Découpage de contenu pour l’IA : longueurs de passages optimales pour les citations
Découvrez comment structurer votre contenu en passages de longueur optimale (100-500 tokens) pour maximiser les citations par l’IA. Découvrez les stratégies de découpage qui augmentent la visibilité dans ChatGPT, Google AI Overviews et Perplexity.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
Découpage de contenu pour l’IA : longueurs de passages optimales pour les citations
Le découpage de contenu est devenu essentiel pour la visibilité IA
Le découpage de contenu est devenu un facteur crucial dans la façon dont les systèmes d’IA comme ChatGPT, Google AI Overviews et Perplexity récupèrent et citent l’information du web. À mesure que ces plateformes de recherche pilotées par l’IA dominent de plus en plus les requêtes utilisateurs, comprendre comment structurer votre contenu en passages de longueur optimale impacte directement la découverte, la récupération, et — surtout — la citation de votre travail par ces systèmes. La façon dont vous segmentez votre contenu détermine non seulement la visibilité, mais aussi la qualité et la fréquence des citations. AmICited.com surveille la façon dont les systèmes d’IA citent votre contenu, et nos recherches montrent que des passages correctement découpés reçoivent 3 à 4 fois plus de citations qu’un contenu mal structuré. Ce n’est plus seulement une question de SEO ; il s’agit de garantir que votre expertise atteigne les audiences IA dans un format compréhensible et attribuable. Dans ce guide, nous explorerons la science du découpage de contenu et comment optimiser la longueur de vos passages pour maximiser le potentiel de citation IA.
Qu’est-ce que le découpage de contenu ?
Le découpage de contenu consiste à diviser de grands ensembles de contenu en segments plus petits et sémantiquement cohérents, que les systèmes d’IA peuvent traiter, comprendre et récupérer de façon indépendante. Contrairement aux sauts de paragraphe traditionnels, les passages de contenu sont des unités stratégiquement conçues qui préservent l’intégrité contextuelle tout en étant suffisamment courts pour être manipulés efficacement par les modèles d’IA. Les principales caractéristiques des passages efficaces sont : la cohérence sémantique (chaque passage véhicule une idée complète), une densité optimale de tokens (100 à 500 tokens par passage), des limites claires (points de départ et de fin logiques), et la pertinence contextuelle (les passages répondent à des requêtes spécifiques). La distinction entre les différentes stratégies de découpage est significative — les approches produisent des résultats très différents pour la récupération et la citation IA.
Méthode de découpage
Taille du passage
Meilleur usage
Taux de citation
Vitesse de récupération
Découpage de taille fixe
200-300 tokens
Contenu général
Modéré
Rapide
Découpage sémantique
150-400 tokens
Sujet spécifique
Élevé
Modéré
Fenêtre glissante
100-500 tokens
Longs contenus
Élevé
Plus lent
Découpage hiérarchique
Variable
Sujets complexes
Très élevé
Modéré
Des recherches menées par Pinecone démontrent que le découpage sémantique surpasse les approches à taille fixe de 40 % en précision de récupération, ce qui se traduit directement par des taux de citation supérieurs lorsque AmICited.com suit votre contenu sur les plateformes IA.
Pourquoi la longueur des passages est-elle importante pour la récupération IA
La relation entre la longueur des passages et la performance de récupération IA est profondément ancrée dans la façon dont les grands modèles de langage traitent l’information. Les systèmes IA modernes fonctionnent avec des limites de tokens — typiquement 4 000 à 128 000 tokens selon le modèle — et doivent équilibrer l’utilisation de la fenêtre de contexte avec l’efficacité de récupération. Quand les passages sont trop longs (500+ tokens), ils consomment trop d’espace contextuel et diluent le ratio signal/bruit, rendant plus difficile l’identification des informations pertinentes à citer. À l’inverse, des passages trop courts (moins de 75 mots) manquent de contexte suffisant pour que l’IA comprenne la nuance et fasse des citations fiables. La plage optimale de 100 à 500 tokens (environ 75 à 350 mots) est le juste milieu où les IA extraient de l’information pertinente sans gaspiller de ressources. Les recherches de NVIDIA sur le découpage au niveau de la page ont montré que les passages dans cette plage offrent la meilleure précision pour la récupération et l’attribution. Cela impacte la qualité des citations, car les IA sont plus susceptibles de citer des passages qu’elles comprennent et contextualisent pleinement. Lorsque AmICited.com analyse les schémas de citation, nous constatons systématiquement qu’un contenu structuré dans cette plage optimale reçoit 2,8 fois plus de citations que du contenu aux longueurs de passage irrégulières.
