
Fichier LLMs.txt
Découvrez ce que sont les fichiers LLMs.txt, en quoi ils diffèrent de robots.txt, et pourquoi ils sont essentiels pour la visibilité et les citations dans ChatG...
12 min de lecture

Analyse critique de l’efficacité de LLMs.txt. Découvrez si cette norme de contenu IA est essentielle pour votre site ou simplement du battage médiatique. Données réelles sur l’adoption, la prise en charge des plateformes et ce qui fonctionne réellement pour la visibilité auprès de l’IA.
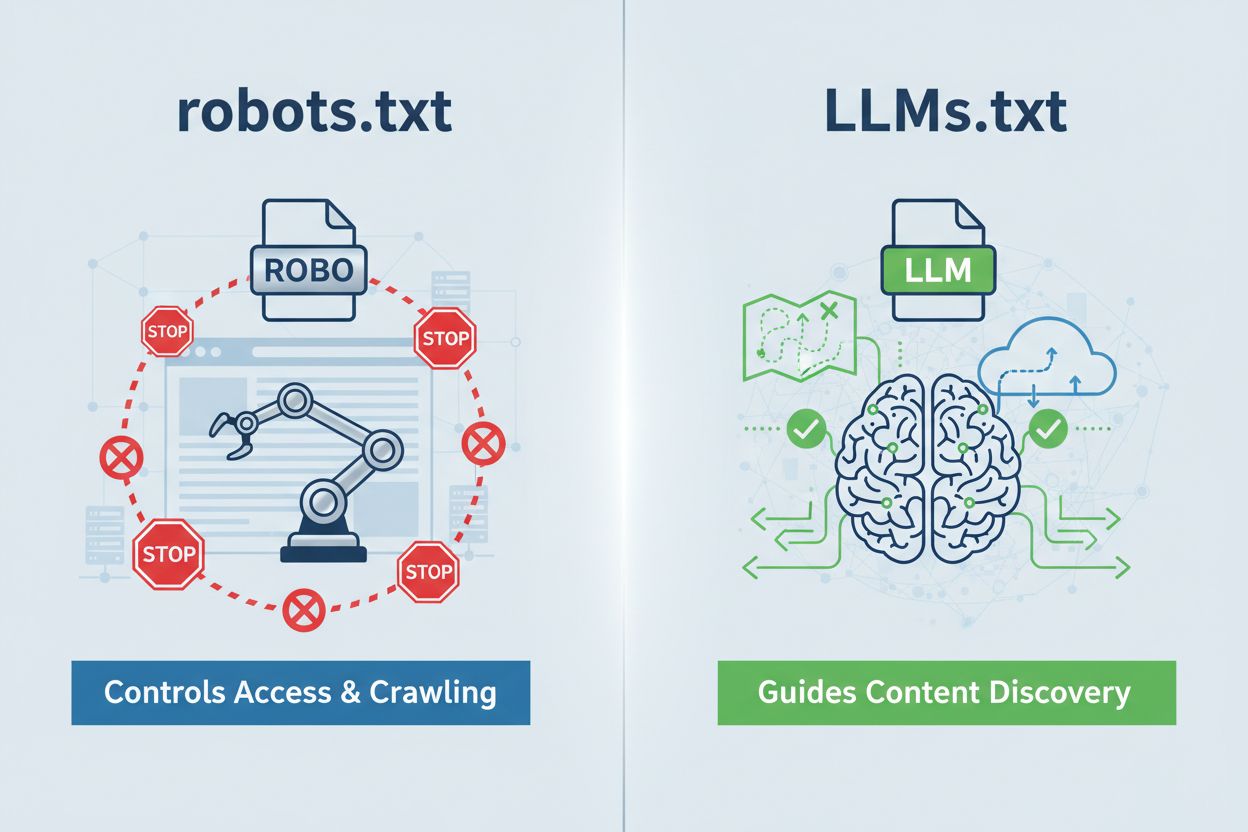
LLMs.txt est un fichier texte brut placé sur domaine.com/llms.txt qui sert de guide sélectionné pour permettre aux systèmes d’IA de découvrir votre contenu de la plus haute qualité. Il est fondamentalement différent de robots.txt—alors que robots.txt contrôle l’accès des crawlers IA à votre site, LLMs.txt fonctionne à l’accès au moment de l’inférence, aidant les systèmes d’IA à comprendre quelles pages méritent la priorité lors de la génération de réponses. Voyez-le moins comme un agent de circulation et plus comme une carte au trésor : il n’empêche pas l’exploration, il souligne simplement où la vraie valeur est cachée. Son format est d’une simplicité rafraîchissante—du markdown brut sans syntaxe complexe—ce qui le rend accessible à toute organisation, quel que soit son niveau technique. Cette distinction est importante car elle redéfinit toute la discussion : LLMs.txt ne vise pas à contrôler le crawling ; il s’agit d’optimiser la façon dont les systèmes d’IA interprètent et hiérarchisent votre contenu lisible par l’IA après vous avoir déjà trouvé.
