Fiche de Référence des Crawlers IA : Tous les Bots en un Coup d’Œil
Guide complet de référence des crawlers IA et bots. Identifiez GPTBot, ClaudeBot, Google-Extended et plus de 20 autres crawlers IA avec leurs user agents, fréquences de crawl et stratégies de blocage.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
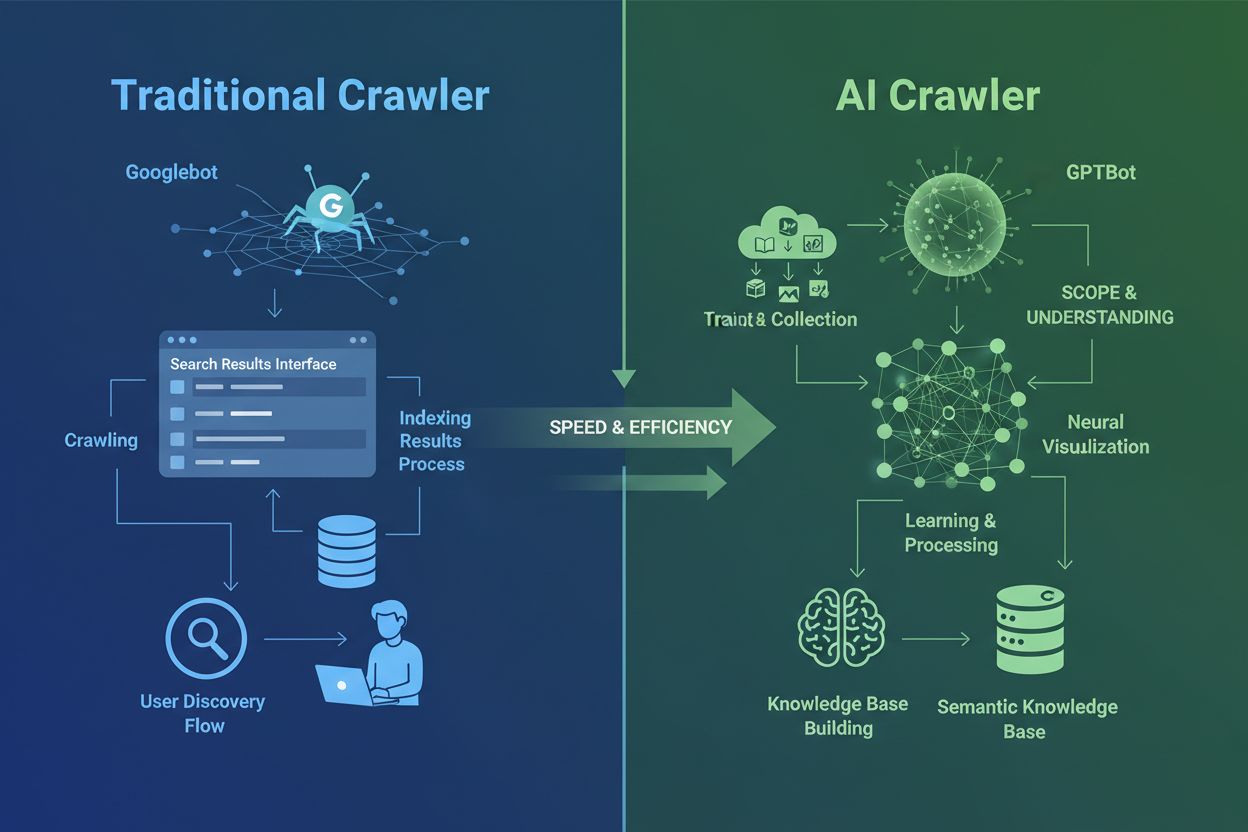
Comprendre les Crawlers IA vs Crawlers Traditionnels
Les crawlers IA sont fondamentalement différents des crawlers des moteurs de recherche traditionnels que vous connaissez depuis des décennies. Alors que Googlebot et Bingbot indexent le contenu pour aider les utilisateurs à trouver de l’information via les résultats de recherche, les crawlers IA comme GPTBot et ClaudeBot collectent spécifiquement des données pour entraîner des modèles de langage. Cette distinction est cruciale : les crawlers traditionnels créent des chemins pour la découverte humaine, tandis que les crawlers IA alimentent les bases de connaissance des systèmes d’intelligence artificielle. Selon des données récentes, les crawlers IA représentent désormais près de 80% de tout le trafic bot vers les sites web, les crawlers d’entraînement consommant d’énormes quantités de contenu tout en envoyant très peu de trafic de référence aux éditeurs. Contrairement aux crawlers traditionnels qui peinent avec les sites dynamiques riches en JavaScript, les crawlers IA utilisent le machine learning avancé pour comprendre le contenu contextuellement, comme le ferait un lecteur humain. Ils peuvent interpréter le sens, le ton et l’intention sans mises à jour manuelles de configuration. Cela représente un saut quantique dans la technologie d’indexation web qui oblige les propriétaires de sites à repenser entièrement leur stratégie de gestion des crawlers.