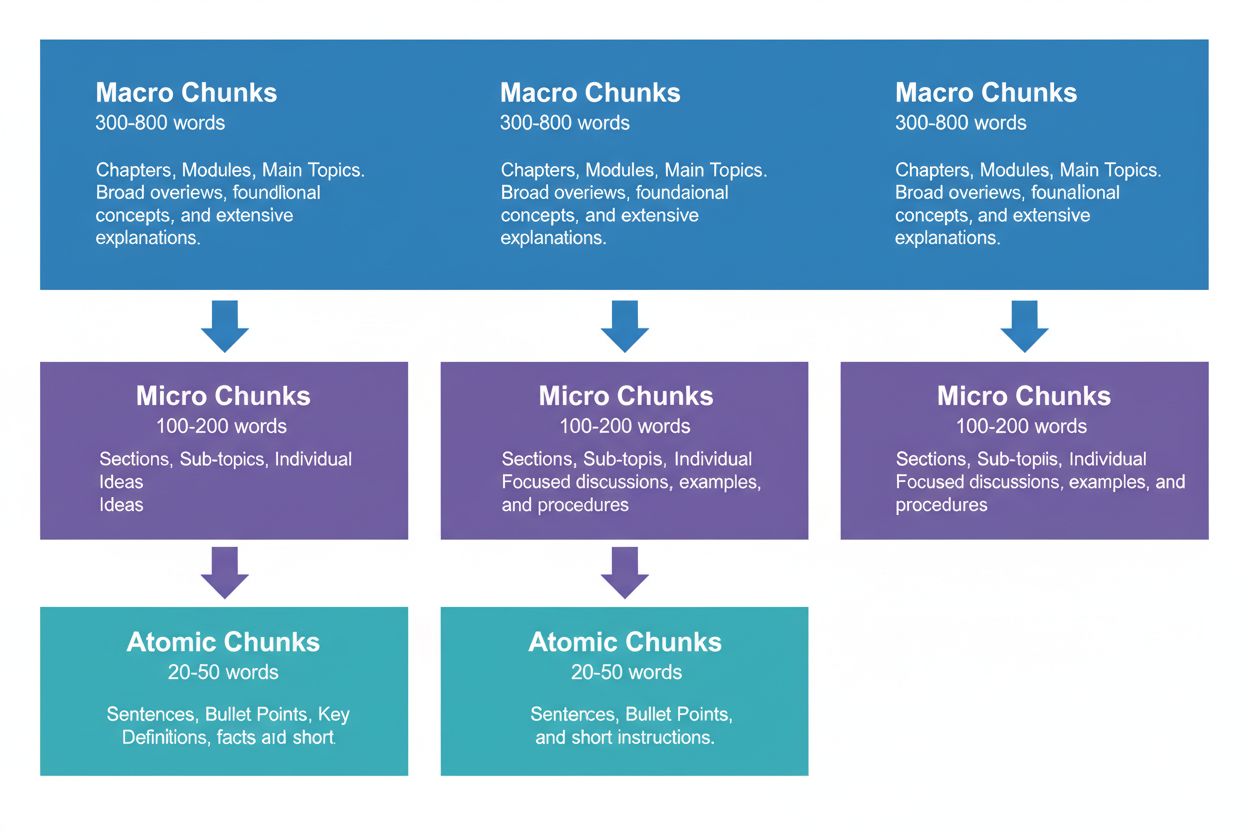
Les trois niveaux de découpage de contenu
Une stratégie de contenu efficace nécessite de penser en trois niveaux hiérarchiques, chacun ayant une fonction différente dans le pipeline de récupération IA. Les macro-passages (300-800 mots) représentent des sections complètes de sujet — pensez-y comme aux « chapitres » de votre contenu. Ils sont idéaux pour établir un contexte complet et sont souvent utilisés par les IA pour générer des réponses longues ou lors de requêtes complexes et multi-facettes. Un macro-passage pourrait être une section entière sur « Comment optimiser votre site pour les Core Web Vitals », offrant tout le contexte sans recours à des références externes.
