
Accès différentiel aux crawlers
Découvrez comment autoriser ou bloquer sélectivement les crawlers IA en fonction des objectifs commerciaux. Mettez en œuvre un accès différentiel aux crawlers p...
10 min de lecture

Découvrez comment utiliser robots.txt pour contrôler quels bots d’IA accèdent à votre contenu. Guide complet pour bloquer GPTBot, ClaudeBot et d’autres crawlers IA avec des exemples pratiques et des stratégies de configuration.
Le paysage du crawling web a fondamentalement changé ces deux dernières années, dépassant le simple cadre de l’indexation des moteurs de recherche pour entrer dans le monde complexe de l’entraînement des modèles d’IA. Alors que le Googlebot de Google était depuis longtemps un visiteur prévisible des sites éditeurs, une nouvelle génération de crawlers arrive désormais avec des intentions et des modes de consommation radicalement différents. Le GPTBot d’OpenAI présente un ratio crawl-to-refer d’environ 1 700:1, ce qui signifie qu’il explore 1 700 pages pour ne générer qu’une seule redirection vers votre site, tandis que le ClaudeBot d’Anthropic fonctionne à un ratio encore plus extrême de 73 000:1—bien loin du ratio de 14:1 de Google où l’activité de crawling se traduit par un trafic significatif. Cette différence fondamentale crée une décision commerciale urgente pour les créateurs de contenu : autoriser ces bots à accéder librement à votre contenu, c’est permettre à vos données d’entraîner des modèles d’IA qui concurrencent votre trafic et vos revenus, alors que votre site reçoit peu de compensation ou de trafic en retour. Les éditeurs doivent désormais décider activement si la proposition de valeur de l’accès des bots d’IA correspond à leur modèle économique, faisant de la configuration de robots.txt non seulement une considération technique mais un impératif stratégique.
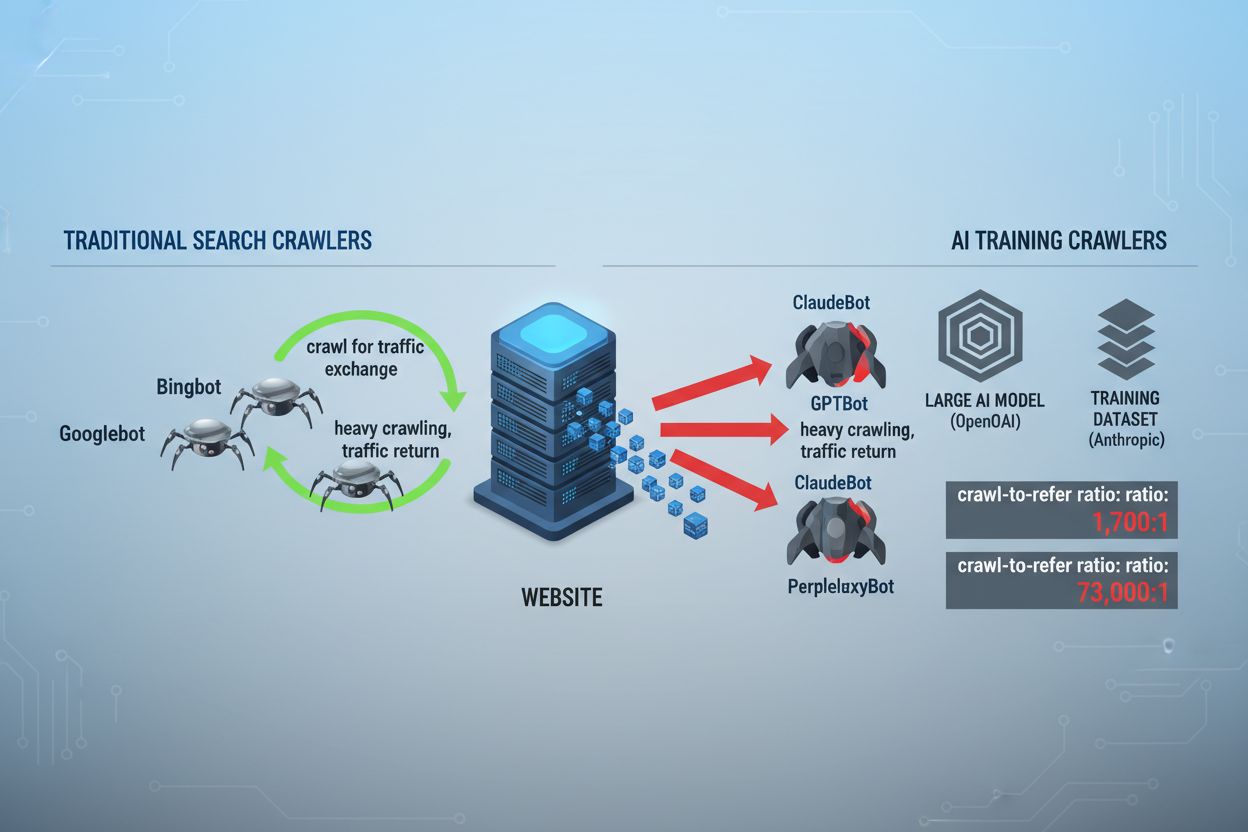
Les crawlers IA opèrent selon trois grandes catégories, chacune ayant des objectifs différents et nécessitant des stratégies de blocage distinctes. Les crawlers d’entraînement sont conçus pour ingérer de grands volumes de contenu afin d’entraîner des modèles d’IA fondamentaux : cela inclut GPTBot d’OpenAI, ClaudeBot d’Anthropic, Google-Extended de Google, PerplexityBot de Perplexity, Meta-ExternalAgent de Meta, Applebot-Extended d’Apple, ainsi que de nouveaux acteurs comme Amazonbot, Bytespider et cohere-ai. Les crawlers de recherche, à l’inverse, servent à alimenter les expériences de recherche IA et renvoient en général du trafic aux éditeurs ; cela inclut OAI-SearchBot d’OpenAI, Claude-Web d’Anthropic, et la fonction de recherche de Perplexity. Les agents déclenchés par l’utilisateur forment une troisième catégorie où le contenu est consulté à la demande lorsqu’un utilisateur sollicite explicitement