Complétude sémantique : créer des réponses autonomes pour l’IA
Découvrez comment la complétude sémantique crée des réponses autonomes que les systèmes d’IA citent. Découvrez les 3 piliers de la complétude sémantique et mett...
14 min de lecture
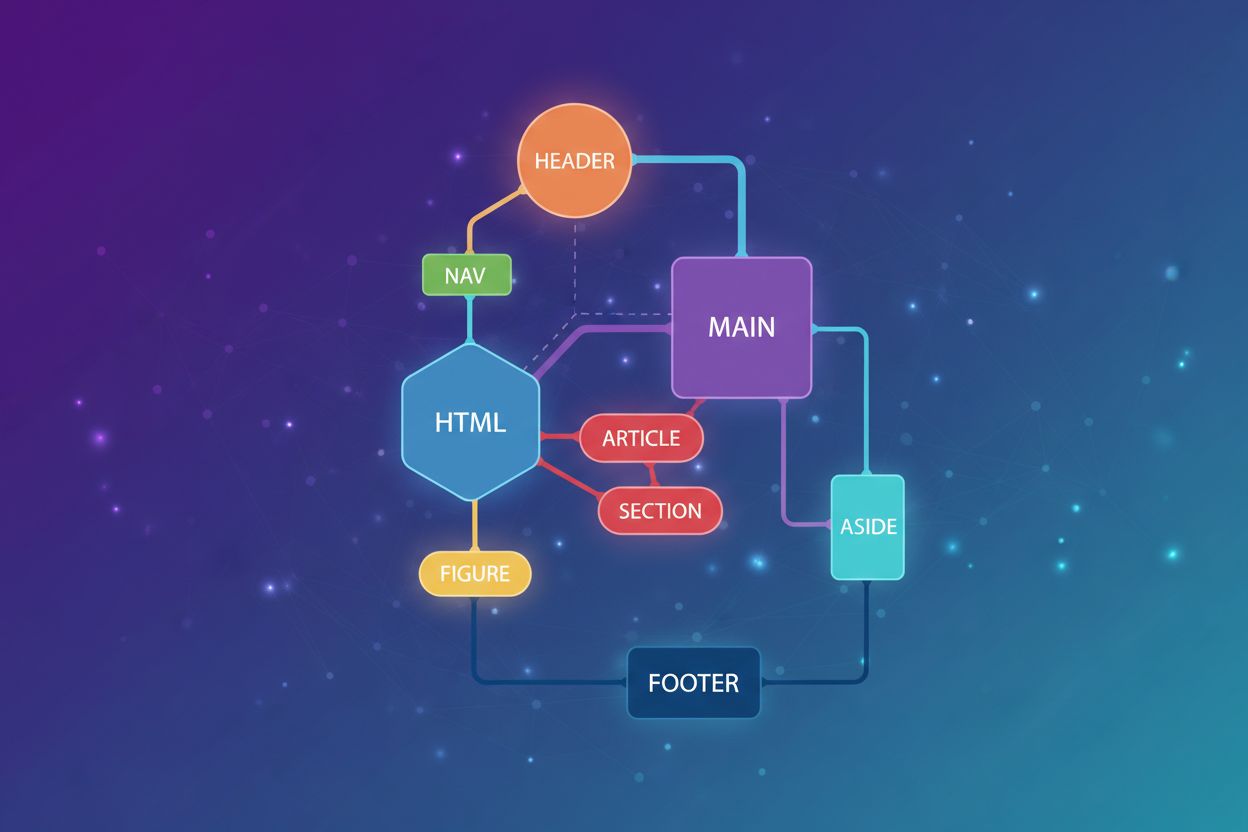
Découvrez comment l’HTML sémantique améliore la compréhension de l’IA, la compréhension des LLM et l’attribution de contenu. Découvrez des techniques avancées pour optimiser le balisage pour les systèmes d’IA comme ChatGPT, Perplexity et Google Gemini.
