L’intention utilisateur dans la recherche IA : comment les LLM interprètent les requêtes
Découvrez comment les grands modèles de langage interprètent l’intention utilisateur au-delà des mots-clés. Apprenez l’expansion des requêtes, la compréhension sémantique et la manière dont les systèmes d’IA déterminent quels contenus citer dans leurs réponses.
Publié le Jan 3, 2026.Dernière modification le Jan 3, 2026 à 3:24 am
Qu’est-ce que l’intention utilisateur dans la recherche IA ?
L’intention utilisateur dans la recherche IA désigne l’objectif ou le but sous-jacent d’une requête, et non simplement les mots-clés saisis. Lorsque vous recherchez « meilleurs outils de gestion de projet », vous pouvez vouloir une comparaison rapide, des informations sur les prix ou les capacités d’intégration — et les grands modèles de langage (LLM) comme ChatGPT, Perplexity et Gemini de Google cherchent à comprendre lequel de ces objectifs vous poursuivez réellement. Contrairement aux moteurs de recherche traditionnels qui font correspondre des mots-clés à des pages, les LLM interprètent le sens sémantique de votre requête en analysant le contexte, la formulation et des signaux associés pour prédire ce que vous souhaitez accomplir. Ce passage de l’appariement par mots-clés à la compréhension de l’intention est fondamental dans le fonctionnement des systèmes de recherche IA modernes et détermine directement quelles sources seront citées dans les réponses générées par l’IA. Comprendre l’intention utilisateur est devenu essentiel pour les marques souhaitant gagner en visibilité dans les résultats de recherche IA, car des outils comme AmICited surveillent désormais la manière dont les systèmes d’IA référencent votre contenu en fonction de l’alignement d’intention.