Le Grand Écosystème des Crawlers IA
Le paysage des crawlers IA est devenu de plus en plus encombré alors que les grandes entreprises technologiques se disputent la construction de leurs propres modèles de langage. OpenAI, Anthropic, Google, Meta, Amazon, Apple et Perplexity exploitent chacun plusieurs crawlers spécialisés, chacun remplissant des fonctions distinctes au sein de leurs écosystèmes respectifs. Les entreprises déploient plusieurs crawlers car des finalités différentes requièrent des comportements différents : certains crawlers sont dédiés à la collecte massive pour l’entraînement, d’autres à l’indexation de recherche en temps réel, et d’autres encore récupèrent du contenu à la demande lorsque les utilisateurs le souhaitent. Comprendre cet écosystème suppose d’identifier trois grandes catégories de crawlers : les crawlers d’entraînement qui collectent des données pour améliorer les modèles, les crawlers de recherche et de citation qui indexent le contenu pour l’expérience de recherche IA, et les fetchers déclenchés par l’utilisateur qui s’activent lorsque l’utilisateur sollicite un contenu via un assistant IA. Le tableau suivant offre un aperçu rapide des principaux acteurs :
Entreprise
Nom du Crawler
Objectif principal
Fréquence de Crawl
Données d’entraînement
OpenAI
GPTBot
Entraînement du modèle
100 pages/heure
Oui
OpenAI
ChatGPT-User
Requêtes utilisateur en temps réel
2400 pages/heure
Non
OpenAI
OAI-SearchBot
Indexation de recherche
150 pages/heure
Non
Anthropic
ClaudeBot
Entraînement du modèle
500 pages/heure
Oui
Anthropic
Claude-User
Accès web en temps réel
<10 pages/heure
Non
Google
Google-Extended
Entraînement Gemini IA
Variable
Oui
Google
Gemini-Deep-Research
Fonction recherche
<10 pages/heure
Non
Meta
Meta-ExternalAgent
Entraînement modèle IA
1100 pages/heure
Oui
Amazon
Amazonbot
Amélioration de service
1050 pages/heure
Oui
Perplexity
PerplexityBot
Indexation de recherche
150 pages/heure
Non
Apple
Applebot-Extended
Entraînement IA
<10 pages/heure
Oui
Common Crawl
CCBot
Jeu de données ouvert
<10 pages/heure
Oui
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
OpenAI exploite trois crawlers distincts, chacun avec des rôles spécifiques dans l’écosystème ChatGPT. Les comprendre est essentiel car GPTBot d’OpenAI est l’un des crawlers IA les plus agressifs et déployés sur Internet :
GPTBot – Le principal crawler d’entraînement d’OpenAI qui collecte systématiquement des données publiques pour entraîner et améliorer les modèles GPT, dont ChatGPT et GPT-4o. Ce crawler opère à environ 100 pages par heure et respecte les directives robots.txt. OpenAI publie les adresses IP officielles sur https://openai.com/gptbot.json pour vérification.
ChatGPT-User – Ce crawler apparaît lorsqu’un utilisateur réel interagit avec ChatGPT et lui demande de parcourir une page web spécifique. Il fonctionne à des taux bien plus élevés (jusqu’à 2400 pages/heure) car il est déclenché par des actions utilisateur. Le contenu accédé via ChatGPT-User n’est pas utilisé pour l’entraînement, ce qui le rend précieux pour la visibilité en temps réel dans les résultats de ChatGPT.