L’HTML sémantique désigne un balisage qui porte un sens au-delà de la simple présentation — utilisant des balises comme <article>, <section>, <nav> et <header> à la place d’éléments génériques <div> et <span>. Alors que le balisage non sémantique traditionnel s’affiche de façon identique dans les navigateurs, il n’apporte aucune information contextuelle aux systèmes d’IA qui tentent de comprendre la structure de la page et la hiérarchie du contenu. Les modèles d’IA, en particulier les grands modèles de langage (LLM), dépendent fortement de la structure HTML pour extraire le sens, identifier le contenu principal et comprendre les relations entre les différents éléments de la page. Lorsque vous utilisez l’HTML sémantique, vous créez en quelque sorte un plan lisible par machine qui aide les systèmes d’IA à distinguer navigation, contenu principal, barres latérales et métadonnées. Cette distinction devient cruciale à mesure que les systèmes d’IA explorent, indexent et citent de plus en plus de contenus web — ils doivent savoir ce qui est réellement important. La différence entre un balisage sémantique et non sémantique est la différence entre un document bien organisé et un empilement de blocs de texte non marqués, et les systèmes d’IA les traitent en conséquence.
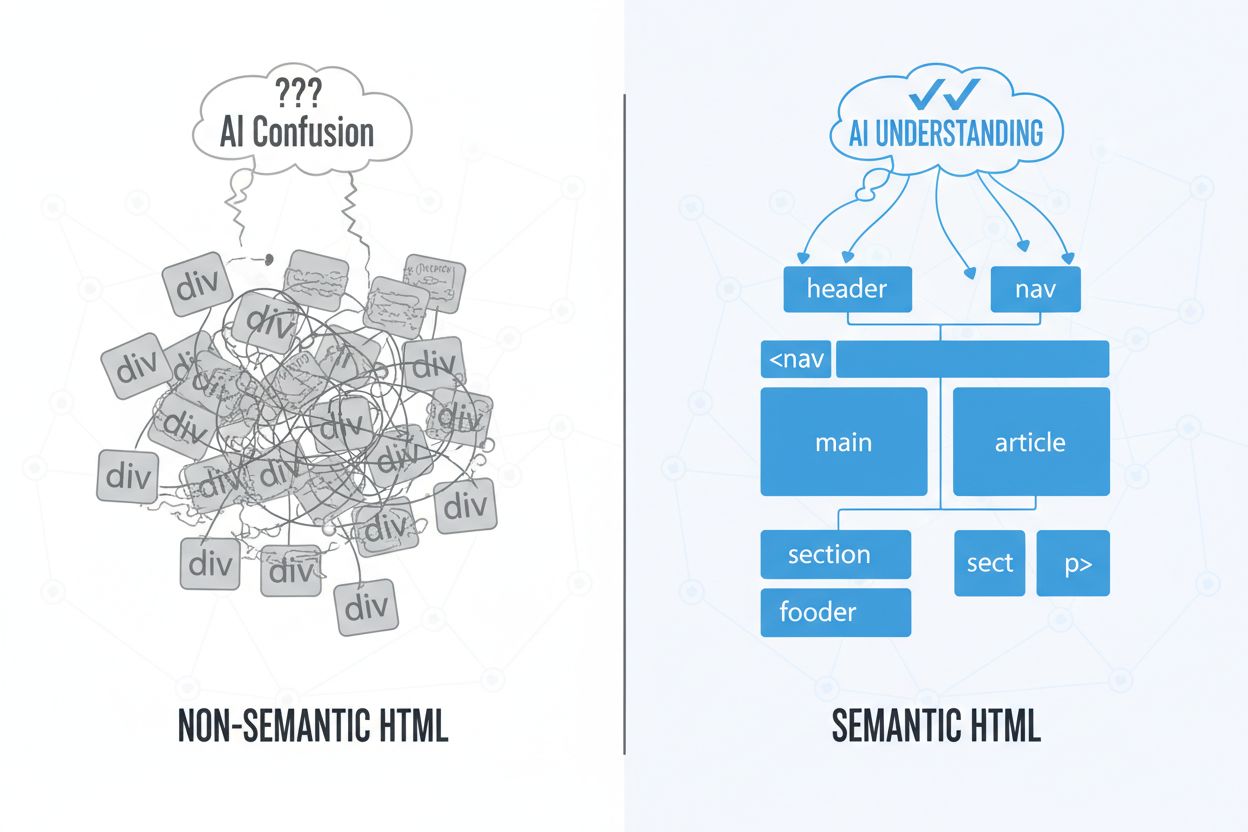
Les grands modèles de langage traitent le HTML brut fondamentalement différemment des navigateurs humains. Les LLM n’affichent pas JavaScript, n’appliquent pas de styles CSS et n’exécutent pas d’interactions dynamiques — ils travaillent exclusivement avec le code source HTML brut et le contenu textuel. Cela signifie que le contenu masqué par le rendu JavaScript, les éléments chargés dynamiquement ou les astuces de visibilité CSS est essentiellement invisible pour les systèmes d’IA. Lorsque ChatGPT, Perplexity ou Google Gemini explorent votre site, ils lisent la structure HTML pure, rendant le balisage sémantique exponentiellement plus précieux que la conception visuelle. Le tableau suivant illustre la manière dont différents systèmes d’IA gèrent le traitement HTML :
| Système IA | Traitement HTML | Support JavaScript | Reconnaissance des éléments sémantiques | Précision de la citation |
|---|---|---|---|---|
| ChatGPT | Analyse HTML brut | Limité/Aucun | Élevée (avec balisage approprié) | Moyenne-Élevée |
| Perplexity | Structure HTML complète | Partiel | Élevée (privilégie les balises sémantiques) | Élevée |
| Google Gemini | Analyse HTML complète | Limité | Élevée (détection des repères) | Moyenne |
Comprendre ces différences vous aide à optimiser le contenu spécifiquement pour la façon dont chaque système d’IA traite réellement vos pages, plutôt que de supposer qu’ils fonctionnent comme les moteurs de recherche traditionnels.
Les éléments HTML5 sémantiques forment la base du balisage lisible par l’IA, chacun remplissant un rôle structurel spécifique qui aide les systèmes à comprendre la hiérarchie et les relations du contenu. Les principaux repères sémantiques incluent :
