Pagination
La pagination divise de grands ensembles de contenu en pages gérables pour une meilleure expérience utilisateur et un meilleur référencement. Découvrez comment ...
11 min de lecture

Découvrez comment la pagination influence la visibilité dans l’IA. Comprenez pourquoi la division traditionnelle en pages aide les systèmes d’IA à trouver votre contenu alors que le scroll infini le masque, et comment optimiser la pagination pour les générateurs de réponses IA.
La pagination est la pratique consistant à diviser de grands ensembles de contenus en plusieurs pages liées entre elles. Oui, elle affecte significativement les systèmes d'IA—la pagination crée des URL distinctes et explorables qui aident les moteurs de recherche IA comme ChatGPT, Perplexity et le SGE de Google à découvrir et indexer votre contenu plus efficacement, tandis que les systèmes de scroll infini masquent souvent le contenu aux crawlers IA.
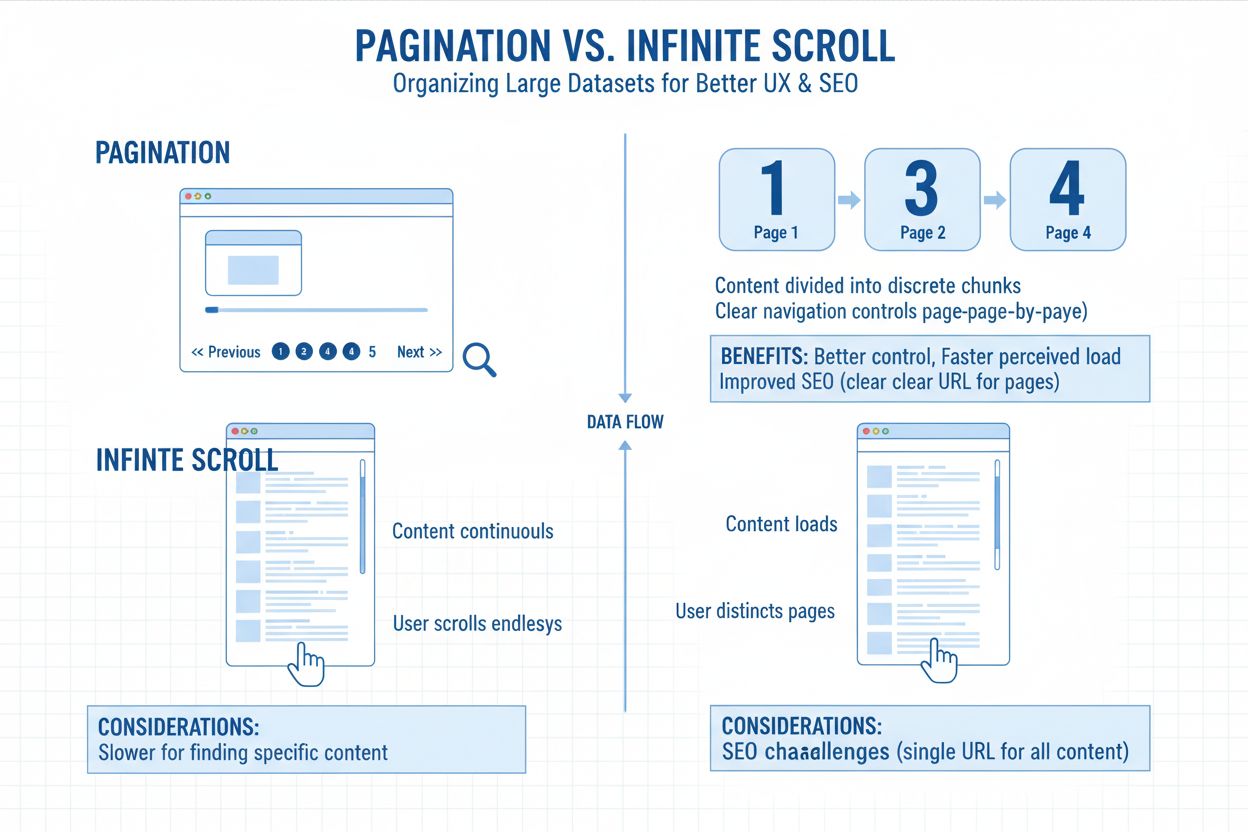
La pagination désigne la pratique consistant à diviser de grands ensembles de contenus en plusieurs pages liées plutôt que d’afficher tout sur un écran unique et infini. Imaginez cela comme les chapitres d’un livre—chaque page contient une portion gérable du contenu total, reliée par des liens numérotés ou des boutons “suivant/précédent”. Cette approche structurelle est présente partout, des listes de produits dans les boutiques e-commerce aux archives de blogs, fils de discussion de forums et résultats de recherche. La structure des URL reflète généralement cette division via des paramètres tels que ?page=2 ou des chemins comme /category/page/2/, permettant aux utilisateurs comme aux moteurs de recherche de comprendre leur position dans la série de contenus. La pagination sert d’outil organisationnel fondamental qui équilibre l’expérience utilisateur avec les exigences techniques d’accessibilité du contenu.
