
Quels crawlers IA dois-je autoriser ? Guide complet pour 2025
Découvrez quels crawlers IA autoriser ou bloquer dans votre robots.txt. Guide complet couvrant GPTBot, ClaudeBot, PerplexityBot et plus de 25 crawlers IA avec e...
12 min de lecture

Comprenez comment fonctionnent les crawlers IA comme GPTBot et ClaudeBot, leurs différences avec les crawlers de recherche traditionnels, et comment optimiser votre site pour la visibilité dans la recherche IA.
Les crawlers IA sont des programmes automatisés conçus pour parcourir systématiquement Internet et collecter des données sur les sites web, spécifiquement pour entraîner et améliorer les modèles d’intelligence artificielle. Contrairement aux crawlers de moteurs de recherche traditionnels tels que Googlebot, qui indexent le contenu pour les résultats de recherche, les crawlers IA recueillent des données web brutes pour alimenter de grands modèles de langage (LLM) comme ChatGPT, Claude et d’autres systèmes IA. Ces bots opèrent en continu sur des millions de sites web, téléchargeant des pages, analysant le contenu et extrayant des informations qui aident les plateformes IA à comprendre les schémas linguistiques, les faits et une diversité de styles d’écriture. Les principaux acteurs de ce secteur incluent GPTBot d’OpenAI, ClaudeBot d’Anthropic, Meta-ExternalAgent de Meta, Amazonbot d’Amazon et PerplexityBot de Perplexity.ai, chacun répondant aux besoins de formation et d’exploitation de leurs propres plateformes IA. Comprendre le fonctionnement de ces crawlers est devenu essentiel pour les propriétaires de sites et les créateurs de contenu, car la visibilité dans l’IA influence désormais directement la façon dont votre marque apparaît dans les résultats de recherche et recommandations propulsés par l’IA.
Le paysage de l’exploration web a connu une transformation spectaculaire au cours de l’année écoulée, avec une croissance explosive des crawlers IA tandis que les crawlers de recherche traditionnels maintiennent des schémas stables. Entre mai 2024 et mai 2025, le trafic global des crawlers a augmenté de 18 %, mais la répartition a changé de façon significative — GPTBot a bondi de 305 % en nombre de requêtes brutes, tandis que d’autres crawlers comme ClaudeBot ont chuté de 46 % et Bytespider a dégringolé de 85 %. Cette réorganisation reflète l’intensification de la concurrence entre les entreprises IA pour sécuriser les données d’entraînement et améliorer leurs modèles. Voici une vue détaillée des principaux crawlers et de leur position actuelle sur le marché :
| Nom du crawler | Entreprise | Requêtes mensuelles | Croissance annuelle | Objectif principal |
|---|---|---|---|---|
| Googlebot | 4,5 milliards | 96 % | Indexation de recherche & AI Overviews | |
| GPTBot | OpenAI | 569 millions | 305 % | Entraînement de ChatGPT & recherche |
| Claude | Anthropic | 370 millions | -46 % | Entraînement de Claude & recherche |
| Bingbot | Microsoft | ~450 millions | 2 % | Indexation de recherche |
| PerplexityBot | Perplexity.ai | 24,4 millions | 157 490 % | Indexation IA de recherche |
| Meta-ExternalAgent | Meta | ~380 millions | Nouvelle entrée | Entraînement Meta AI |
| Amazonbot | Amazon | ~210 millions | -35 % | Recherche & applications IA |
Les données montrent que même si Googlebot conserve sa domination avec 4,5 milliards de requêtes mensuelles, les crawlers IA représentent collectivement environ 28 % du volume de Googlebot, ce qui en fait une force significative du trafic web. L’explosion de PerplexityBot (augmentation de 157 490 %) démontre la rapidité à laquelle de nouvelles plateformes IA étendent leurs opérations de crawl, tandis que le recul de certains crawlers IA établis laisse entrevoir une consolidation du marché autour des plateformes IA les plus performantes.
