
Le guide complet pour bloquer (ou autoriser) les crawlers IA
Apprenez à bloquer ou autoriser les crawlers IA comme GPTBot et ClaudeBot grâce à robots.txt, au blocage serveur et à des méthodes de protection avancées. Guide...
8 min de lecture
Découvrez comment mettre en œuvre un blocage sélectif des crawlers IA pour protéger votre contenu des bots d’entraînement tout en maintenant votre visibilité dans les résultats de recherche IA. Stratégies techniques pour les éditeurs.
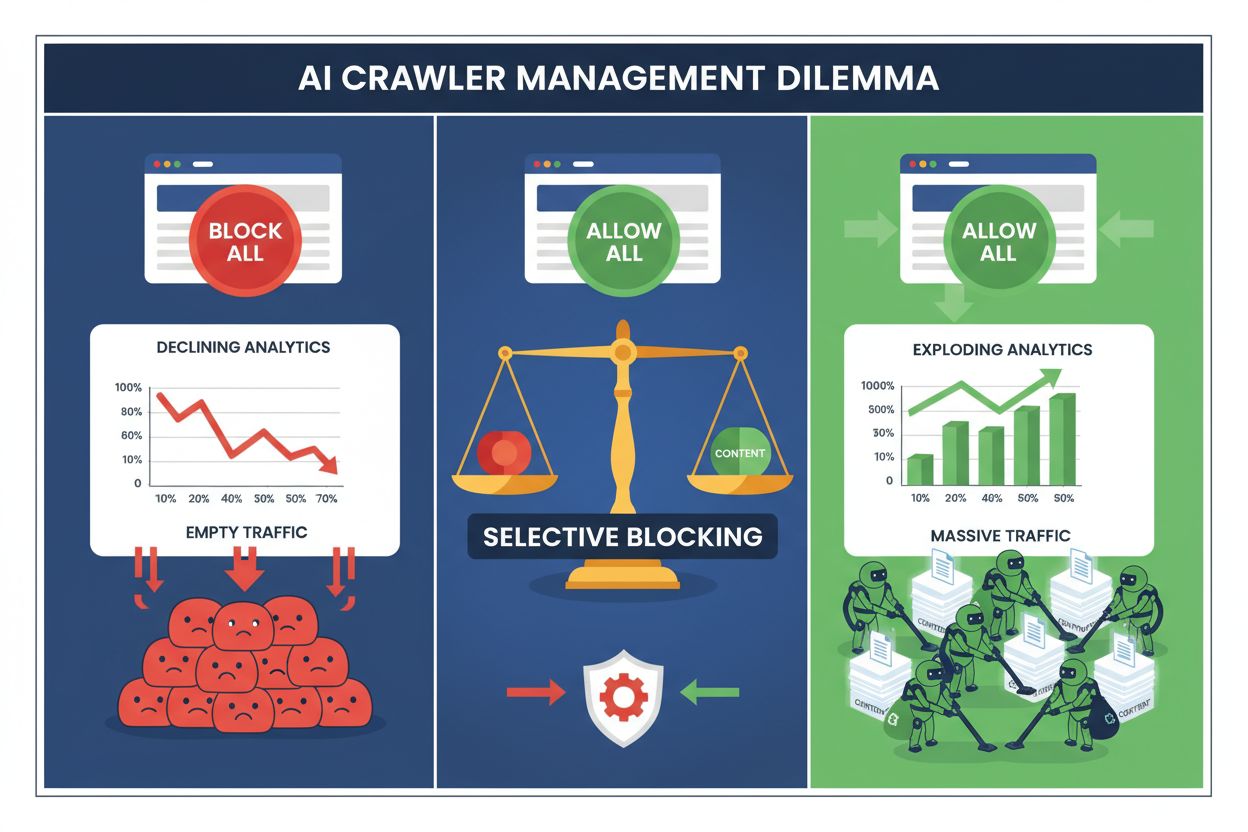
Les éditeurs font aujourd’hui face à un choix impossible : bloquer tous les crawlers IA et perdre un trafic précieux provenant des moteurs de recherche, ou les autoriser tous et voir leur contenu alimenter des ensembles de données d’entraînement sans compensation. L’essor de l’IA générative a créé un écosystème de crawlers scindé, où les mêmes règles robots.txt s’appliquent indistinctement aussi bien aux moteurs de recherche générateurs de revenus qu’aux crawlers d’entraînement qui extraient de la valeur. Ce paradoxe a poussé les éditeurs les plus avisés à développer des stratégies de contrôle sélectif, distinguant les différents types de bots IA en fonction de leur impact réel sur les métriques business.