<header> – Identifie le contenu introductif, l’image de marque du site et les conteneurs de navigation ; aide l’IA à distinguer les métadonnées de la page du contenu principal<nav> – Marque explicitement les sections de navigation ; les systèmes d’IA utilisent ceci pour filtrer les liens de navigation lors de l’extraction du contenu principal<main> – Désigne la zone de contenu principal ; essentiel pour que l’IA identifie ce qui est réellement important par rapport au matériel complémentaire<article> – Englobe les blocs de contenu autonomes ; fondamental pour que l’IA reconnaisse des blocs de contenu indépendants et citables<section> – Regroupe le contenu thématiquement lié ; aide l’IA à comprendre l’organisation du contenu et les limites des sujets<aside> – Marque le contenu périphérique ou complémentaire ; permet à l’IA de déprioriser les barres latérales et les sections de contenu associé<footer> – Contient les métadonnées, droits d’auteur et liens secondaires ; aide l’IA à distinguer le pied de page du contenu principal<figure> et <figcaption> – Associe des images à des légendes ; permet à l’IA de comprendre le contexte et l’attribution du contenu visuelL’utilisation cohérente de ces éléments crée une couche de données sémantiques que les systèmes d’IA peuvent analyser de façon fiable, améliorant considérablement la précision de l’extraction de contenu et la qualité des citations.
L’HTML sémantique et les données structurées (Schema.org/JSON-LD) jouent des rôles complémentaires mais distincts pour rendre le contenu accessible à l’IA. L’HTML sémantique fournit un contexte structurel via la hiérarchie du balisage — il indique aux systèmes d’IA où se trouve le contenu important et comment il est organisé. Les données structurées, via JSON-LD ou microdonnées, donnent un sens sémantique explicite à ce que le contenu représente — définissant entités, relations et propriétés dans un format lisible par machine. L’approche la plus efficace combine les deux stratégies : utiliser l’HTML sémantique pour la structure du document et la hiérarchie du contenu, tout en superposant le balisage Schema.org pour définir explicitement les entités, événements, produits, articles et leurs relations. Par exemple, une balise <article> indique à l’IA « ceci est un article », mais le schéma Article de Schema.org lui indique l’auteur, la date de publication, le titre et le nombre de mots. Aucune approche seule n’est suffisante pour une compréhension optimale par l’IA — l’HTML sémantique sans données structurées laisse les relations d’entités ambiguës, tandis que les données structurées sans balisage sémantique fournissent des métadonnées sans contexte. Les sites avant-gardistes mettent en œuvre les deux, créant une couche sémantique riche que les systèmes d’IA peuvent exploiter pleinement pour une compréhension précise du contenu et une citation fidèle.