une information, par exemple via ChatGPT-User ou Claude-Web via une action directe de l’utilisateur final. Comprendre cette taxonomie est essentiel car votre stratégie de blocage doit refléter vos priorités business : vous pouvez accueillir les crawlers de recherche qui génèrent du trafic de référence tout en bloquant les crawlers d’entraînement qui consomment le contenu sans compensation. Chaque grande société d’IA maintient sa propre flotte de crawlers spécialisés, et la différence entre eux repose souvent sur la chaîne user-agent utilisée, ce qui rend l’identification précise et le blocage ciblé essentiels pour une configuration robots.txt efficace.
| Entreprise | Crawler d’entraînement | Crawler de recherche | Agent déclenché par l’utilisateur |
|---|---|---|---|
| OpenAI | GPTBot | OAI-SearchBot | ChatGPT-User |
| Anthropic | ClaudeBot, anthropic-ai | Claude-Web | claude-web |
| Google-Extended | — | (Utilise Googlebot standard) | |
| Perplexity | PerplexityBot | PerplexityBot | Perplexity-User |
| Meta | Meta-ExternalAgent | — | Meta-ExternalFetcher |
| Apple | Applebot-Extended | — | Applebot |
Maintenir une liste précise et à jour des user-agents des bots IA est essentiel pour une configuration robots.txt efficace, mais cet environnement évolue rapidement à mesure que de nouveaux modèles sont lancés et que les entreprises ajustent leurs stratégies de crawling. Les principaux crawlers d’entraînement à connaître incluent GPTBot (crawler d’entraînement principal d’OpenAI), ClaudeBot (Anthropic), anthropic-ai (identifiant alternatif d’Anthropic), Google-Extended (jeton IA de Google), PerplexityBot (Perplexity), Meta-ExternalAgent (Meta), Applebot-Extended (Apple), CCBot (Common Crawl), Amazonbot (Amazon), Bytespider (ByteDance), cohere-ai (Cohere), DuckAssistBot (assistant IA de DuckDuckGo), et YouBot (You.com). Les crawlers orientés recherche qui génèrent généralement du trafic incluent OAI-SearchBot, Claude-Web, et PerplexityBot en mode recherche. Le défi majeur est que cette liste n’est pas statique—de nouvelles entreprises IA émergent régulièrement, les sociétés existantes lancent de nouveaux crawlers pour de nouveaux produits, et les chaînes user-agent changent ou s’étendent parfois. Les éditeurs doivent considérer leur robots.txt comme un document vivant nécessitant une révision et une mise à jour trimestrières, en s’abonnant aux ressources sectorielles de veille ou en surveillant les logs serveur pour détecter des user-agents inconnus qui pourraient signaler l’arrivée de nouveaux crawlers IA. Ne pas maintenir à jour votre liste de user-agents signifie risquer d’autoriser accidentellement de nouveaux crawlers d’entraînement que vous souhaitiez bloquer, ou de bloquer inutilement des crawlers légitimes pouvant générer un trafic précieux.
