Créer des données originales que l’IA souhaite citer
Découvrez comment créer des données et des recherches originales que les systèmes d’IA souhaitent activement citer. Découvrez des stratégies pour rendre vos données repérables par ChatGPT, Perplexity, Google Gemini et Claude tout en construisant une visibilité durable auprès de l’IA.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
Pourquoi les données originales comptent à l’ère de l’IA
À l’ère de l’intelligence artificielle, les données originales sont devenues le nouvel avantage concurrentiel pour les marques cherchant à exister au-delà du référencement classique. À mesure que des plateformes IA comme ChatGPT, Perplexity, Google Gemini ou Claude deviennent l’interface principale de découverte de l’information, les règles de la visibilité ont fondamentalement changé. Plutôt que de viser la position zéro sur Google, les organisations doivent désormais créer des données que les systèmes d’IA souhaitent activement citer et référencer. Cette transformation accompagne une évolution plus large, du SEO centré contenu vers ce que les experts appellent le « Generative Engine Optimization » (GEO), où la citation par l’IA remplace le ranking traditionnel comme principal indicateur de visibilité. Les plateformes synthétisant l’information en réponses directes — par génération augmentée par récupération (RAG) ou synthèse « model-native » — favorisent mécaniquement les sources proposant des recherches claires, extractibles et faisant autorité. Les organisations qui comprennent ce changement et investissent dans la création de données originales, de recherches propriétaires et d’insights uniques se positionnent pour obtenir des citations sur plusieurs plateformes IA simultanément, générant notoriété et crédibilité auprès d’audiences qui ne verront peut-être jamais les résultats de recherche classiques.
Comment les systèmes IA découvrent et citent les données
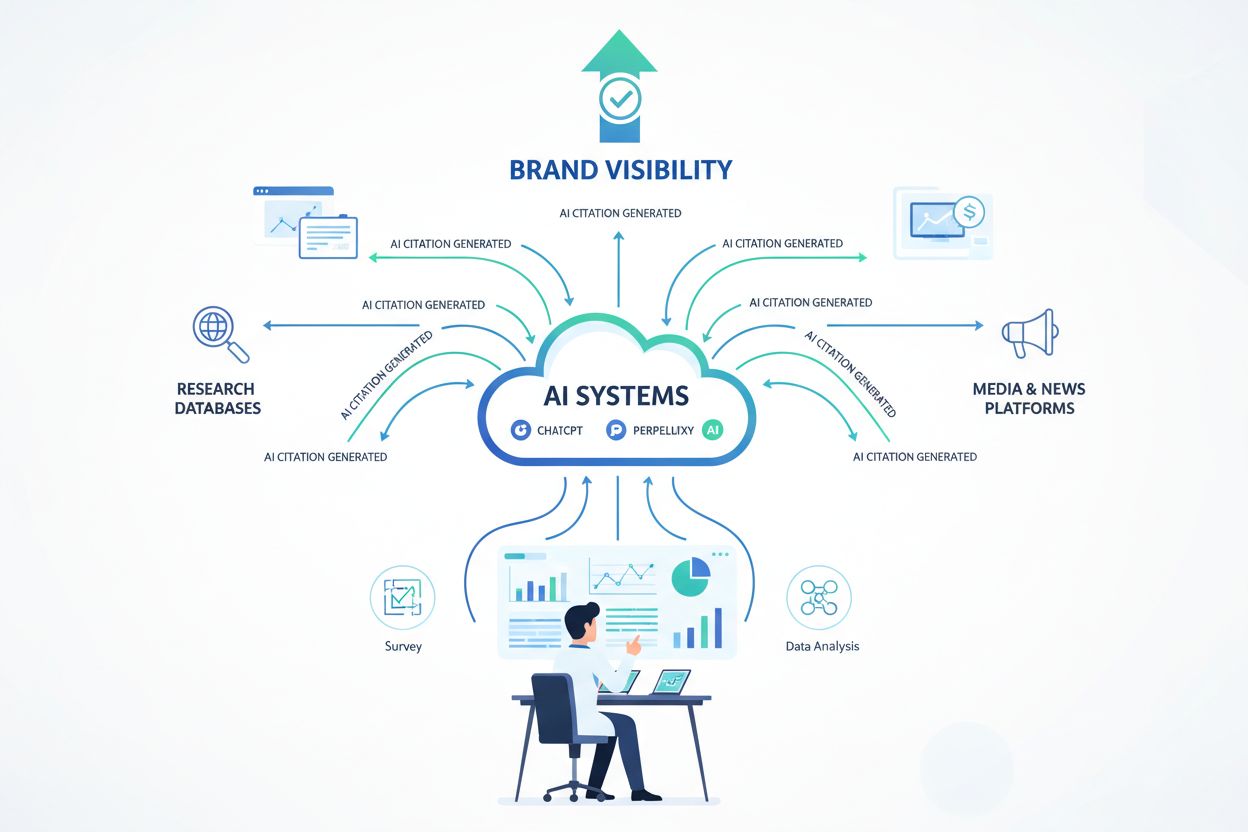
Différentes plateformes IA reposent sur des architectures fondamentalement distinctes pour découvrir et citer les sources, ce qui influence directement la façon dont vos données originales sont repérées et créditées. Comprendre ces mécanismes est essentiel pour optimiser la visibilité de votre contenu dans l’univers IA. La différence entre synthèse model-native (où l’IA génère des réponses à partir de motifs appris sur les données d’entraînement) et génération augmentée par récupération (où l’IA recherche des sources en direct et synthétise à partir des résultats récupérés) explique pourquoi certaines plateformes fournissent des citations explicites, alors que d’autres livrent des réponses sans attribution. Les plateformes utilisant la RAG peuvent relier leurs réponses à des sources précises, rendant la citation claire et traçable. À l’inverse, les systèmes model-native s’appuient sur les connaissances probabilistes acquises lors de l’entraînement, ce qui rend l’attribution de source difficile, voire impossible sans plugins ou intégrations supplémentaires.
Plateforme IA
Méthode de citation
Priorité source de données
Impact sur la visibilité
ChatGPT
Model-native (par défaut) ; citations avec plugins/navigation activée
Données d’entraînement + web en direct (si activé) ; privilégie les sources récentes et de référence en mode récupération
Faible sans plugins ; modérée avec recherche activée ; citations dans le texte des réponses quand disponibles
Perplexity
