URL canoniques et IA : prévenir les problèmes de contenu dupliqué
Découvrez comment les URLs canoniques préviennent les problèmes de contenu dupliqué dans les systèmes de recherche IA. Découvrez les meilleures pratiques pour implémenter les canoniques afin d’améliorer la visibilité dans l’IA et garantir la bonne attribution de votre contenu.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
Comment les systèmes IA gèrent le contenu dupliqué
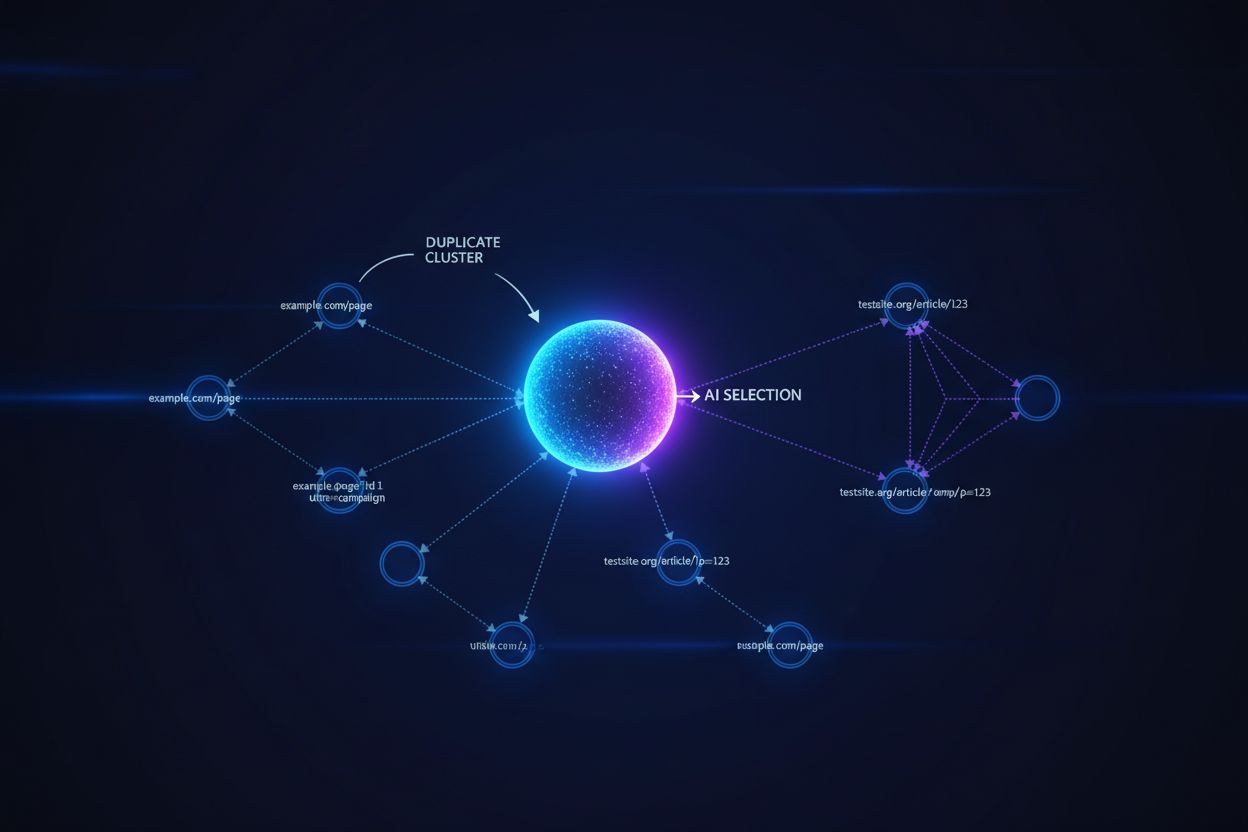
Les grands modèles de langage et les systèmes de recherche IA utilisent des algorithmes de regroupement sophistiqués pour identifier et regrouper les URLs quasi-identiques, traitant plusieurs versions d’un même contenu comme une seule entité pour le classement et la citation. Lorsque les systèmes IA rencontrent du contenu dupliqué, ils doivent choisir quelle version prioriser—une décision qui a un impact direct sur l’URL qui recevra visibilité, signaux d’autorité et attribution de l’utilisateur. Le problème critique apparaît lorsque l’IA sélectionne la mauvaise version : si votre URL canonique pointe vers la page préférée mais que le système IA regroupe et classe à la place un doublon de moindre qualité, votre contenu perd en visibilité et en crédit de citation. Les signaux d’intention se diluent entre les versions dupliquées, fragmentant l’autorité qui devrait se concentrer sur une seule URL et provoquant un affaiblissement du classement pour chaque doublon comparé à une autorité unifiée sur la version canonique.