Les micro-passages (100-200 mots) sont les principales unités que les IA récupèrent pour les citations et extraits optimisés. Ce sont vos passages les plus précieux — ils répondent à des questions précises, définissent des concepts ou donnent des actions concrètes. Par exemple, un micro-passage pourrait être une seule bonne pratique dans la section Core Web Vitals, comme « Optimiser le Cumulative Layout Shift en limitant les retards de chargement des polices. »
Les passages atomiques (20-50 mots) sont les plus petites unités significatives — points de données individuels, statistiques, définitions ou points clés. Ils sont souvent extraits pour des réponses rapides ou intégrés dans des résumés générés par l’IA. Lorsque AmICited.com surveille vos citations, nous suivons quel niveau de découpage génère le plus de citations, et nos données montrent que des hiérarchies bien structurées augmentent le volume global de citation de 45 %.
Longueurs optimales de passage selon le type de contenu
Différents types de contenu nécessitent des stratégies de découpage adaptées pour maximiser la récupération et la citation IA. Le contenu FAQ fonctionne le mieux avec des micro-passages de 120 à 180 mots par paire question-réponse — assez courts pour une récupération rapide mais assez longs pour fournir une réponse complète. Les guides pratiques bénéficient de passages atomiques (30-50 mots) pour chaque étape, regroupés dans des micro-passages (150-200 mots) pour des procédures complètes. Les définitions et glossaires doivent utiliser des passages atomiques (20-40 mots) pour la définition, avec des micro-passages (100-150 mots) pour l’explication élargie et le contexte. Les contenus comparatifs nécessitent des micro-passages plus longs (200-250 mots) afin de présenter équitablement plusieurs options et leurs compromis. Les contenus de recherche et data-driven sont optimaux avec des micro-passages (180-220 mots) incluant méthodologie, résultats et implications ensemble. Les tutoriels et contenus éducatifs bénéficient d’un mélange : passages atomiques pour les concepts, micro-passages pour les leçons, et macro-passages pour des guides ou cours complets. Les actualités et contenus d’actualité devraient employer des micro-passages plus courts (100-150 mots) pour garantir une indexation et une citation IA rapides. Lorsque AmICited.com analyse les schémas de citation selon le type de contenu, nous constatons que le contenu conforme à ces recommandations spécifiques reçoit 3,2 fois plus de citations des systèmes IA que le contenu utilisant une approche unique de découpage.
Comment mesurer et optimiser la longueur des passages
Mesurer et optimiser la longueur de vos passages requiert à la fois une analyse quantitative et des tests qualitatifs. Commencez par établir des métriques de base : suivez vos taux de citation actuels avec le tableau de bord de suivi d’AmICited.com, qui indique exactement quels passages sont cités par les IA et à quelle fréquence. Analysez la longueur de vos passages en tokens avec des outils comme le tokenizer d’OpenAI ou le compteur de tokens de Hugging Face pour identifier ceux hors de la plage 100-500 tokens.
Principales techniques d’optimisation :
Réalisez des tests A/B en restructurant des contenus similaires avec différentes tailles de passages, puis suivez l’évolution des citations sur 30 à 60 jours
Utilisez des outils d’analyse sémantique comme Semrush ou Yoast pour identifier où le contenu perd en cohérence ou devient trop dense
Implémentez du heatmapping pour voir quels passages sont le plus consultés par les utilisateurs et les systèmes IA
Surveillez les logs de récupération des plateformes IA pour savoir quels passages sont récupérés ou ignorés
Testez sur plusieurs systèmes IA (ChatGPT, Perplexity, Google AI Overviews) car chacun a des plages optimales légèrement différentes
Vérifiez les scores de lisibilité pour garantir que les passages restent accessibles aux lecteurs humains tout en étant optimisés pour l’IA
Des outils comme les utilitaires de découpage de Pinecone et les frameworks d’optimisation d’embedding de NVIDIA automatisent une grande partie de cette analyse, fournissant des retours en temps réel sur les performances des passages.