Comment les LLM décomposent les requêtes en sous-intentions
Quand vous saisissez une requête dans un système de recherche IA, un phénomène remarquable se produit en coulisse : le modèle ne répond pas simplement à votre question. Il élargit votre requête en dizaines de micro-questions liées, un processus appelé « expansion de requête ». Par exemple, une recherche simple comme « Notion vs Trello » peut déclencher des sous-requêtes telles que « Quel outil est le meilleur pour la collaboration en équipe ? », « Quelles sont les différences de prix ? », « Lequel s’intègre le mieux avec Slack ? » et « Lequel est le plus simple pour les débutants ? » Cette expansion permet aux LLM d’explorer différents axes de votre intention et de rassembler des informations plus complètes avant de générer une réponse. Le système évalue alors des passages issus de différentes sources à un niveau granulaire, plutôt que de classer des pages entières, ce qui signifie qu’un seul paragraphe de votre contenu peut être sélectionné tandis que le reste de la page est ignoré. Cette analyse au niveau du passage explique pourquoi la clarté et la précision de chaque section comptent plus que jamais : une réponse bien structurée à une sous-intention spécifique peut être la raison pour laquelle votre contenu sera extrait par l’IA.
Requête d’origine
Sous-intention 1
Sous-intention 2
Sous-intention 3
Sous-intention 4
« Meilleurs outils de gestion de projet »
« Quel est le meilleur pour les équipes à distance ? »
« Quels sont les tarifs ? »
« Lequel s’intègre avec Slack ? »
« Lequel est le plus simple pour les débutants ? »
« Comment améliorer la productivité »
« Quels outils aident à gérer le temps ? »
