
URL canoniques et IA : prévenir les problèmes de contenu dupliqué
Découvrez comment les URLs canoniques préviennent les problèmes de contenu dupliqué dans les systèmes de recherche IA. Découvrez les meilleures pratiques pour i...
8 min de lecture

Découvrez comment la republication de contenu crée des problèmes de contenu dupliqué qui nuisent à la visibilité dans la recherche IA bien plus sévèrement que dans la recherche traditionnelle. Découvrez les mesures techniques de protection et les bonnes pratiques.
La republication de contenu sur plusieurs canaux, plateformes et formats est une stratégie légitime et souvent nécessaire pour maximiser la portée et l’engagement. Cependant, cette pratique crée une tension fondamentale avec la façon dont les systèmes de recherche — en particulier ceux alimentés par l’IA — traitent et classent le contenu. Le défi n’est pas de savoir si vous pouvez republier, mais si vous le faites d’une manière qui ne sabote pas votre visibilité dans les résultats de recherche IA. Contrairement aux moteurs de recherche traditionnels qui ont développé des mécanismes sophistiqués de détection des doublons au fil des décennies, les systèmes d’IA abordent le contenu dupliqué différemment, créant de nouveaux risques auxquels de nombreux éditeurs ne se sont pas encore adaptés.
Selon la documentation technique de Microsoft sur Copilot et la recherche IA, « Les LLM regroupent les URL quasi-identiques dans un seul cluster et choisissent ensuite une page pour représenter l’ensemble. » Ce comportement de clustering est fondamentalement différent de la façon dont l’algorithme PageRank de Google répartit l’autorité sur les pages dupliquées. Plutôt que de consolider les signaux, les systèmes d’IA prennent une décision binaire : ils sélectionnent une page représentative dans un cluster de contenus similaires et ignorent en grande partie les autres. Ce processus de sélection n’est pas toujours prévisible ni basé sur la version que vous souhaitez voir classée. L’algorithme prend en compte des facteurs comme la fraîcheur, la qualité du contenu, les signaux techniques et l’autorité du domaine — mais la pondération de ces facteurs reste opaque. Ce qui rend cela particulièrement problématique, c’est que les systèmes d’IA peuvent sélectionner une version obsolète si les différences entre les pages sont suffisamment minimes pour que l’algorithme de clustering ne détecte pas de variations significatives.
| Aspect | Recherche traditionnelle | Recherche IA |
|---|---|---|
| Gestion des doublons | Consolide les signaux d’autorité | Regroupe et sélectionne une page représentative |
| Risque de pénalité | Action manuelle possible | Pas de pénalité, mais dilution de la visibilité |
| Reconnaissance des mises à jour | Propagation progressive des signaux | Peut ignorer les mises à jour si différences minimes |
| Efficacité du crawl | Gaspille le budget sur les doublons | Réduit la priorité d’exploration pour les doublons |
| Respect du canonique | Honoré mais non garanti | Critique pour la sélection du cluster |
La republication sans garde-fous appropriés introduit trois risques interdépendants qui affectent directement la visibilité dans l’IA :
Dilution des signaux d’intention : Lorsque le même contenu apparaît sur plusieurs URL, le système d’IA reçoit des signaux contradictoires sur la version qui répond le mieux à la requête utilisateur. Au lieu de concentrer l’autorité sur une seule URL, vos signaux se dispersent dans le cluster. Cette dilution réduit le score de confiance que l’IA attribue à votre contenu lors de la décision d’inclusion dans ses réponses. Un contenu qui aurait pu être une source principale devient un choix secondaire parce que le système ne peut déterminer avec certitude quelle version fait autorité.
Risque de représentation : La sélection par l’IA de la page qui représente votre cluster de contenu peut ne pas s’aligner sur vos objectifs business. Vous pouvez republier un article sur un réseau de syndication en espérant que cette version génère du trafic, pour que l’IA sélectionne finalement la version originale de votre domaine — ou pire, la version syndiquée qui ne renvoie pas à votre site. Ce décalage fait que votre stratégie de republication nuit activement à votre visibilité au lieu de l’amplifier.
