Robots d’entraînement IA vs robots d’indexation : Comprendre la différence
Découvrez les différences essentielles entre les robots d’entraînement IA et les robots d’indexation. Apprenez comment ils influencent la visibilité de votre contenu, vos stratégies d’optimisation et les citations par l’IA.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
Les robots des moteurs de recherche comme Googlebot et Bingbot sont la colonne vertébrale du fonctionnement traditionnel des moteurs de recherche. Ces bots automatisés naviguent systématiquement sur le web, découvrant et indexant du contenu pour déterminer ce qui apparaît dans les pages de résultats des moteurs de recherche (SERP). Googlebot, opéré par Google, est le robot d’indexation le plus connu et le plus actif, suivi par Bingbot de Microsoft et YandexBot de Yandex. Ces robots disposent de capacités sophistiquées leur permettant d’exécuter du JavaScript, d’afficher du contenu dynamique et de comprendre des structures de sites complexes. Ils visitent fréquemment les sites web en fonction de facteurs tels que l’autorité du site, la fraîcheur du contenu et l’historique des mises à jour, les sites à forte autorité recevant des visites plus fréquentes. L’objectif principal des robots d’indexation est d’indexer le contenu pour le classement, c’est-à-dire d’évaluer les pages selon leur pertinence, leur qualité et les signaux d’expérience utilisateur.
Type de robot
Objectif principal
Prise en charge JavaScript
Fréquence de crawl
But
Googlebot
Indexer pour le classement dans la recherche
Oui (avec limitations)
Fréquent, basé sur l’autorité
Classement & visibilité
Bingbot
Indexer pour le classement dans la recherche
Oui (avec limitations)
Régulier, selon les mises à jour de contenu
Classement & visibilité
YandexBot
Indexer pour le classement dans la recherche
Oui (avec limitations)
Régulier, selon les signaux du site
Classement & visibilité
Qu’est-ce qu’un robot d’entraînement IA ?
Les robots d’entraînement IA constituent une catégorie fondamentalement différente de bots web conçus pour collecter des données destinées à l’entraînement de grands modèles de langage (LLM), et non pour l’indexation de recherche. GPTBot, opéré par OpenAI, est le robot d’entraînement IA le plus connu, aux côtés de ClaudeBot d’Anthropic, PetalBot de Huawei et CCBot de Common Crawl. Contrairement aux robots d’indexation qui visent à classer le contenu, les robots d’entraînement IA se concentrent sur la collecte d’informations de haute qualité et contextuellement riches afin d’améliorer la base de connaissances et les capacités de génération de réponses des modèles IA. Ces robots opèrent généralement moins fréquemment que les robots d’indexation, visitant souvent un site seulement une fois toutes les quelques semaines ou mois, et privilégient la qualité du contenu plutôt que le volume. Cette distinction est cruciale : alors que votre contenu peut être parfaitement indexé par Googlebot pour la visibilité dans la recherche, il peut n’être que partiellement ou rarement crawlé par GPTBot pour l’entraînement des modèles IA.
Type de robot
Objectif principal
Prise en charge JavaScript
Fréquence de crawl
But
GPTBot
Collecter des données pour l’entraînement LLM
Non
Peu fréquent, sélectif
Qualité des données d’entraînement
ClaudeBot
Collecter des données pour l’entraînement LLM
Non
Peu fréquent, sélectif
Qualité des données d’entraînement
PetalBot
Collecter des données pour l’entraînement LLM
Non
Peu fréquent, sélectif
Qualité des données d’entraînement
CCBot
Collecter des données pour Common Crawl
Non
Peu fréquent, sélectif
Qualité des données d’entraînement
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Les distinctions techniques entre robots d’indexation et robots d’entraînement IA ont des implications majeures sur la visibilité du contenu. La différence la plus critique est l’exécution du JavaScript : les robots d’indexation comme Googlebot peuvent exécuter le JavaScript (avec certaines limitations), ce qui leur permet de voir le contenu rendu dynamiquement. Les robots d’entraînement IA, à l’inverse, n’exécutent pas du tout de JavaScript — ils analysent uniquement le HTML brut disponible au chargement initial de la page. Cette différence fondamentale signifie que tout contenu chargé dynamiquement via des scripts côté client reste totalement invisible pour les robots IA. De plus, les robots d’indexation respectent des budgets de crawl et priorisent les pages selon l’architecture du site et le maillage interne, tandis que les robots IA adoptent des schémas de crawl plus sélectifs, axés sur la qualité. Les robots d’indexation suivent généralement strictement les directives du robots.txt, alors que certains robots IA ont historiquement été moins transparents sur leur conformité. La fréquence de crawl diffère radicalement : les robots d’indexation visitent les sites actifs plusieurs fois par semaine voire quotidiennement, alors que les robots d’entraînement IA peuvent ne visiter qu’une fois toutes les quelques semaines ou mois. Enfin, les robots d’indexation sont conçus pour comprendre les signaux de classement et les métriques d’expérience utilisateur, tandis que les robots IA se concentrent sur l’extraction de texte propre et bien structuré pour l’entraînement des modèles.