« Quelles méthodes de productivité sont éprouvées ? »
« Comment réduire les distractions ? »
« Quelles habitudes favorisent la concentration ? »
« Moteurs de recherche IA expliqués »
« En quoi diffèrent-ils de Google ? »
« Quel moteur IA est le plus précis ? »
« Comment gèrent-ils la confidentialité ? »
« Quel est l’avenir de la recherche IA ? »
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
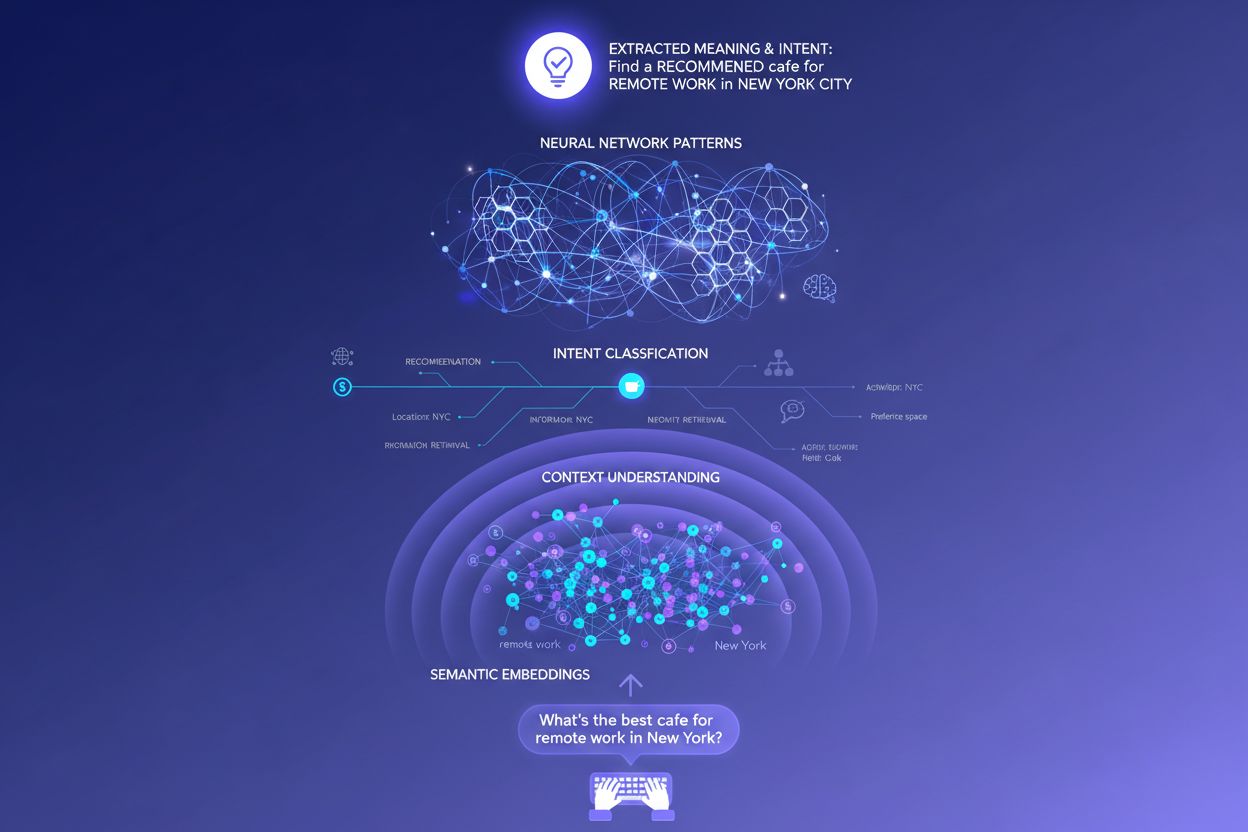
Le rôle du contexte dans la reconnaissance de l’intention
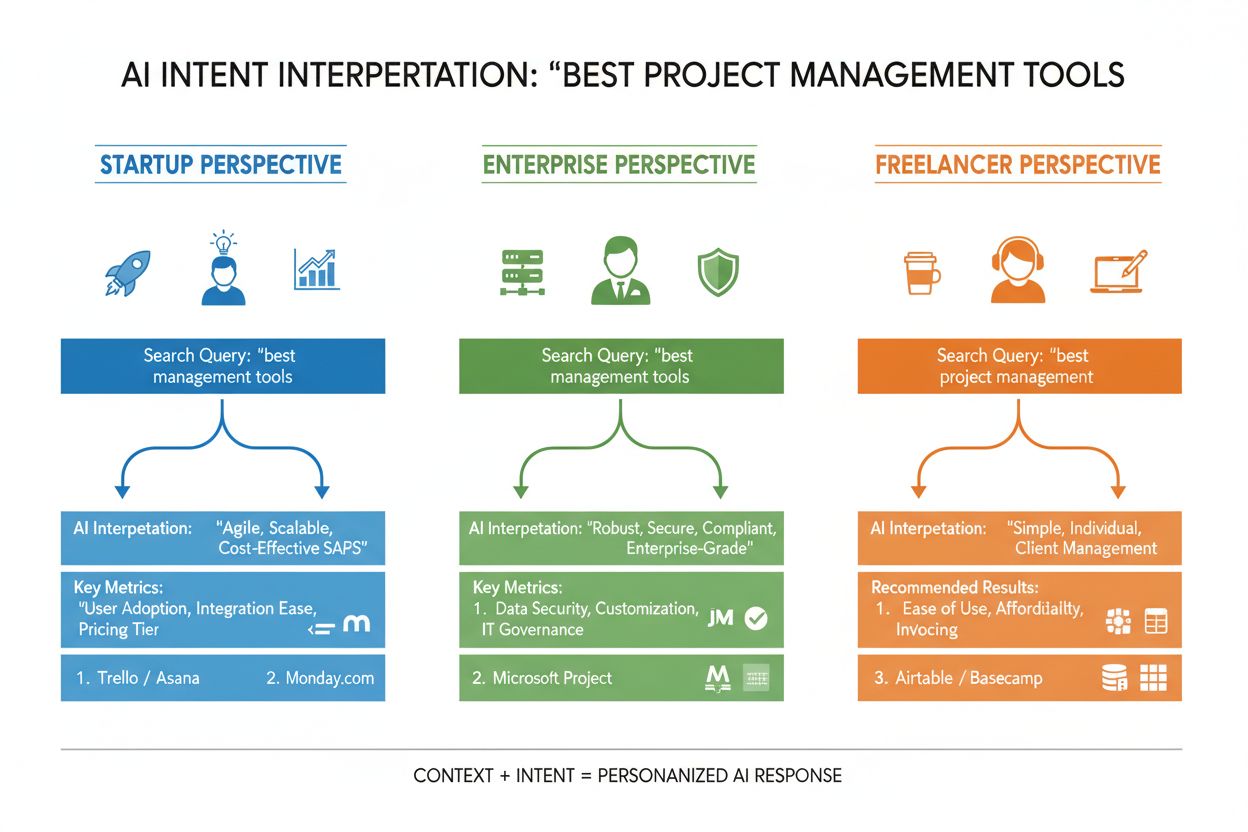
Les LLM n’évaluent pas votre requête isolément : ils construisent ce que les chercheurs appellent un « embedding utilisateur », un profil vectoriel qui capture votre intention évolutive en fonction de votre historique de recherche, localisation, type d’appareil, moment de la journée et même des conversations précédentes. Cette compréhension contextuelle permet au système de personnaliser fortement les résultats : deux personnes recherchant « meilleurs outils CRM » peuvent recevoir des recommandations totalement différentes si l’une est fondatrice d’une startup et l’autre gestionnaire en entreprise. Le reclassement en temps réel affine encore les résultats selon vos interactions — si vous cliquez sur certains résultats, lisez des sections spécifiques ou posez des questions de suivi, le système ajuste sa compréhension de votre intention et met à jour ses recommandations. Cette boucle de retour comportementale signifie que les systèmes d’IA apprennent en permanence ce que veulent réellement les utilisateurs, pas seulement ce qu’ils ont tapé. Pour les créateurs de contenu et marketeurs, cela souligne l’importance d’élaborer des contenus satisfaisant l’intention à travers divers contextes et étapes de décision.
