Balises Meta NoAI : Contrôler l’accès des IA via les en-têtes
Découvrez comment implémenter les balises meta noai et noimageai pour contrôler l’accès des crawlers IA au contenu de votre site web. Guide complet sur les en-têtes de contrôle d’accès IA et les méthodes de mise en œuvre.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
Les crawlers web sont des programmes automatisés qui parcourent systématiquement Internet pour collecter des informations sur les sites web. Historiquement, ces bots étaient principalement exploités par des moteurs de recherche comme Google, dont le Googlebot explorait les pages, indexait le contenu et renvoyait les utilisateurs vers les sites via les résultats de recherche—créant ainsi une relation mutuellement bénéfique. Cependant, l’apparition des crawlers IA a fondamentalement changé cette dynamique. Contrairement aux bots de moteurs de recherche traditionnels qui apportent du trafic de référence en échange d’un accès au contenu, les crawlers d’entraînement IA consomment d’énormes quantités de contenu web pour constituer des ensembles de données pour les grands modèles de langage, tout en ne renvoyant souvent que très peu ou pas de trafic aux éditeurs. Ce changement a rendu les balises meta—petites directives HTML qui communiquent des instructions aux crawlers—de plus en plus importantes pour les créateurs de contenu souhaitant garder le contrôle sur la manière dont leur travail est utilisé par les systèmes d’intelligence artificielle.
Qu’est-ce que les balises Meta NoAI et NoImageAI ?
Les balises noai et noimageai sont des directives créées par DeviantArt en 2022 pour aider les créateurs à empêcher que leur travail ne soit utilisé pour entraîner des générateurs d’images IA. Ces balises fonctionnent de la même manière que la directive noindex bien établie, qui indique aux moteurs de recherche de ne pas indexer une page. La directive noai signale qu’aucun contenu de la page ne doit être utilisé pour l’entraînement IA, tandis que noimageai empêche spécifiquement les images d’être utilisées pour l’entraînement des modèles IA. Vous pouvez implémenter ces balises dans la section head de votre HTML avec la syntaxe suivante :
<!-- Bloquer tout le contenu de l’entraînement IA --><metaname="robots"content="noai">
<!-- Bloquer uniquement les images de l’entraînement IA --><metaname="robots"content="noimageai">
<!-- Bloquer à la fois le contenu et les images --><metaname="robots"content="noai, noimageai">
Voici un tableau comparatif des différentes directives de balises meta et de leurs objectifs :
Directive
Objectif
Syntaxe
Portée
noai
Empêche tout le contenu d’être utilisé pour l’entraînement IA
content="noai"
Tout le contenu de la page
noimageai
Empêche les images d’être utilisées pour l’entraînement IA
content="noimageai"
Images uniquement
noindex
Empêche l’indexation par les moteurs de recherche
content="noindex"
Résultats de recherche
nofollow
Empêche le suivi des liens
content="nofollow"
Liens sortants
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Alors que les balises meta sont placées directement dans votre HTML, les en-têtes HTTP offrent une méthode alternative pour communiquer des directives aux crawlers au niveau du serveur. L’en-tête X-Robots-Tag peut inclure les mêmes directives que les balises meta mais fonctionne différemment—il est envoyé dans la réponse HTTP avant que le contenu de la page ne soit délivré. Cette approche est particulièrement utile pour contrôler l’accès à des fichiers non-HTML comme les PDF, images et vidéos, où il n’est pas possible d’intégrer des balises meta HTML.