Le paysage des crawlers IA se divise en deux grandes catégories aux finalités et impacts business très différents. Les crawlers d’entraînement—opérés par des entreprises comme OpenAI, Anthropic et Google—sont conçus pour ingérer d’énormes volumes de texte afin de construire et améliorer des modèles de langage, tandis que les crawlers de recherche indexent le contenu pour la découverte et la récupération d’informations. Les bots d’entraînement représentent environ 80 % de toute l’activité bot liée à l’IA, mais ne génèrent aucun revenu direct pour les éditeurs, alors que les crawlers de recherche comme Googlebot et Bingbot apportent chaque année des millions de visites et d’impressions publicitaires. La distinction est cruciale, car un seul crawler d’entraînement peut consommer une bande passante équivalente à celle de milliers d’utilisateurs humains, tandis que les crawlers de recherche sont optimisés pour l’efficacité et respectent généralement les limites de débit.
| Nom du bot | Opérateur | Objectif principal | Potentiel de trafic |
|---|---|---|---|
| GPTBot | OpenAI | Entraînement de modèle | Aucun (extraction de données) |
| Claude Web Crawler | Anthropic | Entraînement de modèle | Aucun (extraction de données) |
| Googlebot | Indexation de recherche | 243,8 M visites (avril 2025) | |
| Bingbot | Microsoft | Indexation de recherche | 45,2 M visites (avril 2025) |
| Perplexity Bot | Perplexity AI | Recherche + entraînement | 12,1 M visites (avril 2025) |
Les chiffres sont éloquents : le crawler de ChatGPT à lui seul a envoyé 243,8 millions de visites aux éditeurs en avril 2025, mais ces visites ont généré zéro clic, zéro impression publicitaire et zéro revenu. Pendant ce temps, le trafic généré par Googlebot se traduit en engagement utilisateur réel et opportunités de monétisation. Comprendre cette distinction est la première étape vers la mise en place d’une stratégie de blocage sélectif qui protège votre contenu tout en préservant votre visibilité dans la recherche.
Le blocage systématique de tous les crawlers IA est économiquement autodestructeur pour la plupart des éditeurs. Tandis que les crawlers d’entraînement extraient de la valeur sans compensation, les crawlers de recherche restent l’une des sources de trafic les plus fiables dans un paysage numérique de plus en plus fragmenté. L’argument financier du blocage sélectif repose sur plusieurs facteurs clés :
Les éditeurs ayant mis en place des stratégies de blocage sélectif maintiennent ou améliorent leur trafic de recherche tout en réduisant jusqu’à 85 % l’extraction non autorisée de contenu. Cette approche stratégique reconnaît que tous les crawlers IA ne se valent pas et qu’une politique nuancée sert bien mieux les intérêts business qu’une approche radicale.
Le fichier robots.txt demeure le principal mécanisme de communication des permissions de crawl, et il s’avère étonnamment efficace pour distinguer les différents types de bots lorsqu’il est bien configuré. Ce simple fichier texte, placé à la racine de votre site, utilise des directives user-agent pour spécifier quels crawlers peuvent accéder à quel contenu. Pour un contrôle sélectif des crawlers IA, vous pouvez autoriser les moteurs de recherche tout en bloquant les crawlers d’entraînement de façon chirurgicale.
Voici un exemple concret qui bloque les crawlers d’entraînement tout en autorisant les moteurs de recherche :
# Bloquer GPTBot d’OpenAI
User-agent: GPTBot
Disallow: /
# Bloquer le crawler Claude d’Anthropic
User-agent: Claude-Web
Disallow: /
# Bloquer d’autres crawlers d’entraînement
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# Autoriser les moteurs de recherche
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
Cette méthode fournit des instructions claires aux crawlers respectueux tout en maintenant la découvrabilité de votre site dans les résultats de recherche. Cependant, robots.txt reste une norme volontaire—il repose sur la bonne volonté des opérateurs de crawlers. Pour les éditeurs soucieux de la conformité, des couches d’application supplémentaires s’imposent.
Robots.txt seul ne garantit pas la conformité, car environ 13 % des crawlers IA ignorent complètement les directives, par négligence ou contournement délibéré. L’application au niveau serveur via votre serveur web ou la couche applicative fournit un garde-fou technique qui empêche tout accès non autorisé, quel que soit le comportement du crawler. Cette approche bloque les requêtes au niveau HTTP avant qu’elles ne consomment trop de bande passante ou de ressources.