GPTBot est le crawler web d’OpenAI, spécialement conçu pour collecter des données en vue d’entraîner et d’améliorer ChatGPT ainsi que d’autres modèles OpenAI. Lancé comme acteur relativement mineur avec seulement 5 % de part de marché en mai 2024, GPTBot est devenu le crawler IA dominant, captant 30 % du trafic total des crawlers IA en mai 2025 — une progression remarquable de 305 % en nombre de requêtes. Cette croissance explosive reflète la stratégie agressive d’OpenAI pour garantir à ChatGPT un accès à du contenu web frais et diversifié, tant pour l’entraînement du modèle que pour des capacités de recherche en temps réel via ChatGPT Search. GPTBot opère selon un schéma de crawl distinct, privilégiant le contenu HTML (57,70 % des récupérations) tout en téléchargeant aussi des fichiers JavaScript et des images, bien qu’il n’exécute pas le JavaScript pour rendre du contenu dynamique. Son comportement montre qu’il rencontre fréquemment des erreurs 404 (34,82 % des requêtes), suggérant qu’il suit parfois des liens obsolètes ou tente d’accéder à des ressources qui n’existent plus. Pour les propriétaires de sites, la domination de GPTBot signifie qu’assurer l’accessibilité de votre contenu à ce crawler est devenu crucial pour la visibilité dans la recherche ChatGPT et pour une potentielle inclusion dans les futures itérations d’entraînement du modèle.
ClaudeBot, développé par Anthropic, est le crawler principal pour l’entraînement et la mise à jour de l’assistant IA Claude, en plus de supporter les fonctions de recherche et d’ancrage de Claude. Autrefois deuxième plus grand crawler IA avec 27 % de part de marché en mai 2024, ClaudeBot a connu un déclin notable à 21 % en mai 2025, le nombre de requêtes brutes chutant de 46 % sur un an. Ce recul n’indique pas nécessairement un problème dans la stratégie d’Anthropic, mais plutôt un déplacement du marché vers la domination d’OpenAI et l’émergence de nouveaux concurrents comme Meta-ExternalAgent. ClaudeBot présente un comportement similaire à GPTBot, en privilégiant le contenu HTML mais en consacrant une part plus importante de ses requêtes aux images (35,17 % des récupérations), ce qui suggère qu’Anthropic pourrait entraîner Claude à mieux comprendre le contenu visuel en complément du texte. Comme les autres crawlers IA, ClaudeBot n’interprète pas le JavaScript, ce qui signifie qu’il ne voit que le HTML brut des pages, sans contenu chargé dynamiquement. Pour les créateurs de contenu, maintenir la visibilité auprès de ClaudeBot reste important afin que Claude puisse accéder à votre contenu et le citer, surtout à mesure qu’Anthropic développe les capacités de recherche et de raisonnement de Claude.
En dehors de GPTBot et ClaudeBot, plusieurs autres crawlers IA majeurs collectent activement des données web pour leurs plateformes respectives :
Meta-ExternalAgent (Meta) : Le crawler de Meta a fait une entrée spectaculaire dans le classement, captant 19 % de part de marché en mai 2025 en tant que nouvel entrant. Ce bot collecte des données pour les initiatives IA de Meta, y compris un possible entraînement pour Meta AI et son intégration aux fonctionnalités IA d’Instagram et Facebook. La progression rapide de Meta laisse penser que l’entreprise mise énormément sur la recherche et les recommandations propulsées par l’IA.
PerplexityBot (Perplexity.ai) : Malgré seulement 0,2 % de part de marché, PerplexityBot a enregistré la croissance la plus explosive avec 157 490 % d’augmentation sur un an. Cela reflète la montée en puissance de Perplexity comme moteur de réponse IA reposant sur la recherche web en temps réel pour étayer ses réponses. Pour les sites web, les visites de PerplexityBot représentent autant d’opportunités d’être cité dans les réponses IA générées par Perplexity.
Amazonbot (Amazon) : Le crawler d’Amazon est passé de 21 % à 11 % de part de marché, les requêtes brutes baissant de 35 % sur un an. Amazonbot collecte des données pour la recherche Amazon et les applications IA, mais ce recul suggère qu’Amazon pourrait revoir sa stratégie IA ou consolider ses opérations de crawl.