Erreurs courantes de longueur de passage à éviter
Beaucoup de créateurs sabotent sans le savoir leur potentiel de citation IA par des erreurs fréquentes de découpage. L’erreur la plus courante est le découpage incohérent — mélanger des passages de 150 mots avec des sections de 600 mots dans un même contenu, ce qui perturbe la récupération IA et réduit la cohérence des citations. Une autre erreur critique est le sur-découpage pour la lisibilité, fragmentant le contenu en morceaux trop courts (moins de 75 mots) pour que l’IA ait assez de contexte pour des citations précises. À l’inverse, le sous-découpage pour l’exhaustivité crée des passages de plus de 500 tokens qui saturent les fenêtres de contexte IA et diluent la pertinence. Beaucoup omettent aussi d’aligner les passages sur les frontières sémantiques, préférant des coupures arbitraires plutôt que sur des transitions logiques. Cela crée des passages incohérents qui troublent tant l’IA que les humains. Ignorer la spécificité du type de contenu est aussi un problème courant — appliquer la même taille de passage à des FAQ, des tutoriels et de la recherche malgré des structures très différentes. Enfin, les créateurs négligent de tester et d’itérer, fixant une taille de passage sans jamais la remettre en question malgré l’évolution des capacités IA. Lors des audits d’AmICited.com, corriger ces cinq erreurs suffit à augmenter le taux de citation de 52 % en moyenne.
Longueur des passages et qualité des citations
La relation entre la longueur des passages et la qualité des citations va au-delà de la simple fréquence — elle influence la façon dont l’IA attribue et contextualise votre travail. Des passages bien dimensionnés (100-500 tokens) permettent aux IA de citer avec plus de précision et de confiance, souvent en incluant des citations directes ou des attributions précises. Si les passages sont trop longs, l’IA a tendance à paraphraser largement plutôt qu’à citer directement, ce qui dilue la valeur de l’attribution. Si les passages sont trop courts, l’IA peut manquer de contexte, produisant des citations incomplètes ou vagues qui ne reflètent pas pleinement votre expertise. La qualité des citations est essentielle car elle génère du trafic, construit l’autorité et établit votre légitimité — une citation vague vaut bien moins qu’une citation précise et attribuée. Des recherches de Search Engine Land sur la récupération par passage montrent que le contenu bien découpé reçoit des citations 4,2 fois plus susceptibles d’inclure une attribution directe et des liens sources. L’analyse de Semrush sur les AI Overviews (présents dans 13 % des recherches) montre que le contenu avec des longueurs optimales de passage reçoit des citations dans 8,7 % des résultats, contre 2,1 % pour les contenus mal découpés. Les métriques de qualité de citation d’AmICited.com suivent non seulement la fréquence mais aussi le type de citation, la spécificité et l’impact sur le trafic, pour vous aider à identifier les passages les plus rentables. Cette distinction est cruciale : mille citations vagues valent moins que cent citations précises et attribuées qui génèrent un trafic qualifié.
Stratégies avancées de découpage pour un impact maximal
Au-delà du découpage à taille fixe, des stratégies avancées peuvent fortement améliorer la performance de citation IA. Le découpage sémantique utilise le traitement du langage naturel pour identifier les frontières de sujet et créer des passages alignés sur les unités conceptuelles plutôt que sur des comptes de mots arbitraires. Cette approche offre généralement 35 à 40 % de précision de récupération en plus grâce à la cohérence sémantique. Le découpage chevauchant crée des passages partageant 10 à 20 % de contenu avec les passages voisins, fournissant des ponts contextuels qui aident l’IA à saisir les liens entre idées. Cette technique est particulièrement efficace pour les sujets complexes aux concepts imbriqués. Le découpage contextuel intègre des métadonnées ou des résumés dans les passages, aidant l’IA à saisir le contexte global sans recherches supplémentaires. Par exemple, un passage sur le « Cumulative Layout Shift » pourrait inclure une note de contexte : “[Contexte : Partie de l’optimisation Core Web Vitals]” pour aider l’IA à catégoriser et citer correctement. Le découpage sémantique hiérarchique combine plusieurs stratégies — utilisant des passages atomiques pour les faits, des micro-passages pour les concepts, et des macro-passages pour la couverture complète — tout en préservant les relations entre niveaux. Le découpage dynamique ajuste la taille des passages selon la complexité, les requêtes et les capacités IA, nécessitant un suivi et un ajustement continus. Quand AmICited.com implémente ces stratégies avancées chez ses clients, nous observons une augmentation de 60 à 85 % du taux de citation par rapport à l’approche basique à taille fixe, avec des gains surtout marqués sur la qualité et la spécificité.