Mettre en place un blocage serveur avec Nginx est simple et très efficace :
# Dans votre bloc serveur Nginx
location / {
# Bloquer les crawlers d’entraînement au niveau serveur
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# Bloquer par plages IP si nécessaire (pour les crawlers qui falsifient leur user agent)
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# Traitement normal des requêtes
proxy_pass http://backend;
}
Cette configuration retourne une réponse 403 Forbidden aux crawlers bloqués, consommant un minimum de ressources serveur tout en indiquant clairement que l’accès est refusé. Combinée au robots.txt, l’application au niveau serveur crée une défense à deux niveaux qui cible à la fois les crawlers conformes et non conformes. Le taux de contournement de 13 % chute pratiquement à zéro lorsque les règles serveur sont correctement appliquées.
Les Content Delivery Networks et les Web Application Firewalls offrent une couche d’application supplémentaire qui intervient avant que les requêtes n’atteignent vos serveurs d’origine. Des services comme Cloudflare, Akamai ou AWS WAF permettent de créer des règles qui bloquent certains user agents ou plages IP en périphérie, empêchant ainsi les crawlers malveillants ou indésirables de consommer vos ressources. Ces services maintiennent des listes à jour d’IP et de user agents connus des crawlers d’entraînement, les bloquant automatiquement sans configuration manuelle.
Les contrôles CDN présentent plusieurs avantages sur l’application serveur : ils diminuent la charge sur le serveur d’origine, proposent des capacités de blocage géographique et offrent des analyses en temps réel sur les requêtes bloquées. De nombreux fournisseurs CDN proposent désormais des règles de blocage IA en standard, conscients des inquiétudes des éditeurs face à l’extraction non autorisée de données. Pour les éditeurs utilisant Cloudflare, activer l’option « Bloquer les crawlers IA » dans les paramètres de sécurité permet de se prémunir d’un simple clic contre les principaux crawlers d’entraînement tout en préservant l’accès des moteurs de recherche.
