Sources de citation de ChatGPT : D'où ChatGPT tire-t-il ses informations ?
Découvrez d’où ChatGPT tire ses données d’entraînement, comment il cite ses sources, les dates de coupure de connaissance, et pourquoi surveiller les citations de l’IA est crucial pour votre marque.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
Comprendre les sources de données d’entraînement de ChatGPT
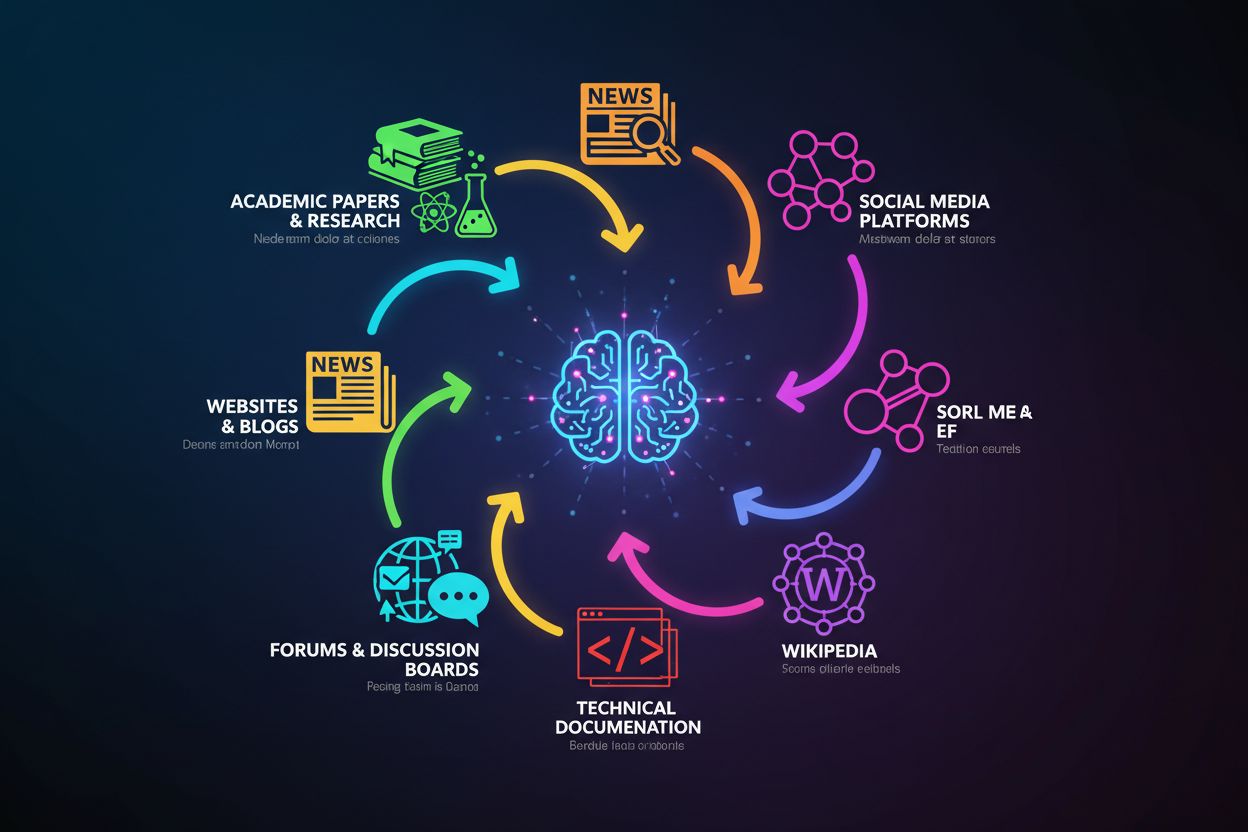
La base de connaissances de ChatGPT est construite à partir d’une collection diversifiée de données Internet accessibles au public, combinée à des jeux de données sous licence et à un affinement par retour humain. Le modèle a été entraîné sur trois sources principales : données Internet disponibles publiquement (sites web, articles et contenus en ligne), jeux de données sous licence (dont des livres et publications académiques), et retour humain de la part de formateurs ayant contribué à affiner les réponses. Ces données d’entraînement englobent un éventail extraordinairement vaste de sources, notamment des sites d’actualités, des revues académiques, des livres, de la documentation technique, des forums comme Reddit et Stack Overflow, des articles de Wikipedia, et d’innombrables autres pages web accessibles publiquement. L’ampleur et la diversité de ces sources—couvrant de multiples langues, domaines et points de vue—créent une base de connaissances complète permettant à ChatGPT d’aborder des sujets allant de la physique quantique à l’histoire médiévale en passant par la culture pop contemporaine. Cependant, il est crucial de comprendre que ChatGPT n’a pas accès à des informations en temps réel ni à des bases de données propriétaires ; il ne peut puiser que dans ce qui était disponible lors de sa période d’entraînement.
