car le modèle a confirmation explicite et lisible de leurs affirmations.
Les plateformes IA adoptent des styles de citation distincts qui conditionnent la visibilité de vos citations auprès des utilisateurs. Voici les schémas les plus courants :
Citations en ligne (style Perplexity) :
« Selon des recherches récentes, l’adoption de l’IA chez les chercheurs est montée à 84 % en 2025[1], avec 62 % utilisant spécifiquement des outils d’IA pour la recherche[2]. »
Citations en fin de paragraphe (style Claude) :
« L’adoption de l’IA chez les chercheurs a atteint 84 % en 2025, avec 62 % utilisant spécifiquement des outils d’IA. [Source : Wiley Research Report, 2025] »
Citations façon notes de bas de page (approche académique) :
« L’adoption de l’IA chez les chercheurs a atteint 84 % en 2025¹, avec 62 % utilisant spécifiquement des outils d’IA². »
Listes de sources (style ChatGPT) :
Texte de réponse sans citation en ligne, suivi d’une section « Sources » listant 3 à 5 liens.
Citations au survol (schéma émergent) :
Texte souligné révélant la source au survol, minimisant l’encombrement visuel tout en conservant la traçabilité.
Chaque style induit des comportements utilisateurs différents : les citations en ligne génèrent des clics immédiats, les listes de sources nécessitent une action délibérée, et les citations au survol équilibrent visibilité et esthétique. La probabilité que votre contenu soit cité varie selon la plateforme, rendant le suivi multi-plateforme indispensable.
Comprendre les mécanismes de placement des citations se traduit directement par des résultats business mesurables. Les implications sur le trafic sont immédiates : les sources citées en ligne par Perplexity reçoivent 3 à 5 fois plus de trafic référent que celles qui n’apparaissent que dans le panneau « Sources » de ChatGPT, car les utilisateurs cliquent davantage sur les citations intégrées en cours de lecture. La corrélation entre visibilité et taux de clic n’est pas linéaire — être cité n’est utile que si les utilisateurs cliquent, ce qui dépend du placement, de la plateforme et du contexte.
L’autorité de marque se construit dans le temps : les sources citées régulièrement par plusieurs plateformes IA développent des signaux d’autorité plus forts, ce qui améliore leur classement en recherche traditionnelle et augmente leur probabilité de futures citations IA. Cela crée un cercle vertueux où le contenu cité devient plus autoritaire et attire plus de citations. L’avantage concurrentiel revient aux marques qui optimisent pour la citation IA avant les autres — les pionniers du schema et de l’optimisation structurelle récoltent aujourd’hui une part disproportionnée des citations. Les implications SEO dépassent l’IA : un contenu optimisé pour la citation IA performe aussi mieux en SEO classique, car clarté structurelle et signaux d’autorité profitent aux deux systèmes. La valeur d’AmICited devient alors évidente : dans un paysage de découverte piloté par l’IA, ignorer ses citations revient à ignorer ses positions de recherche — c’est un angle mort critique dans votre stratégie de visibilité.
Pour être cité par l’IA, il faut adopter des changements concrets dans la création et la structuration du contenu. Voici les tactiques les plus efficaces :
Structurez pour l’extractibilité : Utilisez des titres clairs, des paragraphes courts et des listes pour faciliter l’extraction de vos affirmations par les IA sans ambiguïté.
Utilisez des faits clairs et citables : Commencez avec des statistiques précises, des dates et des entités nommées plutôt que des généralités. Les IA citent plus volontiers des affirmations concrètes.
Implémentez le balisage schema : Ajoutez le balisage Schema.org pour Article, NewsArticle ou ScholarlyArticle, incluant l’auteur, la date de publication et des métadonnées sur les affirmations facilement exploitables par les IA.
Assurez la cohérence des entités : Utilisez les mêmes noms pour les personnes, organisations et concepts dans tout le contenu, évitant pronoms et abréviations sources d’ambiguïté pour l’IA.
Citez vos sources : En citant d’autres sources dans votre contenu, vous signalez aux IA qu’il est bien documenté et crédible, augmentant vos propres chances d’être cité.
Testez avec les outils IA : Interrogez régulièrement vos sujets cibles dans ChatGPT, Perplexity, Gemini et Claude pour vérifier si votre contenu est cité et comment il apparaît.
Suivez vos performances : Analysez quels contenus sont cités, par quelles plateformes et dans quel contexte, et ajustez votre stratégie d’optimisation en conséquence.
Les créateurs qui appliquent ces tactiques voient leur taux de citation augmenter de 40 à 60 % en 3 à 6 mois, avec des gains correspondants en trafic référent et en autorité de marque.