Un blocage sélectif efficace nécessite une approche méthodique de classification des crawlers selon leur impact business et leur fiabilité. Plutôt que de traiter tous les crawlers IA de la même façon, les éditeurs doivent appliquer un cadre à trois niveaux, reflétant la valeur réelle et le risque de chaque crawler. Ce cadre autorise des décisions nuancées, équilibrant protection du contenu et opportunités business.
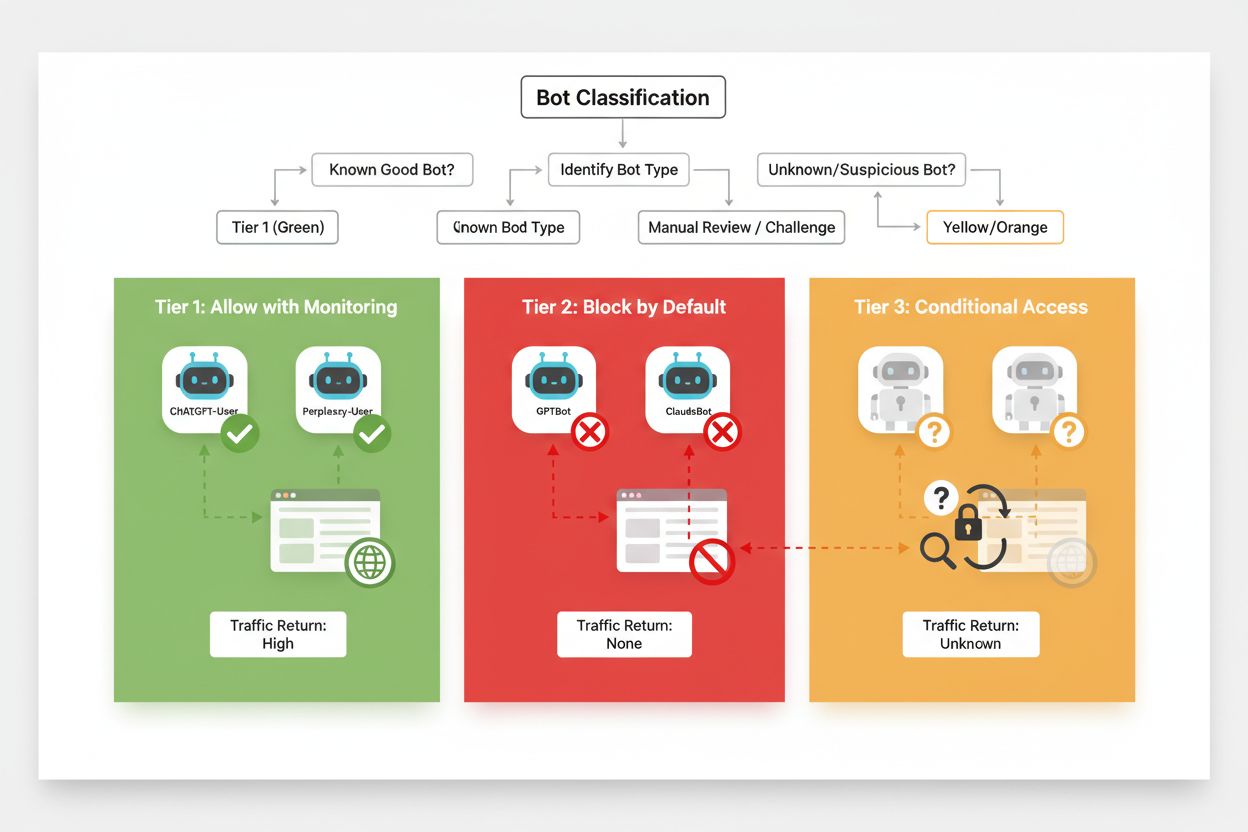
| Niveau | Classification | Exemples | Action |
|---|---|---|---|
| Niveau 1 : Générateurs de revenus | Moteurs de recherche et sources de référence à fort trafic | Googlebot, Bingbot, Perplexity Bot | Autoriser l’accès total ; optimiser la crawlabilité |
| Niveau 2 : Neutres/Non prouvés | Nouveaux crawlers au but incertain | Startups IA émergentes, bots de recherche | Surveiller étroitement ; autoriser avec limitation de débit |
| Niveau 3 : Extracteurs de valeur | Crawlers d’entraînement sans bénéfice direct | GPTBot, Claude-Web, CCBot | Bloquer totalement ; appliquer sur plusieurs couches |
La mise en œuvre de ce cadre exige une veille constante sur les nouveaux crawlers et leurs modèles économiques. Les éditeurs doivent auditer régulièrement leurs logs d’accès pour identifier de nouveaux bots, étudier les conditions d’utilisation et politiques de rémunération de leurs opérateurs, et ajuster leur classification en conséquence. Un crawler débutant en niveau 3 peut passer en niveau 2 si son opérateur propose un partage de revenus, tandis qu’un crawler autrefois fiable peut être rétrogradé en niveau 3 s’il viole les limites de débit ou robots.txt.
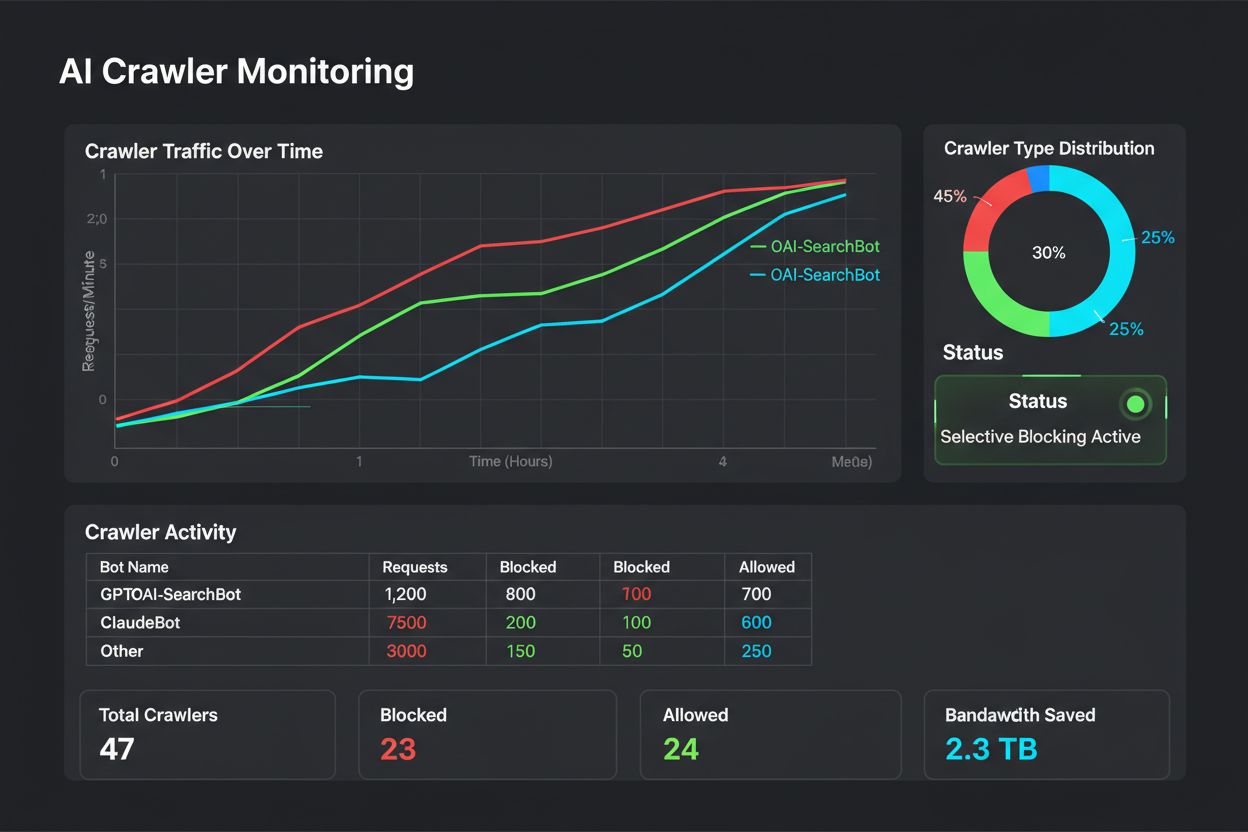
Le blocage sélectif n’est pas une configuration à oublier ensuite : il requiert une surveillance et des ajustements continus à mesure que l’écosystème évolue. Les éditeurs doivent mettre en place une journalisation et une analyse complètes pour suivre quels crawlers accèdent à leur contenu, la bande passante consommée et le respect des restrictions. Ces données guident les décisions stratégiques sur qui autoriser, bloquer ou limiter.
L’analyse des logs d’accès révèle les comportements des crawlers et éclaire vos ajustements :
# Identifier tous les crawlers IA accédant au site
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# Calculer la bande passante consommée par un crawler précis
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "Bande passante GPTBot : " sum/1024/1024 " MB"}'
# Surveiller les réponses 403 aux crawlers bloqués
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