Récupération d’abord avec citations numérotées en ligne
Résultats de recherche web en direct ; privilégie les sources fraîches et pertinentes ; met en avant la proéminence de la source
Élevé ; citations numérotées avec liens clairs ; la première source reçoit un trafic disproportionné
Google Gemini
Intégré à Google Search & Knowledge Graph
Pages indexées + entités du Knowledge Graph ; priorité aux pages avec données structurées et signaux E-E-A-T
Élevé ; citations sous forme de liens dans les AI Overviews ; données structurées améliorent la probabilité de citation
Claude
Model-native (par défaut) ; recherche web déployée en 2025
Données d’entraînement + recherche web sélective ; priorité à la sécurité et à l’autorité des sources
Modéré ; citations si recherche web activée ; accent sur l’exactitude et la crédibilité des sources
Les implications pratiques sont majeures : les plateformes comme Perplexity et Google Gemini, qui explorent activement le web en temps réel, peuvent citer votre contenu dès sa publication si celui-ci répond à leurs critères de qualité et de pertinence. ChatGPT et Claude, qui reposent davantage sur les données d’entraînement, peuvent mettre plus de temps à intégrer vos recherches originales mais offrent d’autres opportunités via plugins et intégrations. Pour les créateurs de contenu, cela signifie qu’il faut comprendre les plateformes utilisées par votre audience cible et optimiser vos données en conséquence — qu’il s’agisse de garantir un contenu extractible et bien structuré pour la récupération live de Perplexity, ou de renforcer les signaux d’autorité influençant l’inclusion dans les données d’entraînement pour les systèmes model-native.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Le rôle des données structurées et des métadonnées
Les données structurées sont passées du statut de simple levier SEO à celui de nécessité stratégique pour la visibilité IA. Lorsque vous implémentez un balisage schema à l’aide de Schema.org, vous ne facilitez pas seulement la compréhension de votre contenu par Google — vous créez une couche lisible par machine sur laquelle les systèmes IA peuvent s’appuyer pour leurs réponses. Cette couche structurée, souvent appelée « content knowledge graph », définit explicitement les entités (personnes, produits, services, lieux, organisations) et leurs relations, ce qui simplifie radicalement la compréhension de ce qu’est votre marque, ce qu’elle propose et comment elle doit être perçue. Selon des recherches récentes de BrightEdge, les pages avec un balisage schema robuste affichent des taux de citation plus élevés dans les AI Overviews de Google, suggérant que les données structurées influencent directement la probabilité de citation. L’émergent Model Context Protocol (MCP), adopté par OpenAI et Google DeepMind, représente la prochaine évolution — fonctionnant en somme comme une API standardisée pour connecter les modèles d’IA à des sources de données structurées. En généralisant le balisage schema, les entreprises créent un socle qui réduit les hallucinations des IA, améliore l’ancrage dans le factuel et rend leurs données plus repérables dans les systèmes de récupération. C’est d’autant plus important que les IA entraînées sur du texte non structuré peinent souvent à garantir la justesse ; les données structurées apportent la clarté contextuelle qui permet aux LLM de générer des réponses plus fiables et attribuables, citant vos recherches originales avec confiance.