Pourquoi les URLs canoniques sont importantes pour la visibilité dans l’IA
Les balises canoniques servent de signaux explicites aux systèmes IA pour indiquer quelle version du contenu dupliqué doit être considérée comme faisant autorité, influençant directement la présence de votre URL préférée dans les réponses générées par l’IA et la bonne attribution. Sans balises canoniques, les systèmes IA prennent leurs propres décisions de regroupement sur la base de la similarité du contenu, des liens et de la fraîcheur—ce qui conduit souvent à la sélection de la mauvaise version comme source canonique. En cas de contenu dupliqué sans implémentation correcte des canoniques, les réponses IA peuvent citer une version syndiquée, une copie en cache ou une variante de moindre qualité plutôt que votre contenu original, fragmentant ainsi votre visibilité sur plusieurs URLs. Les URLs canoniques garantissent que, lorsque des systèmes IA rencontrent votre contenu sur différents domaines, paramètres ou versions, ils comprennent quelle URL unique doit recevoir le crédit et être mise en avant dans les réponses.
Scénario
Sans canonique
Avec canonique
Impact sur l’IA
L’IA regroupe les doublons indépendamment ; peut sélectionner la mauvaise version pour le classement
L’IA reconnaît une source faisant autorité unique ; consolide tous les signaux vers l’URL canonique
Crédit de citation
Attribution dispersée sur plusieurs URLs ; autorité par URL affaiblie
Toutes les citations et l’autorité vont à l’URL canonique ; meilleure visibilité
Résultat
Le contenu apparaît dans les réponses IA mais la mauvaise URL reçoit le crédit ; visibilité fragmentée
L’URL préférée apparaît dans les réponses IA avec des signaux d’autorité consolidés
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
URLs canoniques vs. redirections : quand utiliser chaque méthode
Les balises canoniques et les redirections ont des fonctions différentes dans la gestion du contenu dupliqué pour les systèmes IA : les balises canoniques indiquent aux moteurs de recherche et aux systèmes IA quelle version est préférée tout en gardant les deux URLs accessibles, tandis que les redirections redirigent définitivement les utilisateurs et crawlers d’une URL à une autre. Les redirections (301 pour un déplacement permanent, 302 pour temporaire) sont des signaux plus forts car elles consolident toute l’autorité sur une seule URL et éliminent complètement le doublon du web, ce qui les rend idéales lorsque vous retirez définitivement une URL ou consolidez des domaines. Les balises canoniques sont préférables lorsque vous devez conserver plusieurs URLs pour des raisons commerciales—comme le suivi analytique, la préservation d’anciennes URLs pour les favoris utilisateurs, ou la diffusion de versions différentes à des audiences spécifiques—tout en signalant aux systèmes IA quelle version fait autorité. Utilisez des redirections lors de la consolidation de domaines après une migration, de la suppression de versions obsolètes ou de l’élimination de variations de paramètres sans utilité distincte. Utilisez des balises canoniques si vous devez maintenir plusieurs URLs mais souhaitez éviter les pénalités pour contenu dupliqué et garantir que les systèmes IA comprennent votre version préférée.