Explication de la date de coupure de connaissance
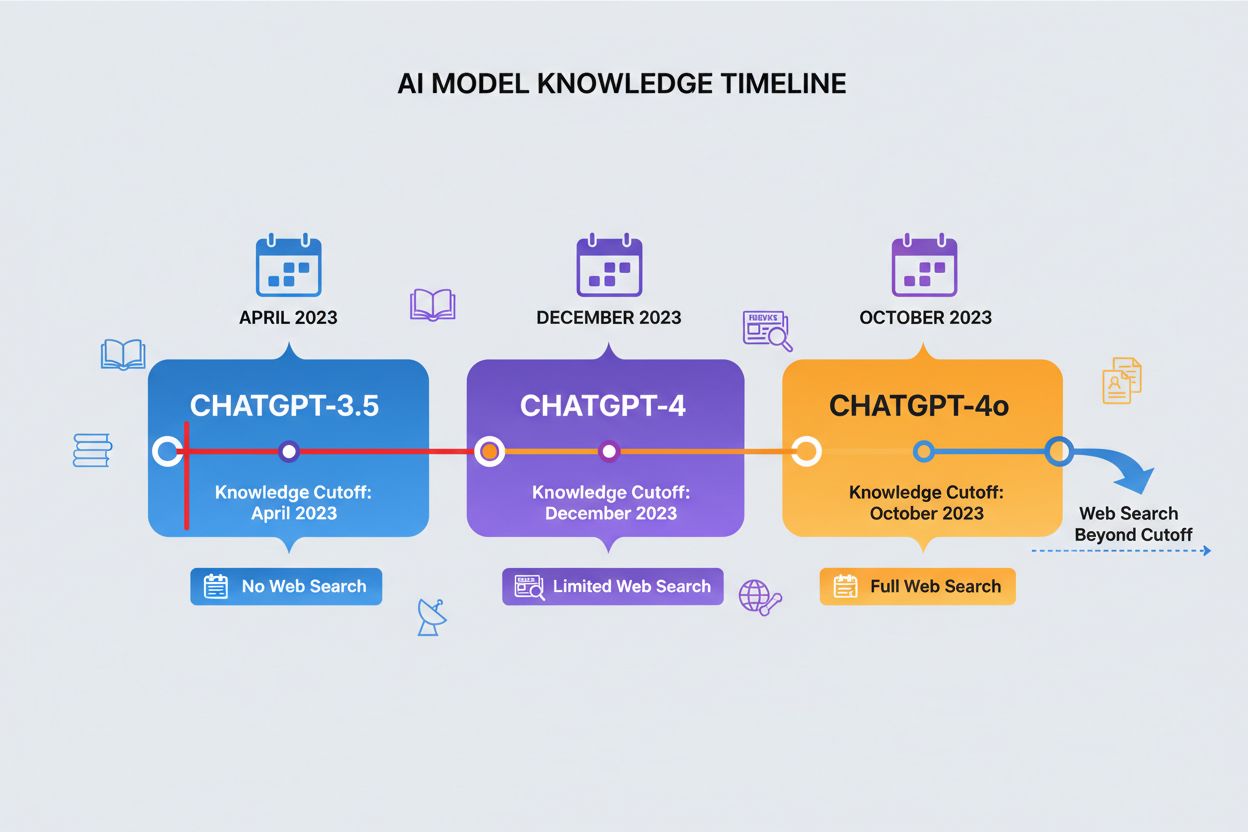
Une date de coupure de connaissance représente le moment après lequel ChatGPT ne dispose plus de données d’entraînement, créant ainsi une limite stricte aux informations auxquelles il peut accéder. Différentes versions de ChatGPT présentent différentes dates de coupure : ChatGPT-4 a été entraîné sur des données jusqu’en décembre 2023, tandis que ChatGPT-4o (la version optimisée) a une coupure en octobre 2023. Ces dates de coupure impactent considérablement la précision et la pertinence des réponses, en particulier pour les événements récents, les recherches nouvellement publiées ou les statistiques actuelles qui peuvent avoir évolué depuis la collecte des données d’entraînement. Certaines versions récentes de ChatGPT peuvent effectuer des recherches web pour récupérer des informations actuelles au-delà de leur date de coupure, bien que cette fonctionnalité ne soit pas disponible dans toutes les versions ou contextes. Comprendre la date de coupure de votre modèle est essentiel pour les utilisateurs ayant besoin d’informations récentes, car ChatGPT ne peut pas fournir de réponses précises sur des événements ou développements survenus après sa période d’entraînement. Cette limitation est l’un des facteurs les plus importants à considérer lors de l’évaluation de la fiabilité de ChatGPT pour des requêtes sensibles au temps.
Version de ChatGPT
Date de coupure de connaissance
Fonctionnalité de recherche web
Cas d’usage principal
ChatGPT-4
Décembre 2023
Limité
Connaissances générales, analyse, raisonnement
ChatGPT-4o
Octobre 2023
Disponible
Performance optimisée, tâches multimodales