Créer des données que les systèmes IA souhaitent citer
La stratégie la plus efficace pour obtenir des citations IA est de produire des données originales extractibles, faisant autorité et alignées sur la façon dont l’IA récupère et synthétise l’information. Au lieu d’espérer que votre contenu existant soit cité, il faut concevoir délibérément des produits de données que les plateformes IA pourront facilement découvrir, comprendre et référencer. Voici les stratégies clés pour créer des données originales dignes de citation :
Mener des recherches originales avec une méthodologie transparente : les systèmes IA privilégient les sources affichant des pratiques de recherche rigoureuses. Publiez des études, sondages, analyses avec méthodologie, taille d’échantillon et limites clairement documentées. En montrant votre démarche, les plateformes IA peuvent citer vos conclusions avec confiance. Exemples : benchmarks sectoriels, études comportementales clients, analyses de marché, données propriétaires non réplicables par la concurrence.
Rendre les données extractibles grâce à des formats structurés : l’IA préfère le contenu sous forme de tableaux, listes, matrices comparatives, FAQ, plutôt que des paragraphes denses. Un tableau comparatif de fonctionnalités concurrentes sera bien plus cité que la même information noyée dans du texte. Utilisez titres, puces, hiérarchies visuelles pour que les insights clés soient instantanément repérables et exploitables par les systèmes IA.
Garantir la fraîcheur des données et les signaux de mise à jour : les plateformes IA, notamment celles utilisant la récupération live, privilégient l’information actuelle. Affichez des dates de publication visibles, des horodatages de mise à jour, rafraîchissez régulièrement le contenu. Montrer que vos données sont à jour et entretenues les rend plus fiables aux yeux de l’IA. C’est crucial pour les données sensibles au temps comme les prix, statistiques, tendances.
Établir l’autorité de l’auteur et de la marque : les systèmes IA évaluent la crédibilité de la source avant de la citer. Affichez clairement les références de l’auteur (bios, expertise), l’autorité organisationnelle (backlinks, mentions presse, reconnaissance sectorielle), les signaux d’expertise de domaine. Une marque reconnue dans sa catégorie sera citée plus souvent et plus en vue.
Définir explicitement les entités et leurs relations : précisez vos entités clés — entreprise, produits, services, collaborateurs, concepts sectoriels — et utilisez les données structurées pour établir leurs relations. Lorsqu’un système IA comprend précisément qui vous êtes et comment vous vous rattachez à votre secteur, il peut vous citer plus justement et dans le bon contexte.