OAI-SearchBot – Conçu spécifiquement pour la recherche ChatGPT, ce crawler indexe le contenu pour des résultats de recherche en temps réel sans collecter de données d’entraînement. Il fonctionne à environ 150 pages par heure et aide votre contenu à apparaître dans les résultats de recherche ChatGPT lors de requêtes pertinentes.
Les crawlers d’OpenAI respectent robots.txt et opèrent depuis des plages d’IP vérifiées, ce qui les rend relativement faciles à gérer par rapport à des concurrents moins transparents.
Les Crawlers Claude d’Anthropic
Anthropic, la société derrière Claude AI, exploite plusieurs crawlers avec des objectifs et des niveaux de transparence variables. L’entreprise a été moins transparente qu’OpenAI dans la documentation, mais leur comportement est bien documenté via l’analyse des logs serveur :
ClaudeBot – Le principal crawler d’entraînement d’Anthropic qui collecte du contenu web pour améliorer la base de connaissances et les capacités de Claude. Ce crawler opère à environ 500 pages par heure et est la cible principale si vous souhaitez empêcher l’utilisation de votre contenu pour l’entraînement de Claude. Le user agent complet est Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com).
Claude-User – Activé lorsque les utilisateurs de Claude demandent un accès web en temps réel, ce crawler récupère du contenu à la demande avec un faible volume. Il respecte l’authentification et ne tente pas de contourner les restrictions d’accès, ce qui le rend plutôt bénin côté ressources.
Claude-SearchBot – Soutient les capacités de recherche interne de Claude, aidant votre contenu à apparaître dans les résultats de recherche Claude lors de questions utilisateur. Ce crawler fonctionne à très faible volume et sert principalement à l’indexation, pas à l’entraînement.
Un point de vigilance important concernant les crawlers d’Anthropic est le ratio crawl/renvoi : Selon Cloudflare, pour chaque renvoi envoyé par Anthropic vers un site, ses crawlers ont déjà visité environ 38 000 à 70 000 pages. Ce déséquilibre massif signifie que votre contenu est consommé bien plus qu’il n’est cité, posant des questions sur la juste rémunération de l’utilisation du contenu.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Crawlers d’Entraînement IA de Google
L’approche de Google diffère sensiblement de ses concurrents car l’entreprise sépare strictement indexation de recherche et entraînement IA. Google-Extended est le crawler qui collecte les données pour entraîner Gemini (anciennement Bard) et autres produits IA Google, complètement séparé du Googlebot traditionnel :
La chaîne user agent de Google-Extended est : Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0. Cette séparation est intentionnelle et bénéfique pour les propriétaires de site, car vous pouvez bloquer Google-Extended via robots.txt sans affecter votre visibilité dans Google Search. Google déclare officiellement que bloquer Google-Extended n’a aucun impact sur le classement ou l’inclusion dans les AI Overviews, même si certains webmasters signalent des points à surveiller. Gemini-Deep-Research est un autre crawler Google qui prend en charge la fonction recherche de Gemini, opérant à très faible volume et impact serveur minimal. Un avantage technique majeur des crawlers Google est leur capacité à exécuter du JavaScript et à rendre du contenu dynamique, contrairement à la plupart des concurrents. Cela signifie que Google-Extended peut crawler efficacement des applications React, Vue ou Angular, alors que GPTBot d’OpenAI ou ClaudeBot d’Anthropic ne le peuvent pas. Pour les sites JavaScript-intensifs, cette distinction compte pour la visibilité IA.
Autres Grands Crawlers IA
Au-delà des géants technologiques, de nombreuses autres organisations exploitent des crawlers IA dignes d’attention. Meta-ExternalAgent, discrètement lancé en juillet 2024, scrape le web pour entraîner les IA de Meta et améliorer Facebook, Instagram et WhatsApp. Il fonctionne à environ 1100 pages/heure et a reçu moins d’attention publique malgré un comportement agressif. Bytespider, exploité par ByteDance (maison-mère de TikTok), est devenu l’un des crawlers les plus agressifs depuis son lancement en avril 2024. Des observations tierces suggèrent que Bytespider est bien plus agressif que GPTBot ou ClaudeBot, selon les contextes. Certains rapports indiquent qu’il ne respecte pas toujours robots.txt, rendant le blocage par IP plus fiable.