Les chiffres indiquent une réelle traction : plus de 844 000 sites web ont mis en place LLMs.txt en octobre 2025, avec une adoption concentrée parmi les entreprises qui comprennent le rôle de l’IA dans leur avenir. De grands acteurs comme Anthropic, Cloudflare, Stripe, Vercel et Supabase ont tous adopté la norme, signalant que les entreprises d’infrastructure sérieuses y voient un intérêt. La décision de Mintlify d’activer la génération automatique pour des milliers de sites de documentation en novembre 2024 a créé un pic d’adoption, démontrant que le support des outils peut accélérer la mise en œuvre. Trois annuaires communautaires suivent désormais les implémentations, avec plus de 788 sites vérifiés répertoriés. Cependant, le schéma d’adoption révèle un point important : la mise en œuvre est fortement concentrée dans les outils développeurs et les plateformes de documentation—les secteurs les plus susceptibles de bénéficier de la visibilité auprès de l’IA. Voici à quoi ressemble réellement le paysage de l’adoption :
| Entreprise/Plateforme | Implémentation | Nombre de tokens | Statut |
|---|---|---|---|
| Anthropic | Oui | ~2 000 | Actif |
| Cloudflare | Oui | ~5 000 | Actif |
| Stripe | Oui | ~8 000 | Actif |
| Vercel | Oui | ~3 500 | Actif |
| Supabase | Oui | ~4 200 | Actif |
| Mintlify (généré automatiquement) | Oui | Variable | Actif |
C’est ici que le scepticisme devient justifié : AUCUNE grande plateforme IA n’a officiellement confirmé utiliser LLMs.txt dans leurs systèmes de récupération. John Mueller de Google l’a dit clairement : « Aucun système IA n’utilise actuellement llms.txt », un commentaire qui aurait dû clore le débat, mais qui ne l’a pas fait. OpenAI, Anthropic, Google, Microsoft et Perplexity gardent tous un silence stratégique sur le sujet—pas de documentation officielle, pas de confirmation d’utilisation, aucun plan public. Il existe des preuves que certaines plateformes crawlent les fichiers (des bots Microsoft et OpenAI ont été observés récupérant des fichiers LLMs.txt), mais le crawling et l’utilisation réelle sont deux choses totalement différentes. L’interprétation optimiste suggère que les plateformes testent discrètement avant de s’engager publiquement ; l’interprétation sceptique suggère qu’elles ne l’adopteront jamais car cela ne résout pas un problème réel pour elles. Ce silence est le cœur de l’argument « surcoté » : 18 mois après le lancement de la proposition, on constate une large mise en œuvre mais aucune adoption officielle par les plateformes. Ce n’est pas un standard—c’est un espoir.