Latence de mise à jour et obsolescence : Lorsque vous mettez à jour votre contenu original mais que les versions republiées restent inchangées, les systèmes d’IA peuvent sélectionner une version obsolète comme page représentative. L’algorithme de clustering ne reconnaît pas toujours qu’une version est plus récente ou plus exacte que d’autres, surtout si les modifications sont incrémentales et non structurelles. Cela crée une situation où votre contenu le plus récent et exact est invisible, tandis qu’une version plus ancienne représente votre expertise auprès des systèmes d’IA.
L’erreur de republication la plus fréquente se produit lorsque le contenu est syndiqué sur des plateformes tierces sans balises canoniques. Considérons un scénario typique : une société de logiciels B2B publie un guide complet sur son blog, puis le syndique à des publications comme Medium, LinkedIn et des agrégateurs spécialisés. Chaque plateforme héberge le contenu identique sous des URL différentes. Sans balises canoniques pointant vers l’original, l’algorithme de clustering de l’IA traite toutes les versions comme également autoritaires. La plateforme de syndication peut avoir une autorité de domaine supérieure, poussant l’IA à sélectionner cette version comme page représentative. Votre contenu original — celui que vous avez optimisé, mis à jour et valorisé par des backlinks — devient alors invisible dans les résultats IA. Le trafic et l’autorité sont transférés à la plateforme de syndication au lieu de votre propre site. Ce scénario se répète chaque jour des milliers de fois dans l’industrie, avec des éditeurs sapant leur propre visibilité faute d’implémenter une simple balise HTML.
Le contenu spécifique à une campagne pose un problème particulièrement insidieux de duplication lorsqu’il est republié sur différents canaux. Une équipe marketing lance une page de campagne optimisée pour une promotion particulière, puis republie des variantes dans des newsletters, sur les réseaux sociaux, en publicité payante et sur des sites partenaires. Chaque version contient un texte, des CTA ou une mise en forme légèrement différente — mais le fond et l’intention restent identiques. Les systèmes d’IA les reconnaissent comme quasi-duplicatas et les regroupent. Le problème s’aggrave lorsque ces pages de campagne sont republiées sans canonique adéquat. Le système d’IA peut sélectionner la version newsletter (sans suivi de conversion) comme page représentative, ou la version du site partenaire qui ne bénéficie pas à vos métriques. De plus, lorsque les campagnes se terminent et que les pages sont archivées ou supprimées, l’IA peut avoir déjà sélectionné une version désormais non disponible, rendant votre contenu invisible ou menant les utilisateurs vers des expériences brisées.
La republication régionale complexifie la détection des doublons car il faut prendre en compte les besoins légitimes de localisation. Une entreprise opérant dans plusieurs pays peut publier le même contenu de base dans différentes langues ou avec des variantes régionales. Sans implémentation adaptée, ces versions régionales se concurrencent dans le clustering IA. Par exemple, une société SaaS publie un guide en anglais sur son domaine US, puis le republie sur son domaine UK avec orthographe britannique et tarifs adaptés. Le système d’IA regroupe ces versions comme doublons et peut sélectionner la version US même pour les utilisateurs britanniques. La solution consiste à implémenter des balises hreflang signalant les relations régionales aux systèmes IA, bien que l’efficacité du hreflang dans la recherche IA reste moins établie que dans la recherche traditionnelle.
