Algorithme Sonar
L’Algorithme Sonar est le système RAG propriétaire de Perplexity combinant recherche hybride, réordonnancement neuronal et génération de citations en temps réel...
17 min de lecture

Découvrez comment l’algorithme Sonar de Perplexity alimente la recherche IA en temps réel avec des modèles économiques. Explorez les variantes Sonar, Sonar Pro et Sonar Reasoning.
Sonar est la famille de modèles de recherche légère et économique de Perplexity, optimisée pour l'intégration de la recherche web en temps réel avec les grands modèles de langage. Il combine une récupération rapide avec des réponses fondées, proposant plusieurs variantes dont Sonar de base pour des questions-réponses rapides, Sonar Pro pour les requêtes complexes, et Sonar Reasoning pour la résolution de problèmes en chaîne de raisonnement avec accès web en direct.
Sonar est la famille de modèles de recherche propriétaire de Perplexity conçue pour intégrer des capacités de recherche web en temps réel directement dans les grands modèles de langage afin de générer des réponses fondées et précises. Contrairement aux moteurs de recherche traditionnels qui renvoient des liens bleus, les algorithmes Sonar alimentent une expérience de recherche centrée IA où le modèle synthétise des informations provenant de multiples sources pour fournir des réponses complètes et citées. La famille Sonar représente une évolution fondamentale dans la façon dont les systèmes d’IA accèdent et traitent l’information actuelle, permettant aux modèles de répondre à des questions sur des événements récents, des actualités ou des données à jour sans dépendre de données d’entraînement statiques. Cette technologie est cruciale dans le paysage en mutation des moteurs de recherche IA comme Perplexity, ChatGPT avec recherche web, Google AI Overviews et Claude, où la récupération d’informations en temps réel est devenue essentielle pour maintenir précision et pertinence.
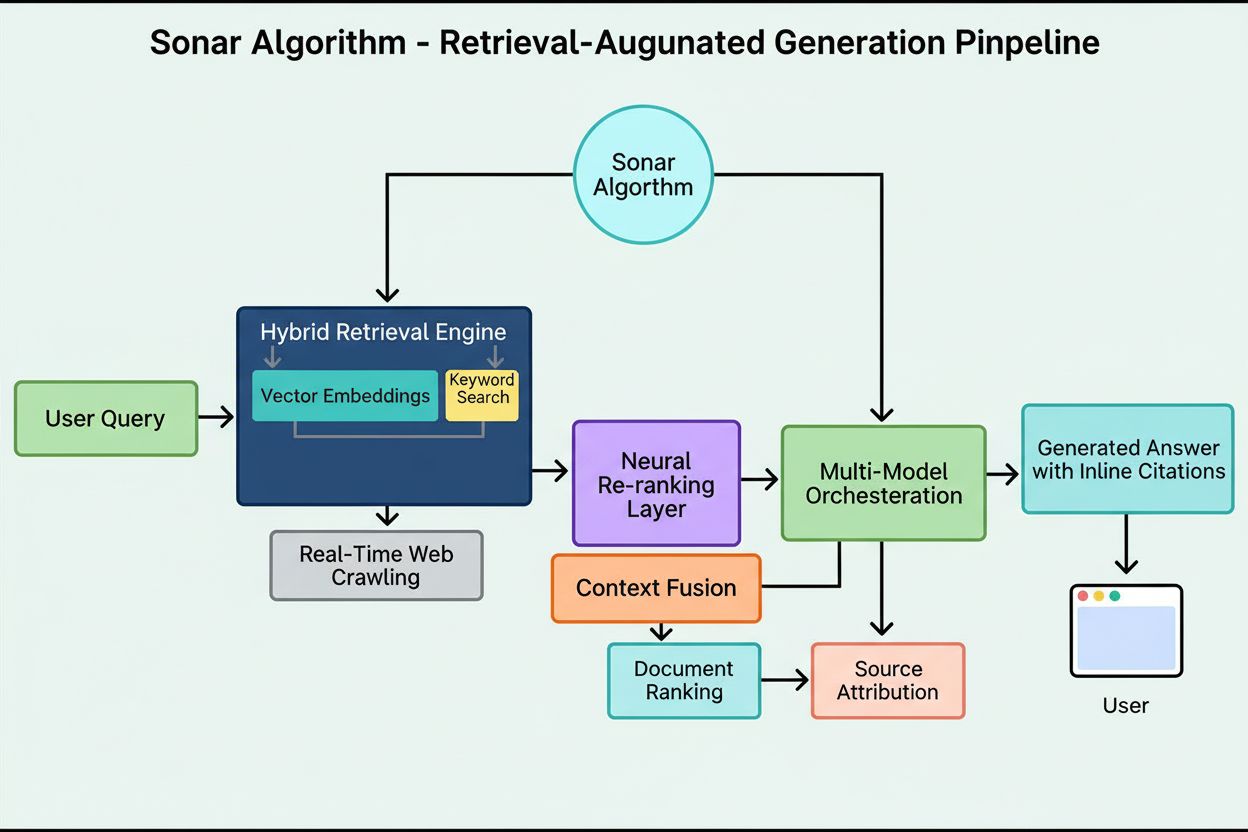
L’infrastructure de recherche de Perplexity traite plus de 200 millions de requêtes quotidiennes et maintient un index suivant plus de 200 milliards d’URL uniques, en faisant l’un des index web les plus vastes et fréquemment mis à jour, optimisé spécifiquement pour la consommation par l’IA. L’algorithme Sonar a été développé pour répondre aux limitations critiques des API de recherche héritées, conçues pour les humains et non pour les modèles IA. Les API de recherche traditionnelles facturent des frais exorbitants (certains fournisseurs demandaient 200 $ pour mille requêtes), fonctionnent sur des index obsolètes et renvoient des résultats au niveau du document, trop grossiers pour des modèles IA aux fenêtres de contexte limitées. Sonar résout ces problèmes via une chaîne hybride de récupération et classement combinant des signaux de recherche lexicale (basée sur des mots-clés) et de recherche sémantique (basée sur le sens) pour identifier les informations les plus pertinentes à un niveau sous-documentaire.