Assurer une attribution et des sources transparentes : si vos données originales s’appuient sur d’autres sources, citez-les de façon transparente. Les systèmes IA reconnaissent et valorisent les sources qui citent elles-mêmes leurs références. Cela crée une chaîne d’attribution qui renforce la confiance et la probabilité de citation dans tout l’écosystème.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Mesurer et optimiser la citation par l’IA
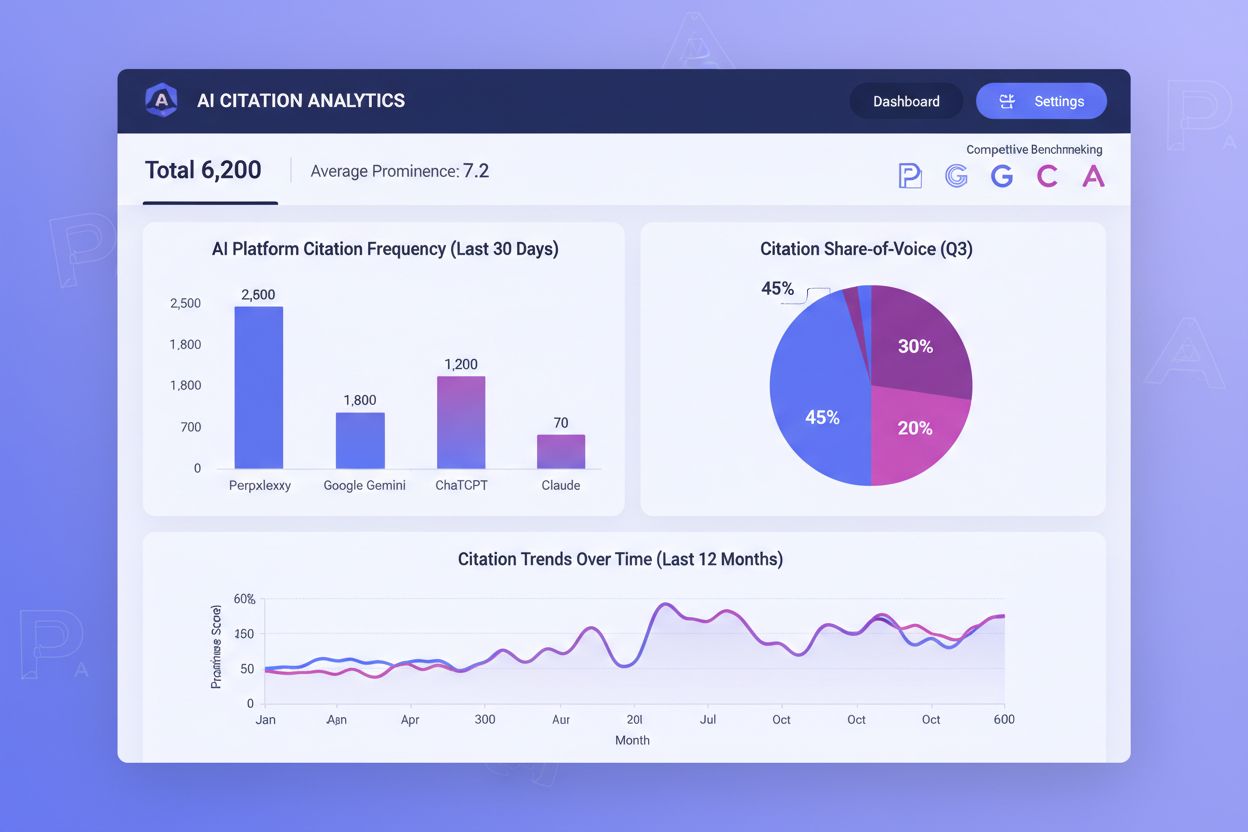
Suivre les citations IA est devenu aussi crucial que le suivi du ranking SEO, pourtant la plupart des organisations ignorent à quelle fréquence leur contenu est cité sur les plateformes IA. Fréquence de citation, proéminence de citation et part de voix sont les trois métriques centrales qui conditionnent votre succès dans la découverte médiée par l’IA. La fréquence de citation mesure combien de fois votre contenu apparaît dans les réponses IA pour vos requêtes cibles — si vous êtes cité sur 40 % des prompts pertinents alors que vos concurrents le sont sur 60 %, il existe un écart d’optimisation évident. La proéminence de citation compte encore plus : une citation en première position dans la liste numérotée de Perplexity apporte une visibilité sans commune mesure avec la cinquième position. La part de voix révèle votre position concurrentielle — si votre marque est citée sur 25 % des requêtes structurantes alors que votre principal concurrent l’est sur 50 %, vous perdez une part majeure de visibilité.
Des outils comme AmICited.com sont devenus essentiels pour monitorer les citations IA sur les différentes plateformes. Ces solutions recensent quelles pages de votre site obtiennent des citations sur Perplexity, Google AI Overviews, ChatGPT avec recherche, etc., révélant quel contenu génère réellement une visibilité médiée par l’IA. En suivant les schémas de citation dans le temps, vous pouvez déterminer quels types, sujets et formats de contenu génèrent le plus de citations, puis reproduire ces stratégies gagnantes. Le benchmarking concurrentiel via ces outils montre précisément où vous perdez des citations face à la concurrence, permettant une optimisation ciblée. Les données révèlent si vos difficultés de citation sont universelles sur toutes les IA ou spécifiques à certaines plateformes — si vous êtes souvent cité sur Perplexity mais rarement sur Google AI Overviews, votre stratégie d’optimisation doit différer en conséquence. Les métriques pondérées par position reconnaissent que les premières citations ont plus de valeur ; un outil pondérant davantage les positions hautes fournit des insights bien plus exploitables que de simples comptages. En traitant le suivi des citations IA comme un pilier de votre stratégie de contenu, vous pourrez optimiser en continu vos données originales pour accroître à la fois la fréquence et la proéminence de vos citations, améliorant directement votre visibilité dans un univers de recherche piloté par l’IA.