<!-- Sur la version US (example.com/feature-guide) -->
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
<!-- Sur la version UK (example.co.uk/feature-guide) -->
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
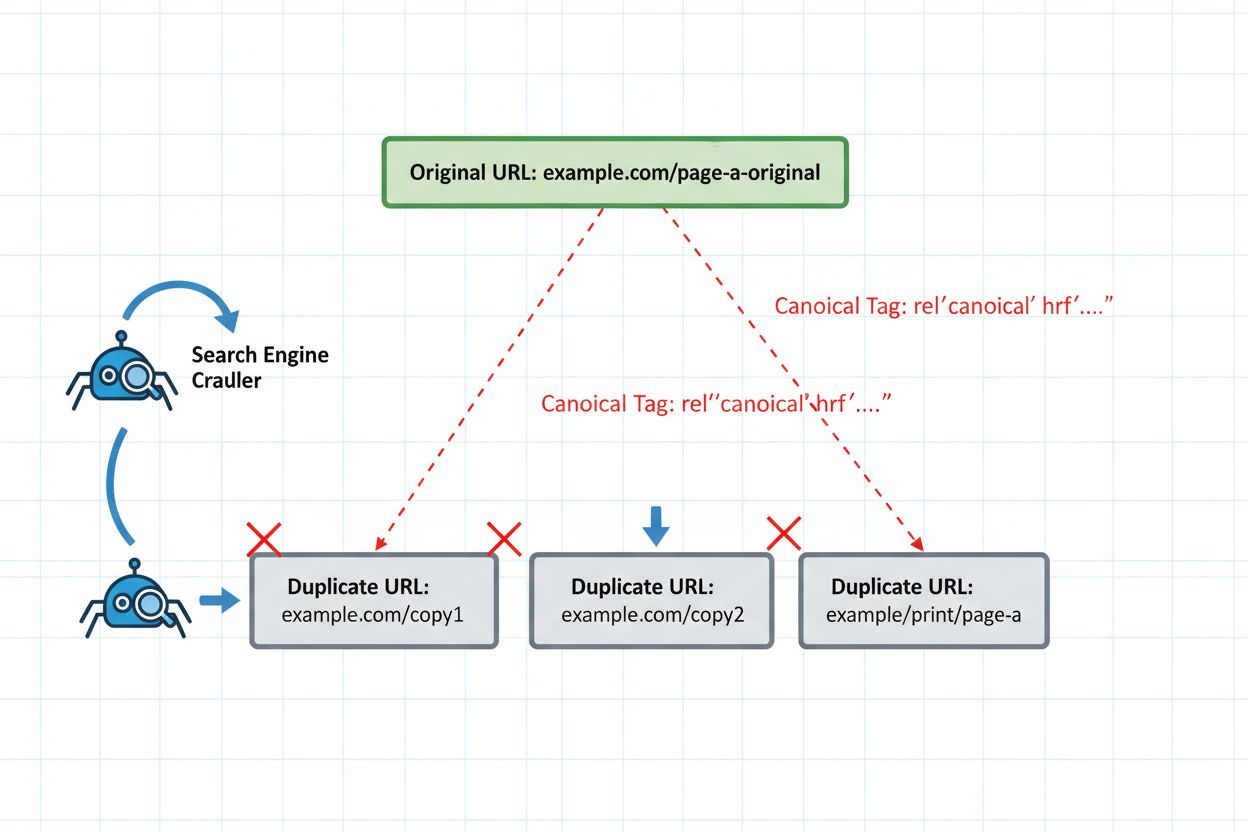
La mise en œuvre de garde-fous techniques adaptés est incontournable pour republier sans risque. La balise canonique reste votre principale défense, indiquant explicitement aux systèmes IA quelle version doit représenter votre cluster de contenu. Placez la balise canonique dans la section <head> de chaque version republiée, en pointant vers votre version faisant autorité. Pour le contenu syndiqué, cela signifie généralement un lien vers votre domaine d’origine.
<!-- Sur la version syndiquée (medium.com/your-publication/article) -->
<link rel="canonical" href="https://yoursite.com/blog/article" />
Pour le contenu qui ne doit jamais être en concurrence avec d’autres versions, implémentez noindex sur les versions secondaires. Cela les retire complètement de l’indexation IA, garantissant qu’elles ne peuvent pas être sélectionnées comme pages représentatives. Utilisez cette méthode pour les pages internes dupliquées, les versions de test, ou le contenu syndiqué dont vous ne voulez aucune visibilité IA.
<!-- Sur une version secondaire qui ne doit pas être indexée -->
<meta name="robots" content="noindex, follow" />
Les redirections 301 offrent le signal le plus fort pour la consolidation d’autorité, mais ne les utilisez que lorsque la version secondaire ne sera jamais mise à jour indépendamment. Les redirections indiquent aux systèmes IA que l’ancienne URL a été déplacée définitivement, consolidant tous les signaux vers la nouvelle adresse. Toutefois, si vous devez maintenir les deux versions actives (comme pour la syndication), les redirections peuvent poser problème car elles cassent la structure d’URL de la plateforme de syndication.