Une analyse régulière de ces données—idéalement chaque semaine ou chaque mois—révèle si votre stratégie fonctionne, si de nouveaux crawlers sont apparus, et si les bots précédemment bloqués modifient leur comportement. Ces informations alimentent votre cadre de classification, assurant l’alignement de vos politiques sur les objectifs business et la réalité technique.
Les éditeurs qui mettent en œuvre un blocage sélectif commettent fréquemment des erreurs compromettant leur stratégie ou ayant des conséquences inattendues. Comprendre ces pièges vous aide à les éviter et à bâtir une politique plus efficace dès le début.
Tout bloquer sans discernement : L’erreur la plus fréquente consiste à utiliser des règles de blocage trop larges, qui excluent à la fois les moteurs de recherche et les crawlers d’entraînement, détruisant la visibilité dans la recherche sous prétexte de protéger le contenu.
Se fier uniquement à robots.txt : Supposer que robots.txt suffira à empêcher l’accès non autorisé néglige les 13 % de crawlers qui l’ignorent, exposant votre contenu à l’extraction.
Oublier de surveiller et d’ajuster : Appliquer une politique statique sans jamais la réviser fait manquer l’apparition de nouveaux crawlers, l’évolution des modèles économiques et peut conduire à bloquer des bots utiles.
Bloquer uniquement par user agent : Les crawlers sophistiqués falsifient ou font tourner leurs user agents, rendant le blocage inefficace sans règles complémentaires sur les IP et la limitation de débit.
Ignorer la limitation de débit : Même les crawlers autorisés peuvent consommer une bande passante excessive s’ils ne sont pas limités, dégradant l’expérience utilisateur et gaspillant vos ressources.
L’avenir des relations entre éditeurs et crawlers IA impliquera probablement des modèles de négociation et de compensation plus sophistiqués que le simple blocage. Cependant, en attendant l’apparition de standards industriels, le contrôle sélectif demeure l’approche la plus pragmatique pour protéger votre contenu tout en maintenant votre visibilité dans la recherche. Considérez votre stratégie de blocage comme une politique dynamique, évoluant avec l’écosystème, et réévaluez régulièrement quels crawlers méritent l’accès selon leur impact business et leur fiabilité.