Construire une stratégie de données durable pour la visibilité IA
Créer des données originales qui obtiennent des citations IA ne peut pas être un projet ponctuel : cela exige de bâtir une stratégie de données durable et transversale qui considère la donnée comme un actif stratégique méritant investissement et gouvernance continue. Les organisations qui réussissent dans la visibilité IA mettent en place des processus structurés pour la mise à jour continue des données, garantissant que la recherche originale reste à jour et pertinente. Cela implique des cycles réguliers de rafraîchissement des jeux de données clés, de mise à jour des statistiques à mesure que les infos évoluent, et de maintien des signaux de fraîcheur utilisés par l’IA pour évaluer la crédibilité des sources. Au-delà des mises à jour de contenu, les entreprises performantes alignent leur stratégie de données entre marketing, SEO, contenu, produit et data via la gouvernance des entités — définitions et taxonomies partagées assurant une représentation cohérente et précise de votre marque, de vos produits et des concepts sectoriels sur l’ensemble des points de contact.
L’approche la plus avancée consiste à traiter les données structurées et les knowledge graphs comme une infrastructure d’entreprise. Plutôt que de mettre en place le balisage schema page par page, les organisations leaders construisent des knowledge graphs globaux connectant toutes les entités, sujets et relations sur leurs propriétés numériques. Cela requiert des capacités techniques — outils et processus pour gérer le schema à grande échelle — et un alignement organisationnel sur les standards de qualité des données. Si la structure est correcte, cette infrastructure remplit un double objectif : elle améliore la visibilité externe auprès de l’IA tout en facilitant les initiatives IA internes. Selon l’étude Gartner « AI Mandates for the Enterprise 2024 », la disponibilité et la qualité des données sont le principal obstacle à la réussite de l’IA d’entreprise ; investir dans les données structurées et la gouvernance des entités permet de résoudre à la fois les défis de visibilité externe et d’activation IA interne. Les entreprises qui gagnent la bataille de la visibilité IA considèrent la création de données originales non comme une tactique marketing mais comme une capacité business fondamentale, avec des ressources dédiées, une responsabilité claire et une optimisation continue fondée sur le suivi des citations et le benchmarking concurrentiel.
Questions fréquemment posées
Quelle est la différence entre des données originales et du contenu classique pour la citation par l’IA ?
Les données originales désignent des recherches propriétaires, des jeux de données uniques et des résultats primaires que vous avez créés ou découverts vous-même. Les systèmes d’IA privilégient les données originales car elles offrent une information faisant autorité et directement exploitable qu’ils peuvent citer en toute confiance. Le contenu classique synthétise souvent des informations existantes, ce qui le rend moins intéressant pour la citation par l’IA. Les données originales deviennent le socle de la visibilité IA car des plateformes comme Perplexity et Google Gemini recherchent et citent activement les sources qui proposent des insights et recherches uniques.
Comment les différentes plateformes IA découvrent-elles et citent-elles mes données originales ?
Différentes plateformes IA utilisent des mécanismes de découverte variés. Perplexity et Google Gemini recourent à la génération augmentée par récupération (RAG), c’est-à-dire qu’elles explorent le web en temps réel et peuvent citer votre contenu dès sa publication. ChatGPT et Claude s’appuient davantage sur les données d’entraînement, votre contenu peut donc être intégré plus tardivement mais offre d’autres opportunités de visibilité. Toutes les plateformes bénéficient des données structurées (balises schema) qui rendent vos données lisibles par les machines et plus compréhensibles, augmentant la probabilité de citation sur tous les systèmes.
Quel rôle jouent les données structurées dans la citation par l’IA ?
Les données structurées utilisant le vocabulaire Schema.org créent une couche lisible par machine dans laquelle les systèmes IA peuvent ancrer leurs réponses. En mettant en place le balisage schema, vous définissez explicitement les entités (votre entreprise, produits, services) et leurs relations, ce qui facilite énormément la compréhension et la citation précise de votre contenu par les systèmes IA. Des études montrent que les pages avec un balisage schema robuste reçoivent plus de citations dans les AI Overviews de Google. Les données structurées réduisent également les hallucinations en fournissant aux IA des informations factuelles et claires à référencer.
Quels types de données originales sont les plus susceptibles d’être citées par l’IA ?