Les sites web mettent en œuvre la pagination principalement pour optimiser les performances et organiser le contenu. Charger des centaines ou milliers d’éléments simultanément solliciterait excessivement les ressources du serveur et entraînerait des temps de chargement lents, ce qui pénalise particulièrement les métriques de performance impactant le classement dans la recherche. Les utilisateurs apprécient la possibilité de mettre une page en favori, d’accéder directement à la page 10 ou de voir la quantité de contenu restant à consulter. D’un point de vue technique, diviser le contenu crée des URL distinctes que les moteurs de recherche peuvent indexer individuellement, préservant la distribution de l’autorité des liens à travers l’architecture de votre site. Cette clarté structurelle devient d’autant plus importante que les systèmes d’IA évoluent pour comprendre les relations entre les contenus et les schémas d’accessibilité.
La relation entre pagination et visibilité dans l’IA constitue l’un des aspects techniques SEO les plus cruciaux dans le paysage de recherche moderne. Les moteurs de recherche traditionnels comme Google comprennent depuis longtemps la pagination en explorant les liens et en suivant les séquences de pages. Toutefois, les moteurs de recherche et générateurs de réponses alimentés par l’IA fonctionnent fondamentalement différemment, nécessitant une approche plus nuancée de l’organisation du contenu. Les modèles de langage géants tels que ceux qui alimentent ChatGPT, Perplexity et le Search Generative Experience (SGE) de Google ne parcourent pas nécessairement les pages de façon linéaire ou ne suivent pas les hiérarchies de navigation traditionnelles. Ils fonctionnent plutôt en tokenisant et résumant les entrées textuelles—souvent issues de données publiques, d’API ou de bases de données structurées plutôt que de hiérarchies de profondeur d’exploration.
Lorsque votre contenu est réparti sur plusieurs pages faiblement structurées, les moteurs IA peuvent ignorer les entrées plus profondes ou mal interpréter leur relation avec l’ensemble du contenu. S’il y a peu de variation dans les métadonnées ou des signaux sémantiques faibles, votre contenu paginé paraît redondant—ou est tout simplement ignoré. Cela crée un écart de visibilité critique : un contenu bien classé dans la recherche Google traditionnelle peut rester totalement invisible pour les générateurs de réponses IA. La distinction est importante car les systèmes d’IA privilégient des données structurées, complètes et facilement récupérables. Ils ne “scrollent” pas comme un utilisateur. Ils analysent le code, les URL et les métadonnées pour résumer ou citer un contenu rapidement et précisément. Si votre page n’expose pas le contenu via des URL explorables ou des métadonnées riches, les moteurs IA ne peuvent pas le récupérer pour l’inclure dans des réponses générées.
Le choix entre pagination traditionnelle et scroll infini est devenu un facteur déterminant de la découvrabilité du contenu par l’IA. Les systèmes de scroll infini chargent le contenu via JavaScript uniquement après une interaction utilisateur, posant un problème fondamental d’accessibilité pour les crawlers IA. La plupart des systèmes de scroll infini n’exposent pas le contenu via des URL distinctes—ils chargent tout sur une seule page via une exécution JavaScript dynamique. Cela signifie que les crawlers IA, qui ne simulent pas le comportement réel de l’utilisateur comme le scroll ou le clic, manquent souvent tout ce qui se trouve au-delà de la première vue. Si votre page n’expose pas ce contenu supplémentaire via des URL explorables ou des métadonnées, les moteurs IA ne peuvent pas le récupérer. Vous pouvez avoir 200 articles, 300 produits ou des dizaines d’études de cas, mais s’ils sont enfouis sous des événements de chargement déclenchés par JavaScript, l’IA ne voit que 12 éléments. Peut-être.