Les éditeurs les plus performants sont ceux qui mettent en place des défenses en couches—en combinant directives robots.txt, application serveur, contrôles CDN et surveillance continue en une stratégie globale. Cette approche protège contre les crawlers conformes comme non conformes, tout en préservant le trafic moteur de recherche qui génère revenus et engagement utilisateur. À mesure que les sociétés d’IA reconnaissent la valeur du contenu éditeur et proposent des modèles de compensation ou de licence, le cadre que vous bâtissez aujourd’hui saura s’adapter aux nouveaux modèles économiques tout en gardant le contrôle de vos actifs numériques.
Les crawlers d'entraînement comme GPTBot et ClaudeBot collectent des données pour construire des modèles IA sans renvoyer de trafic vers votre site. Les crawlers de recherche comme OAI-SearchBot et PerplexityBot indexent le contenu pour les moteurs de recherche IA et peuvent générer un trafic de référence significatif vers votre site. Comprendre cette distinction est crucial pour mettre en œuvre une stratégie de blocage sélectif efficace.
Oui, c'est le principe fondamental du contrôle sélectif des crawlers. Vous pouvez utiliser robots.txt pour interdire les bots d'entraînement tout en autorisant les bots de recherche, puis appliquer des contrôles au niveau du serveur pour les bots qui ignorent robots.txt. Cette approche protège votre contenu contre l'entraînement non autorisé tout en maintenant la visibilité dans les résultats de recherche IA.
La plupart des grandes entreprises IA affirment respecter robots.txt, mais la conformité est volontaire. Les recherches montrent qu'environ 13 % des bots IA contournent complètement les directives de robots.txt. C'est pourquoi l'application au niveau serveur est essentielle pour les éditeurs qui souhaitent réellement protéger leur contenu contre les crawlers non conformes.
Important et en croissance. ChatGPT a envoyé 243,8 millions de visites à 250 sites d’actualités et médias en avril 2025, soit une hausse de 98 % par rapport à janvier. Bloquer ces crawlers signifie perdre cette source de trafic émergente. Pour de nombreux éditeurs, le trafic de recherche IA représente désormais 5 à 15 % du trafic de référence total.
Analysez régulièrement vos journaux serveur avec des commandes grep pour identifier les user agents des bots, suivre la fréquence de crawl et surveiller le respect de vos règles robots.txt. Examinez les logs au moins une fois par mois pour repérer de nouveaux bots, des comportements inhabituels et vérifier que les bots bloqués restent bien exclus. Ces données alimentent vos décisions stratégiques concernant votre politique de crawl.
Vous protégez votre contenu de l’entraînement non autorisé mais perdez en visibilité dans les résultats de recherche IA, manquez des sources de trafic émergentes et réduisez potentiellement les mentions de votre marque dans les réponses générées par l’IA. Les éditeurs qui mettent en place des blocages globaux constatent souvent une baisse de 40 à 60 % de leur visibilité dans la recherche et ratent des opportunités de découverte via les plateformes IA.
Au moins une fois par mois, car de nouveaux bots apparaissent constamment et les bots existants font évoluer leur comportement. Le paysage des crawlers IA change rapidement, avec de nouveaux opérateurs lançant des crawlers et des acteurs existants fusionnant ou renommant leurs bots. Des revues régulières garantissent que votre politique reste alignée sur les objectifs business et la réalité technique.
C’est le nombre de pages crawlées par rapport aux visiteurs renvoyés sur votre site. Anthropic crawl 38 000 pages pour chaque visiteur référé, OpenAI maintient un ratio de 1 091:1, et Perplexity est à 194:1. Des ratios faibles indiquent une meilleure valeur à laisser accéder le crawler. Cette métrique vous aide à décider quels crawlers méritent l’accès selon leur impact réel sur votre activité.
AmICited suit quelles plateformes IA citent votre marque et votre contenu. Obtenez des informations sur votre visibilité IA et assurez une attribution correcte sur ChatGPT, Perplexity, Google AI Overviews, et plus encore.
Apprenez à bloquer ou autoriser les crawlers IA comme GPTBot et ClaudeBot grâce à robots.txt, au blocage serveur et à des méthodes de protection avancées. Guide...

Découvrez comment les pare-feux applicatifs web offrent un contrôle avancé sur les crawlers IA au-delà du robots.txt. Mettez en place des règles WAF pour protég...

Discussion communautaire sur l'autorisation des bots IA à explorer votre site. Retours d'expérience sur la configuration de robots.txt, la mise en place de llms...