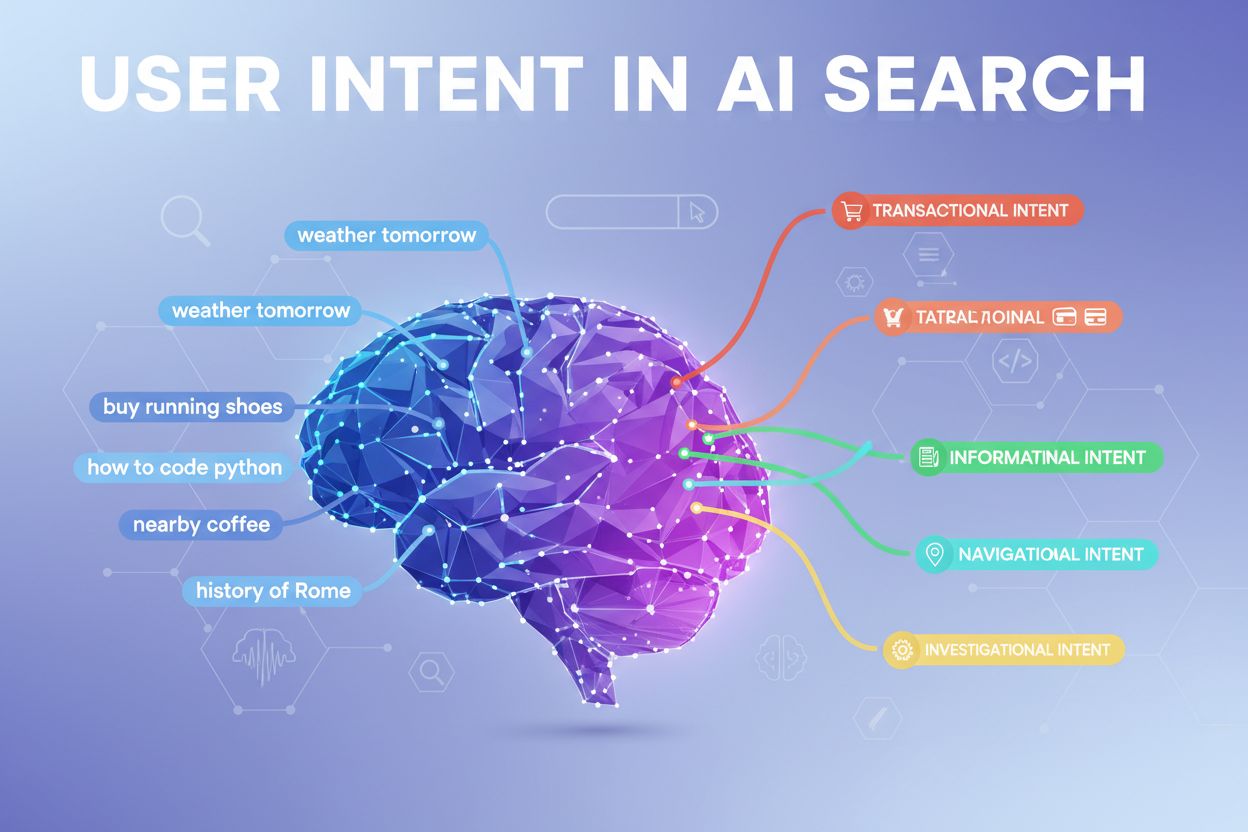
Systèmes de classification de l’intention : comprendre les différents types d’objectifs utilisateur
Les systèmes d’IA modernes classent l’intention utilisateur en plusieurs catégories distinctes, nécessitant chacune des types de contenus et de réponses spécifiques :
Intention informationnelle — L’utilisateur recherche ou apprend ; il souhaite comprendre un concept, comparer des options ou rassembler des connaissances sans agir immédiatement
Intention transactionnelle — L’utilisateur est prêt à agir, que ce soit pour acheter, s’inscrire ou télécharger une ressource
Intention navigationnelle — L’utilisateur cherche une marque, un site ou une fonctionnalité spécifique qu’il connaît déjà
Intention commerciale — L’utilisateur évalue activement des options avant de prendre une décision d’achat, compare des fonctionnalités, des prix, des cas d’usage
Intention conversationnelle — L’utilisateur interagit avec un assistant IA dans un échange dialogué, posant des questions de suivi et s’attendant à une gestion du contexte sur plusieurs échanges
Les LLM classifient automatiquement ces intentions en analysant la structure de la requête, les mots-clés et les signaux contextuels, puis sélectionnent le contenu qui correspond le mieux au type d’intention détecté. Comprendre ces catégories aide les créateurs de contenu à structurer leurs pages pour répondre à l’intention spécifique des utilisateurs.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Compréhension sémantique vs. appariement de mots-clés : pourquoi l’IA surpasse la recherche traditionnelle
Les moteurs de recherche à base de mots-clés fonctionnent via un simple appariement de chaînes de caractères : si votre page contient exactement les mots recherchés, elle peut être classée. Cette approche échoue totalement avec les synonymes, paraphrases et le contexte. Si quelqu’un cherche « logiciel de gestion de projet abordable » et que votre page utilise « plateforme économique de coordination des tâches », la recherche traditionnelle peut rater complètement la connexion. Les embeddings sémantiques règlent ce problème en convertissant mots et expressions en vecteurs mathématiques qui capturent le sens, et non seulement le texte de surface. Ces vecteurs existent dans un espace de grande dimension où les concepts sémantiquement proches se regroupent, permettant aux LLM de reconnaître que « abordable », « économique », « pas cher » et « à bas coût » expriment la même intention. Cette approche sémantique gère aussi beaucoup mieux les requêtes longues ou conversationnelles qu’un simple appariement de mots-clés : une requête comme « Je suis freelance et j’ai besoin d’un outil simple mais puissant » peut être reliée à un contenu pertinent même sans mots-clés classiques. Au final, les systèmes IA peuvent proposer des réponses pertinentes à des requêtes vagues, complexes ou inhabituelles, les rendant bien plus utiles que leurs prédécesseurs à mots-clés.