La pagination traditionnelle reste la meilleure solution pour l’indexation par l’IA car elle produit des URL propres et explorables (ex. : /blog/page/4), permettant aux moteurs d’accéder à tout votre contenu et de le segmenter. Elle signale la structure thématique via un maillage interne, utilisant des liens standardisés comme “Page suivante” ou “Page précédente” pour aider les moteurs à comprendre la connexion des contenus. La pagination limite la dépendance au JavaScript, garantissant que votre contenu se charge pour les crawlers, quelle que soit l’interaction utilisateur avec la page. Cette clarté structurelle se traduit directement par une meilleure visibilité dans l’IA—lorsque ChatGPT ou Perplexity explore votre site, ils peuvent découvrir et indexer le contenu paginé beaucoup plus efficacement que le contenu caché derrière des systèmes de scroll infini.
| Aspect | Pagination | Scroll infini |
|---|---|---|
| Accessibilité à l’exploration | Les URL uniques permettent un indexage en profondeur | Le contenu est souvent masqué derrière des chargements JS |
| Découvrabilité IA | Plusieurs pages peuvent être classées indépendamment | Typiquement une seule page indexée |
| Données structurées | Plus facile à attribuer à chaque page | Souvent absentes ou diluées |
| Lien direct | Facile de lier à un contenu spécifique | Difficile de faire des liens profonds |
| Compatibilité sitemap | Compatible et complet | Souvent exclut le contenu profond |
| Structure d’URL | URL claires et distinctes par page | URL unique avec chargement dynamique |
| Visibilité du contenu | Tout le contenu est accessible aux crawlers | Le contenu nécessite l’exécution JS |
L’architecture technique du scroll infini crée des barrières fondamentales à la découverte de contenu pour l’IA. Lorsque le contenu ne se charge que par JavaScript, et qu’aucune URL ne reflète ce nouveau contenu, les moteurs IA ne le voient jamais. Pour un crawler, le reste de votre liste n’existe tout simplement pas. Ce n’est pas une limitation des systèmes d’IA—c’est une conséquence de la façon dont le scroll infini est généralement implémenté. La plupart des systèmes de scroll infini privilégient l’expérience utilisateur à l’accessibilité technique, en chargeant le contenu dynamiquement sans créer d’URL ou de métadonnées que les systèmes d’IA peuvent analyser.
Considérez un scénario réel : un détaillant de mode mondial a repensé son site avec une interface de scroll infini attrayante. La vitesse du site s’est améliorée, les métriques d’engagement semblaient solides, mais le trafic issu des résumés IA a chuté de façon spectaculaire. Leurs références produits semblaient disparaître des outils de recherche conversationnelle. Après un audit de leur architecture, le problème était évident : l’intégralité de leur catalogue était cachée derrière un scroll infini sans solutions alternatives explorables. Aucune URL de page secondaire. Aucun lien supplémentaire. Juste une longue liste de produits invisible. Google SGE et ChatGPT ne pouvaient accéder qu’à la première douzaine de produits par catégorie. Aussi beau que soit le site, sa découvrabilité était rompue pour les systèmes IA.
Une implémentation correcte de la pagination nécessite une attention à de multiples facteurs techniques qui déterminent collectivement si les systèmes d’IA peuvent découvrir et citer votre contenu. Tout commence par des structures d’URL propres et logiques qui indiquent clairement les relations séquentielles. Que vous utilisiez des paramètres de requête (?page=2) ou des structures basées sur des chemins (/page/2/), la cohérence importe plus que le format spécifique choisi. Les deux approches fonctionnent aussi bien pour les systèmes IA lorsqu’elles sont bien implémentées. Ce qui compte, c’est que chaque URL paginée charge un contenu distinct et reste accessible via des liens HTML standards ne nécessitant pas d’exécution JavaScript.