La position sceptique repose sur un fondement simple : il n’existe aucune preuve que LLMs.txt améliore la récupération IA, augmente le trafic ou améliore la visibilité du contenu. Le problème de confiance est plus profond—en créant un fichier séparé qui peut contenir un contenu différent de celui de votre HTML, vous rendez possible la manipulation. Les recherches sur le comportement des LLM montrent qu’ils sont 2,5 fois plus susceptibles de recommander un contenu spécifiquement mis en avant ou ciblé, ce qui crée des incitations évidentes à tricher. Une organisation pourrait théoriquement remplir LLMs.txt avec ses meilleurs contenus tout en cachant les pages plus faibles, ou pire, inclure dans LLMs.txt du contenu qui n’existe pas réellement sur le site. Les éditeurs d’outils SEO accentuent la pression en signalant l’absence de fichiers LLMs.txt comme une opportunité d’optimisation—Rank Math, SEMrush, et d’autres créent un cercle vicieux où les sites mettent en œuvre la norme non parce qu’elle fonctionne, mais parce que les outils leur disent qu’il manque quelque chose. Voilà le vrai problème : 18 mois de pression à la mise en œuvre sans un seul cas documenté de valeur mesurable. C’est l’équivalent numérique d’acheter tous un billet de loterie parce que la société de loterie fait de la publicité.
Le camp pro-LLMs.txt propose un raisonnement différent, fondé sur l’inévitabilité du changement plus que sur la preuve actuelle. Carolyn Shelby de Yoast l’a parfaitement résumé : « Le classement n’est plus le prix—l’inclusion l’est. » Windsurf, un éditeur de code IA, a signalé que LLMs.txt permettait d’économiser du temps et des tokens lors de l’analyse de documentation, suggérant de vrais gains d’efficacité pour les IA qui l’utilisent. Anthropic a spécifiquement demandé à Mintlify d’implémenter LLMs.txt pour leur documentation, laissant entendre une valeur interne même s’ils ne le confirment pas publiquement. Google a inclus LLMs.txt dans son protocole A2A (Agents to Agents), suggérant que l’entreprise le considère comme faisant partie de l’infrastructure future pour la communication IA-à-IA. La mise en œuvre prend 1 à 4 heures sans désavantage démontré—vous ne cassez rien, n’affectez pas le SEO, vous créez juste un fichier. L’observation de Jeremy Howard va droit au cœur de la logique des partisans : « 99,9 % de l’attention va bientôt être celle des LLM, pas des humains, » ce qui signifie qu’optimiser pour les systèmes d’IA n’est plus une option, mais une nécessité. Springs Apps a rapporté une augmentation de 20 % de la visibilité en recherche après mise en place, bien que cela reste non vérifié et pourrait refléter une corrélation plutôt qu’une causalité.
Comprendre pourquoi LLMs.txt pourrait échouer nécessite d’analyser pourquoi d’autres standards ont réussi. Robots.txt a fonctionné car il créait un bénéfice mutuel à coût minimal et bénéficiait d’un support RFC officiel (RFC 9309)—les moteurs de recherche voulaient crawler efficacement, les sites voulaient contrôler le crawling, et la solution était suffisamment simple pour que l’adoption soit sans friction. Schema.org a réussi grâce à un développement multi-parties impliquant Google, Microsoft, Yahoo et Yandex dès le départ—aucune entreprise ne pouvait en revendiquer la propriété, ce qui a instauré la confiance. Sitemap.xml a obtenu un large soutien des plateformes avant l’adoption massive, et non après. LLMs.txt n’a aucun de ces trois facteurs de succès : pas d’implication du W3C, aucun consortium, aucun support officiel de plateforme, et aucune preuve de gain en trafic, classement ou précision. Ce qui fait fonctionner un standard, c’est la participation de multiples parties prenantes, des bénéfices clairs et mesurables, et un faible potentiel de manipulation. LLMs.txt a de l’espoir. Il a l’adoption des premiers croyants. Il est soutenu par des outils. Mais il n’a pas les éléments fondamentaux qui transforment une expérimentation en infrastructure.
Si LLMs.txt reste non prouvé, qu’est-ce qui fait vraiment la différence pour la visibilité IA et les citations IA ? La réponse est moins exotique qu’un nouveau format de fichier :
Ces tactiques fonctionnent car elles correspondent à la façon dont les IA traitent effectivement l’information, et non parce qu’elles sont optimisées pour un format de fichier particulier.