Le fichier robots.txt, situé à la racine de votre domaine (votredomaine.com/robots.txt), utilise une syntaxe simple pour communiquer vos préférences de crawling aux bots qui respectent le protocole. Chaque règle commence par une directive User-Agent spécifiant à quel bot elle s’applique, suivie d’une ou plusieurs directives Disallow indiquant les chemins auxquels le bot ne peut accéder. Pour bloquer tous les principaux crawlers d’entraînement IA tout en préservant l’accès aux moteurs de recherche traditionnels, créez des blocs User-Agent séparés pour chaque crawler d’entraînement à exclure : GPTBot, ClaudeBot, anthropic-ai, Google-Extended, PerplexityBot, Meta-ExternalAgent, Applebot-Extended, etc., chacun avec une directive “Disallow: /” empêchant le crawling de tout le site. En parallèle, assurez-vous que les crawlers de recherche légitimes comme Googlebot, Bingbot, ou des variantes orientées recherche comme OAI-SearchBot restent autorisés, afin qu’ils continuent à indexer votre contenu et à générer du trafic. Un fichier robots.txt correctement configuré doit également inclure une référence au Sitemap XML pour aider les moteurs de recherche à découvrir et indexer efficacement votre contenu. L’importance d’une configuration correcte est capitale : une simple erreur de syntaxe, un caractère mal placé ou un user-agent incorrect peut rendre votre stratégie de blocage inefficace, en laissant passer des crawlers indésirables tout en risquant de bloquer des sources de trafic légitimes. Tester votre configuration avant le déploiement n’est donc pas optionnel mais essentiel pour s’assurer que votre robots.txt remplit bien son rôle.
# Bloquer les crawlers d'entraînement IA
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: DuckAssistBot
Disallow: /
User-agent: YouBot
Disallow: /
# Autoriser les moteurs de recherche traditionnels
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Référence sitemap
Sitemap: https://yoursite.com/sitemap.xml
De nombreux éditeurs doivent prendre une décision nuancée : ils souhaitent rester visibles dans les résultats de recherche IA et bénéficier du trafic généré par ces plateformes, mais ils veulent empêcher que leur contenu ne soit utilisé pour entraîner des modèles IA concurrents. Cette stratégie de blocage sélectif implique de distinguer entre les crawlers de recherche et d’entraînement d’une même entreprise—par exemple, autoriser OAI-SearchBot d’OpenAI (qui alimente la recherche ChatGPT et renvoie du trafic) tout en bloquant GPTBot (qui entraîne le modèle sous-jacent). De même, vous pouvez autoriser le crawler de recherche de Perplexity tout en bloquant ses opérations d’entraînement, ou autoriser Claude-Web pour les recherches déclenchées par l’utilisateur tout en bloquant les activités d’entraînement de ClaudeBot. L’argument commercial est clair : les crawlers de recherche opèrent généralement avec des ratios crawl-to-refer bien plus faibles car ils sont conçus pour générer du trafic de retour, alors que les crawlers d’entraînement consomment le contenu à très grande échelle avec peu de bénéfices réciproques. Cette approche nécessite une configuration attentive et une surveillance continue, car les entreprises modifient parfois leurs stratégies de crawling ou introduisent de nouveaux user-agents qui brouillent la frontière entre recherche et entraînement. Les éditeurs adoptant cette stratégie doivent auditer régulièrement leurs logs serveur pour vérifier que les crawlers souhaités accèdent bien au contenu et que les bots bloqués sont effectivement exclus, en ajustant leur robots.txt au rythme de l’évolution du secteur IA et de l’arrivée de nouveaux acteurs.