Applebot (Apple) : Le crawler d’Apple a connu une baisse de 26 % des requêtes, passant de 1,9 % à 1,2 % de part de marché. Applebot sert principalement Siri et la recherche Spotlight, mais il pourrait aussi soutenir les initiatives IA d’Apple. Contrairement à la plupart des autres crawlers IA, Applebot peut interpréter le JavaScript, ce qui lui confère des capacités proches de Googlebot.
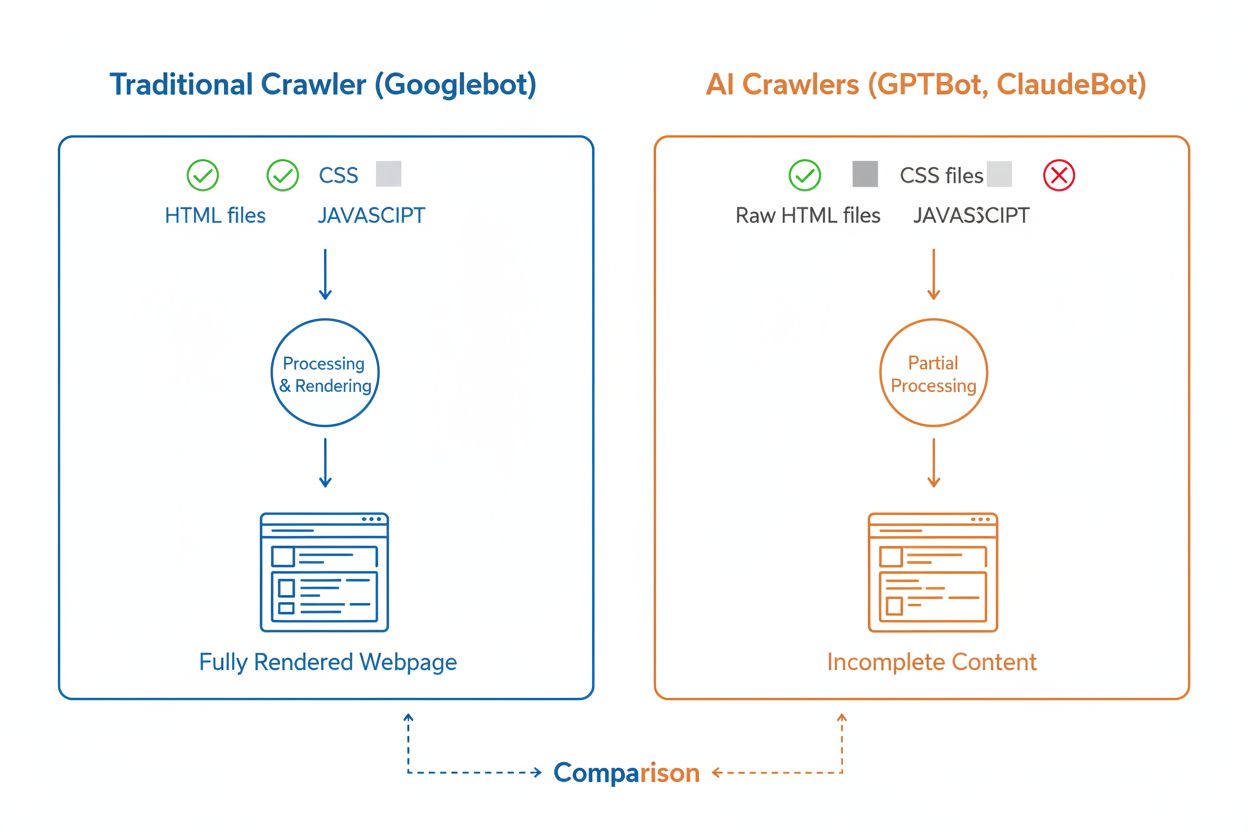
Bien que les crawlers IA et les crawlers de recherche traditionnels comme Googlebot parcourent tous deux systématiquement le web, leurs capacités techniques et leurs comportements diffèrent profondément, ce qui impacte directement la façon dont votre contenu est découvert et compris. La différence la plus critique concerne le rendu JavaScript : Googlebot peut exécuter le JavaScript après avoir téléchargé une page, ce qui lui permet de voir le contenu chargé dynamiquement, alors que la plupart des crawlers IA (GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider) ne lisent que le HTML brut et ignorent tout contenu dépendant du JavaScript. Cela signifie que si votre site s’appuie sur le rendu côté client pour afficher des informations clés, les crawlers IA ne verront qu’une version incomplète de vos pages. De plus, les crawlers IA présentent des schémas de crawl moins prévisibles par rapport à l’approche systématique de Googlebot : ils consacrent 34,82 % de leurs requêtes à des pages 404 et 14,36 % à suivre des redirections, contre 8,22 % et 1,49 % respectivement pour Googlebot. La fréquence d’exploration diffère aussi : alors que Googlebot visite les pages selon un système sophistiqué de crawl budget, les crawlers IA semblent crawler plus fréquemment mais de manière moins systématique, certaines recherches montrant qu’ils peuvent visiter des pages plus de 100 fois plus souvent que Google dans certains cas. Ces différences signifient que les stratégies SEO traditionnelles ne suffisent pas à garantir l’explorabilité IA, nécessitant une approche distincte axée sur le rendu côté serveur et des structures d’URL propres.
L’un des plus grands défis techniques pour les crawlers IA est leur incapacité à interpréter le JavaScript, une limitation qui découle du coût computationnel d’exécuter du JavaScript à l’échelle gigantesque requise pour entraîner de grands modèles de langage. Lorsqu’un crawler télécharge votre page web, il reçoit la réponse HTML initiale, mais tout contenu chargé ou modifié par JavaScript — comme des détails produits, des informations tarifaires, des avis clients ou des éléments de navigation dynamiques — reste invisible aux crawlers IA. Cela pose un problème critique pour les sites