Les balises canoniques auto-référencées représentent une décision clé pour la stratégie de pagination. Chaque page paginée doit inclure une balise canonique pointant vers elle-même, indiquant qu’elle est la version préférée d’elle-même. Cette approche préserve l’indépendance des URL séquentielles, permettant à chacune de se classer selon son propre contenu et sa pertinence. Évitez la pratique obsolète qui consiste à canoniser toutes les pages paginées vers la page un—cela consolide les signaux mais empêche chaque page de se classer indépendamment dans les systèmes IA. Lorsque vous canonisez tout vers la page un, vous indiquez explicitement aux moteurs IA d’ignorer des pages potentiellement précieuses contenant des produits, contenus ou informations uniques.
Des métadonnées uniques pour chaque page sont essentielles à la visibilité IA. N’utilisez pas de titres génériques de type “Page 2” ou de descriptions dupliquées à travers la séquence. Rédigez plutôt des métadonnées spécifiques, riches en mots-clés, qui reflètent le sujet de chaque page. Par exemple, au lieu de “Produits - Page 2”, utilisez “Chaussures de sport femme à moins de 100 € - Page 2” ou “Tendances IA dans le retail – Bibliothèque de cas (Page 2)”. Cette clarté améliore la visibilité car les systèmes d’IA comprennent le contexte et peuvent mieux déterminer quand votre contenu répond à une requête spécifique. Chaque jeu de métadonnées doit respecter les principes de clarté, d’unicité et d’alignement sur les mots-clés. L’objectif est de rendre l’objet de chaque page évident pour les systèmes IA comme pour les lecteurs humains.
L’architecture du maillage interne détermine si les systèmes IA peuvent découvrir et naviguer efficacement à travers les pages séquentielles. Une structure linéaire (page 1 → 2 → 3) crée des chemins d’exploration longs où les pages profondes restent à plusieurs clics de la page d’accueil, laissant potentiellement du contenu précieux inexploré. Les bonnes pratiques incluent des liens complémentaires comme les options “Tout voir” ou des hubs de catégorie reliant directement aux pages clés, réduisant la profondeur d’exploration et répartissant plus équitablement l’autorité des liens. La relation entre navigation à facettes et pages séquentielles ajoute de la complexité, car les combinaisons de filtres peuvent générer des milliers de variations d’URL. Un maillage interne adéquat garantit que les pages prioritaires reçoivent suffisamment d’attention des crawlers tandis que les combinaisons moins importantes sont dépriorisées via l’utilisation stratégique de balises noindex ou de signaux canoniques.
Des chaînes de liens internes stratégiques depuis les contenus piliers vers des pages paginées spécifiques guident les systèmes IA à travers votre structure de contenu. Depuis votre page de catégorie principale, créez des liens directs vers des pages paginées précises en utilisant des textes d’ancrage qui orientent la compréhension de l’IA. Exemple : “Découvrez plus de succès e-commerce dans notre série d’études de cas – page 3.” Rendez le signal pertinent et facilement repérable. Cette approche apprend aux systèmes IA comment s’articule votre contenu et comment il doit être découvert. Lorsque les crawlers IA rencontrent ces liens contextuels, ils saisissent la relation entre les pages et peuvent mieux déterminer quel contenu est pertinent pour une requête donnée.
Les problèmes de contenu dupliqué apparaissent lorsque plusieurs URL affichent un contenu identique ou très similaire sans différenciation adéquate. Cela survient lorsque les pages séquentielles manquent d’éléments uniques au-delà des items listés, ou lorsque des paramètres URL créent plusieurs chemins vers le même contenu. Les moteurs de recherche et l’IA peinent alors à déterminer quelle version classer, fragmentant potentiellement la visibilité sur plusieurs URL. De plus, si les pages paginées contiennent surtout du texte standard, des en-têtes et pieds de page avec peu de contenu unique, elles peuvent être perçues comme des pages fines à faible valeur ajoutée. Pour éviter cela, il faut utiliser les balises canoniques avec soin, rédiger des méta-descriptions uniques pour chaque page et s’assurer que chaque page apporte suffisamment de valeur distincte au-delà des éléments de navigation et des sections standardisées.