# Autoriser les crawlers IA de recherche
User-agent: OAI-SearchBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: ChatGPT-User
Allow: /
# Bloquer les crawlers d'entraînement
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
Même les webmasters expérimentés commettent souvent des erreurs de configuration qui ruinent complètement leur stratégie robots.txt, exposant leur contenu aux crawlers qu’ils voulaient bloquer. La première erreur fréquente consiste à créer des lignes User-Agent seules sans directive Disallow correspondante—par exemple, écrire “User-Agent: GPTBot” sur une ligne puis commencer immédiatement une nouvelle règle sans préciser ce que GPTBot ne doit pas consulter, ce qui laisse le bot totalement autorisé. La deuxième erreur concerne l’emplacement, le nom ou la casse du fichier ; il doit impérativement s’appeler “robots.txt” (en minuscules), être à la racine du domaine et renvoyer un code HTTP 200—le placer dans un sous-répertoire ou le nommer “Robots.txt” ou “robots.TXT” le rend invisible pour les crawlers. La troisième erreur est d’insérer des lignes vides dans un bloc de règles, ce que de nombreux parseurs robots.txt interprètent comme la fin de la règle, rendant les directives suivantes inopérantes ou mal appliquées. La quatrième erreur touche à la sensibilité à la casse des chemins d’URL : bien que les noms de user-agent ne soient pas sensibles à la casse, les chemins dans Disallow le sont, donc “Disallow: /Admin” ne bloquera pas “/admin” ou “/ADMIN”. La cinquième erreur est une mauvaise utilisation des jokers (*) : l’astérisque correspond à toute séquence de caractères, mais beaucoup écrivent “Disallow: .pdf” alors qu’il faudrait “Disallow: /.pdf” ou “Disallow: /*pdf” pour bien bloquer les extensions. Enfin, certains éditeurs créent des règles trop complexes avec de multiples Disallow contradictoires, ou oublient de prendre en compte les paramètres d’URL et chaînes de requête, ce qui peut bloquer du contenu légitime ou laisser accessible du contenu sensible. Tester votre configuration avec des validateurs robots.txt dédiés avant déploiement permet de corriger ces erreurs en amont et d’assurer la crawlabilité souhaitée.
Erreurs courantes à éviter :
Google-Extended représente un cas unique dans la configuration robots.txt, car il fonctionne comme un jeton de contrôle plutôt que comme un crawler traditionnel, et comprendre cette nuance est essentiel pour prendre les bonnes décisions de blocage. Contrairement à Googlebot, qui explore votre site pour indexer le contenu pour la recherche Google, Google-Extended est un signal qui contrôle si votre contenu peut être utilisé pour entraîner les modèles Gemini IA de Google et alimenter la fonction AI Overviews dans les résultats de recherche. Bloquer Google-Extended empêche l’utilisation de votre contenu pour l’entraînement Gemini et la génération de AI Overview, mais n’affecte pas votre visibilité dans les résultats Google standard—Googlebot continuera d’indexer normalement. Le compromis est important : bloquer Google-Extended signifie que votre contenu n’apparaîtra pas dans les AI Overviews, qui deviennent de plus en plus présents sur Google et peuvent générer du trafic, mais vous protégez votre contenu de l’entraînement d’un modèle concurrent. À l’inverse, autoriser Google-Extended permet à votre contenu d’apparaître dans les AI Overviews (potentiellement source de trafic) mais contribue aussi à l’entraînement de Gemini, qui pourrait concurrencer votre contenu ou votre modèle économique. Les éditeurs doivent bien analyser leur situation—les médias et créateurs dont le business dépend du trafic direct peuvent avoir intérêt à bloquer Google-Extended, d’autres privilégieront la visibilité et le trafic potentiel générés par l’IA. Cette décision doit être prise intentionnellement et non par défaut, car elle a un impact majeur sur votre visibilité et vos flux de trafic sur Google.