L’HTML sémantique constitue la base de la construction de graphes de connaissances pilotés par l’IA, permettant aux systèmes d’extraire entités, relations et connexions hiérarchiques à partir de votre contenu. Lorsque vous structurez correctement le contenu avec des éléments sémantiques, les systèmes d’IA peuvent identifier de façon fiable les entités clés (personnes, organisations, concepts) et comprendre comment elles se relient dans votre document. L’extraction d’entités devient bien plus précise quand le contenu est organisé sémantiquement — un système d’IA peut distinguer une personne mentionnée dans l’article principal d’une personne évoquée dans une barre latérale ou un pied de page, produisant une cartographie relationnelle plus fine. En combinant l’HTML sémantique avec le balisage Schema.org, vous créez une couche de données sémantiques qui définit explicitement ces relations, permettant aux systèmes d’IA de construire des graphes de connaissances fidèles à votre domaine d’expertise. Cette base sémantique est particulièrement précieuse pour les domaines spécialisés comme la santé, la finance ou la documentation technique, où la précision des relations d’entités et la compréhension hiérarchique impactent directement la fiabilité des systèmes IA. Les graphes de connaissances issus de contenus balisés sémantiquement sont plus fiables, plus complets et plus utiles pour les applications IA en aval — des systèmes de questions-réponses aux moteurs de recommandation.
Un balisage sémantique approprié améliore directement la précision des citations IA et l’attribution du contenu, enjeu crucial à mesure que les systèmes d’IA génèrent de plus en plus de réponses à partir du web. Lorsque les systèmes d’IA utilisent la génération augmentée par récupération (RAG) pour citer des sources, ils s’appuient sur le découpage du contenu et la détection des limites — des éléments HTML sémantiques comme <article>, <section> et <figure> fournissent des limites explicites qui empêchent le contenu d’être attribué ou fragmenté à tort entre différentes sources. Les sites avec une structure sémantique claire constatent une précision de citation nettement supérieure car les systèmes d’IA peuvent identifier de manière fiable où se termine un contenu et où un autre commence, évitant l’attribution erronée fréquente avec les balises <div> génériques. Des outils comme AmICited.com aident les éditeurs à suivre la fréquence des citations de leur contenu par les systèmes d’IA, et les données montrent que le contenu balisé sémantiquement reçoit une attribution plus fidèle. Le lien entre balisage sémantique et précision de citation crée une incitation directe : un meilleur balisage conduit à une meilleure compréhension par l’IA, donc à des citations plus exactes, ce qui génère plus de trafic et de crédibilité. À mesure que le contenu généré par l’IA se répand, l’HTML sémantique devient votre principal levier pour garantir l’attribution fidèle de votre contenu et la reconnaissance de votre expertise.
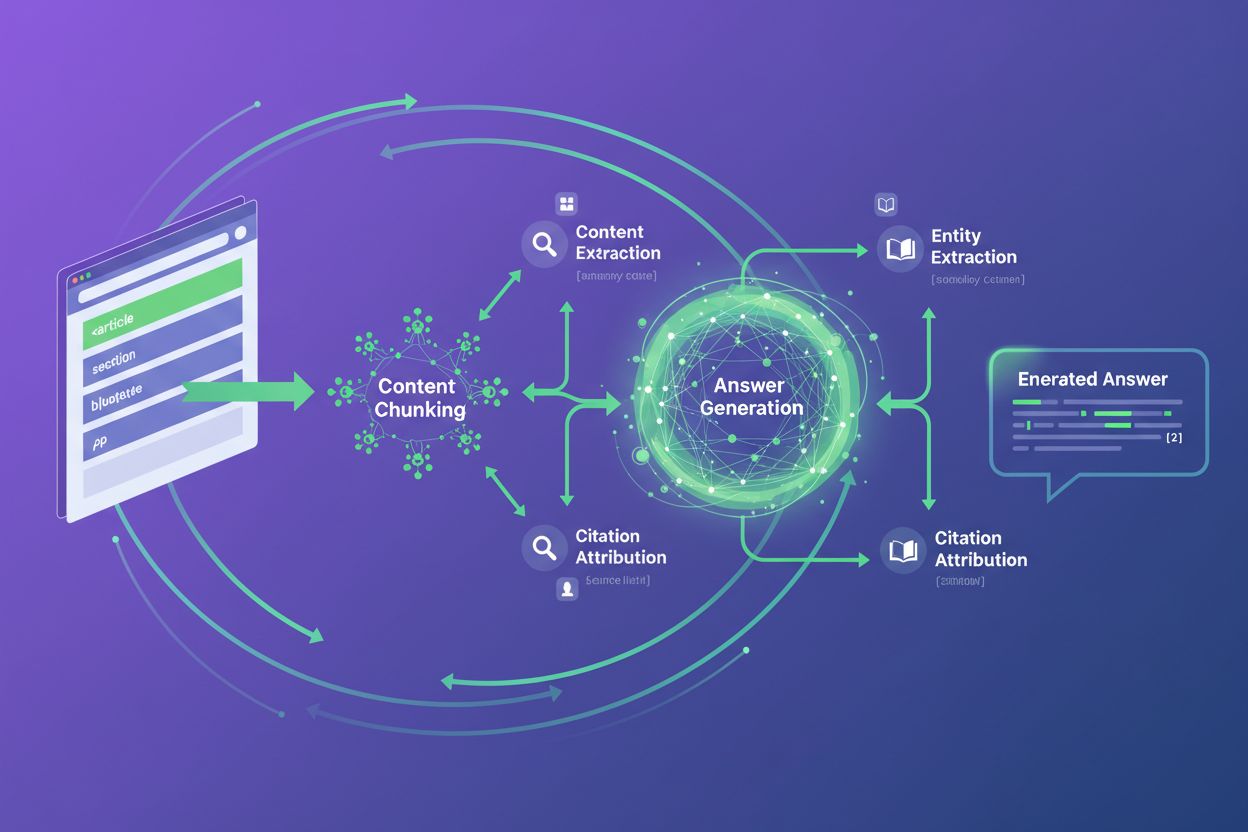