Principales différences entre canoniques et redirections :
Expérience utilisateur : Les redirections dirigent les utilisateurs vers une seule URL ; les canoniques laissent l’utilisateur sur l’URL d’origine tout en signalant la préférence aux systèmes IA
Consolidation de l’autorité : Les redirections consolident totalement l’autorité sur une URL ; les canoniques distribuent l’autorité mais signalent la préférence
Efficacité du crawl : Les redirections réduisent le gaspillage de crawl en éliminant le crawl des doublons ; les canoniques nécessitent encore le crawl des deux versions
Complexité d’implémentation : Les canoniques requièrent une implémentation HTML/en-tête ; les redirections nécessitent une configuration serveur
Réversibilité : Les canoniques sont faciles à modifier ; les redirections sont permanentes et plus difficiles à inverser sans impacter l’expérience utilisateur
Problèmes courants de contenu dupliqué en recherche IA
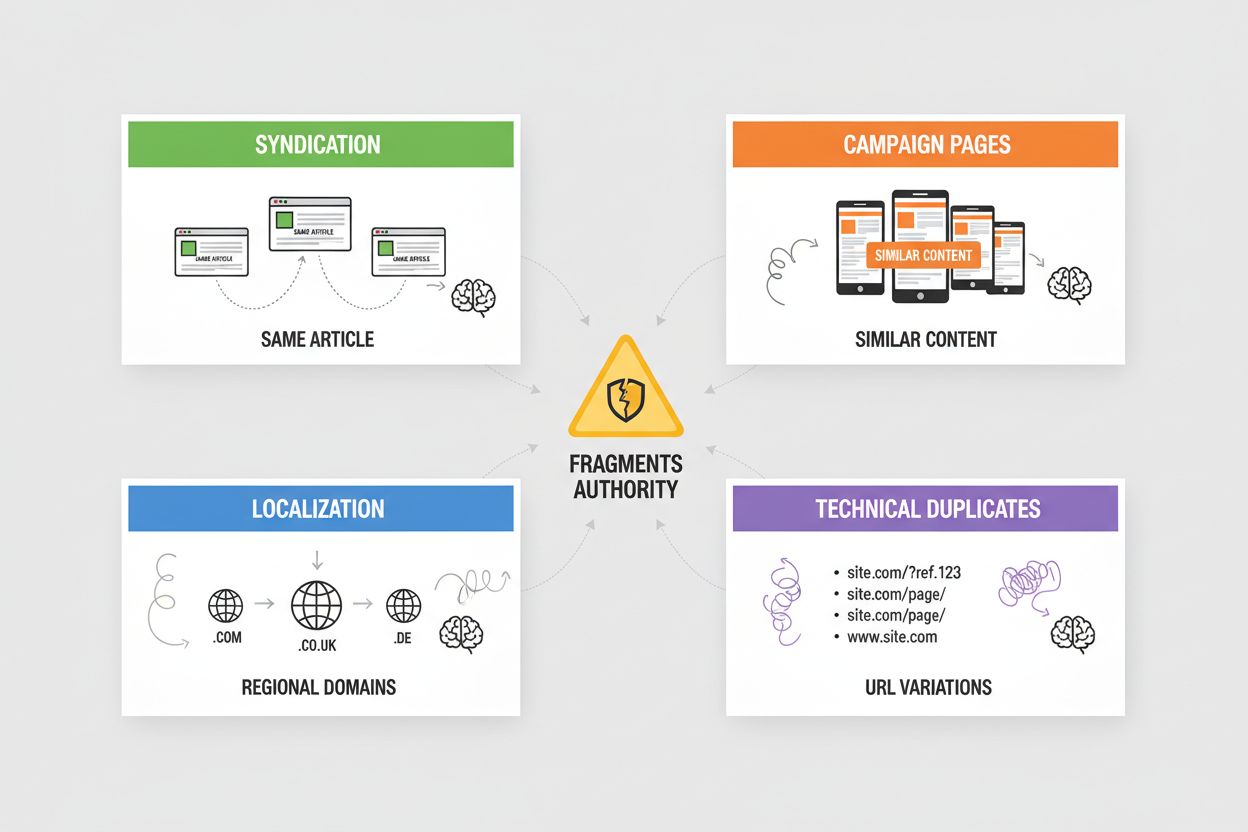
La syndication crée un contenu dupliqué massif lorsque vos articles sont republiés sur des sites partenaires, agrégateurs d’actualités ou réseaux de contenu—les systèmes IA doivent déterminer s’il faut créditer la source originale ou la version syndiquée, choisissant souvent celle qui apparaît en premier lors de leur crawl. Les pages de campagne créent des doublons lorsque vous générez plusieurs pages d’atterrissage avec un contenu identique ou quasi-identique pour différents canaux marketing, paramètres UTM ou tests A/B, ce qui conduit les systèmes IA à fragmenter l’autorité entre des variations qui devraient être consolidées. La localisation et l’internationalisation génèrent des doublons lorsque vous proposez un contenu similaire sur des domaines régionaux (exemple.com, exemple.co.uk, exemple.de) ou des versions linguistiques, nécessitant des balises hreflang et une implémentation canonique pour éviter que les systèmes IA considèrent ces variations comme des doublons plutôt que des contenus intentionnellement distincts. Les doublons techniques proviennent des identifiants de session, paramètres de suivi, versions imprimables et variations d’URL (www vs non-www, http vs https, slash final), créant plusieurs URLs pointant vers un même contenu—les systèmes IA voient cela comme des doublons et doivent décider quelle version prioriser. Chacun de ces scénarios dilue l’autorité qui devrait se concentrer sur votre URL préférée, réduisant votre visibilité dans les réponses IA et dispersant le crédit de citation sur plusieurs versions.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Bonnes pratiques pour l’implémentation des URLs canoniques
Utilisez toujours des URLs absolues dans vos balises canoniques plutôt que des URLs relatives, afin que les systèmes IA et moteurs de recherche puissent identifier sans ambiguïté l’URL cible, peu importe où la balise apparaît. Ajoutez des canoniques auto-référencées sur vos pages préférées—même les pages sans doublons doivent se référencer elles-mêmes en canonique, pour éviter que les systèmes IA n’infèrent des canoniques sur la base des liens ou de la similarité du contenu. Placez les balises canoniques dans la section <head> de votre document HTML, et pour les contenus non-HTML (PDF, images), implémentez les canoniques via les en-têtes HTTP pour que les crawlers IA reconnaissent votre préférence quel que soit le type de contenu.