Tester votre configuration robots.txt avant déploiement en production est absolument crucial, car une erreur peut avoir de lourdes conséquences sur votre visibilité et votre stratégie de protection du contenu. Google Search Console propose un testeur robots.txt intégré permettant de vérifier si des user-agents spécifiques peuvent accéder à certaines URLs de votre site—vous pouvez saisir une chaîne user-agent comme “GPTBot” et un chemin d’URL, et Google vous indiquera si ce bot est autorisé ou bloqué selon votre configuration. Le Merkle Robots.txt Tester offre des fonctionnalités similaires avec une interface conviviale et des explications détaillées sur l’interprétation de vos règles. TechnicalSEO.com propose aussi un outil gratuit validant la syntaxe robots.txt et affichant comment sont traités différents bots. Pour une surveillance plus poussée, Knowatoa AI Search Console propose des outils spécialisés pour suivre l’activité des crawlers IA et valider votre configuration face aux bots que vous souhaitez bloquer. Votre workflow de validation doit inclure le téléchargement de votre robots.txt sur un environnement de staging, puis la vérification que les pages critiques restent accessibles, que les bots IA ciblés sont effectivement exclus, et la surveillance des logs pour détecter toute activité inattendue. Cette étape doit aussi inclure la vérification de la référence au sitemap et que les moteurs de recherche accèdent toujours normalement à votre contenu—vous souhaitez bloquer les crawlers d’entraînement IA sans risquer de bloquer du trafic légitime. N’effectuez le déploiement en production qu’après des tests approfondis, et continuez à surveiller vos logs la première semaine pour détecter tout problème imprévu.
Outils de test :
Bien que robots.txt soit une première ligne de défense utile, il fonctionne sur la base de la confiance—les bots respectueux suivent vos directives, mais les crawlers malveillants ou mal conçus peuvent ignorer robots.txt et accéder malgré tout à votre contenu. Les données du secteur indiquent que robots.txt bloque environ 40 à 60 % du trafic crawler indésirable, ce qui signifie que 40 à 60 % des bots contournent ou ignorent le protocole. Pour les éditeurs nécessitant une protection renforcée, il faut ajouter d’autres couches défensives. Le pare-feu applicatif de Cloudflare (WAF) permet de créer des règles bloquant le trafic selon user-agent, adresses IP ou comportements, protégeant ainsi contre les bots qui ignorent robots.txt. Des outils serveur comme .htaccess (Apache) ou équivalents Nginx peuvent bloquer certains user-agents ou plages IP avant même que la requête n’atteigne votre application. Le blocage IP peut être efficace si vous identifiez les plages utilisées par certains crawlers, mais cela demande un suivi car leur infrastructure évolue. Fail2ban ou outils similaires bloquent automatiquement les IP au comportement suspect (ex. nombre de requêtes anormal, accès à des chemins sensibles). Cependant, ces protections complémentaires doivent être configurées avec soin : un blocage trop agressif peut exclure du trafic légitime, y compris des utilisateurs réels passant par des VPN ou proxies d’entreprise partageant des IP avec des crawlers connus. L’approche la plus efficace combine robots.txt comme première demande courtoise, le blocage user-agent au niveau serveur pour les bots qui l’ignorent, et une surveillance comportementale pour détecter les crawlers sophistiqués qui usurpent des user-agents ou utilisent des IP distribuées. Les éditeurs doivent mettre en place ces couches progressivement, en testant chaque étape pour éviter de bloquer accidentellement du trafic légitime tout en atteignant leurs objectifs de protection du contenu.