Les crawlers de Perplexity incluent PerplexityBot pour l’indexation de recherche et Perplexity-User pour la récupération en temps réel. Perplexity est accusé parfois d’ignorer robots.txt, bien que la société affirme le contraire. Amazonbot alimente les capacités question-réponse d’Alexa et respecte robots.txt, opérant à environ 1050 pages par heure. Applebot-Extended, introduit en juin 2024, détermine comment le contenu déjà indexé par Applebot sera utilisé pour l’entraînement IA d’Apple, sans crawler directement les pages web. CCBot, géré par Common Crawl (organisation à but non lucratif), construit des archives web ouvertes utilisées par OpenAI, Google, Meta, Hugging Face, etc. Des crawlers émergents de sociétés comme xAI (Grok), Mistral et DeepSeek commencent à apparaître dans les logs, signe de l’expansion continue de l’écosystème IA.
Tableau de Référence Complet des Crawlers IA
Voici un tableau de référence complet des crawlers IA vérifiés, leurs objectifs, user agents et syntaxe de blocage robots.txt. Ce tableau est mis à jour régulièrement sur la base de l’analyse des logs et de la documentation officielle. Chaque entrée a été vérifiée avec les listes d’IP officielles lorsque disponibles :
Nom du Crawler
Entreprise
Objectif
User Agent
Fréquence de Crawl
Vérification IP
Syntaxe robots.txt
GPTBot
OpenAI
Collecte de données d’entraînement
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
100/h
✓ Officiel
User-agent: GPTBot Disallow: /
ChatGPT-User
OpenAI
Requêtes utilisateur en temps réel
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0
2400/h
✓ Officiel
User-agent: ChatGPT-User Disallow: /
OAI-SearchBot
OpenAI
Indexation de recherche
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36; compatible; OAI-SearchBot/1.3
150/h
✓ Officiel
User-agent: OAI-SearchBot Disallow: /
ClaudeBot
Anthropic
Collecte de données d’entraînement
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
500/h
✓ Officiel
User-agent: ClaudeBot Disallow: /
Claude-User
Anthropic
Accès web en temps réel
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-User/1.0)
<10/h
✗ Non disponible
User-agent: Claude-User Disallow: /
Claude-SearchBot
Anthropic
Indexation de recherche
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-SearchBot/1.0)
<10/h
✗ Non disponible
User-agent: Claude-SearchBot Disallow: /
Google-Extended
Google
Entraînement Gemini IA
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0)
Variable
✓ Officiel
User-agent: Google-Extended Disallow: /
Gemini-Deep-Research
Google
Fonction recherche
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Gemini-Deep-Research)
<10/h
✓ Officiel
User-agent: Gemini-Deep-Research Disallow: /
Bingbot
Microsoft
Recherche Bing & Copilot
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0)
Tous les crawlers IA ne servent pas le même objectif, et comprendre ces distinctions est primordial pour prendre des décisions de blocage éclairées. Les crawlers d’entraînement représentent environ 80% du trafic bot IA et collectent du contenu pour constituer des jeux de données destinés à l’entraînement des modèles de langage. Une fois votre contenu intégré à un jeu d’entraînement, il fait partie de la base de connaissances du modèle, ce qui peut réduire le besoin des utilisateurs de visiter votre site. Les crawlers d’entraînement tels que GPTBot, ClaudeBot et Meta-ExternalAgent opèrent à fort volume et avec des schémas systématiques, ramenant peu ou pas de trafic référent aux éditeurs.