ChatGPT-3.5
Avril 2023
Non
Requêtes basiques, option économique
ChatGPT avec navigation
Temps réel
Oui
Actualité, recherches récentes
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Comment ChatGPT récupère et synthétise l’information
Contrairement aux moteurs de recherche qui récupèrent des documents ou pages web spécifiques en réponse à des requêtes, ChatGPT génère des réponses en synthétisant les schémas appris lors de l’entraînement—un processus fondamentalement différent. Lorsque vous posez une question à ChatGPT, il ne parcourt pas une base de données ou un index ; il utilise plutôt des schémas statistiques issus de ses données d’entraînement pour prédire la séquence de mots la plus susceptible de constituer une réponse utile. Cette approche basée sur la génération signifie que ChatGPT combine des informations de multiples sources de ses données d’entraînement pour créer des réponses nouvelles qui n’existent peut-être nulle part sous cette forme dans le matériel source. Le modèle apprend essentiellement les relations entre concepts, faits et idées, puis reconstruit ces connaissances en fonction de votre requête spécifique. Cependant, cette méthode présente un inconvénient majeur : lorsque le modèle hésite ou que les schémas dans ses données d’entraînement sont contradictoires ou lacunaires, il peut générer des informations plausibles mais fausses, un phénomène appelé « hallucination ». Les versions récentes de ChatGPT qui intègrent la recherche web peuvent compléter ce processus de génération en récupérant des informations actuelles sur Internet, bien que cette fonctionnalité nécessite une activation explicite et ne soit pas disponible sur toutes les plateformes.