Fonctionnalité
Robots d’indexation
Robots d’entraînement IA
Exécution JavaScript
Oui (avec limitations)
Non
Fréquence de crawl
Élevée (plusieurs fois par semaine)
Faible (une fois toutes les quelques semaines)
Analyse du contenu
Rendu complet de la page
HTML brut uniquement
Respect du robots.txt
Strict
Variable
Priorisation du budget de crawl
Priorisation par autorité
Sélection basée sur la qualité
Gestion du contenu dynamique
Peut rendre et indexer
Ignore totalement
Objectif principal
Classement & visibilité recherche
Collecte de données d’entraînement
Tolérance au timeout
Longue (autorise un rendu complexe)
Serrée (1-5 secondes)
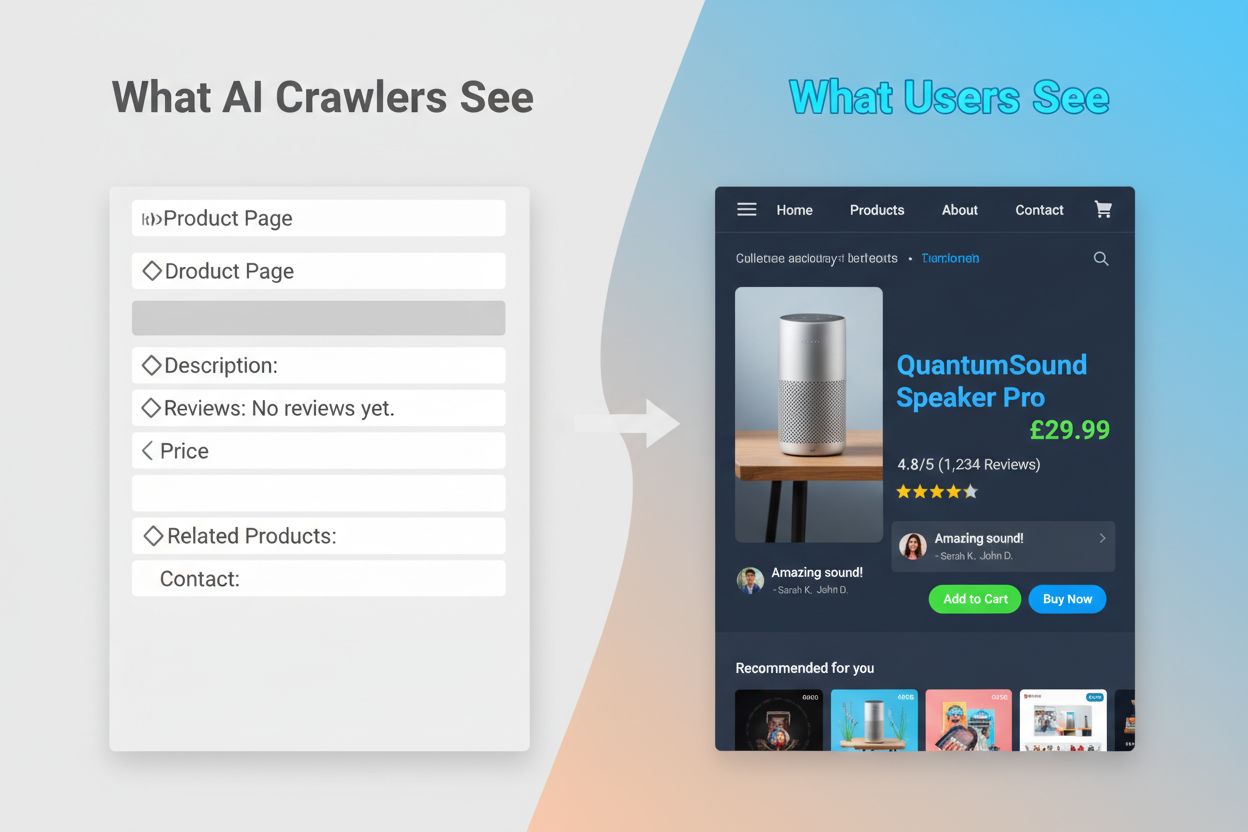
Le problème du JavaScript
L’incapacité des robots IA à exécuter du JavaScript crée un écart de visibilité critique qui affecte de nombreux sites web modernes. Lorsqu’un site dépend du JavaScript pour charger dynamiquement son contenu — descriptions produit, avis clients, prix, images — ce contenu devient invisible pour les robots IA. Cela pose particulièrement problème pour les applications monopage (SPA) basées sur React, Vue ou Angular, où la majorité du contenu est chargée côté client après la livraison du HTML initial. Par exemple, un site e-commerce peut afficher la disponibilité et les prix des produits via JavaScript, ce qui fait que GPTBot ne voit qu’une page blanche ou une structure HTML basique. De même, les sites utilisant le lazy-loading pour les images ou le scroll infini pour le contenu verront ces éléments complètement ignorés par les robots IA. L’impact business est considérable : si vos détails produits, témoignages clients ou contenus clés sont cachés derrière du JavaScript, les systèmes IA comme ChatGPT et Perplexity n’auront pas accès à ces informations lors de la génération de réponses. Le résultat : votre contenu peut très bien se classer sur Google mais être totalement absent des réponses générées par l’IA, vous rendant invisible pour une partie croissante des utilisateurs qui s’appuient sur l’IA pour la découverte d’informations.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Robots d’indexation vs robots IA : implications pratiques
Les conséquences pratiques de ces différences techniques sont profondes et souvent mal comprises par les propriétaires de sites. Votre site peut obtenir d’excellents classements Google tout en étant presque invisible pour ChatGPT, Perplexity et d’autres systèmes IA. Cela crée une situation paradoxale où le succès SEO traditionnel ne garantit pas la visibilité IA. Lorsque les utilisateurs demandent à ChatGPT une information sur votre