modernes reposant fortement sur des frameworks de rendu côté client comme React, Vue ou Angular sans rendu côté serveur (SSR) ou génération de site statique (SSG). Par exemple, un site e-commerce qui charge les informations produit via JavaScript apparaîtra aux crawlers IA comme une page vide sans aucun détail produit, rendant impossible pour les systèmes IA de comprendre ou de citer ce contenu. La solution consiste à s’assurer que tout le contenu critique est servi dans la réponse HTML initiale grâce au rendu côté serveur, qui génère le HTML complet sur le serveur avant de l’envoyer au navigateur. Cette approche garantit que les visiteurs humains et les crawlers IA bénéficient de la même expérience riche en contenu. Les sites utilisant des frameworks modernes comme Next.js avec SSR, des générateurs statiques comme Hugo ou Gatsby, ou des plateformes traditionnelles comme WordPress sont naturellement adaptés aux crawlers IA, alors que ceux reposant uniquement sur le rendu côté client font face à de sérieux défis de visibilité en recherche IA.
Les crawlers IA présentent des schémas de fréquence d’exploration distincts de ceux de Googlebot, avec des implications importantes sur la rapidité avec laquelle votre contenu est capté par les systèmes IA. Les recherches montrent que des crawlers IA comme ChatGPT et Perplexity visitent souvent les pages plus fréquemment que Google à court terme après leur publication — dans certains cas, jusqu’à 8 fois plus souvent que Googlebot dans les premiers jours. Ce crawl initial rapide suggère que les plateformes IA priorisent la découverte et l’indexation rapides des nouveaux contenus, afin que leurs modèles et fonctions de recherche disposent des informations les plus récentes. Cependant, cette exploration intensive initiale est suivie d’un schéma où les crawlers IA peuvent ne pas revenir si le contenu ne répond pas à des standards de qualité, rendant la première impression cruciale. Contrairement à Googlebot, qui dispose d’un système sophistiqué de crawl budget et revient régulièrement sur les pages selon leur fréquence de mise à jour et leur importance, les crawlers IA semblent juger rapidement si un contenu mérite d’être revisité. Ainsi, si un crawler IA visite votre page et y trouve un contenu faible, des erreurs techniques ou de mauvais signaux d’expérience utilisateur, il pourrait mettre beaucoup de temps à revenir — voire ne jamais revenir. Pour les créateurs de contenu, cela signifie qu’il ne faut pas compter sur une seconde chance d’optimisation pour les crawlers IA comme on le ferait pour les moteurs de recherche traditionnels, d’où l’importance de l’assurance qualité avant publication.