Les crawlers de recherche et de citation indexent le contenu pour l’expérience de recherche IA et peuvent parfois renvoyer du trafic via des citations. Lorsque des utilisateurs posent des questions sur ChatGPT ou Perplexity, ces crawlers aident à faire remonter les sources pertinentes. Contrairement aux crawlers d’entraînement, les crawlers de recherche comme OAI-SearchBot et PerplexityBot opèrent à volume modéré avec un comportement centré sur la récupération et peuvent inclure attribution et liens. Les fetchers déclenchés par l’utilisateur s’activent uniquement lorsque l’utilisateur sollicite un contenu via un assistant IA. Quand quelqu’un colle une URL dans ChatGPT ou demande à Perplexity d’analyser une page spécifique, ces fetchers récupèrent le contenu à la demande. Ils fonctionnent à très faible volume et la plupart des sociétés IA confirment qu’ils ne servent pas à l’entraînement. Comprendre ces catégories vous aide à prendre des décisions stratégiques sur les crawlers à autoriser ou à bloquer selon vos priorités business.
Comment Identifier les Crawlers sur Votre Site
La première étape pour gérer les crawlers IA est de savoir lesquels visitent réellement votre site. Vos logs d’accès serveur contiennent des enregistrements détaillés de chaque requête, dont le user agent qui identifie le crawler. La plupart des panneaux d’hébergement proposent des outils d’analyse, mais vous pouvez aussi accéder directement aux logs bruts. Pour Apache, les logs sont généralement dans /var/log/apache2/access.log, pour Nginx dans /var/log/nginx/access.log. Filtrez les logs avec grep pour repérer l’activité crawler :
grep -i "gptbot\|claudebot\|google-extended\|bytespider" /var/log/apache2/access.log | head -20
Cette commande affiche les 20 requêtes les plus récentes des principaux crawlers IA. Google Search Console fournit des statistiques sur les crawlers de Google, bien qu’elle n’affiche que ceux de Google. Cloudflare Radar donne des tendances globales sur le trafic des bots IA et peut aider à identifier les crawlers actifs. Pour vérifier si un crawler est légitime ou usurpé, comparez son IP avec les listes officielles publiées par les grandes sociétés. OpenAI publie ses IP vérifiées sur https://openai.com/gptbot.json, Amazon sur https://developer.amazon.com/amazonbot/ip-addresses/, etc. Un faux crawler usurpant un user agent légitime depuis une IP non vérifiée doit être bloqué immédiatement, car il s’agit probablement d’un scraping malveillant.
Guide de Mise en Œuvre Robots.txt
Le robots.txt est votre principal outil pour contrôler l’accès des crawlers. Ce simple fichier texte, placé à la racine de votre site, indique aux crawlers quelles parties sont accessibles. Pour bloquer certains crawlers IA, ajoutez des entrées comme ceci :
# Bloquer GPTBot d’OpenAI
User-agent: GPTBot
Disallow: /
# Bloquer ClaudeBot d’Anthropic
User-agent: ClaudeBot
Disallow: /
# Bloquer l’entraînement IA de Google (pas la recherche)
User-agent: Google-Extended
Disallow: /
# Bloquer Common Crawl
User-agent: CCBot
Disallow: /
Vous pouvez aussi autoriser les crawlers tout en limitant leur débit pour éviter la surcharge serveur :
Ceci indique à GPTBot d’attendre 10 secondes entre chaque requête et d’éviter le dossier privé. Pour une approche équilibrée autorisant les crawlers de recherche tout en bloquant les crawlers d’entraînement :
# Autoriser les moteurs de recherche traditionnels
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Bloquer tous les crawlers IA d’entraînement
User-agent: GPTBot
User-agent: ClaudeBot
User-agent: CCBot
User-agent: Google-Extended
User-agent: Bytespider
User-agent: Meta-ExternalAgent
Disallow: /
# Autoriser les crawlers de recherche IA
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
La plupart des crawlers IA réputés respectent robots.txt, mais certains crawlers agressifs l’ignorent totalement. Voilà pourquoi robots.txt seul ne suffit pas pour une protection complète.
Stratégies de Blocage Avancées
Robots.txt est un conseil et non une obligation : les crawlers peuvent ignorer vos directives s’ils le souhaitent. Pour une protection plus forte contre les crawlers qui ne respectent pas robots.txt, mettez en place un blocage par IP au niveau serveur. Cette approche est plus fiable car il est plus difficile de falsifier une IP qu’un user agent. Vous pouvez autoriser les IP officielles tout en bloquant toutes les autres requêtes se réclamant de crawlers IA.