secteur ou produit, le système peut citer vos concurrents plutôt que vous, simplement parce que leur contenu était plus accessible aux robots IA. La relation entre les données d’entraînement et les citations en recherche ajoute une couche de complexité : le contenu utilisé pour entraîner un modèle IA peut être favorisé dans les résultats de ce modèle, ce qui signifie que bloquer les robots d’entraînement IA pourrait réduire votre visibilité dans les réponses alimentées par l’IA. Pour les éditeurs et créateurs de contenu, la décision stratégique d’autoriser ou non les robots IA a donc des conséquences réelles sur le trafic futur. Un site qui bloque GPTBot pour protéger son contenu de l’entraînement peut voir ses chances d’apparaître dans les résultats de ChatGPT diminuer. À l’inverse, autoriser les robots IA à accéder à votre contenu fournit des données d’entraînement sans garantir des citations ou du trafic, ce qui crée un véritable dilemme stratégique sans solution parfaite.
Surveiller et identifier l’activité des robots
Comprendre quels robots accèdent à votre site et à quelle fréquence est essentiel pour optimiser votre stratégie de contenu. L’analyse des fichiers logs est la méthode principale pour identifier l’activité des robots, vous permettant de segmenter et d’analyser les logs du serveur afin de voir quels bots accèdent à votre site, à quelle fréquence et sur quelles pages ils se concentrent. En examinant les chaînes User-Agent dans vos logs serveur, vous pouvez distinguer Googlebot, GPTBot, OAI-SearchBot et d’autres robots, révélant leurs schémas de comportement. Les métriques clés à suivre incluent la fréquence de crawl (fréquence des visites de chaque robot), la profondeur de crawl (combien de niveaux de votre structure de site sont explorés), et le budget de crawl (nombre total de pages crawlé sur une période donnée). Des outils comme Google Search Console et Bing Webmaster Tools fournissent des informations sur l’activité des robots d’indexation, tandis que des solutions spécialisées comme AmICited.com offrent un suivi complet du comportement des robots IA sur plusieurs plateformes, y compris ChatGPT, Perplexity et Google AI Overviews. AmICited.com suit spécifiquement la façon dont les systèmes IA référencent votre marque et contenu, offrant de la visibilité sur les plateformes IA qui vous citent et à quelle fréquence. Comprendre ces schémas vous aide à identifier rapidement les problèmes techniques, à optimiser l’allocation du budget de crawl, et à prendre des décisions éclairées concernant l’accès des robots et l’optimisation du contenu.