# Dans .htaccess ou la configuration du serveur
Redirect 301 /old-article https://yoursite.com/new-article
Pour les systèmes de gestion de contenu, implémentez rel=“canonical” dynamiquement pour gérer la pagination, les variations de paramètres et les URL de session qui créent des doublons involontaires. De nombreux CMS génèrent plusieurs URL pour le même contenu via différents chemins de navigation — les balises canoniques consolident cela automatiquement.
IndexNow accélère la prise en compte des signaux canoniques et la consolidation des doublons, réduisant ce qui prenait traditionnellement des semaines à quelques jours. Lorsque vous ajoutez des balises canoniques à du contenu republié, IndexNow notifie immédiatement les moteurs de recherche que ces URL doivent être regroupées. Plutôt que d’attendre que les robots découvrent la relation canonique lors de l’exploration, IndexNow transmet cette information directement à l’index de Microsoft et aux autres systèmes participants. Cela est particulièrement précieux lorsque vous corrigez des erreurs de republication a posteriori — vous pouvez implémenter les balises canoniques et utiliser IndexNow pour signaler le changement immédiatement, sans attendre que les robots revisitent les pages. Pour les éditeurs gérant du contenu sur plusieurs plateformes, IndexNow devient un outil critique pour garder le contrôle sur la version représentant votre cluster de contenu. L’API permet la soumission en masse d’URL, ce qui le rend pratique pour gérer des centaines ou milliers de pages republiées.
POST https://api.indexnow.org/indexnow
{
"host": "yoursite.com",
"key": "your-api-key",
"keyLocation": "https://yoursite.com/indexnow-key.txt",
"urlList": [
"https://yoursite.com/blog/article-1",
"https://yoursite.com/blog/article-2"
]
}
Identifier la version de votre contenu republié sélectionnée par les systèmes d’IA nécessite un suivi qui va au-delà de l’analytique classique. Mettez en place un suivi pour détecter quand les systèmes d’IA citent ou référencent votre contenu, en notant quelle URL apparaît dans les résultats IA. Des outils comme Semrush, Ahrefs ou Moz commencent à intégrer des métriques de visibilité IA, bien qu’elles soient moins matures que pour la recherche classique. Ajoutez des paramètres UTM sur les versions syndiquées pour suivre l’attribution du trafic, tout en sachant que les systèmes IA peuvent ne pas transmettre ces paramètres, rendant l’attribution directe difficile. Surveillez votre Search Console (ou équivalent) pour repérer les schémas d’exploration — si les versions secondaires sont explorées plus fréquemment que votre canonique, cela indique que l’IA a pu sélectionner la mauvaise page représentative. Configurez des alertes pour les mentions de votre contenu sur les plateformes de syndication et croisez-les avec votre visibilité IA afin de déceler un éventuel décalage entre l’endroit où votre contenu apparaît et la version sélectionnée par l’IA.
Appliquez cette checklist avant toute republication de contenu pour conserver la maîtrise de votre visibilité IA :
Avant de republier, identifiez votre version canonique — l’URL que vous souhaitez voir représenter ce contenu dans les résultats IA. Il s’agit généralement de votre propre domaine, pas d’une plateforme de syndication. Implémentez des balises canoniques sur chaque version republiée, pointant vers votre URL canonique, même si vous republiez sur vos propres propriétés (domaines, sous-domaines ou variations de paramètres). Utilisez IndexNow pour notifier immédiatement les moteurs de la relation canonique, sans attendre la découverte par crawl. Évitez de republier sur des plateformes à forte autorité sans prise en charge du canonique — certaines retirent ou n’autorisent pas cette balise, ce qui les rend inadaptées à la republication sans accepter une perte de visibilité. Surveillez les 48 premières heures suivant la republication pour vérifier que les systèmes IA sélectionnent bien la version canonique souhaitée. Mettez à jour toutes les versions simultanément lors de modifications — si vous ne mettez à jour que la canonique, l’algorithme de clustering pourrait ne pas reconnaître la mise à jour sur l’ensemble des versions, ce qui risque de faire sélectionner une version obsolète par l’IA. Établissez un calendrier de republication pour éviter que le contenu ne devienne obsolète sur les plateformes secondaires ; un contenu syndiqué dépassé augmente le risque que l’IA le sélectionne comme version représentative si votre canonique n’a pas été actualisée récemment.