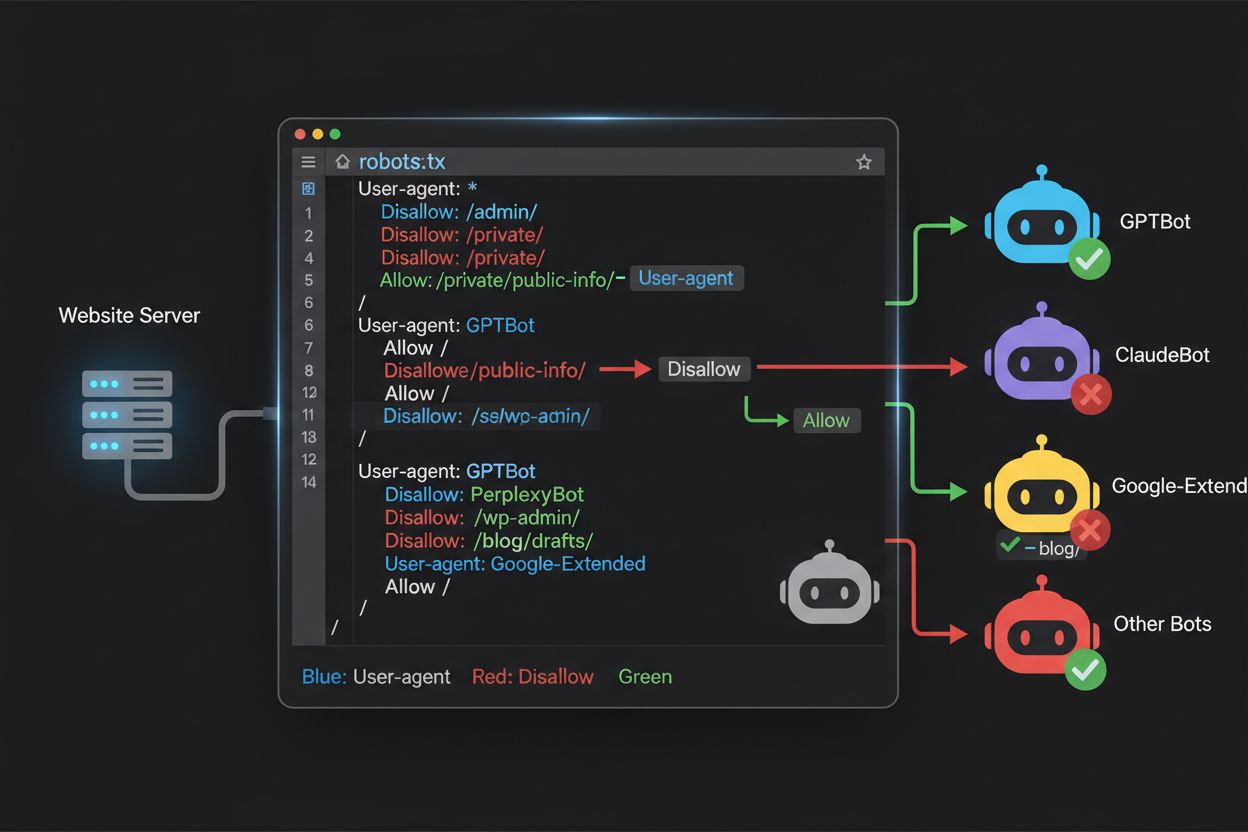
Comprendre ce qui accède réellement à votre site est essentiel pour valider l’efficacité de votre robots.txt et pour identifier de nouveaux crawlers à bloquer. L’analyse des logs serveur est la méthode principale pour ce suivi—vos logs web (Apache, Nginx, etc.) contiennent l’historique précis de chaque requête, incluant le user-agent, l’adresse IP, l’horodatage et la ressource demandée. Vous pouvez utiliser des outils en ligne de commande comme grep pour rechercher des user-agents spécifiques ; par exemple, “grep ‘GPTBot’ /var/log/apache2/access.log” affichera toutes les requêtes de GPTBot, vous permettant de vérifier si vos règles de blocage fonctionnent. Une analyse plus poussée peut consister à calculer les taux de crawl par bot, les pages consultées, et le respect ou non de vos directives robots.txt. Des solutions automatisées peuvent analyser en continu vos logs et vous alerter en cas d’apparition de crawlers inattendus, ce qui est particulièrement utile vu la rapidité d’évolution du paysage IA. Certains éditeurs utilisent des plateformes d’agrégation de logs comme ELK Stack, Splunk ou des solutions cloud pour centraliser et analyser l’activité crawler sur plusieurs serveurs. L’évolution rapide des crawlers IA implique que la surveillance n’est pas une tâche ponctuelle mais un devoir permanent : de nouveaux bots émergent souvent, les user-agents changent, et le comportement des crawlers évolue selon les stratégies des sociétés IA. Mettre en place une routine de vérification régulière (hebdomadaire ou mensuelle) vous permet d’anticiper les évolutions et d’adapter votre robots.txt de manière proactive, avant de subir les conséquences d’un problème.