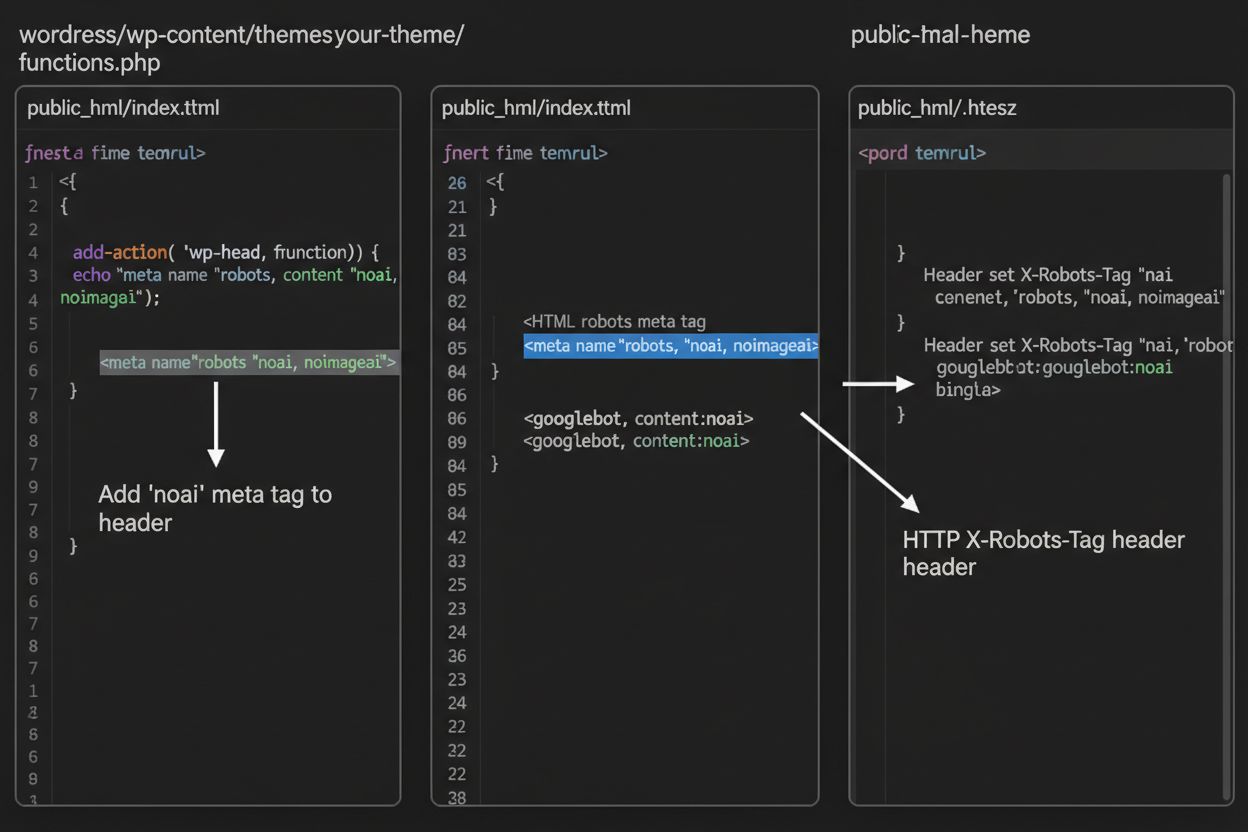
Pour les serveurs Apache, vous pouvez définir des en-têtes X-Robots-Tag dans votre fichier .htaccess :
<IfModulemod_headers.c> Header set X-Robots-Tag "noai, noimageai"</IfModule>
Pour les serveurs NGINX, ajoutez l’en-tête dans votre configuration serveur :
Les en-têtes offrent une protection globale sur l’ensemble de votre site ou sur des répertoires spécifiques, ce qui les rend idéaux pour des stratégies de contrôle d’accès IA complètes.
Comment les crawlers IA respectent (ou ignorent) ces directives
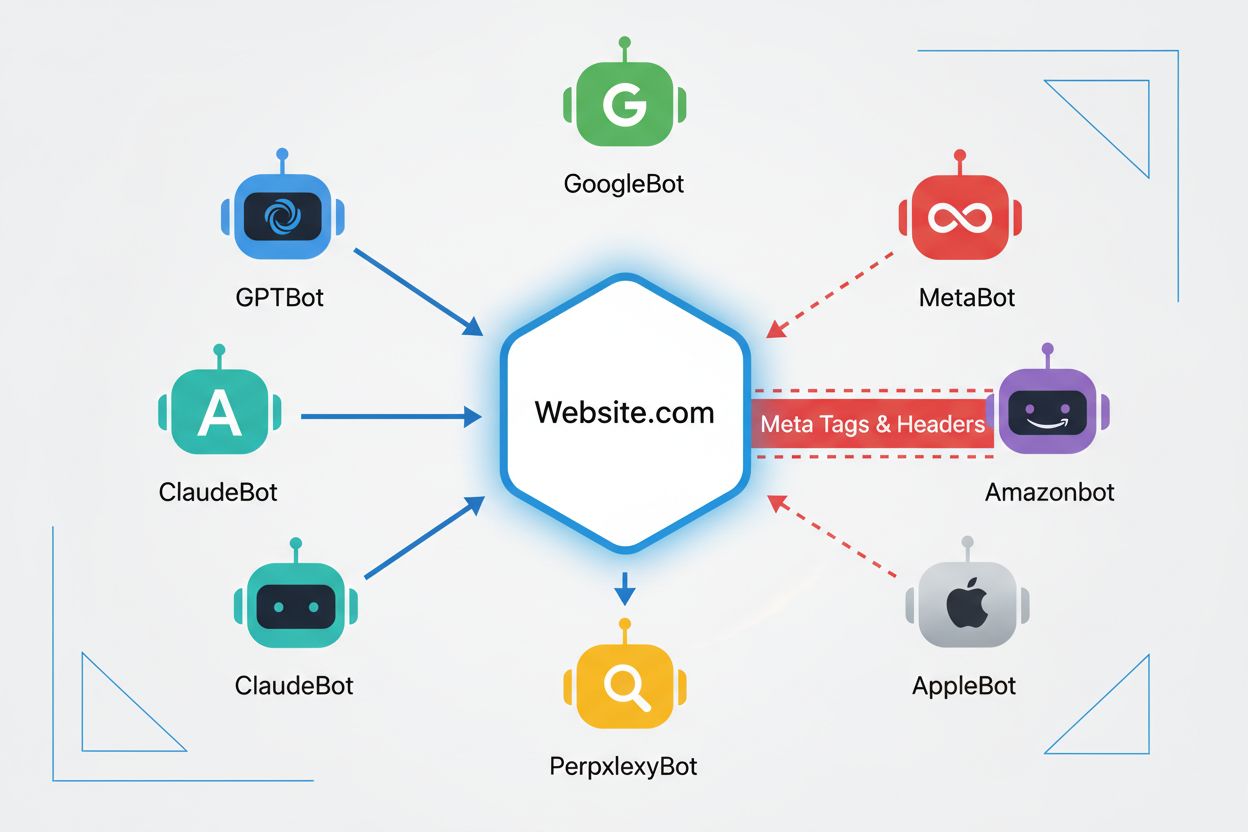
L’efficacité des balises noai et noimageai dépend entièrement du choix des crawlers de les respecter ou non. Les crawlers respectueux des grandes entreprises IA honorent généralement ces directives :
GPTBot (OpenAI) : respecte les directives noai
ClaudeBot (Anthropic) : respecte les directives noai
PerplexityBot (Perplexity) : respecte les directives noai
Amazonbot (Amazon) : respecte les directives noai
CCBot (Common Crawl) : respecte les directives noai
Petits crawlers/inconnus : peuvent ne pas respecter les directives
Cependant, les bots moins respectueux et les crawlers malveillants peuvent délibérément ignorer ces directives, car il n’existe aucun mécanisme de contrainte. Contrairement à robots.txt, que les moteurs de recherche ont accepté de respecter comme standard industriel, noai n’est pas une norme web officielle, ce qui signifie que les crawlers ne sont pas obligés de s’y conformer. C’est pourquoi les experts en sécurité recommandent une approche en couches combinant plusieurs méthodes de protection plutôt que de compter uniquement sur les balises meta.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Méthodes d’implémentation sur différentes plateformes
L’implémentation des balises noai et noimageai varie selon la plateforme de votre site. Voici des instructions étape par étape pour les plateformes les plus courantes :
1. WordPress (via functions.php)
Ajoutez ce code dans le fichier functions.php de votre thème enfant :
3. Squarespace
Allez dans Paramètres > Avancé > Injection de code, puis ajoutez dans la section Header :
<metaname="robots"content="noai, noimageai">
4. Wix
Allez dans Paramètres > Code personnalisé, cliquez sur « Ajouter du code personnalisé », collez la balise meta, sélectionnez « Head » et appliquez à toutes les pages.
Chaque plateforme offre des niveaux de contrôle différents—WordPress permet une implémentation spécifique à la page via des plugins, tandis que Squarespace et Wix proposent des options globales pour l’ensemble du site. Choisissez la méthode qui correspond le mieux à votre niveau de compétence technique et à vos besoins spécifiques.