<!-- Implémentation canonique correcte dans le head HTML --><linkrel="canonical"href="https://example.com/article/canonical-urls-ai" />
Incluez les URLs canoniques dans vos sitemaps XML pour renforcer les versions faisant autorité, et associez les canoniques à des balises hreflang lors de la gestion de contenu international ou localisé afin d’éviter que les systèmes IA ne considèrent les variations régionales comme des doublons. Évitez les erreurs courantes : ne créez jamais de chaînes canoniques (A→B→C), ne pointez jamais des canoniques vers des pages en noindex, et n’utilisez jamais les canoniques pour manipuler le classement en pointant vers un contenu non pertinent. Surveillez votre implémentation canonique avec des outils comme Google Search Console, Bing Webmaster Tools et AmICited.com pour vérifier que les systèmes IA reconnaissent vos URLs préférées et attribuent correctement le contenu.
<!-- Implémentation correcte avec hreflang pour le contenu international --><linkrel="canonical"href="https://example.com/article/canonical-urls-ai" />
<linkrel="alternate"hreflang="en-GB"href="https://example.co.uk/article/canonical-urls-ai" />
<linkrel="alternate"hreflang="de"href="https://example.de/artikel/canonical-urls-ai" />
Surveiller et corriger les problèmes de canoniques
Auditez vos URLs canoniques en crawlant l’ensemble de votre site avec des outils comme Screaming Frog, SEMrush ou Ahrefs pour identifier les pages sans canoniques, les chaînes canoniques cassées ou les canoniques pointant vers des pages en noindex—ces problèmes empêchent les systèmes IA de consolider correctement l’autorité. Utilisez le rapport Couverture de Google Search Console pour repérer les pages ayant des problèmes de contenu dupliqué et vérifier que Google reconnaît vos préférences canoniques, puis croisez avec Bing Webmaster Tools pour garantir la cohérence sur les systèmes de recherche IA. Implémentez IndexNow pour notifier immédiatement les moteurs de recherche et crawlers IA lors de l’ajout, la mise à jour ou la suppression de balises canoniques, accélérant la prise en compte de vos préférences au lieu d’attendre les cycles de crawl naturels. Surveillez les citations IA avec des outils comme AmICited.com et des recherches manuelles dans ChatGPT, Claude et Perplexity afin de vérifier que vos URLs préférées reçoivent bien l’attribution dans les réponses IA—si des doublons sont cités à la place, revoyez votre implémentation canonique et assurez-vous que les balises sont correctement formatées et placées. Auditez régulièrement pour détecter de nouveaux contenus dupliqués issus de partenariats de syndication, de lancements de campagne ou de changements techniques, et implémentez les canoniques de façon proactive pour maintenir une visibilité IA constante.
Questions fréquemment posées
Qu'est-ce qu'une URL canonique et pourquoi est-ce important pour la recherche IA ?
Une URL canonique est la version préférée d'une page que vous souhaitez que les moteurs de recherche et les systèmes IA reconnaissent comme faisant autorité. C'est important pour la recherche IA car les LLM regroupent les URLs quasi-identiques et sélectionnent une version pour représenter l'ensemble. Sans une implémentation correcte de la canonique, les systèmes IA peuvent citer la mauvaise version de votre contenu, fragmentant votre visibilité et attribution sur plusieurs URLs.
Comment les systèmes IA gèrent-ils le contenu dupliqué différemment des moteurs de recherche traditionnels ?