Les propriétaires de sites peuvent utiliser le fichier robots.txt pour exprimer leurs préférences concernant l’accès des crawlers IA, même si l’efficacité et l’application de ces règles varient grandement selon les crawlers. Selon des données récentes, environ 14 % des 10 000 plus grands sites ont mis en place des règles d’autorisation ou d’interdiction ciblant spécifiquement les bots IA dans leur robots.txt. GPTBot est le crawler le plus souvent bloqué, avec 312 domaines (250 totalement, 62 partiellement) l’interdisant explicitement, mais c’est aussi celui qui est le plus explicitement autorisé avec 61 domaines lui donnant l’accès. D’autres crawlers couramment bloqués incluent CCBot (Common Crawl) et Google-Extended (le token d’entraînement IA de Google). Le problème du robots.txt est que le respect est volontaire : les crawlers n’appliquent ces règles que si leurs opérateurs choisissent de le faire, et certains crawlers récents ou peu transparents peuvent ignorer les directives du robots.txt. De plus, les tokens comme “Google-Extended” ne correspondent pas directement à des user-agents dans les requêtes HTTP ; ils signalent plutôt l’objectif du crawl, ce qui signifie que l’on ne peut pas toujours vérifier le respect via les logs serveur. Pour une application plus stricte, les propriétaires de sites se tournent de plus en plus vers des règles de pare-feu et des Web Application Firewalls (WAF) permettant de bloquer activement des user-agents spécifiques, offrant un contrôle bien plus fiable que le seul robots.txt. Ce passage à des mécanismes de blocage actifs reflète des préoccupations croissantes quant aux droits sur le contenu et la volonté de mieux contrôler l’accès des crawlers IA.
Suivre l’activité des crawlers IA sur votre site est essentiel pour comprendre votre visibilité dans la recherche IA, mais cela présente des défis uniques par rapport au suivi des crawlers de moteurs de recherche traditionnels. Les outils d’analyse classiques comme Google Analytics se basent sur le suivi JavaScript, que les crawlers IA n’exécutent pas, ce qui signifie que ces outils ne donnent aucune visibilité sur les visites des bots IA. De même, le tracking par pixel ne fonctionne pas car la plupart des crawlers IA ne traitent que le texte et ignorent les images. Le seul moyen fiable de suivre l’activité des crawlers IA est la surveillance côté serveur : analyser les en-têtes des requêtes HTTP et les logs serveur pour identifier les user-agents de crawlers avant l’envoi de la page. Cela nécessite soit une analyse manuelle des logs, soit des outils spécialisés conçus spécialement pour détecter et suivre le trafic des crawlers IA. La surveillance en temps réel est particulièrement cruciale car les crawlers IA opèrent selon des plannings imprévisibles et pourraient ne pas revenir sur les pages où ils rencontrent des problèmes, ce qui fait qu’un audit hebdomadaire ou mensuel pourrait rater des problèmes importants. Si un crawler IA visite votre site et rencontre une erreur technique ou un contenu de mauvaise qualité, vous n’aurez peut-être pas une nouvelle occasion de faire bonne impression. Mettre en place des solutions de surveillance 24/7 qui vous alertent immédiatement lorsque les crawlers IA rencontrent des problèmes — erreurs 404, temps de chargement lents, balisage schema manquant — vous permet de corriger les soucis avant qu’ils n’impactent votre visibilité dans la recherche IA. Cette approche en temps réel marque un changement fondamental par rapport aux pratiques SEO traditionnelles, reflétant la rapidité et l’imprévisibilité du comportement des crawlers IA.