Sources de données spécifiques et leur importance
Les données d’entraînement de ChatGPT proviennent de plusieurs grandes catégories de sources, chacune apportant une valeur unique à sa base de connaissances :
Articles et recherches académiques : Les revues à comité de lecture et publications de recherche apportent des informations fiables et validées sur des sujets scientifiques et techniques
Articles de presse : Les grands médias d’actualité contribuent à la connaissance des événements récents et à la diversité des points de vue sur des questions contemporaines
Livres : Les livres publiés offrent une couverture approfondie et structurée des sujets et représentent un contenu édité et sélectionné
Sites web et blogs : Le contenu web général fournit des informations pratiques, des tutoriels et des points de vue variés
Forums et plateformes de discussion : Les discussions communautaires comme Reddit et Stack Overflow apportent des solutions concrètes et des avis d’experts
Documentation technique : La documentation logicielle, les API et les guides techniques fournissent des informations précises et spécialisées
Wikipedia : L’encyclopédie collaborative offre des informations structurées couvrant pratiquement tous les domaines
L’importance de cette diversité de sources réside dans leurs forces complémentaires : les articles académiques garantissent la rigueur, les articles de presse l’actualité, les livres la profondeur et les forums l’application pratique. Cependant, la qualité des sources varie considérablement—un article académique révisé par des pairs a plus de poids qu’un simple billet de blog, mais le processus d’entraînement de ChatGPT ne fait pas explicitement la distinction entre eux. Cela signifie que la connaissance de ChatGPT reflète à la fois des sources autorisées de haute qualité et des contenus de moindre qualité, voire trompeurs, d’où l’importance de la vérification lors de l’utilisation du modèle pour des décisions importantes.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Le rôle du retour humain dans l’entraînement
Après l’entraînement initial sur de vastes quantités de textes, OpenAI a utilisé une technique appelée apprentissage par renforcement à partir de retours humains (RLHF) pour affiner les réponses de ChatGPT. Dans ce processus, des formateurs humains ont évalué les réponses du modèle et fourni un retour d’information, aidant le système à apprendre quelles réponses étaient les plus utiles, précises et conformes aux valeurs humaines. Ces formateurs n’ont pas vérifié chaque affirmation ; ils ont plutôt évalué la qualité, l’utilité et la sécurité globale des réponses, influençant indirectement la manière dont le modèle priorise et présente les informations. Le RLHF influence significativement les informations mises en avant dans les réponses et la façon dont les sujets sont abordés, introduisant un jugement humain dans ce qui serait autrement un modèle purement statistique. Cependant, ce processus de retour humain comporte des limites inhérentes : les formateurs ont leurs propres biais, lacunes et limites, et ne peuvent pas évaluer la véracité de chaque affirmation dans tous les domaines. De plus, le processus de retour est coûteux en ressources et ne peut être appliqué qu’à une fraction des sorties possibles du modèle, ce qui signifie qu’une grande partie du comportement de ChatGPT reflète encore les schémas bruts de ses données d’entraînement plutôt qu’une curation humaine explicite.
Bien citer ChatGPT
Citer ChatGPT est important pour l’intégrité académique et la transparence, permettant aux lecteurs de comprendre l’origine des informations et, potentiellement, de reproduire ou vérifier vos résultats. Le format de citation dépend du guide de style requis, mais voici les approches les plus courantes :
Exemple de format MLA :
OpenAI. "ChatGPT." Consulté le [date], https://chat.openai.com.
En style MLA, ChatGPT est cité comme un site web, en incluant la date d’accès car le contenu est dynamique et susceptible de changer. Si vous citez une réponse précise, indiquez la date d’accès et idéalement l’invite ou la question posée.
Exemple de format APA :
OpenAI. (2024). ChatGPT (Version 4) [Grand modèle de langage].
Récupéré de https://chat.openai.com
Le format APA traite ChatGPT comme un outil ou une application logicielle, incluant le numéro de version et la date de récupération. Certains guides APA recommandent d’ajouter l’invite spécifique dans la citation ou en note complémentaire.
Quand citer ChatGPT : Vous devez citer l’outil chaque fois que vous utilisez ses sorties dans un travail académique, un rapport professionnel ou tout contexte où l’attribution est importante. Documentez l’invite exacte utilisée, la date d’accès, et idéalement la version de ChatGPT, car ces détails impactent la reproductibilité. La principale différence entre la citation de ChatGPT et celle de sources traditionnelles est que les réponses de ChatGPT sont générées dynamiquement—la même invite peut produire des résultats légèrement différents selon les occasions—donc l’invite elle-même fait partie intégrante d’une citation correcte. De nombreuses institutions développent encore des directives officielles pour la citation de l’IA, alors vérifiez les recommandations de votre organisation ou publication.