La surveillance des citations n’est plus optionnelle — c’est une infrastructure essentielle pour comprendre votre visibilité dans le paysage de la découverte IA. Pourquoi surveiller est évident : on n’optimise que ce que l’on mesure, et les schémas de citation évoluent avec les IA et l’apparition de nouvelles plateformes. Quels indicateurs suivre : fréquence de citation (combien de fois vous êtes cité), emplacement (en ligne ou en liste de sources), répartition par plateforme (où vous êtes le plus cité), contexte de la requête (quels sujets déclenchent vos citations), et attribution du trafic (combien de trafic référent vient des citations IA).
Identifier les opportunités suppose d’analyser les écarts de citation : sujets où des concurrents sont cités et pas vous, plateformes où vous êtes sous-représenté, types de contenu moins performants. Cette analyse révèle des cibles d’optimisation précises — vos guides pratiques ne sont peut-être pas cités faute de balisage schema, ou vos contenus de recherche n’apparaissent pas dans Perplexity car ils ne sont pas structurés pour l’extraction en ligne.
AmICited relève le défi du monitoring en suivant vos citations sur ChatGPT, Perplexity, Gemini, Claude et d’autres grandes plateformes IA en temps réel. Plutôt que d’interroger manuellement vos sujets, AmICited surveille automatiquement les schémas de citation, vous alerte sur les nouvelles citations et fournit des données de benchmark concurrentiel pour comparer vos performances. Pour les créateurs de contenu, marketeurs et SEO, AmICited transforme la surveillance des citations d’un processus manuel et chronophage en un système automatisé qui fait remonter des insights actionnables. Dans un monde piloté par l’IA, voir où votre contenu est cité est aussi indispensable que connaître vos positions de recherche — et AmICited rend cette visibilité possible à grande échelle.
Les réponses natives au modèle proviennent de schémas appris lors de l’entraînement, tandis que RAG récupère des données en direct avant de générer des réponses. RAG fournit généralement de meilleures citations car il ancre les réponses dans des sources spécifiques, rendant le processus plus transparent et traçable pour les utilisateurs et les créateurs de contenu.
Chaque plateforme utilise des architectures différentes. Perplexity et Gemini privilégient RAG avec des citations, tandis que ChatGPT génère par défaut sans RAG sauf si la navigation est activée. Ce choix reflète la philosophie de conception et l’approche de la transparence propres à chaque plateforme.
Un contenu clair, bien structuré, avec des réponses directes, des titres appropriés et un balisage schema est plus facilement exploitable par les systèmes d’IA. Un contenu commençant par la réponse et utilisant des listes et des tableaux a plus de chances d’être cité car il est plus simple à analyser et à attribuer pour l’IA.
Le balisage schema aide les systèmes d’IA à comprendre la structure du contenu et les relations entre entités, facilitant une attribution correcte et la citation de votre contenu. Une bonne mise en œuvre du schema augmente la probabilité de citation et aide les systèmes d’IA à vérifier la crédibilité de votre contenu.
Oui. Privilégiez une structure qui commence par la réponse, un formatage clair, une exactitude factuelle, des sources crédibles et une bonne implémentation du schema. Surveillez vos citations et adaptez-vous selon les performances pour améliorer continuellement votre visibilité auprès de l’IA.
Des outils comme AmICited surveillent les mentions de votre marque sur ChatGPT, Perplexity, Google AI Overviews et d’autres plateformes, vous montrant exactement où et comment vous êtes cité dans les réponses IA. Cela fournit des informations utiles pour l’optimisation.
Bien que les citations de l’IA n’aient pas d’impact direct sur le classement Google, elles augmentent la visibilité de la marque et les signaux d’autorité. Être cité par l’IA peut générer du trafic et renforcer votre présence en ligne, créant des bénéfices SEO indirects.
Ils sont complémentaires. Le SEO traditionnel vise à classer dans les résultats de recherche, tandis que l’optimisation de la citation IA vise à apparaître dans les réponses générées par l’IA. Les deux sont essentiels pour une visibilité complète dans le paysage moderne de la découverte.
Comprenez exactement où votre marque apparaît dans les réponses générées par l’IA. Suivez les citations sur ChatGPT, Perplexity, Google AI Overviews et plus encore avec AmICited.
Découvrez comment les modèles et outils optimisent votre contenu pour les citations IA. Découvrez des stratégies pour augmenter la visibilité dans ChatGPT, Perp...
Découvrez quels formats de contenu sont le plus cités par les modèles d’IA. Analysez les données de plus de 768 000 citations IA pour optimiser votre stratégie ...

Découvrez comment fonctionne la position des citations sur ChatGPT, Perplexity, Google AI Overviews et d'autres systèmes d'IA. Comprenez les stratégies de place...