Les systèmes IA citent le plus fréquemment des recherches originales à la méthodologie transparente, des jeux de données propriétaires, des benchmarks sectoriels, des études comportementales clients, des analyses de marché et des insights uniques que les concurrents ne peuvent reproduire. Les données présentées dans des formats extractibles — tableaux, matrices comparatives, listes, FAQ — reçoivent plus de citations que la même information dans des paragraphes denses. Les données fraîches et actuelles avec dates de publication visibles et mises à jour régulières sont privilégiées. Les signaux d’autorité tels que les références d’auteurs et la reconnaissance organisationnelle augmentent aussi la probabilité de citation.
Comment mesurer si mes données originales sont citées par des systèmes IA ?
Des outils comme AmICited.com suivent les citations IA sur plusieurs plateformes, vous montrant à quelle fréquence votre contenu apparaît dans les réponses de ChatGPT, Perplexity, Google AI Overviews et Claude. Ces outils mesurent la fréquence de citation (combien de fois vous êtes cité), la proéminence de la citation (position dans la réponse) et la part de voix (vos citations comparées à celles des concurrents). En surveillant ces métriques, vous pouvez identifier quels types et sujets de contenu génèrent le plus de citations, puis optimiser votre stratégie de données en conséquence. Les métriques pondérées par position reconnaissent que les citations en première position ont plus de valeur que celles plus basses.
Quelle est la différence entre fréquence de citation et proéminence de citation ?
La fréquence de citation mesure combien de fois votre contenu est cité dans les réponses IA pour vos requêtes cibles — si vous êtes cité sur 40 % des prompts pertinents, c’est votre fréquence de citation. La proéminence de citation mesure où votre citation apparaît dans la réponse — une citation en première position dans la liste numérotée de Perplexity offre bien plus de visibilité qu’une citation en cinquième position. Les deux métriques comptent pour la visibilité IA, mais la proéminence est souvent plus importante car les utilisateurs cliquent ou interagissent surtout avec les premières citations. Une optimisation efficace implique d’améliorer ces deux métriques en parallèle.
À quelle fréquence dois-je mettre à jour mes données originales pour maintenir leur valeur de citation IA ?
Les données originales doivent être actualisées selon un rythme qui correspond à la vitesse d’évolution de votre secteur. Pour les domaines évoluant vite comme la tech ou la finance, des mises à jour mensuelles ou trimestrielles peuvent être nécessaires. Pour des secteurs plus stables, une mise à jour annuelle peut suffire. L’essentiel est de maintenir des signaux de fraîcheur visibles — dates de publication, horodatages de mise à jour, indicateurs de rafraîchissement — qui indiquent aux IA que vos données sont actuelles et fiables. Les mises à jour régulières augmentent aussi vos chances d’être cité par des systèmes comme Perplexity qui privilégient l’information récente. Considérez la maintenance des données comme une responsabilité opérationnelle continue, non un projet ponctuel.
Puis-je utiliser AmICited.com pour suivre les citations de mes concurrents ?
Oui, AmICited.com propose des fonctionnalités de benchmark concurrentiel qui montrent vos performances de citation par rapport à des concurrents définis. Vous pouvez voir quels concurrents sont cités plus souvent, dans des positions plus en vue, et sur quelles plateformes IA. Cette veille concurrentielle révèle précisément où vous perdez des citations et quelles stratégies d’optimisation pourraient vous faire gagner du terrain. En comprenant votre paysage concurrentiel en matière de citation, vous pouvez prioriser vos efforts de création et d’optimisation de données sur les opportunités à plus fort impact, pour garantir à vos données originales la visibilité qu’elles méritent.
Surveillez vos citations IA dès aujourd'hui
Suivez la fréquence à laquelle vos données originales sont citées par ChatGPT, Perplexity, Google AI Overviews et d'autres plateformes IA. Obtenez des analyses exploitables pour optimiser votre contenu et maximiser votre visibilité auprès de l’IA.
Pourquoi la recherche originale est cruciale pour la visibilité IA et les citations
Découvrez pourquoi la création de recherches originales est essentielle pour la visibilité auprès de l’IA. Apprenez comment la recherche originale aide votre ma...
Relations publiques axées sur les données : créer des recherches que l’IA veut citer
Découvrez comment créer des recherches originales et des contenus RP axés sur les données que les systèmes d’IA citent activement. Découvrez les 5 attributs d’u...
Recherche originale : le gain de visibilité de 30 à 40 % pour les citations par l’IA
Découvrez comment la recherche originale et les données propriétaires génèrent un gain de visibilité de 30 à 40 % dans les citations par l’IA sur ChatGPT, Perpl...
15 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.