Pour Apache, utilisez des règles .htaccess pour bloquer les crawlers côté serveur :
Cela retourne une erreur 403 à tout user agent correspondant, quels que soient les paramètres robots.txt. Les règles de pare-feu offrent une protection supplémentaire en autorisant seulement les plages d’IP officielles. La plupart des pare-feux applicatifs et hébergeurs permettent de créer des règles autorisant les IP vérifiées et bloquant les autres pour les crawlers IA. Les meta tags HTML offrent un contrôle granulaire page par page. Amazon et d’autres respectent la directive noarchive :
<metaname="robots"content="noarchive">
Cela indique aux crawlers de ne pas utiliser la page pour l’entraînement tout en permettant d’autres indexations. Choisissez votre méthode de blocage selon vos capacités techniques et les crawlers ciblés. Le blocage IP est le plus fiable mais demande plus de configuration technique, tandis que robots.txt est le plus simple mais moins efficace contre les crawlers non coopératifs.
Surveillance et Vérification
Mettre en place des blocages n’est que la moitié de la solution ; vérifiez qu’ils fonctionnent. Une surveillance régulière permet de détecter tôt les problèmes et d’identifier de nouveaux crawlers. Consultez vos logs serveur chaque semaine pour repérer une activité bot inhabituelle, recherchez des user agents contenant “bot”, “crawler”, “spider” ou des noms comme “GPT”, “Claude” ou “Perplexity”. Configurez des alertes pour tout pic soudain de trafic bot pouvant signaler un nouveau crawler ou un comportement agressif. Google Search Console affiche les statistiques de crawl pour les bots Google, utile pour voir l’activité de Googlebot et Google-Extended. Cloudflare Radar fournit une vue globale des tendances de trafic des crawlers IA et aide à identifier de nouveaux bots.
Pour vérifier vos blocages robots.txt, accédez directement à votresite.com/robots.txt et vérifiez la présence de tous les user agents et directives. Pour les blocages serveur, surveillez vos logs d’accès en cherchant des requêtes de crawlers bloqués. Si vous en voyez malgré le blocage, c’est qu’ils ignorent vos directives ou usurpent leur user agent. Testez vos mises en œuvre en vérifiant l’accès crawler dans vos analyses et logs. Des revues trimestrielles sont essentielles car l’écosystème évolue vite. De nouveaux crawlers apparaissent, les existants changent de user agent, et des entreprises lancent de nouveaux bots sans préavis. Programmez des révisions régulières de votre liste de blocage pour maintenir votre protection à jour.
Suivre les Citations IA avec AmICited.com
Gérer l’accès des crawlers est important, mais savoir comment les IA citent et référencent votre contenu l’est tout autant. AmICited.com offre une surveillance complète de la façon dont votre marque et votre contenu apparaissent dans les réponses générées par ChatGPT, Perplexity, Google Gemini et autres IA. Plutôt que de simplement bloquer, AmICited.com vous permet de comprendre l’impact réel des crawlers IA sur votre visibilité et autorité. La plateforme suit quelles IA citent votre contenu, la fréquence d’apparition de votre marque dans les réponses, et comment cette visibilité se traduit en trafic et autorité. En surveillant vos citations IA, vous pouvez décider quels crawlers autoriser sur la base de données réelles, non de suppositions. AmICited.com s’intègre à votre stratégie de contenu globale et vous montre quels sujets et contenus génèrent le plus de citations IA. Cette approche data-driven vous aide à optimiser la découverte IA tout en protégeant votre propriété intellectuelle. Comprendre vos métriques de citation IA vous permet d’aligner vos choix d’accès crawler sur vos objectifs business.
Décider de Bloquer ou d’Autoriser
Décider d’autoriser ou de bloquer les crawlers IA dépend entièrement de votre situation et de vos priorités business. Autorisez les crawlers IA si : vous gérez un site d’actualité ou un blog où la visibilité dans les réponses IA génère du trafic, votre activité bénéficie d’être citée comme source dans les réponses IA, vous souhaitez influencer l’apprentissage des modèles IA dans votre secteur, ou vous êtes à l’aise avec l’utilisation de votre contenu pour l’IA. Les éditeurs de news, créateurs de contenus éducatifs et leaders d’opinion tirent souvent parti de la visibilité IA, car les citations génèrent trafic et autorité.