Limites et efficacité des balises NoAI
Bien que les balises noai et noimageai représentent une avancée importante pour la protection des créateurs de contenu, elles présentent des limites significatives. Premièrement, ce ne sont pas des normes web officielles—DeviantArt les a créées comme initiative communautaire, il n’existe donc ni spécification formelle ni mécanisme de contrainte. Deuxièmement, le respect est entièrement volontaire. Les crawlers respectueux des grandes entreprises suivent généralement ces directives, mais les bots moins respectueux et les scrapers peuvent les ignorer sans conséquence. Troisièmement, l’absence de standardisation implique une adoption variable. Certaines petites entreprises d’IA et organisations de recherche peuvent même ne pas connaître ces directives, encore moins les prendre en charge. Enfin, les balises meta seules ne peuvent pas empêcher les acteurs malveillants déterminés de scraper votre contenu. Un crawler malveillant peut les ignorer complètement, ce qui rend essentielles des couches de protection supplémentaires pour une sécurité complète du contenu.
Combiner balises meta, robots.txt et autres méthodes
La stratégie de contrôle d’accès IA la plus efficace utilise plusieurs couches de protection plutôt que de s’appuyer sur une seule méthode. Voici un comparatif des différentes approches de protection :
Méthode
Portée
Efficacité
Difficulté
Balises meta (noai)
Par page
Moyenne (respect volontaire)
Facile
robots.txt
À l’échelle du site
Moyenne (avis seulement)
Facile
En-têtes X-Robots-Tag
Au niveau serveur
Moyenne-Haute (couvre tous types de fichiers)
Moyenne
Règles de pare-feu
Au niveau réseau
Élevée (blocage à l’infrastructure)
Difficile
Liste blanche d’IP
Au niveau réseau
Très élevée (sources vérifiées uniquement)
Difficile
Une stratégie complète pourrait inclure : (1) l’implémentation des balises meta noai sur toutes les pages, (2) l’ajout de règles robots.txt bloquant les crawlers IA connus, (3) la configuration d’en-têtes X-Robots-Tag au niveau serveur pour les fichiers non-HTML, et (4) la surveillance des logs serveur pour identifier les crawlers qui ignorent vos directives. Cette approche en couches complique considérablement la tâche des acteurs malveillants tout en préservant la compatibilité avec les crawlers respectueux qui suivent vos préférences.
Surveiller et vérifier la conformité des crawlers
Après avoir implémenté les balises noai et autres directives, vous devez vérifier que les crawlers respectent réellement vos règles. La méthode la plus directe consiste à consulter vos logs d’accès serveur pour détecter l’activité des crawlers. Sur les serveurs Apache, vous pouvez rechercher des crawlers spécifiques :
Si vous constatez des requêtes de crawlers que vous avez bloqués, c’est qu’ils ignorent vos directives. Pour les serveurs NGINX, consultez /var/log/nginx/access.log en utilisant la même commande grep. De plus, des outils comme Cloudflare Radar offrent une visibilité sur les schémas de trafic des crawlers IA sur votre site, montrant quels bots sont les plus actifs et comment leur comportement évolue dans le temps. Une surveillance régulière des logs—au moins mensuelle—vous aide à identifier de nouveaux crawlers et à vérifier que vos mesures de protection fonctionnent comme prévu.
L’avenir des standards de contrôle d’accès IA
Actuellement, noai et noimageai existent dans une zone grise : elles sont largement reconnues et respectées par les grandes entreprises IA, mais restent non officielles et non standardisées. Toutefois, une dynamique croissante s’oriente vers une standardisation formelle. Le W3C (World Wide Web Consortium) et divers groupes industriels discutent de la création de standards officiels pour le contrôle d’accès IA, ce qui donnerait à ces directives le même poids que des standards établis comme robots.txt. Si noai devient une norme web officielle, le respect deviendrait une pratique attendue dans l’industrie plutôt que volontaire, ce qui renforcerait considérablement son efficacité. Cet effort de standardisation reflète un changement plus large dans la manière dont l’industrie technologique envisage les droits des créateurs de contenu et l’équilibre entre le développement de l’IA et la protection des éditeurs. À mesure que de plus en plus d’éditeurs adoptent ces balises et réclament des protections plus fortes, la probabilité d’une standardisation officielle augmente, ce qui pourrait faire du contrôle d’accès IA un élément aussi fondamental de la gouvernance web que les règles d’indexation des moteurs de recherche.
Questions fréquemment posées
Qu’est-ce que la balise meta noai et comment fonctionne-t-elle ?