L’architecture de Sonar repose sur trois principes fondamentaux : exhaustivité, fraîcheur et rapidité. L’index de recherche doit cartographier le web de façon exhaustive, être constamment mis à jour pour refléter la dernière information, et répondre aux requêtes en quelques millisecondes pour prendre en charge les applications IA en temps réel. L’infrastructure de crawling de Perplexity comprend des dizaines de milliers de CPUs et des centaines de téraoctets de RAM, permettant au système de traiter des dizaines de milliers d’opérations d’indexation par seconde. Les modèles de machine learning prédisent quelles URL doivent être indexées et quand planifier ces opérations, garantissant que les documents à fort trafic et fréquemment mis à jour restent actuels tout en maintenant un rythme de crawl maîtrisé pour les opérateurs de sites web.
| Variante de Modèle | Cas d’Usage Principal | Fonctionnalités Clés | Longueur de Contexte | Optimisation |
|---|---|---|---|---|
| Sonar (Base) | Questions-réponses rapides et recherches simples | Léger, économique, recherche web en temps réel | 128K tokens | Rapidité et accessibilité |
| Sonar Pro | Requêtes complexes et recherche avancée | Récupération améliorée, personnalisation des sources, citations | 128K tokens | Précision et gestion de la complexité |
| Sonar Reasoning | Résolution logique et analyse | Raisonnement en chaîne, inférence étape par étape | 128K tokens | Raisonnement profond avec recherche en direct |
| Sonar Reasoning Pro | Analyse complexe hautes performances | Chaîne de raisonnement multi-étapes avancée, récupération améliorée | 128K tokens | Capacité de raisonnement maximale |
La famille Sonar de Perplexity comprend quatre variantes de modèles distinctes, chacune optimisée pour des cas d’usage et niveaux de complexité différents. Le modèle Sonar de base est l’option la plus légère et économique, pensée pour un usage quotidien comme la synthèse de contenus, la recherche de définitions ou la consultation de l’actualité. Il traite les requêtes à 1 $ par million de tokens en entrée et 1 $ par million de tokens en sortie, le rendant bien plus abordable que les solutions concurrentes. Sonar Pro s’appuie sur cette base avec des capacités accrues pour gérer les requêtes complexes et multi-étapes nécessitant des analyses approfondies et une personnalisation des sources. Les utilisateurs peuvent spécifier quelles sources privilégier ou exclure, pour un contrôle granulaire sur la récupération d’informations.