L’implémentation de l’HTML sémantique pour l’optimisation IA exige l’application cohérente de bonnes pratiques structurelles sur l’ensemble de votre contenu. Commencez par une hiérarchie correcte des titres — utilisez <h1> pour le titre de la page, <h2> pour les sections principales, <h3> pour les sous-sections, etc., sans sauter de niveau. Cette hiérarchie aide l’IA à comprendre l’organisation du contenu et à identifier les sujets clés. Encadrez toujours votre contenu principal dans des balises <main> et utilisez <article> pour les blocs de contenu autonomes :
<main>
<article>
<h1>Titre de l’article</h1>
<section>
<h2>Titre de section</h2>
<p>Contenu ici...</p>
</section>
</article>
</main>
Évitez les erreurs courantes comme l’utilisation d’éléments sémantiques uniquement pour le style (par exemple <section> pour l’espacement visuel) ou un mauvais emboîtement. Utilisez <figure> avec <figcaption> pour les images nécessitant une explication :
<figure>
<img src="image.jpg" alt="Description">
<figcaption>Légende de l’image avec contexte</figcaption>
</figure>
Placez la navigation dans des balises <nav>, le pied de page dans <footer>, et le contenu complémentaire dans <aside>, en créant des limites claires que les systèmes d’IA peuvent analyser de façon fiable. Combinez l’HTML sémantique avec le balisage Schema.org pour une compréhension optimale par l’IA, et validez régulièrement votre balisage à l’aide d’outils comme le validateur W3C pour garantir la cohérence.
Le suivi de l’impact des améliorations HTML sémantiques demande de surveiller à la fois des métriques directes et des indicateurs spécifiques à l’IA de visibilité et de citation du contenu. Utilisez des outils comme AmICited.com pour suivre la fréquence d’apparition de votre contenu dans les réponses générées par l’IA, et vérifiez si la fréquence des citations augmente après l’implémentation de balisages sémantiques. Analysez vos journaux serveur et les schémas de crawl IA pour comprendre quels contenus sont accédés par les systèmes d’IA et à quelle fréquence — les améliorations HTML sémantiques devraient s’accompagner d’une augmentation de l’activité des crawlers IA et d’une extraction de contenu plus régulière. Surveillez vos métriques de visibilité dans la recherche en parallèle des citations IA, car le balisage sémantique améliore souvent les deux simultanément. Les indicateurs clés de performance incluent : la fréquence des citations dans les réponses IA, la justesse des extraits attribués, le trafic issu du contenu généré par l’IA et la régularité de l’extraction de contenu sur différents systèmes IA. Définissez des métriques de référence avant de mettre en place les améliorations, puis mesurez les évolutions sur 4 à 8 semaines pour laisser le temps aux systèmes IA de re-crawler et réindexer votre contenu. L’investissement dans l’HTML sémantique porte ses fruits sur plusieurs canaux — meilleurs classements dans la recherche, meilleures citations IA, représentation plus fidèle du contenu, et à terme, une visibilité et une crédibilité accrues dans un paysage informationnel piloté par l’IA.