La balise meta noai est une directive placée dans la section head du HTML de votre site web qui indique aux crawlers IA que votre contenu ne doit pas être utilisé pour entraîner des modèles d’intelligence artificielle. Elle fonctionne en communiquant votre préférence aux bots IA respectueux, même si ce n’est pas une norme web officielle et que certains crawlers peuvent l’ignorer.
Noai est-elle une norme web officielle ?
Non, noai et noimageai ne sont pas des normes web officielles. Elles ont été créées par DeviantArt comme initiative communautaire pour aider les créateurs à protéger leur travail de l’entraînement d’IA. Cependant, de grandes entreprises IA comme OpenAI, Anthropic et d’autres ont commencé à respecter ces directives dans leurs crawlers.
Quels crawlers IA respectent la balise meta noai ?
Les principaux crawlers IA, dont GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity), Amazonbot (Amazon) et d’autres respectent la directive noai. Cependant, certains crawlers plus petits ou moins respectueux peuvent l’ignorer, d’où la recommandation d’une approche de protection en couches.
Quelle est la différence entre les balises meta et les en-têtes HTTP pour le contrôle des IA ?
Les balises meta sont placées dans la section head de votre HTML et s’appliquent aux pages individuelles, tandis que les en-têtes HTTP (X-Robots-Tag) sont définis au niveau du serveur et peuvent s’appliquer globalement ou à des types de fichiers spécifiques. Les en-têtes fonctionnent pour les fichiers non-HTML comme les PDF et les images, ce qui les rend plus polyvalents pour une protection complète.
Puis-je implémenter les balises noai sur WordPress ?
Oui, vous pouvez implémenter les balises noai sur WordPress de plusieurs façons : en ajoutant du code au fichier functions.php de votre thème, en utilisant un plugin comme WPCode, ou via des outils de page builder comme Divi et Elementor. La méthode functions.php est la plus courante et consiste à ajouter un simple hook pour injecter la balise meta dans l’en-tête de votre site.
Dois-je bloquer tous les crawlers IA ou uniquement ceux d’entraînement ?
Cela dépend de vos objectifs commerciaux. Bloquer les crawlers d’entraînement protège votre contenu de l’utilisation dans le développement de modèles IA. Cependant, bloquer les crawlers de recherche comme OAI-SearchBot peut réduire votre visibilité dans les résultats de recherche IA et les plateformes de découverte. Beaucoup d’éditeurs adoptent une approche sélective qui bloque les crawlers d’entraînement mais autorise les crawlers de recherche.
Comment vérifier si les crawlers IA respectent mes directives noai ?
Vous pouvez vérifier l’activité des crawlers dans les logs de votre serveur en utilisant des commandes comme grep pour rechercher des user agents de bots spécifiques. Des outils comme Cloudflare Radar donnent de la visibilité sur les schémas de trafic des crawlers IA. Surveillez régulièrement vos logs pour voir si des crawlers bloqués accèdent toujours à votre contenu, ce qui indiquerait qu’ils ignorent vos directives.
Que faire si des crawlers ignorent mes balises meta noai ?
Si des crawlers ignorent vos balises meta, mettez en œuvre des couches de protection supplémentaires comme des règles robots.txt, des en-têtes HTTP X-Robots-Tag, et des blocages au niveau du serveur via .htaccess ou des règles de pare-feu. Pour une vérification renforcée, utilisez la liste blanche d’IP pour n’autoriser que les requêtes provenant d’adresses IP vérifiées publiées par les principales entreprises IA.
Surveillez comment l’IA référence votre marque
Utilisez AmICited pour suivre la manière dont des systèmes IA comme ChatGPT, Perplexity et Google AI Overviews citent et référencent votre contenu sur différentes plateformes d’IA.
Comment identifier les crawlers IA dans les logs serveur : Guide complet de détection
Découvrez comment identifier et surveiller les crawlers IA comme GPTBot, PerplexityBot et ClaudeBot dans vos logs serveur. Découvrez les chaînes user-agent, les...
Quels crawlers IA dois-je autoriser ? Guide complet pour 2025
Découvrez quels crawlers IA autoriser ou bloquer dans votre robots.txt. Guide complet couvrant GPTBot, ClaudeBot, PerplexityBot et plus de 25 crawlers IA avec e...
Comment autoriser les bots IA à explorer votre site web : Guide complet robots.txt & llms.txt
Découvrez comment autoriser des bots IA comme GPTBot, PerplexityBot et ClaudeBot à explorer votre site. Configurez robots.txt, mettez en place llms.txt, et opti...
17 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.