Les systèmes IA utilisent des algorithmes de regroupement pour rassembler les URLs quasi-identiques en entités uniques, puis sélectionnent une version pour représenter tout le groupe. Cela diffère des moteurs de recherche traditionnels car les réponses IA nécessitent une seule URL source pour l'attribution. Si votre canonique n'est pas correctement implémentée, l'IA peut sélectionner une version syndiquée, une copie en cache ou une variante de moindre qualité à la place de votre URL préférée.
Dois-je utiliser des balises canoniques ou des redirections pour gérer le contenu dupliqué ?
Utilisez les balises canoniques lorsque vous devez conserver plusieurs URLs pour des raisons commerciales (paramètres de suivi, URLs anciennes, audiences différentes) tout en signalant votre préférence aux systèmes IA. Utilisez des redirections lorsque vous retirez définitivement une URL, consolidez des domaines ou éliminez des variations de paramètres qui n'ont pas d'utilité. Les redirections sont des signaux plus forts car elles consolident totalement l'autorité, tandis que les canoniques distribuent l'autorité mais signalent la préférence.
Quels sont les problèmes de contenu dupliqué les plus courants qui nuisent à la visibilité dans l'IA ?
Les problèmes les plus courants sont : la syndication (articles republiés sur des sites partenaires), les pages de campagne (multiples pages d'atterrissage avec un contenu identique), la localisation (contenu similaire sur des domaines régionaux), et les doublons techniques (paramètres d'URL, identifiants de session, slashs finaux). Chacun de ces cas fragmente l'autorité entre plusieurs URLs, réduisant la visibilité dans les réponses générées par l'IA.
Comment implémenter correctement les URLs canoniques ?
Utilisez toujours des URLs absolues (https://exemple.com/page, pas /page), placez les balises canoniques dans la section head du HTML, incluez des canoniques auto-référencées sur toutes les pages, et évitez les chaînes canoniques (A→B→C). Pour les contenus non-HTML comme les PDF, utilisez les en-têtes HTTP. Ajoutez les canoniques dans votre sitemap XML et associez-les à des balises hreflang pour le contenu international.
Comment vérifier que les systèmes IA reconnaissent mes URLs canoniques ?
Utilisez Google Search Console et Bing Webmaster Tools pour vérifier la reconnaissance des canoniques, surveillez les citations IA via AmICited.com et des recherches manuelles dans ChatGPT/Claude/Perplexity, et auditez votre site avec des outils comme Screaming Frog ou SEMrush. Si des doublons sont cités à la place de votre canonique, revoyez votre implémentation et assurez-vous que les balises sont correctement formatées et placées dans le head du HTML.
Qu'est-ce que IndexNow et comment cela aide-t-il pour l'implémentation des URLs canoniques ?
IndexNow est un protocole qui notifie immédiatement les moteurs de recherche et les crawlers IA lorsque vous ajoutez, mettez à jour ou supprimez des balises canoniques, plutôt que d'attendre les cycles de crawl naturels. Cela accélère la prise en compte de vos préférences canoniques et aide à ce que les systèmes IA reconnaissent plus rapidement vos URLs préférées, réduisant le temps d'apparition des doublons dans les réponses IA.
Les systèmes IA peuvent-ils ignorer mes balises canoniques ?
Oui, les balises canoniques sont de forts signaux mais pas des directives. Les systèmes IA peuvent ignorer votre préférence canonique s'ils estiment qu'une autre version est plus autoritaire selon la qualité du contenu, les liens, la fraîcheur ou d'autres signaux. C'est pourquoi une implémentation correcte combinée à des signaux d'autorité et de qualité est essentielle—cela augmente la probabilité que les systèmes IA respectent votre préférence canonique.
Surveillez vos citations IA avec AmICited
Suivez comment des systèmes IA comme ChatGPT, Claude et Perplexity citent votre contenu. Assurez-vous que vos URLs canoniques sont correctement reconnues et que votre marque reçoit la bonne attribution dans les réponses générées par l'IA.
Comment gérer le contenu dupliqué pour les moteurs de recherche IA
Découvrez comment gérer et prévenir le contenu dupliqué lors de l’utilisation d’outils IA. Découvrez les balises canoniques, les redirections, les outils de dét...
Comment les moteurs de recherche IA gèrent-ils le contenu dupliqué ? Est-ce différent de Google ?
Discussion communautaire sur la manière dont les systèmes d'IA traitent le contenu dupliqué différemment des moteurs de recherche traditionnels. Les professionn...
Le contenu dupliqué est un contenu identique ou similaire sur plusieurs URLs qui perturbe les moteurs de recherche et dilue l’autorité de classement. Découvrez ...
13 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.