Sonar Reasoning introduit le raisonnement en chaîne de pensée (Chain-of-Thought, CoT), une technique où le modèle travaille explicitement les problèmes étape par étape avant d’aboutir à des conclusions. Cette variante est propulsée par la technologie DeepSeek-R1 et excelle dans le raisonnement logique, la résolution de problèmes mathématiques et l’analyse structurée. Sonar Reasoning Pro représente le niveau de performance le plus élevé, combinant raisonnement multi-étapes avancé et récupération d’informations renforcée pour les tâches d’analyse les plus exigeantes. Toutes les variantes Sonar disposent d’un contexte de 128K tokens, offrant un espace conséquent pour traiter de longs documents, plusieurs sources et des requêtes complexes.
L’algorithme Sonar met en œuvre une chaîne de récupération et classement multi-étapes qui affine progressivement les résultats de recherche avec une sophistication croissante. Le processus débute par la recherche hybride, où le système interroge l’index à la fois par méthodes lexicales et sémantiques, puis fusionne les résultats dans un ensemble de candidats exhaustif. Cette double approche garantit la prise en compte des correspondances sur mots-clés et des contenus conceptuellement similaires. Les étapes suivantes appliquent des heuristiques de pré-filtrage pour éliminer les contenus manifestement non pertinents ou obsolètes, puis procèdent à plusieurs rounds de classement avec des modèles de plus en plus avancés.
Les premiers classements utilisent des scores lexicaux et par embeddings optimisés pour la rapidité, tandis que les étapes ultérieures s’appuient sur des modèles de reranking cross-encoder pour une analyse sémantique sophistiquée. Toute la chaîne fonctionne à la fois au niveau du document et du sous-document, ce qui permet d’identifier et d’extraire des paragraphes, sections ou même phrases répondant directement à une requête, sans forcer l’utilisateur à parcourir toute la page web. Cette compréhension fine du contenu est cruciale pour les modèles IA, où chaque token de contexte compte et où l’information non pertinente peut nuire à la performance. Le module de compréhension du contenu de Perplexity utilise des règles dynamiques et une auto-amélioration pilotée par IA pour analyser la structure complexe et variée du web, s’adaptant continuellement à de nouveaux formats de sites et modèles de contenu.
Les modèles Sonar de Perplexity ont démontré des performances exceptionnelles lors d’évaluations rigoureuses face à d’autres solutions de recherche IA. À travers des benchmarks comme SimpleQA, FRAMES, BrowseComp et HLE, les variantes Sonar ont constamment surpassé les modèles de Google Gemini 2.0 Flash, OpenAI GPT-4o Search et autres systèmes IA de pointe. Sur le benchmark SimpleQA, Sonar a obtenu un score de 0,930, dépassant significativement des concurrents comme Brave Search (0,822) et les API basées sur les SERP (0,890). Pour les tâches de recherche approfondie mesurées par le benchmark HLE, Sonar a atteint 0,288, bien devant les autres fournisseurs.
Au-delà des métriques de qualité, Sonar excelle en latence, un facteur clé pour les applications orientées utilisateur. La latence médiane de recherche chez Perplexity est de 358 millisecondes, soit plus de 150 millisecondes plus rapide que le deuxième fournisseur le plus rapide. La latence au 95e percentile reste sous les 800 millisecondes, garantissant une performance constante même en période de forte charge. Cet avantage de rapidité provient des investissements infrastructurels de Perplexity, incluant l’indexation distribuée sur des centaines de téraoctets de stockage, des stratégies de cache intelligentes et des pipelines d’inférence optimisés. La combinaison d’une qualité de pointe et d’une rapidité inégalée signifie que les développeurs n’ont plus à choisir entre rapidité d’application et précision des résultats.
Les algorithmes Sonar représentent un changement de paradigme dans l’accès à l’information en temps réel par l’IA, fondamentalement différent des moteurs de recherche classiques et des premiers chatbots IA. ChatGPT avec recherche web et Google AI Overviews proposent des capacités en temps réel, mais Sonar est spécifiquement conçu pour l’usage IA, plutôt que d’adapter une recherche humaine aux modèles IA. L’API Sonar offre aux développeurs un accès programmatique à l’infrastructure de recherche de Perplexity, leur permettant de créer des applications IA nécessitant des informations actualisées sans gérer eux-mêmes le crawling, l’indexation et le classement.