La discussion autour de LLMs.txt reflète un changement plus profond dans la réussite des contenus en ligne : la convergence de l’expérience utilisateur humaine et de l’optimisation pour l’IA. La recherche sur le Generative Engine Optimization (GEO) montre que les contenus qui gagnent dans les réponses générées par l’IA partagent des caractéristiques spécifiques—clarté, structure, autorité et précision. Vercel a rapporté que 10 % de ses inscriptions proviennent désormais directement des mentions ChatGPT, plutôt que du référencement organique traditionnel, une métrique inimaginable il y a cinq ans. Le succès signifie de plus en plus apparaître dans les réponses générées par l’IA, pas seulement dans les résultats organiques—ce sont des objectifs d’optimisation différents, avec des exigences différentes. Le paysage des outils a évolué pour accompagner ce changement : SEMrush AIO, le suivi GEO de Profound et Ahrefs Brand Radar surveillent désormais la visibilité IA en plus du classement traditionnel. Le véritable changement de paradigme est le suivant : être cité importe plus qu’être classé, et être référencé importe plus qu’être indexé. Ce changement explique pourquoi LLMs.txt a gagné en popularité malgré l’absence de soutien officiel—il tente d’optimiser pour une nouvelle économie de l’attention où les IA sont le principal canal de distribution.
Si vous décidez de l’implémenter, faites-le correctement. Le fichier doit être situé sur domaine.com/llms.txt (attention : pluriel, pas singulier), formaté en markdown brut plutôt qu’en XML ou JSON. Commencez par un titre H1 avec le nom de votre site, suivi éventuellement d’un résumé (blockquote) de l’objectif de votre site. Organisez le contenu en sections H2 si votre site comporte plusieurs zones (Documentation, Blog, Référence API, etc.), avec des descriptions expliquant le contenu de chaque section. Utilisez le format [Titre](URL) : Description pour chaque page, en gardant la description concise mais informative. À inclure : contenu intemporel, pages bien structurées, et contenus qui démontrent une véritable expertise. À éviter : votre page d’accueil (généralement peu utile isolément), toutes les URL de votre site (qualité avant quantité), et les pages qui n’ont pas de sens hors contexte. Voici un exemple de structure de base :
# Nom de l'entreprise
> Brève description de ce que fait votre entreprise et pourquoi les IA devraient s'intéresser à votre contenu
## Documentation
[Premiers pas](https://example.com/docs/getting-started): Guide pas-à-pas pour les nouveaux utilisateurs
[Référence API](https://example.com/docs/api): Documentation API complète avec exemples
[Bonnes pratiques](https://example.com/docs/best-practices): Modèles éprouvés pour utiliser notre plateforme
## Blog
[Pourquoi nous avons créé ceci](https://example.com/blog/why-we-built-this): Le problème que nous avons résolu et comment
Vous pouvez éventuellement inclure une section pour les URLs à ignorer si un contexte plus court est nécessaire, bien que la plupart des implémentations n’aient pas besoin de ce niveau de granularité.
Oui, vous devriez mettre en place LLMs.txt. Pas parce que son efficacité est prouvée, mais parce que le risque est nul et le gain potentiel réel. Si les plateformes IA ne l’adoptent jamais officiellement, le fichier restera simplement sur votre serveur sans conséquence—aucune pénalité SEO, aucune perte de trafic, aucune fonctionnalité cassée. La mise en œuvre prend environ 10 minutes pour un petit site et peut-être une heure pour des structures plus grandes. Pendant ce temps, le trafic se fragmente entre plusieurs IA : ChatGPT, Perplexity, Claude et de nouveaux compétiteurs gèrent collectivement des centaines de millions de requêtes chaque mois. Vous êtes déjà visible pour les IA—LLMs.txt les aide simplement à trouver votre meilleur contenu plutôt que des pages aléatoires. Même si LLMs.txt ne devient jamais une norme officielle, vous entraînez les IA à mieux comprendre la structure et les priorités de votre site, ce qui a de la valeur. L’essentiel est le suivant : couvrez-vous gratuitement. Implémentez la norme, optimisez votre contenu pour la visibilité IA avec des méthodes éprouvées, et surveillez ce qui génère réellement du trafic depuis les systèmes IA. Dans 12 mois, vous aurez des données réelles pour savoir si LLMs.txt est important pour votre activité—et cela vaut infiniment mieux que des spéculations.