Stratégies d’optimisation pour les robots d’indexation
L’optimisation pour les robots d’indexation traditionnels repose sur les fondamentaux du SEO technique pour garantir la découvrabilité et l’indexabilité de votre contenu. Les stratégies suivantes restent essentielles pour maintenir une forte visibilité en recherche :
Améliorez la crawlabilité en créant des structures de liens internes claires, en éliminant les liens brisés et en évitant les pages orphelines inaccessibles aux robots
Soumettez des sitemaps XML aux moteurs de recherche pour guider les robots vers vos contenus les plus importants et garantir une indexation complète
Mettez en œuvre des données structurées avec le balisage schema pour aider les moteurs à mieux comprendre le contexte et la signification de votre contenu
Optimisez la vitesse des pages afin que les robots puissent parcourir efficacement votre site sans dépasser les délais ou ignorer des pages
Priorisez le contenu important dans l’architecture du site afin que les robots crawlers rencontrent d’abord vos pages les plus précieuses
Utilisez le robots.txt de manière stratégique pour bloquer les pages à faible valeur et préserver le budget de crawl pour le contenu prioritaire
Maintenez un contenu frais et de haute qualité pour signaler aux robots que votre site est actif et mérite des visites fréquentes
Les moteurs de recherche comme Google se concentrent de plus en plus sur l’efficacité du crawl, avec des représentants indiquant que Googlebot crawlera moins à l’avenir. Votre site doit donc être aussi épuré et compréhensible que possible, avec des hiérarchies claires et un maillage interne efficace pour guider les robots vers vos pages les plus stratégiques.
Stratégies d’optimisation pour les robots d’entraînement IA
L’optimisation pour les robots d’entraînement IA nécessite une autre approche, axée sur la qualité, la clarté et l’accessibilité du contenu plutôt que sur les signaux de classement. Les robots IA privilégient un contenu bien structuré et contextuellement riche, votre stratégie doit donc miser sur la complétude et la lisibilité. Évitez que le contenu critique dépende du JavaScript — assurez-vous que les détails produits, prix, avis et données clés figurent dans le HTML brut. Créez des contenus complets et approfondis couvrant les sujets en détail et fournissant du contexte utile aux modèles IA. Utilisez un formatage clair avec titres, listes à puces ou numérotées pour segmenter le texte et faciliter l’analyse. Rédigez clairement en utilisant un langage simple, sans jargon excessif susceptible de perturber les modèles IA. Implémentez une hiérarchie de titres appropriée (H1, H2, H3) pour aider les robots à comprendre la structure et les relations du contenu. Ajoutez des métadonnées et du balisage schema pertinents afin de contextualiser votre contenu. Assurez-vous d’une rapidité de chargement élevée, car les robots IA disposent de timeouts serrés (1-5 secondes) et peuvent ignorer les pages trop lentes.
La grande différence par rapport à l’optimisation pour la recherche est que les robots IA ne tiennent pas compte des signaux de classement, backlinks ou densité de mots-clés. Ils valorisent un contenu clair, bien organisé et riche en informations. Une page qui ne serait pas bien classée sur Google peut s’avérer très utile pour les modèles IA si elle contient des informations complètes et bien structurées sur un sujet.
L’avenir de la gestion des robots
Le paysage du crawl web évolue rapidement, les robots IA devenant de plus en plus importants pour la visibilité des contenus et la notoriété des marques. À mesure que des outils de recherche alimentés par l’IA comme ChatGPT, Perplexity et Google AI Overviews gagnent en popularité, être découvert et cité par ces systèmes sera aussi crucial que les classements traditionnels. La distinction entre robots d’entraînement et robots d’indexation va probablement s’affiner, avec des entreprises offrant une séparation plus nette entre la collecte de données et la recherche, à l’image de l’approche d’OpenAI avec GPTBot et OAI-SearchBot. Les éditeurs devront développer des stratégies conciliant optimisation SEO classique et visibilité IA, en reconnaissant que ces objectifs sont complémentaires et non concurrents. L’émergence d’outils de monitoring spécialisés facilitera le suivi de l’activité des robots sur les plateformes traditionnelles et IA, permettant des décisions data-driven sur l’accès des robots et l’optimisation du contenu. Les premiers à optimiser pour les deux types de robots bénéficieront d’un avantage compétitif, positionnant leur contenu pour être découvert via de multiples canaux à mesure que le paysage de la recherche évolue. L’avenir de la visibilité des contenus dépend de la compréhension et de l’optimisation pour l’ensemble du spectre des robots qui découvrent et utilisent vos contenus.