L’infrastructure de recherche de Perplexity traite les requêtes avec des réponses basées sur la recherche web en temps réel comportant des résultats détaillés et des citations, permettant aux utilisateurs de vérifier les sources d’information. Le système fournit en moyenne 5,01 liens par réponse, se situant entre ChatGPT (10,42 liens) et d’autres outils de recherche IA. Cette approche équilibrée offre une diversité suffisante des sources pour la vérification sans submerger l’utilisateur de citations. La capacité de l’algorithme Sonar à citer les sources est particulièrement importante pour la surveillance de marque et la visibilité des contenus, car les organisations peuvent suivre l’apparition de leurs domaines dans les réponses générées par l’IA sur des plateformes comme Perplexity, ChatGPT, Claude et Google AI Overviews à l’aide d’outils comme AmICited, spécialisé dans le suivi des marques et domaines dans les résultats IA.
Les algorithmes Sonar alimentent des applications variées dans la recherche, l’intelligence économique, la création de contenu et la récupération d’informations en temps réel. Les chercheurs utilisent Sonar pour effectuer des revues de littérature exhaustives et synthétiser l’information de multiples sources avec citations appropriées. Les analystes commerciaux exploitent Sonar Pro pour l’intelligence concurrentielle, la veille marché et l’analyse de tendances nécessitant des données actualisées. Les créateurs de contenu utilisent Sonar pour vérifier des faits, trouver des exemples récents et s’assurer que leur travail reflète les évolutions les plus récentes de leur domaine. Les rédactions et fact-checkeurs s’appuient sur les capacités de recherche en temps réel de Sonar pour vérifier les affirmations et fournir du contexte sur les actualités.
Les variantes Sonar Reasoning sont particulièrement précieuses pour la résolution technique de problèmes, où l’analyse pas à pas combinée à l’information actuelle donne de meilleurs résultats. Les développeurs logiciels utilisent Sonar Reasoning pour résoudre des problèmes en accédant à la dernière documentation, aux discussions Stack Overflow et aux dépôts GitHub. Les data scientists s’appuient sur Sonar pour suivre l’évolution rapide des méthodologies et accéder à des publications récentes. Les professionnels de la finance utilisent Sonar Pro pour surveiller les marchés, suivre la réglementation et analyser les tendances émergentes. La capacité de combiner recherche web en temps réel et raisonnement avancé rend Sonar particulièrement précieux dans les domaines où l’information évolue vite et où la précision est primordiale.
L’algorithme Sonar n’est qu’un début dans l’infrastructure de recherche native à l’IA. Les recherches de Perplexity montrent que les moteurs de recherche hérités plafonnent autour de 10 milliards de requêtes par jour, alors que la prochaine génération de recherche IA servira des ordres de grandeur supérieurs à mesure que les agents IA autonomes se généralisent. Les futures versions de Sonar devront relever de nouveaux défis, dont l’extension efficace face à la croissance exponentielle des requêtes, des approches novatrices d’ingénierie du contexte adaptées à des modèles IA de plus en plus sophistiqués, et la gestion permanente du compromis entre exhaustivité, fraîcheur et latence.
L’infrastructure de Perplexity est idéalement positionnée pour relever ces défis, combinant un système de recherche en production massif desservant des millions d’utilisateurs quotidiens avec une expertise technique et des capacités de recherche. Le module de compréhension auto-améliorée du contenu de la société montre comment l’IA peut améliorer continuellement la qualité de la recherche sans intervention humaine. À mesure que les agents IA deviennent plus autonomes et performants, la qualité de leur infrastructure de recherche devient de plus en plus cruciale. L’évolution de Sonar inclura probablement une intégration plus poussée avec les workflows agentiques, une curation contextuelle plus sophistiquée pour des architectures de modèles IA spécifiques, et des capacités renforcées de vérification des sources pour lutter contre la désinformation. Les organisations souhaitant conserver leur visibilité dans cet environnement évolutif devraient surveiller leur marque sur les plateformes de recherche IA à l’aide d’outils spécialisés, afin que leur contenu reste une référence et soit correctement cité alors que les systèmes IA deviennent l’interface principale de la découverte d’information.
Suivez quand votre domaine apparaît dans les réponses Sonar de Perplexity et d'autres résultats de recherche IA. Assurez-vous que votre contenu est cité comme source d'autorité sur toutes les grandes plateformes IA.
L’Algorithme Sonar est le système RAG propriétaire de Perplexity combinant recherche hybride, réordonnancement neuronal et génération de citations en temps réel...

Perplexity AI est un moteur de réponses alimenté par l’IA qui combine la recherche web en temps réel avec des LLM pour fournir des réponses précises et sourcées...
Découvrez comment fonctionnent les moteurs de recherche IA comme ChatGPT, Perplexity et Google AI Overviews. Découvrez les LLM, RAG, la recherche sémantique et ...