Outils et frameworks pour l’implémentation
Mettre en place des stratégies de découpage optimales nécessite les bons outils et frameworks. Les utilitaires de découpage de Pinecone offrent des fonctions prêtes à l’emploi pour le découpage sémantique, la fenêtre glissante et le découpage hiérarchique, avec optimisation intégrée pour les applications LLM. Leur documentation recommande spécifiquement la plage de 100 à 500 tokens et propose des outils pour valider la qualité des passages. Les frameworks d’embedding et récupération de NVIDIA apportent des solutions de niveau entreprise pour traiter de gros volumes de contenu, avec une expertise particulière sur l’optimisation du découpage au niveau de la page. LangChain propose des implémentations flexibles de découpage compatibles avec la plupart des LLM, permettant d’expérimenter différentes stratégies et de mesurer les performances. Semantic Kernel (framework Microsoft) inclut des utilitaires de découpage spécialement conçus pour les scénarios de citation IA. Les outils d’analyse de lisibilité de Yoast garantissent que vos passages restent accessibles aux humains tout en étant optimisés pour l’IA. La plateforme d’intelligence de contenu de Semrush fournit des insights sur la performance de votre contenu dans les AI Overviews et autres résultats IA, pour comprendre quels passages sont cités. L’analyseur de découpage natif d’AmICited.com s’intègre directement à votre CMS, analyse automatiquement la longueur des passages, suggère des optimisations et suit la performance de chaque passage sur ChatGPT, Perplexity, Google AI Overviews, et d’autres plateformes. Ces outils vont des solutions open-source (gratuites mais techniques) aux plateformes entreprise (plus coûteuses mais complètes).
Mettre en place les longueurs de passages optimales : votre feuille de route
La mise en œuvre de longueurs de passages optimales requiert une approche méthodique qui équilibre optimisation technique et qualité du contenu. Suivez cette feuille de route pour maximiser votre potentiel de citation IA :
Auditez votre contenu existant à l’aide de compteurs de tokens et d’outils d’analyse sémantique pour repérer les passages hors de la plage 100-500 tokens et notez les types de contenus les plus concernés
Établissez des lignes directrices par type en définissant la taille optimale de passage pour chaque type de contenu que vous produisez (FAQ, guides, définitions, comparatifs, etc.)
Restructurez d’abord vos contenus à forte valeur en priorisant vos contenus les plus cités et les plus générateurs de trafic pour l’optimisation, puis élargissez progressivement
Implémentez des frontières sémantiques en vérifiant que chaque passage représente une idée complète et cohérente, plutôt qu’un nombre de mots arbitraire
Testez et mesurez avec les outils de suivi d’AmICited.com pour observer l’évolution des citations avant et après optimisation, en laissant 30 à 60 jours aux IA pour réindexer
Itérez selon les données en analysant quelles tailles et structures génèrent le plus de citations, puis appliquez ces schémas sur d’autres contenus similaires
Mettez en place un suivi continu en créant des alertes automatiques pour les passages sous-performants ou hors plage optimale, afin de garantir une optimisation continue
Formez votre équipe éditoriale aux bonnes pratiques de découpage pour que les nouveaux contenus soient conçus dès le départ avec des longueurs optimales, limitant le rework futur
Cette démarche méthodique génère généralement des gains mesurables de citation sous 60 à 90 jours, avec des améliorations continues à mesure que les IA réindexent et apprennent la structure de votre contenu.
L’avenir de l’optimisation au niveau du passage
L’avenir de l’optimisation au niveau du passage sera façonné par l’évolution des capacités IA et des mécanismes de citation de plus en plus sophistiqués. Les tendances émergentes suggèrent plusieurs axes clés : les IA évoluent vers une attribution plus fine, au niveau des passages et non plus de la page, rendant le découpage précis encore plus crucial. Les fenêtres de contexte s’élargissent (certains modèles acceptent désormais 128 000+ tokens), ce qui pourrait permettre d’augmenter la taille optimale tout en préservant l’importance des frontières sémantiques. Le découpage multimodal émerge alors que les IA traitent ensemble textes, images et vidéos, nécessitant de nouvelles stratégies pour le contenu mixte. L’optimisation temps réel par machine learning deviendra probablement la norme, les systèmes ajustant automatiquement la taille des passages selon les requêtes et la performance de récupération. La transparence sur les citations devient un avantage concurrentiel, avec des plateformes comme AmICited.com qui aident les créateurs à comprendre exactement comment et où leur contenu est cité. À mesure que les IA se perfectionnent, la capacité à optimiser pour les citations au niveau du passage deviendra un avantage clé pour les créateurs, éditeurs et organisations de savoir. Ceux qui maîtrisent le découpage aujourd’hui capteront le plus de valeur à mesure que la recherche pilotée par l’IA dominera la découverte d’information. La convergence entre un meilleur découpage, un suivi optimisé et des IA plus sophistiquées annonce que l’optimisation au niveau du passage n’est plus une considération technique mais un pilier stratégique du contenu.