Limites et considérations sur la fiabilité
Bien que ChatGPT soit remarquablement performant, il présente d’importantes limites affectant la fiabilité de ses informations. ChatGPT peut énoncer avec assurance de fausses informations, un problème appelé hallucination, en particulier sur des sujets obscurs, des événements récents postérieurs à sa date de coupure, ou lorsqu’il rencontre des informations contradictoires dans ses données d’entraînement. Les données d’entraînement du modèle comportent des biais inhérents reflétant les perspectives, démographies et points de vue présents dans les sources, ce qui signifie que les réponses peuvent involontairement favoriser certains points de vue ou contenir des stéréotypes. L’information contenue dans les données d’entraînement de ChatGPT devient progressivement obsolète au fil du temps, le rendant peu fiable pour les statistiques actuelles, les découvertes récentes ou les situations en évolution. Pour ces raisons, la vérification des affirmations de ChatGPT est essentielle, notamment pour les décisions importantes—il faut vérifier les faits clés auprès de sources primaires, de publications récentes et de bases de données faisant autorité. Pour vérifier les affirmations de ChatGPT, recoupez ses déclarations avec plusieurs sources indépendantes, vérifiez les dates et statistiques avec les données actuelles, et soyez particulièrement prudent avec les chiffres précis, les noms ou les événements récents. Enfin, rappelez-vous que ChatGPT n’est pas une source primaire ; c’est une source secondaire qui synthétise des informations provenant d’autres sources, donc pour un travail académique ou professionnel, il convient de citer les sources originales référencées par ChatGPT plutôt que ChatGPT lui-même.
Surveiller les citations IA avec AmICited
À mesure que ChatGPT et d’autres systèmes d’IA s’intègrent dans la découverte d’information, surveiller la façon dont ces systèmes citent et référencent votre marque ou organisation est devenu crucial. AmICited est une plateforme de surveillance des réponses IA conçue spécifiquement pour suivre la façon dont ChatGPT, Claude et d’autres grands modèles de langage mentionnent, citent ou font référence à votre entreprise, vos produits ou votre marque dans leurs réponses. La plateforme vous aide à comprendre quand et comment votre marque apparaît dans les réponses générées par l’IA, offrant une visibilité sur un nouveau canal croissant de découverte d’information que les outils de veille web traditionnels manquent souvent. Cette surveillance est essentielle car les citations de l’IA fonctionnent différemment des citations web traditionnelles—elles sont intégrées dans des réponses conversationnelles utilisées chaque jour par des millions d’utilisateurs, alors que la plupart des marques n’ont aucune visibilité sur la façon dont elles sont représentées. Grâce à AmICited, vous obtenez un aperçu de la perception de votre marque dans les systèmes d’IA, pouvez identifier des inexactitudes ou des informations obsolètes à corriger, et comprendre comment votre marque se compare à la concurrence dans les réponses générées par l’IA. À une époque où les systèmes d’IA deviennent la source principale d’information pour de nombreux utilisateurs, surveiller votre présence dans ces systèmes est aussi important que surveiller les résultats des moteurs de recherche traditionnels, faisant d’outils comme AmICited des incontournables pour la gestion moderne de marque et la transparence de l’IA.
Questions fréquemment posées
D'où exactement ChatGPT tire-t-il ses données d'entraînement ?
ChatGPT a été entraîné sur trois sources principales : des données Internet disponibles publiquement (sites web, articles, forums), des jeux de données sous licence (livres et publications académiques), et des retours humains de la part des formateurs. Les données d'entraînement englobent des sites d'actualités, des revues académiques, de la documentation technique, Wikipedia, Reddit, Stack Overflow et d'innombrables autres pages web accessibles au public collectées jusqu'à la date de coupure de connaissance.
Qu'est-ce qu'une date de coupure de connaissance et pourquoi est-ce important ?