LLMs.txt est un fichier texte brut qui guide les systèmes d'IA vers votre meilleur contenu pour un accès au moment de l'inférence, tandis que robots.txt contrôle l'accès des crawlers et l'indexation. LLMs.txt ne restreint rien—il sélectionne et met en avant vos pages les plus précieuses pour la compréhension par l'IA. Considérez robots.txt comme un agent de circulation et LLMs.txt comme une carte au trésor.
Officiellement non. Bien que plus de 844 000 sites web l'aient mis en œuvre, aucune grande plateforme IA n'a confirmé utiliser LLMs.txt pour générer des réponses. Certaines preuves montrent une activité de crawling provenant des robots OpenAI et Microsoft, mais aucune utilisation confirmée à des fins d'inférence ou de citation. C'est le cœur de l'argument "surcoté".
Oui. La mise en œuvre prend 10 à 30 minutes sans inconvénient. Si les plateformes l'adoptent, vous êtes déjà prêt. Si ce n'est pas le cas, le fichier ne cause aucun tort. C'est une couverture à faible risque et à gain potentiel pour la visibilité auprès de l'IA. Vous pariez essentiellement sur l'avenir de la découverte de contenu médiée par l'IA.
Incluez du contenu intemporel et bien structuré qui répond à des questions précises : guides, FAQ, documentation API, contenus piliers et articles faisant autorité. Évitez votre page d'accueil, chaque URL de votre site, et les pages qui n'ont pas de sens citées hors contexte. La qualité prime sur la quantité.
Oui, c'est une préoccupation légitime. Vous pourriez mettre un contenu différent dans LLMs.txt que sur vos pages réelles, ce qui brise la confiance. C'est pourquoi certains experts restent sceptiques quant à la viabilité du standard à long terme et pourquoi l'adoption par les plateformes reste prudente.
llms.txt contient des liens sélectionnés vers vos meilleures pages avec des descriptions. llms-full.txt est une version exhaustive regroupant toute votre documentation dans un seul fichier massif (parfois plus de 400 000 mots). Utilisez llms-full.txt si vous souhaitez donner tout votre contenu aux systèmes d'IA d'emblée, sans qu'ils aient à suivre des liens.
LLMs.txt est un outil dans la stratégie GEO plus large. GEO vise à rendre votre contenu découvrable et citable par les systèmes d'IA grâce à une structure claire, des citations, des données et une expertise reconnue. LLMs.txt aide à orienter les IA vers votre meilleur contenu GEO-optimisé.
Oui. Tout site web bénéficie d'aider les systèmes d'IA à comprendre et citer votre contenu. Blogs, entreprises locales, sites e-commerce et communautés de niche voient tous du trafic issu de la recherche alimentée par l'IA. LLMs.txt est un moyen simple d'améliorer votre visibilité sur ChatGPT, Claude, Perplexity et autres plateformes d'IA.
Suivez comment des systèmes d'IA comme ChatGPT, Claude et Perplexity référencent votre contenu. Obtenez des analyses en temps réel sur vos citations IA et votre visibilité sur les plateformes d'IA.
Découvrez ce que sont les fichiers LLMs.txt, en quoi ils diffèrent de robots.txt, et pourquoi ils sont essentiels pour la visibilité et les citations dans ChatG...

Découvrez comment implémenter LLMs.txt sur votre site web pour aider les systèmes d’IA à mieux comprendre votre contenu. Guide complet étape par étape pour tout...

Découvrez ce qu'est LLMs.txt, si cela fonctionne réellement et si vous devriez l'implémenter sur votre site web. Une analyse honnête de ce standard émergent du ...