Les balises canoniques n'empêchent pas les sanctions car le contenu dupliqué n'entraîne pas de sanctions à la base. Cependant, les balises canoniques sont essentielles pour la recherche IA car elles indiquent aux systèmes d'IA quelle version doit représenter votre cluster de contenu. Sans balises canoniques, les systèmes d'IA peuvent sélectionner une version non souhaitée comme source d'autorité, réduisant ainsi votre visibilité.
Surveillez quelles URL apparaissent dans les résultats de recherche IA et dans les citations de votre contenu. Des outils comme Semrush et Ahrefs ajoutent des métriques de visibilité dans la recherche IA. Consultez votre Search Console pour repérer les schémas d'exploration — si des versions secondaires sont explorées plus souvent que votre version canonique, le système d'IA a peut-être sélectionné la mauvaise page.
Techniquement oui, mais ce n'est pas recommandé. Sans balises canoniques, les systèmes d'IA regrouperont votre contenu et sélectionneront une version comme représentative — mais vous ne contrôlerez pas laquelle. La plateforme de syndication pourrait avoir une autorité supérieure, ce qui pousserait l'IA à sélectionner cette version au lieu de celle de votre domaine d'origine.
La republication fait généralement référence à la distribution de votre contenu sur plusieurs canaux que vous contrôlez ou avec lesquels vous êtes partenaire. La syndication de contenu est une forme spécifique de republication où des plateformes tierces republient votre contenu avec votre accord. Les deux créent des problèmes de contenu dupliqué si elles ne sont pas correctement gérées avec des balises canoniques.
Les balises canoniques sont généralement reconnues en 24 à 48 heures si vous utilisez IndexNow pour notifier immédiatement les systèmes de recherche. Sans IndexNow, il peut s'écouler plusieurs semaines avant que les robots découvrent la relation canonique. C'est pourquoi IndexNow est essentiel pour la gestion du contenu republié — il accélère considérablement le processus.
Utilisez des redirections 301 uniquement lorsque vous souhaitez consolider définitivement des URL et que la version secondaire ne sera jamais mise à jour indépendamment. Utilisez des balises canoniques lorsque les deux versions doivent rester en ligne (comme pour la syndication). Les redirections sont des signaux plus forts mais coupent le fonctionnement de l'URL secondaire.
Oui, si elle n'est pas correctement gérée. La republication sans balises canoniques dilue vos signaux d'autorité sur plusieurs URL. Les systèmes d'IA peuvent sélectionner la version syndiquée au lieu de votre version originale, réduisant ainsi la visibilité sur votre propre domaine. Une mise en œuvre correcte des balises canoniques évite cela.
Implémentez des balises canoniques sur chaque version republiée en pointant vers votre domaine d'origine. Utilisez IndexNow pour informer immédiatement les systèmes de recherche de la relation canonique. Évitez de republier sur des plateformes qui ne prennent pas en charge les balises canoniques. Surveillez la version sélectionnée par les systèmes d'IA dans les 48 premières heures et ajustez si nécessaire.
Suivez la façon dont les systèmes d'IA citent et référencent votre contenu republié sur toutes les plateformes. Obtenez des informations en temps réel sur la version qu'une IA sélectionne comme source faisant autorité.
Découvrez comment les URLs canoniques préviennent les problèmes de contenu dupliqué dans les systèmes de recherche IA. Découvrez les meilleures pratiques pour i...

Discussion communautaire sur la manière dont les systèmes d'IA traitent le contenu dupliqué différemment des moteurs de recherche traditionnels. Les professionn...
Découvrez comment réutiliser et optimiser votre contenu pour les plateformes d’IA comme ChatGPT, Perplexity et Claude. Apprenez des stratégies pour la visibilit...