Votre configuration robots.txt pour les crawlers IA est avant tout une décision de revenu, et mérite la même attention stratégique que toute décision business à fort impact financier. Autoriser librement les crawlers d’entraînement à accéder à votre contenu, c’est accepter que des modèles IA entraînés sur vos données finissent par concurrencer votre trafic et vos revenus—si votre modèle économique dépend du trafic direct, de la visibilité en recherche ou de la publicité, vous fournissez gratuitement des données d’entraînement à des concurrents potentiels. À l’inverse, bloquer tous les crawlers IA, c’est renoncer à la visibilité dans les résultats de recherche IA et au trafic de référence généré par les assistants IA, ce qui représente une part croissante de la découverte de contenu. La meilleure stratégie dépend de votre modèle : les éditeurs financés par la publicité peuvent autoriser les crawlers de recherche (générant du trafic et des impressions) tout en bloquant ceux d’entraînement (qui ne renvoient rien). Les éditeurs par abonnement peuvent bloquer la plupart des bots pour protéger leur contenu de la synthèse ou duplication IA. Les marques axées sur la notoriété peuvent rechercher la visibilité IA comme canal de distribution. L’essentiel est de faire ce choix de façon intentionnelle, non par défaut—nombre d’éditeurs n’ont jamais configuré leur robots.txt pour les crawlers IA, laissant ainsi tout passer, ce qui revient à offrir leur contenu pour l’entraînement IA sans l’avoir vraiment décidé. Pensez aussi à implémenter du balisage schema pour garantir une attribution correcte lorsque votre contenu est utilisé par des systèmes IA, afin de favoriser le trafic et le crédit vers votre site même lorsqu’il est référencé par des assistants IA. Votre configuration robots.txt doit refléter votre stratégie business, révisée et mise à jour régulièrement au fil de l’évolution du secteur IA et de vos priorités.
Le paysage des crawlers IA évolue à une vitesse inédite : de nouvelles entreprises lancent des produits IA, les acteurs existants introduisent de nouveaux crawlers, et les chaînes user-agent changent ou s’étendent régulièrement. Votre robots.txt ne doit pas être un fichier figé mais un document vivant, à revoir et mettre à jour au moins chaque trimestre. Mettez en place un suivi des annonces sectorielles sur les nouveaux crawlers IA, abonnez-vous à des newsletters ou blogs spécialisés, et auditez régulièrement vos logs serveur pour identifier les user-agents inconnus signalant l’arrivée de nouveaux bots. Lorsqu’un nouveau crawler est détecté, renseignez-vous sur son usage et son modèle économique pour décider s’il correspond à votre stratégie de protection, puis mettez à jour votre robots.txt en conséquence. Surveillez aussi l’efficacité de votre configuration en suivant des métriques comme le volume de trafic crawler, le ratio requêtes crawler / trafic utilisateur, et toute évolution de votre visibilité organique ou du trafic de référence issu de la recherche IA. Certains éditeurs constatent que leur stratégie initiale nécessite des ajustements après quelques mois de données réelles—un blocage peut avoir un effet inattendu ou l’autorisation de certains crawlers peut générer plus de valeur que prévu. Soyez prêts à affiner votre stratégie en fonction des résultats concrets, pas sur des hypothèses. Enfin, communiquez votre stratégie robots.txt aux parties prenantes de votre organisation—équipes SEO, éditoriales, direction business—pour garantir la cohérence et l’intentionnalité de vos choix au fil de l’évolution de votre structure. Cette vigilance continue garantit que votre stratégie de protection reste efficace et alignée avec vos objectifs face à la transformation du paysage IA.