Les implémentations JavaScript uniquement sont sans doute l’erreur la plus courante qui masque le contenu aux systèmes IA. Si votre site utilise des frameworks comme React ou Angular pour rendre les contrôles de pagination côté client, sans rendu côté serveur, les crawlers IA ne découvriront peut-être jamais le contenu au-delà de la page un. Assurez-vous que les liens de navigation existent dans le HTML initial reçu par l’IA, et non générés uniquement après chargement par JavaScript. Utilisez l’amélioration progressive—des liens HTML de base qu’on peut enrichir avec JavaScript pour des interactions plus fluides. Testez votre implémentation avec des outils qui montrent ce que voient les crawlers par rapport à ce qu’affichent les navigateurs avec JavaScript. Cela révèle les lacunes d’explorabilité qui pourraient vous coûter de la visibilité IA.
Suivre l’efficacité de la pagination demande de surveiller comment les systèmes IA interagissent avec votre contenu multi-pages. Contrairement au SEO traditionnel où Google Search Console fournit des données directes, la surveillance de la visibilité IA nécessite d’autres méthodes. Des outils comme Screaming Frog SEO Spider peuvent explorer votre site de façon similaire à l’accès des systèmes IA, cartographiant la structure des pages et identifiant les pages orphelines ou les problèmes de profondeur d’exploration. DeepCrawl et Sitebulk proposent une analyse avancée avec visualisation des relations entre pages. Google Search Console donne la vision de Google, affichant les URL paginées indexées et la fréquence d’exploration.
Les indicateurs clés de performance du contenu paginé incluent la présence de pages profondes dans les réponses générées par l’IA, la fréquence des citations de votre contenu paginé par les systèmes IA et la capacité de différentes pages à se positionner sur des requêtes longue traîne variées. Surveillez vos mentions de marque dans les réponses IA—si les systèmes IA citent systématiquement votre page un mais jamais les pages profondes, votre structure de pagination mérite une optimisation. Suivez quelles pages paginées génèrent le plus de trafic issu des sources IA. Ces données révèlent si votre stratégie de pagination expose efficacement le contenu aux systèmes IA ou s’il faut la réorganiser. Des audits réguliers permettent de détecter les problèmes avant qu’ils n’affectent la visibilité, notamment après des mises à jour du site ou des migrations de frameworks.
Le paysage des recherches alimentées par l’IA évolue rapidement, avec l’apparition régulière de nouveaux systèmes et fonctionnalités. Les stratégies de pagination efficaces aujourd’hui devraient le rester à mesure que les systèmes IA se sophistiquent, mais anticiper l’avenir suppose de comprendre les tendances émergentes. Les algorithmes de recherche IA deviennent de plus en plus performants pour comprendre les relations entre contenus et déterminer quelles pages paginées méritent d’être indexées en priorité. Les technologies de matching neuronal et la compréhension basée sur BERT de Google aident les moteurs à reconnaître que la page deux d’une catégorie propose des produits différents de la page un, même si le texte environnant est similaire. Cette meilleure compréhension signifie qu’une division en pages bien structurée, avec des différences significatives entre pages, bénéficie plus que jamais d’une indexation indépendante.
Cependant, l’IA détecte aussi mieux les contenus vraiment faibles ou dupliqués sur les pages paginées, rendant plus difficile la manipulation du système avec des pages à peine différenciées. Les algorithmes d’apprentissage automatique prédisent plus précisément l’intention utilisateur, mettant potentiellement en avant des pages profondes pour des requêtes longue traîne spécifiques lorsque ces pages correspondent le mieux à l’intention de recherche. Cela implique de s’assurer que chaque page paginée offre une réelle valeur unique—des produits distincts, du contenu différent ou des variantes significatives—plutôt que de simples divisions mécaniques d’une information identique. À mesure que l’IA continue de progresser, les principes fondamentaux restent constants : URL distinctes, liens explorables, valeur unique par page et métadonnées claires continueront de déterminer l’efficacité de la pagination pour la visibilité IA.
Suivez comment votre contenu apparaît dans les réponses générées par l'IA sur ChatGPT, Perplexity et d'autres moteurs de recherche IA. Assurez-vous que votre marque est citée lorsque les systèmes d'IA répondent à des questions sur votre secteur.
La pagination divise de grands ensembles de contenu en pages gérables pour une meilleure expérience utilisateur et un meilleur référencement. Découvrez comment ...
Pages par session mesure la moyenne de pages vues par visite. Découvrez comment cette métrique d’engagement influence le comportement utilisateur, les taux de c...
L’élagage de contenu est la suppression ou la mise à jour stratégique du contenu sous-performant pour améliorer le SEO, l’expérience utilisateur et la visibilit...