Comment les LLM utilisent embeddings et transformers pour interpréter l’intention
Au cœur technique de l’interprétation de l’intention se trouve l’architecture transformer, un réseau neuronal qui traite le langage en analysant les relations entre les mots grâce à un mécanisme appelé « attention ». Plutôt que de lire le texte de façon séquentielle comme un humain, les transformers évaluent comment chaque mot est relié à tous les autres dans une requête, ce qui leur permet de saisir le sens nuancé et le contexte. Les embeddings sémantiques sont les représentations numériques issues de ce processus : chaque mot, expression ou concept est converti en vecteur de nombres qui encode son sens. Des modèles comme BERT (Bidirectional Encoder Representations from Transformers) et RankBrain utilisent ces embeddings pour comprendre que « meilleur CRM pour startups » et « meilleure plateforme de gestion de la relation client pour jeunes entreprises » expriment une intention similaire, même avec des mots différents. Le mécanisme d’attention est particulièrement puissant car il permet au modèle de se concentrer sur les parties les plus pertinentes d’une requête — dans « meilleurs outils de gestion de projet pour équipes à distance avec budget limité », le système apprend à donner du poids à « équipes à distance » et « budget limité » comme signaux d’intention critiques. Cette sophistication technique explique pourquoi la recherche IA moderne paraît bien plus intelligente que les systèmes traditionnels à mots-clés.
Impact sur la stratégie de contenu : optimiser pour la découverte basée sur l’intention
Comprendre comment les LLM interprètent l’intention change radicalement la stratégie de contenu. Plutôt que d’écrire un guide exhaustif cherchant à se positionner sur un seul mot-clé, le contenu performant aborde désormais plusieurs sous-intentions au sein de sections modulaires pouvant exister indépendamment. Si vous écrivez sur les outils de gestion de projet, au lieu d’une comparaison massive, créez des sections distinctes répondant à « Quel est le meilleur pour les équipes à distance ? », « Quelle est l’option la plus abordable ? » et « Lequel s’intègre avec Slack ? » — chaque section devient une potentielle « carte réponse » que les LLM peuvent extraire et citer. Un format prêt à la citation est crucial : privilégiez les faits plutôt que les affirmations vagues, incluez des chiffres et dates précises, et structurez l’information pour que l’IA puisse facilement citer ou résumer. Les listes à puces, titres clairs et paragraphes courts aident les LLM à traiter votre contenu plus efficacement que des blocs de texte denses. Des outils comme AmICited permettent désormais aux marketeurs de surveiller la façon dont les systèmes IA référencent leur contenu sur ChatGPT, Perplexity et Google IA, révélant quels alignements d’intention fonctionnent et où subsistent des lacunes. Cette approche data-driven de la stratégie de contenu — optimiser pour la façon dont les IA interprètent et citent réellement votre travail — marque un changement fondamental par rapport au SEO traditionnel.