Une date de coupure de connaissance est le moment après lequel ChatGPT ne possède plus de données d'entraînement. ChatGPT-4 a une coupure en décembre 2023, tandis que ChatGPT-4o a une coupure en octobre 2023. Cela est important car ChatGPT ne peut pas fournir d'informations précises sur les événements, recherches ou développements survenus après la fin de sa période d'entraînement, ce qui le rend peu fiable pour les requêtes sensibles au temps.
ChatGPT peut-il accéder à des informations en temps réel ?
ChatGPT ne peut pas accéder à des informations en temps réel uniquement à partir de ses données d'entraînement. Cependant, les versions les plus récentes de ChatGPT peuvent effectuer des recherches web pour récupérer des informations actuelles au-delà de leurs dates de coupure, bien que cette fonctionnalité ne soit pas disponible dans toutes les versions ou contextes et nécessite une activation explicite.
Comment citer ChatGPT dans mes travaux académiques ?
En format MLA, citez ChatGPT comme un site web avec la date d'accès. En format APA, traitez-le comme un logiciel et incluez le numéro de version. Les deux formats exigent de documenter l'invite exacte utilisée, la date d'accès et idéalement la version de ChatGPT, car la même invite peut produire des résultats différents selon les occasions.
Les informations de ChatGPT sont-elles toujours exactes ?
Non. ChatGPT peut énoncer avec assurance de fausses informations (hallucination), notamment sur des sujets obscurs, des événements récents postérieurs à sa coupure ou des informations contradictoires. Ses données d'entraînement comportent des biais inhérents, et l'information devient progressivement obsolète. Il est indispensable de vérifier toute affirmation importante auprès de sources primaires et de bases de données faisant autorité.
À quelle fréquence les données d'entraînement de ChatGPT sont-elles mises à jour ?
Les données d'entraînement de ChatGPT ne sont pas mises à jour en continu. De nouvelles versions sont publiées périodiquement avec des dates de coupure actualisées, mais il n'y a pas de mise à jour en temps réel du modèle de base. OpenAI publie de nouvelles versions (comme GPT-4o) avec des données d'entraînement plus récentes, mais le calendrier exact de mise à jour n'est pas divulgué publiquement.
ChatGPT peut-il citer ses sources ?
ChatGPT ne cite pas de sources spécifiques pour chaque affirmation car il synthétise l'information à partir de schémas présents dans ses données d'entraînement plutôt que de retrouver des documents particuliers. Il ne peut pas vous indiquer la source exacte d'un fait. Pour un travail académique, vous devez vérifier les affirmations de ChatGPT et citer les sources originales trouvées, pas ChatGPT lui-même.
Comment AmICited aide-t-il à surveiller les citations de ChatGPT ?
AmICited suit la façon dont ChatGPT, Claude et d'autres systèmes d'IA mentionnent, citent ou font référence à votre marque dans leurs réponses. Il offre une visibilité sur la manière dont votre entreprise apparaît dans les réponses générées par l'IA, aide à identifier les inexactitudes et montre comment votre marque se compare à la concurrence dans les systèmes d'IA—essentiel pour la gestion moderne de marque à l'ère de l'IA.
Surveillez comment ChatGPT fait référence à votre marque
Suivez les citations ChatGPT et les mentions de l'IA en temps réel avec AmICited. Comprenez comment les systèmes d'IA font référence à votre marque et gardez une longueur d'avance sur la découverte d'informations pilotée par l'IA.
Pourquoi ChatGPT aime Reddit : comprendre les préférences de sources
Découvrez pourquoi Reddit domine les citations de ChatGPT avec 40,1 % de toutes les réponses IA. Apprenez comment fonctionnent les préférences de sources de l'I...
Comment ChatGPT Search récupère-t-il des informations depuis le web ?
Découvrez comment ChatGPT Search récupère des informations en temps réel depuis Internet à l'aide de robots d'exploration web, d'indexation et de partenariats a...
Comment ChatGPT choisit-il les sources à citer ? Guide complet
Découvrez comment ChatGPT sélectionne et cite les sources lors de la navigation sur le web. Apprenez les facteurs de crédibilité, les algorithmes de recherche, ...
9 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.