L’HTML sémantique ne classe pas directement les pages dans les systèmes d’IA comme le font les liens dans la recherche traditionnelle. Cependant, il améliore considérablement la précision de l’extraction de contenu, la qualité des citations et la compréhension de l’IA, ce qui augmente indirectement la visibilité dans les réponses générées par l’IA. Une meilleure structure sémantique conduit à des citations plus précises et à une plus grande probabilité d’être sélectionné comme source.
Les LLM n’affichent pas le JavaScript ni n’appliquent de style CSS — ils travaillent exclusivement avec le code source HTML brut. Cela rend le balisage sémantique exponentiellement plus précieux pour les systèmes d’IA que pour les moteurs de recherche traditionnels. Alors que Google peut déduire la structure à partir du rendu visuel, les LLM dépendent entièrement de la sémantique HTML pour comprendre la hiérarchie du contenu et ses relations.
Oui, dans la plupart des cas. Commencez par mettre à jour les modèles principaux (articles de blog, pages produits, documentation) pour utiliser des éléments sémantiques comme main, article et une hiérarchie de titres correcte. Cette approche au niveau des modèles améliore des centaines ou des milliers de pages à la fois sans nécessiter une réécriture complète du site.
L’HTML sémantique est fondamental pour l’accessibilité. Des éléments comme nav, main et les repères permettent aux lecteurs d’écran et aux utilisateurs du clavier de naviguer efficacement. La même structure sémantique qui aide les systèmes d’IA aide également les technologies d’assistance, faisant de l’HTML sémantique une solution gagnant-gagnant pour l’accessibilité et l’optimisation IA.
Des éléments sémantiques comme article, section et figure fournissent des limites de contenu explicites qui empêchent les systèmes d’IA de fragmenter ou d’attribuer incorrectement le contenu. Une structure sémantique claire permet un découpage précis du contenu dans les systèmes RAG, menant à des citations plus exactes et à une attribution correcte de la source.
Absolument. L’HTML sémantique et Schema.org sont complémentaires, pas concurrents. L’HTML sémantique fournit un contexte structurel et une hiérarchie, tandis que Schema.org définit explicitement les entités et les relations. L’utilisation des deux ensemble crée une couche sémantique riche que les systèmes d’IA peuvent exploiter pleinement pour une compréhension optimale.
Les éléments sémantiques principaux pour l’optimisation IA sont : main (contenu principal), article (contenu autonome), section (regroupement thématique), header/footer (métadonnées), nav (navigation), aside (contenu complémentaire), et figure/figcaption (médias avec contexte). Ces éléments créent la base structurelle sur laquelle les systèmes d’IA s’appuient.
Utilisez des outils comme AmICited.com pour suivre la fréquence des citations dans les réponses IA avant et après la mise en œuvre d’améliorations sémantiques. Surveillez l’activité des crawlers IA dans les journaux serveur, suivez la précision de l’extraction de contenu et mesurez les changements du trafic généré par l’IA. Définissez des indicateurs de base avant les améliorations, puis mesurez les changements sur 4 à 8 semaines.
L’optimisation de l’HTML sémantique n’est qu’une partie pour garantir que votre contenu apparaisse fidèlement dans les réponses générées par l’IA. AmICited vous aide à surveiller comment votre marque est citée dans les GPT, Perplexity, Google AI Overviews et autres systèmes d’IA.
Découvrez comment la complétude sémantique crée des réponses autonomes que les systèmes d’IA citent. Découvrez les 3 piliers de la complétude sémantique et mett...

Découvrez comment les listes de définitions et le balisage HTML sémantique aident les systèmes d’IA à comprendre votre terminologie. Améliorez la visibilité de ...

Discussion communautaire sur l’impact de la compréhension sémantique sur les citations par l’IA. Retours concrets de professionnels du SEO qui analysent si l’op...