Exemples concrets : comment l’intention façonne les réponses IA
Prenons l’exemple du e-commerce : lorsqu’un utilisateur cherche « veste imperméable à moins de 200 € », il exprime simultanément plusieurs intentions — il veut des informations sur la durabilité, une confirmation du prix et des recommandations produits. Un système IA peut décliner cela en sous-questions sur la technologie imperméabilisante, la comparaison de prix, les avis de marques et les informations sur la garantie. Une marque qui traite tous ces aspects dans un contenu modulaire et structuré a bien plus de chances d’être citée dans la réponse IA qu’un concurrent avec une page produit générique. Dans le SaaS, la même question « Comment inviter mon équipe sur cet espace de travail ? » peut apparaître des centaines de fois dans les logs de support, signalant un manque de contenu critique. Un assistant IA entraîné sur votre documentation pourrait peiner à répondre clairement, dégradant l’expérience utilisateur et réduisant la visibilité dans les réponses IA de support. Dans l’actualité ou l’information, une requête comme « Que se passe-t-il avec la régulation de l’IA ? » sera interprétée différemment selon le contexte : un décideur politique voudra des détails législatifs, un dirigeant d’entreprise des implications concurrentielles, un technologue des informations sur les standards techniques. Un contenu réussi traite explicitement ces différents contextes d’intention.
Défis de la reconnaissance de l’intention : quand l’IA se trompe
Malgré leur sophistication, les LLM rencontrent de vrais défis dans l’interprétation de l’intention. Les requêtes ambiguës comme « Java » peuvent désigner un langage de programmation, une île ou du café — même avec du contexte, le système peut mal classer l’intention. Les intentions mixtes ou superposées compliquent les choses : « Ce CRM est-il meilleur que Salesforce et où puis-je l’essayer gratuitement ? » mêle comparaison, évaluation et intention transactionnelle en une seule requête. Les limites de la fenêtre de contexte signifient que les LLM ne peuvent considérer qu’un historique de conversation limité ; dans de longues discussions, les signaux d’intention initiaux peuvent être oubliés. Les hallucinations et erreurs factuelles restent un problème, surtout dans des domaines exigeant une grande précision comme la santé, la finance ou le droit. Les questions de confidentialité comptent aussi : à mesure que les systèmes collectent plus de données comportementales pour personnaliser, il faut trouver un équilibre entre précision de l’intention et respect de la vie privée. Comprendre ces limites aide créateurs et marketeurs à avoir des attentes réalistes sur la visibilité IA, et à reconnaître que toute requête ne sera pas parfaitement interprétée.
L’avenir de la recherche IA basée sur l’intention : ce qui arrive ensuite
La recherche basée sur l’intention évolue rapidement vers une compréhension et une interaction toujours plus sophistiquées. L’IA conversationnelle deviendra plus naturelle, les systèmes gardant le contexte sur de longs dialogues complexes où l’intention évolue. La compréhension multimodale de l’intention combinera texte, images, voix et même vidéo pour interpréter les objectifs utilisateur de façon plus holistique — imaginez demander à un assistant IA « trouve-moi quelque chose comme ceci » tout en montrant une photo. La recherche sans requête explicite est une nouvelle frontière où les systèmes IA anticipent les besoins avant même qu’ils ne soient formulés, en exploitant signaux comportementaux et contexte pour proposer proactivement des informations pertinentes. La personnalisation améliorée rendra les résultats toujours plus adaptés aux profils individuels, stades de décision et situations contextuelles. L’intégration avec les systèmes de recommandation brouillera la frontière entre recherche et découverte, l’IA suggérant des contenus auxquels l’utilisateur n’aurait pas pensé spontanément. À mesure que ces capacités mûrissent, l’avantage concurrentiel appartiendra de plus en plus aux marques et créateurs qui comprennent profondément l’intention et structurent leur contenu pour y répondre de façon exhaustive à travers de multiples contextes et types d’utilisateurs.
Questions fréquemment posées
Qu’est-ce que l’intention utilisateur dans la recherche IA ?
L’intention utilisateur désigne l’objectif ou le but sous-jacent d’une requête, et non seulement les mots-clés saisis. Les LLM interprètent la signification sémantique en analysant le contexte, la formulation et les signaux associés pour prédire ce que l’utilisateur cherche réellement à accomplir. C’est pourquoi une même requête peut donner des résultats différents selon le contexte de l’utilisateur et l’étape de sa prise de décision.