L’optimisation de votre site pour les crawlers IA nécessite une approche distincte du SEO traditionnel, axée sur des facteurs techniques qui impactent directement la façon dont les systèmes IA peuvent accéder à et comprendre votre contenu. La première priorité est le rendu côté serveur : assurez-vous que tout le contenu critique — titres, texte principal, métadonnées, données structurées — figure dans la réponse HTML initiale, et non chargé dynamiquement via JavaScript. Cela s’applique à votre page d’accueil, aux pages clés et à tout contenu que vous souhaitez voir cité ou référencé par l’IA. Ensuite, implémentez un balisage de données structurées (Schema.org) sur vos pages à fort impact, incluant le schéma article pour les blogs, le schéma produit pour les e-commerces, et le schéma auteur pour asseoir votre expertise et autorité. Les crawlers IA utilisent les données structurées pour comprendre rapidement la hiérarchie et le contexte du contenu, ce qui facilite grandement l’analyse et la citation de vos informations. Troisièmement, maintenez des standards élevés de qualité de contenu sur toutes vos pages, car les crawlers IA semblent juger rapidement si un contenu mérite d’être indexé et cité. Cela implique un contenu original, bien documenté, factuellement exact et réellement utile pour les lecteurs. Quatrièmement, surveillez et optimisez les Core Web Vitals et la performance globale des pages, car des pages lentes signalent une mauvaise expérience utilisateur et peuvent décourager les crawlers IA de revenir. Enfin, gardez une structure d’URL propre et cohérente, maintenez un sitemap XML à jour et configurez correctement votre robots.txt pour guider les crawlers vers vos contenus les plus importants. Ces optimisations techniques posent les bases pour que votre contenu soit découvert, compris et cité par les systèmes IA.
Le paysage des crawlers IA va continuer à évoluer rapidement à mesure que la concurrence s’accentue entre les sociétés d’IA et que la technologie mûrit. Une tendance claire est la consolidation des parts de marché autour des plateformes les plus performantes — GPTBot d’OpenAI s’impose comme la force dominante, tandis que de nouveaux entrants comme Meta-ExternalAgent montent en puissance, ce qui laisse supposer que le marché se stabilisera autour de quelques grands acteurs. À mesure que les crawlers IA mûrissent, on peut s’attendre à des améliorations de leurs capacités techniques, notamment en matière d’interprétation JavaScript et de schémas de crawl plus efficaces limitant les requêtes inutiles sur des pages 404 ou du contenu obsolète. L’industrie s’oriente aussi vers des protocoles de communication plus standardisés, comme la nouvelle spécification llms.txt, qui permet aux sites de communiquer explicitement leur structure de contenu et leurs préférences d’exploration aux systèmes IA. De plus, les mécanismes de contrôle d’accès aux crawlers IA deviennent plus sophistiqués, des plateformes comme Cloudflare proposant désormais par défaut le blocage automatisé des bots d’entraînement IA, offrant ainsi aux propriétaires de sites un contrôle plus fin sur leur contenu. Pour les créateurs de contenu et propriétaires de sites, anticiper ces évolutions implique de surveiller en continu l’activité des crawlers IA, de maintenir une infrastructure technique optimisée pour l’accessibilité IA, et d’adapter leur stratégie de contenu en tenant compte du fait que l’IA représente désormais une part importante du trafic web et un canal critique de visibilité de marque. L’avenir appartient à ceux qui comprennent et optimisent pour ce nouvel écosystème de crawlers.
Les crawlers IA sont des programmes automatisés qui collectent des données web spécifiquement pour entraîner et améliorer des modèles d'intelligence artificielle comme ChatGPT et Claude. Contrairement aux crawlers de moteurs de recherche traditionnels tels que Googlebot, qui indexent le contenu pour les résultats de recherche, les crawlers IA recueillent des données web brutes afin de les intégrer dans de grands modèles de langage. Les deux types de crawlers parcourent systématiquement Internet, mais ils servent des objectifs différents et disposent de capacités techniques différentes.
Les crawlers IA accèdent à votre site pour collecter des données afin d'entraîner des modèles IA, d'améliorer les fonctionnalités de recherche et d'ancrer les réponses IA avec des informations à jour. Lorsque des systèmes IA comme ChatGPT ou Perplexity répondent aux questions des utilisateurs, ils doivent souvent récupérer votre contenu en temps réel pour fournir des informations précises et citées. Autoriser les crawlers IA à accéder à votre site augmente les chances que votre marque soit mentionnée et citée dans les réponses générées par IA.