Non. Bloquer les crawlers d'entraînement IA comme GPTBot, ClaudeBot et CCBot n'affecte pas votre classement sur Google ou Bing. Les moteurs de recherche traditionnels utilisent des crawlers différents (Googlebot, Bingbot) qui fonctionnent indépendamment. Ne les bloquez que si vous souhaitez disparaître complètement des résultats de recherche.
Les principaux crawlers d'OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) et Perplexity (PerplexityBot) déclarent officiellement respecter les directives de robots.txt. Cependant, des bots plus petits ou moins transparents peuvent ignorer votre configuration, d'où l'existence de stratégies de protection en couches.
Cela dépend de votre stratégie. Bloquer uniquement les crawlers d'entraînement (GPTBot, ClaudeBot, CCBot) protège votre contenu de l'entraînement des modèles tout en permettant aux crawlers axés sur la recherche de vous aider à apparaître dans les résultats de recherche IA. Un blocage complet vous retire entièrement des écosystèmes IA.
Examinez votre configuration au moins chaque trimestre. Les entreprises d'IA introduisent régulièrement de nouveaux crawlers. Anthropic a fusionné ses bots 'anthropic-ai' et 'Claude-Web' en 'ClaudeBot', donnant à ce nouveau bot un accès temporairement non restreint aux sites qui n'avaient pas mis à jour leurs règles.
Robots.txt est un fichier à la racine de votre domaine qui s'applique à toutes les pages, tandis que les balises meta robots sont des directives HTML sur des pages individuelles. Robots.txt est vérifié en premier et peut empêcher les crawlers d'accéder à une page, tandis que les balises meta ne sont lues que si la page est accessible. Utilisez les deux pour un contrôle complet.
Oui. Vous pouvez utiliser des règles Disallow spécifiques à un chemin dans robots.txt (par exemple, 'Disallow: /premium/' pour bloquer uniquement le contenu premium) ou des balises meta robots sur des pages individuelles. Cela vous permet de protéger le contenu sensible tout en laissant les crawlers accéder à d'autres zones.
Si un bot ignore robots.txt, vous aurez besoin de méthodes de protection supplémentaires comme le blocage au niveau du serveur (.htaccess), le blocage IP, ou des règles WAF. Robots.txt arrête environ 40 à 60 % des crawlers indésirables, il est donc important d'avoir une protection en plusieurs couches pour une défense complète.
Utilisez des outils de test comme le testeur robots.txt de Google Search Console, Merkle Robots.txt Tester ou TechnicalSEO.com pour valider votre configuration. Surveillez vos logs serveur pour l'activité des crawlers afin de vérifier que les bots bloqués sont bien exclus et que les bots autorisés accèdent à votre contenu.
Le fichier Robots.txt n'est que la première étape. Utilisez AmICited pour suivre quels systèmes d'IA citent votre contenu, à quelle fréquence ils vous référencent, et assurez-vous d'une attribution correcte à travers GPTs, Perplexity, Google AI Overviews, et plus encore.
Découvrez comment autoriser ou bloquer sélectivement les crawlers IA en fonction des objectifs commerciaux. Mettez en œuvre un accès différentiel aux crawlers p...

Découvrez comment les pare-feux applicatifs web offrent un contrôle avancé sur les crawlers IA au-delà du robots.txt. Mettez en place des règles WAF pour protég...

Découvrez comment vérifier si les crawlers IA comme ChatGPT, Claude et Perplexity peuvent accéder au contenu de votre site web. Découvrez les méthodes de test, ...