Comment les LLM étendent-ils une requête unique en plusieurs recherches ?
Les LLM utilisent un processus appelé « expansion de requête » (« query fan-out ») pour décomposer une seule requête en dizaines de micro-questions connexes. Par exemple, « Notion vs Trello » peut se transformer en sous-requêtes sur la collaboration en équipe, les tarifs, les intégrations et la facilité d’utilisation. Cela permet aux systèmes d’IA d’explorer différentes facettes de l’intention et de recueillir des informations complètes.
Pourquoi comprendre l’intention est-il important pour les créateurs de contenu ?
Comprendre l’intention aide les créateurs à optimiser leur contenu pour que les systèmes d’IA l’interprètent et le citent réellement. Un contenu qui répond à plusieurs sous-intentions dans des sections modulaires a plus de chances d’être sélectionné par les LLM. Cela a un impact direct sur la visibilité dans les réponses générées par l’IA sur ChatGPT, Perplexity et Google IA.
Comment les embeddings sémantiques aident-ils à la reconnaissance de l’intention ?
Les embeddings sémantiques convertissent les mots et expressions en vecteurs mathématiques qui capturent le sens, et pas seulement le texte en surface. Cela permet aux LLM de reconnaître que « abordable », « économique » et « pas cher » expriment la même intention, même avec des mots différents. Cette approche sémantique gère bien mieux synonymes, paraphrases et contexte que l’appariement classique de mots-clés.
Les LLM peuvent-ils mal interpréter l’intention utilisateur ?
Oui, les LLM rencontrent des difficultés avec les requêtes ambiguës, les intentions mixtes et les limites de contexte. Des requêtes comme « Java » peuvent concerner le langage de programmation, la géographie ou le café. Les longues conversations peuvent dépasser la fenêtre de contexte et entraîner l’oubli des signaux d’intention initiaux. Comprendre ces limites aide à avoir des attentes réalistes sur la visibilité IA.
Comment les marques doivent-elles optimiser pour la recherche IA basée sur l’intention ?
Les marques doivent créer un contenu modulaire qui répond à plusieurs sous-intentions dans des sections distinctes. Utilisez un format prêt à la citation, avec des faits, des chiffres précis et une structure claire. Surveillez la façon dont les systèmes d’IA référencent votre contenu avec des outils comme AmICited pour repérer les écarts d’alignement d’intention et optimiser en conséquence.
Quelle est la différence entre intention et intérêt dans la recherche IA ?
L’intention est axée sur la tâche : ce que l’utilisateur veut accomplir immédiatement. L’intérêt est une curiosité plus générale. Les systèmes d’IA priorisent l’intention car elle détermine directement quel contenu sera sélectionné pour les réponses. Un utilisateur peut s’intéresser aux outils de productivité en général, mais son intention peut être de trouver une solution pour la collaboration d’équipes à distance.
Comment l’intention influence-t-elle les sources citées par les systèmes d’IA ?
Les systèmes d’IA citent les sources qui correspondent le mieux à l’intention détectée. Si votre contenu répond clairement à une sous-intention spécifique avec des informations structurées et factuelles, il sera plus susceptible d’être sélectionné. Des outils comme AmICited analysent ces schémas de citation et montrent quels alignements d’intention favorisent la visibilité dans les réponses IA.
Surveillez comment l’IA interprète l’intention de votre marque
Comprenez comment les LLM font référence à votre contenu sur ChatGPT, Perplexity et Google IA. Suivez l’alignement d’intention et optimisez la visibilité IA avec AmICited.
Comment identifier l’intention de recherche pour l’optimisation IA
Apprenez à identifier et optimiser l’intention de recherche dans les moteurs de recherche IA. Découvrez comment classer les requêtes utilisateurs, analyser les ...
L’intention de recherche est le but derrière la requête d’un utilisateur. Découvrez les quatre types d’intention, comment les identifier et optimiser votre cont...
Faire Correspondre le Contenu aux Prompts : Optimisation Fondée sur l'Intention de la Requête
Apprenez à aligner votre contenu avec l’intention de la requête IA pour augmenter vos citations sur ChatGPT, Perplexity et Google AI. Maîtrisez les stratégies d...
10 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.