Questions fréquemment posées
Quelle est la principale différence entre les robots d’indexation et les robots d’entraînement IA ?
Les robots d’indexation comme Googlebot indexent le contenu pour le classement dans les moteurs de recherche et peuvent exécuter JavaScript pour voir le contenu dynamique. Les robots d’entraînement IA comme GPTBot collectent des données pour entraîner des LLM et ne peuvent généralement pas exécuter JavaScript, ce qui les empêche de voir le contenu chargé dynamiquement. Cette différence fondamentale signifie que votre site peut être bien classé sur Google tout en étant presque invisible pour ChatGPT.
Puis-je bloquer les robots d’entraînement IA sans affecter mon référencement ?
Oui, vous pouvez utiliser le fichier robots.txt pour bloquer certains robots IA comme GPTBot tout en autorisant les robots d’indexation. Cependant, cela peut réduire votre visibilité dans les réponses et résumés générés par l’IA. Le choix stratégique dépend de la priorité que vous accordez à la protection du contenu par rapport au trafic potentiel provenant de l’IA.
Pourquoi les robots IA ne voient-ils pas mon contenu JavaScript ?
Les robots IA comme GPTBot n’analysent que le HTML brut lors du chargement initial de la page et n’exécutent pas JavaScript. Le contenu chargé dynamiquement par des scripts — comme les détails produits, avis ou images — leur reste totalement invisible. C’est une limitation majeure pour les sites modernes reposant sur le rendu côté client.
À quelle fréquence les robots d’entraînement IA visitent-ils mon site web ?
Les robots d’entraînement IA visitent généralement moins fréquemment que les robots d’indexation, avec des intervalles plus longs entre chaque visite. Ils privilégient le contenu à forte autorité et peuvent ne crawler une page qu’une fois toutes les quelques semaines ou mois. Ce schéma de crawl peu fréquent reflète leur focalisation sur la qualité plutôt que la quantité.
Quel contenu risque le plus d’être invisible aux robots IA ?
Les détails produits, avis clients, images chargées paresseusement, éléments interactifs (onglets, carrousels, modales), informations tarifaires et tout contenu caché derrière du JavaScript sont les plus vulnérables. Pour les sites e-commerce et ceux basés sur SPA, cela peut représenter une part significative du contenu critique.
Comment optimiser mon site web à la fois pour les robots d’indexation et d’entraînement IA ?
Assurez-vous que les contenus clés sont présents dans le HTML brut, améliorez la vitesse du site, utilisez une structure et un formatage clairs avec une bonne hiérarchie de titres, implémentez le balisage schema et évitez que le contenu critique dépende de JavaScript. L’objectif est de rendre votre contenu accessible tant aux robots traditionnels qu’aux robots IA.
Quels outils peuvent m’aider à surveiller l’activité des robots sur mon site ?
Les outils d’analyse de logs, Google Search Console, Bing Webmaster Tools et des solutions spécialisées de suivi comme AmICited.com permettent de suivre le comportement des robots. AmICited.com surveille spécifiquement comment les systèmes d’IA référencent votre marque sur ChatGPT, Perplexity et Google AI Overviews.
Le blocage des robots IA nuit-il à mon trafic de référence IA ?
Potentiellement oui. Bloquer les robots d’entraînement peut protéger votre contenu, mais cela pourrait réduire votre visibilité dans les résultats et résumés alimentés par l’IA. De plus, le contenu déjà crawlé avant le blocage reste dans les modèles entraînés. La décision nécessite un équilibre entre la protection du contenu et la perte potentielle de découvertes via l’IA.
Surveillez l’activité des robots IA avec AmICited
Suivez comment les systèmes d’IA référencent votre marque sur ChatGPT, Perplexity et Google AI Overviews. Obtenez des informations en temps réel sur votre visibilité IA et optimisez votre stratégie de contenu.
PerplexityBot : Ce que chaque propriétaire de site web doit savoir
Guide complet sur le robot d'indexation PerplexityBot – comprenez son fonctionnement, gérez l'accès, surveillez les citations et optimisez la visibilité sur Per...
Découvrez PerplexityBot, le robot d’indexation web de Perplexity qui indexe le contenu pour son moteur de réponses IA. Comprenez son fonctionnement, sa conformi...
Découvrez ce qu’est GPTBot, son fonctionnement et s’il faut le bloquer sur votre site web. Comprenez l’impact sur le SEO, la charge serveur et la visibilité de ...
12 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.