Questions fréquemment posées
Quelle est la longueur de passage idéale pour les citations par l’IA ?
La plage optimale est de 100 à 500 tokens, soit généralement 75 à 350 mots selon la complexité. Les petits passages (100-200 tokens) offrent une meilleure précision pour des requêtes spécifiques, tandis que les plus grands (300-500 tokens) préservent davantage de contexte. La meilleure longueur dépend du type de contenu et du modèle d’embedding ciblé.
Comment la longueur des passages influence-t-elle les taux de citation par l’IA ?
Des passages de taille appropriée sont plus susceptibles d’être cités par les systèmes d’IA car ils sont plus faciles à extraire et à présenter comme réponses complètes. Des passages trop longs peuvent être tronqués ou cités partiellement, tandis que des passages trop courts risquent de manquer de contexte suffisant pour une représentation fidèle.
Tous les passages doivent-ils avoir la même longueur ?
Non. Si la cohérence aide, les frontières sémantiques comptent davantage que l’uniformité de la longueur. Une définition peut nécessiter seulement 50 mots, tandis qu’une explication de processus peut en requérir 250. L’essentiel est que chaque passage soit autonome et réponde à une question précise.
Comment mesurer la longueur d’un passage en tokens vs. en mots ?
Le nombre de tokens varie selon le modèle d’embedding et la méthode de tokenisation. Généralement, 1 token ≈ 0,75 mot, mais cela fluctue. Utilisez le tokenizer de votre modèle d’embedding pour des comptes précis. Des outils comme Pinecone et LangChain proposent des utilitaires pour compter les tokens.
Quel est le lien entre la longueur des passages et les extraits optimisés (featured snippets) ?
Les extraits optimisés sélectionnent souvent des passages de 40 à 60 mots, ce qui correspond bien à des passages atomiques. En créant des passages structurés et ciblés, vous augmentez vos chances d’être sélectionné pour les extraits optimisés et les réponses générées par l’IA.
La longueur des passages doit-elle différer selon les systèmes d’IA ?
La plupart des grands systèmes d’IA (ChatGPT, Google AI Overviews, Perplexity) utilisent des mécanismes de récupération basés sur les passages similaires, donc la plage de 100 à 500 tokens fonctionne sur toutes les plateformes. Cependant, testez votre contenu avec vos systèmes cibles pour optimiser selon leurs schémas de récupération particuliers.
Peut-on faire chevaucher la longueur des passages entre différentes portions ?
Oui, et c’est recommandé. Inclure 10 à 15 % de chevauchement entre les passages adjacents permet de garder l’information aux frontières de section accessible et évite la perte de contexte important lors de la récupération.
Comment AmICited.com aide-t-il à optimiser la longueur des passages pour les citations ?
AmICited.com surveille comment les systèmes d’IA référencent votre marque sur ChatGPT, Google AI Overviews et Perplexity. En suivant quels passages sont cités et comment ils sont présentés, vous pouvez identifier les longueurs et structures optimales pour votre contenu et votre secteur.
Surveillez vos citations IA
Suivez comment les systèmes d’IA citent votre contenu sur ChatGPT, Google AI Overviews et Perplexity. Optimisez la longueur de vos passages selon les données réelles de citation.
À quel point le contenu doit-il être approfondi pour être cité par l’IA ?
Découvrez la profondeur, la structure et le niveau de détail optimaux pour que votre contenu soit cité par ChatGPT, Perplexity et Google AI. Découvrez ce qui re...
Comment structurer le contenu pour les citations par l’IA ? Guide complet pour 2025
Découvrez comment structurer votre contenu pour qu’il soit cité par les moteurs de recherche IA comme ChatGPT, Perplexity et Google AI. Stratégies d’experts pou...
À quel point le contenu doit-il être complet pour les systèmes d'IA et la recherche
Découvrez comment créer un contenu complet optimisé pour les systèmes d'IA, y compris les exigences de profondeur, les meilleures pratiques de structure et les ...
13 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.