Bloquez les crawlers IA si : vous avez du contenu propriétaire ou des secrets industriels à protéger, vos ressources serveur sont limitées, vous craignez l’utilisation non rémunérée de votre contenu, vous voulez garder le contrôle sur l’utilisation de votre propriété intellectuelle, ou vous avez subi des problèmes de performance liés aux bots. Les sites e-commerce, SaaS, et éditeurs de contenu payant choisissent souvent de bloquer les crawlers d’entraînement. Le compromis réside entre la protection du contenu et la visibilité sur les plateformes IA. Bloquer les crawlers d’entraînement protège votre contenu mais peut réduire votre visibilité dans les réponses IA. Bloquer les crawlers de recherche peut réduire votre visibilité dans les résultats IA. Beaucoup adoptent une approche sélective : autoriser les crawlers de recherche et citation comme OAI-SearchBot et PerplexityBot tout en bloquant les crawlers d’entraînement agressifs comme GPTBot et ClaudeBot. Cette stratégie équilibre visibilité et protection contre la collecte illimitée de données. Votre choix doit s’aligner sur votre modèle économique, stratégie de contenu et contraintes de ressources.
Crawlers Émergents et Tendances Futures
L’écosystème des crawlers IA continue de s’étendre à mesure que de nouveaux entrants arrivent et que les acteurs existants lancent de nouveaux bots. Le crawler Grok de xAI commence à apparaître dans les logs à mesure que la société développe sa plateforme IA. MistralAI-User de Mistral prend en charge la récupération en temps réel pour l’assistant IA Mistral. DeepSeekBot de DeepSeek symbolise la concurrence IA chinoise émergente. Les agents IA basés sur navigateur comme Operator d’OpenAI présentent un nouveau défi : ils n’utilisent pas de user agent distinctif et apparaissent comme du trafic Chrome classique, rendant le blocage traditionnel impossible. Ces navigateurs agents incarnent la prochaine étape de l’évolution des crawlers IA, car ils interagissent avec les sites comme de vrais utilisateurs, exécutant JavaScript et naviguant dans des interfaces complexes.
L’avenir des crawlers IA passera sans doute par plus de sophistication, des mécanismes de contrôle plus fins et peut-être de nouveaux standards pour gérer l’accès IA au contenu. Restez informé sur les nouveaux crawlers car de nouveaux bots apparaissent et les existants évoluent rapidement. Surveillez des ressources comme le ai.robots.txt project sur GitHub
, qui maintient une liste communautaire des crawlers IA connus. Analysez régulièrement vos logs pour repérer de nouveaux user agents. Abonnez-vous aux mises à jour des grandes sociétés IA sur le comportement de leurs crawlers et plages IP. L’écosystème évoluera encore, et votre
Questions fréquemment posées
Quelle est la différence entre les crawlers IA et les crawlers des moteurs de recherche ?
Les crawlers IA comme GPTBot et ClaudeBot collectent du contenu spécifiquement pour entraîner des modèles de langage, tandis que les crawlers des moteurs de recherche comme Googlebot indexent le contenu pour qu’il soit trouvé via les résultats de recherche. Les crawlers IA alimentent les bases de connaissance des systèmes d’IA, alors que les crawlers de recherche aident les utilisateurs à découvrir votre contenu. La différence clé réside dans l’objectif : entraînement vs recherche.
Bloquer les crawlers IA nuira-t-il à mon classement dans les moteurs de recherche ?
Non, bloquer les crawlers IA n’affectera pas votre classement dans la recherche traditionnelle. Les crawlers IA comme GPTBot et ClaudeBot sont totalement séparés des crawlers de moteurs de recherche comme Googlebot. Vous pouvez bloquer Google-Extended (pour l’entraînement IA) tout en autorisant Googlebot (pour la recherche). Chaque crawler a un objectif distinct et bloquer l’un n’impacte pas l’autre.
Comment savoir quels crawlers IA visitent mon site web ?