Oui, vous pouvez utiliser votre fichier robots.txt pour interdire des crawlers IA spécifiques en précisant leurs noms d'agent utilisateur. Cependant, le respect du robots.txt est volontaire et tous les crawlers ne respectent pas ces règles. Pour une application plus stricte, vous pouvez utiliser des règles de pare-feu et des Web Application Firewalls (WAF) pour bloquer activement certains agents utilisateur de crawlers. Cela vous donne un contrôle plus fiable sur les crawlers IA pouvant accéder à votre contenu.
Non, la plupart des crawlers IA (GPTBot, ClaudeBot, Meta-ExternalAgent) n'exécutent pas de JavaScript. Ils lisent uniquement le HTML brut de vos pages, ce qui signifie que tout contenu chargé dynamiquement via JavaScript leur sera invisible. C'est pourquoi le rendu côté serveur est essentiel pour l'exploration IA. Si votre site repose sur le rendu côté client, les crawlers IA ne verront qu'une version incomplète de vos pages.
Les crawlers IA visitent les sites web plus fréquemment que les moteurs de recherche traditionnels à court terme après la publication d'un contenu. Les recherches montrent qu'ils peuvent visiter les pages 8 à 100 fois plus souvent que Google dans les premiers jours. Cependant, si le contenu ne répond pas aux standards de qualité, ils peuvent ne pas revenir. Cela rend la première impression cruciale — vous n'aurez peut-être pas de seconde chance pour optimiser votre contenu pour les crawlers IA.
Les principales optimisations sont : (1) Utilisez le rendu côté serveur pour que le contenu critique soit dans le HTML initial, (2) Ajoutez un balisage de données structurées (Schema) pour aider l'IA à comprendre votre contenu, (3) Maintenez une haute qualité et fraîcheur du contenu, (4) Surveillez les Core Web Vitals pour une bonne expérience utilisateur, et (5) Gardez une structure d'URL propre et un sitemap à jour. Ces optimisations techniques créent une base pour que votre contenu soit découvrable et cité par les systèmes IA.
GPTBot d'OpenAI est actuellement le crawler IA dominant, captant 30 % de tout le trafic des crawlers IA et connaissant une croissance de 305 % d'une année sur l'autre. Cependant, vous devez optimiser pour tous les principaux crawlers, y compris ClaudeBot (Anthropic), Meta-ExternalAgent (Meta), PerplexityBot (Perplexity), et d'autres. Différentes plateformes IA ont des bases d'utilisateurs différentes, donc la visibilité sur plusieurs crawlers maximise la présence de votre marque dans la recherche IA.
Les outils d'analyse traditionnels comme Google Analytics ne capturent pas l'activité des crawlers IA car ils se basent sur le suivi JavaScript. À la place, vous devez utiliser une surveillance côté serveur qui analyse les en-têtes des requêtes HTTP et les journaux du serveur pour identifier les agents utilisateur des crawlers. Des outils spécialisés conçus pour le suivi des crawlers IA offrent une visibilité en temps réel sur les pages explorées, la fréquence des visites et les éventuels problèmes techniques rencontrés par les crawlers.
Suivez comment les crawlers IA comme GPTBot et ClaudeBot accèdent et citent votre contenu. Obtenez des informations en temps réel sur votre visibilité IA grâce à AmICited.
Découvrez quels crawlers IA autoriser ou bloquer dans votre robots.txt. Guide complet couvrant GPTBot, ClaudeBot, PerplexityBot et plus de 25 crawlers IA avec e...

Découvrez comment prendre des décisions stratégiques concernant le blocage des crawlers IA. Évaluez le type de contenu, les sources de trafic, les modèles de re...
Découvrez comment identifier et surveiller les crawlers IA comme GPTBot, PerplexityBot et ClaudeBot dans vos logs serveur. Découvrez les chaînes user-agent, les...