Consultez les logs d’accès serveur pour voir quels user agents visitent votre site. Recherchez des noms de bots comme GPTBot, ClaudeBot, CCBot et Bytespider dans les chaînes user agent. La plupart des panneaux d’hébergement proposent des outils d’analyse de logs. Vous pouvez également utiliser Google Search Console pour surveiller l’activité de crawl, mais cela n’affiche que les crawlers de Google.
Tous les crawlers IA respectent-ils les directives du robots.txt ?
Tous les crawlers IA ne respectent pas robots.txt de la même manière. GPTBot d’OpenAI, ClaudeBot d’Anthropic et Google-Extended suivent en général les règles robots.txt. Bytespider et PerplexityBot ont fait l’objet de rapports les accusant de ne pas toujours respecter ces directives. Pour les crawlers qui ne respectent pas robots.txt, vous devrez mettre en place un blocage basé sur les IP au niveau du serveur via votre pare-feu ou un fichier .htaccess.
Dois-je bloquer tous les crawlers IA ou seulement ceux d’entraînement ?
La décision dépend de vos objectifs. Bloquez les crawlers d’entraînement si vous avez du contenu propriétaire ou des ressources serveur limitées. Autorisez les crawlers de recherche si vous souhaitez être visible dans les résultats de recherche et chatbots IA, ce qui peut générer du trafic et asseoir votre autorité. Beaucoup d’entreprises adoptent une approche sélective en autorisant certains crawlers tout en bloquant les plus agressifs comme Bytespider.
À quelle fréquence dois-je mettre à jour ma liste de blocage des crawlers IA ?
De nouveaux crawlers IA apparaissent régulièrement, donc révisez et mettez à jour votre liste de blocage au moins chaque trimestre. Suivez des ressources comme le projet ai.robots.txt sur GitHub pour des listes communautaires. Consultez vos logs de serveur chaque mois pour identifier de nouveaux crawlers qui ne figurent pas dans votre configuration actuelle. L’écosystème des crawlers IA évolue rapidement, adaptez votre stratégie en conséquence.
Puis-je vérifier si un crawler est légitime ou usurpé ?
Oui, vérifiez l’adresse IP de la requête avec les listes officielles publiées par les grandes entreprises. OpenAI publie des IP vérifiées sur https://openai.com/gptbot.json, Amazon sur https://developer.amazon.com/amazonbot/ip-addresses/, et d’autres maintiennent des listes similaires. Un crawler qui usurpe un user agent légitime à partir d’une IP non vérifiée doit être bloqué immédiatement car il s’agit probablement d’un scraping malveillant.
Quel est l’impact des crawlers IA sur les performances de mon site ?
Les crawlers IA peuvent consommer beaucoup de bande passante et de ressources serveur. Bytespider et Meta-ExternalAgent comptent parmi les crawlers les plus agressifs. Certains éditeurs rapportent une réduction de la bande passante de 800 Go à 200 Go par jour en bloquant les crawlers IA, économisant environ 1 500 $ par mois. Surveillez vos ressources serveur pendant les pics de crawl et mettez en place une limitation de débit pour les bots agressifs si nécessaire.
Prenez le Contrôle de Votre Visibilité IA
Suivez quels crawlers IA citent votre contenu et optimisez votre visibilité sur ChatGPT, Perplexity, Google Gemini, et plus encore.
Quelle est la fréquence de crawl pour la recherche IA ? Comprendre le comportement des bots IA
Découvrez comment les crawlers IA déterminent la fréquence de crawl de votre site web. Voyez comment ChatGPT, Perplexity et d'autres moteurs IA crawlent le cont...
Le guide complet pour bloquer (ou autoriser) les crawlers IA
Apprenez à bloquer ou autoriser les crawlers IA comme GPTBot et ClaudeBot grâce à robots.txt, au blocage serveur et à des méthodes de protection avancées. Guide...
Quels crawlers IA dois-je autoriser ? Guide complet pour 2025
Découvrez quels crawlers IA autoriser ou bloquer dans votre robots.txt. Guide complet couvrant GPTBot, ClaudeBot, PerplexityBot et plus de 25 crawlers IA avec e...
12 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.