Le degré auquel les plateformes d’IA divulguent la façon dont elles sélectionnent et classent les sources lors de la génération de réponses. La transparence du classement par l’IA fait référence à la visibilité des algorithmes et des critères qui déterminent quelles sources apparaissent dans les réponses générées par l’IA, ce qui la distingue du classement traditionnel des moteurs de recherche. Cette transparence est essentielle pour les créateurs de contenu, les éditeurs et les utilisateurs qui ont besoin de comprendre comment l’information est sélectionnée et hiérarchisée. Sans transparence, les utilisateurs ne peuvent pas vérifier la crédibilité des sources ni comprendre les biais potentiels dans le contenu généré par l’IA.
Transparence du classement par l'IA
Le degré auquel les plateformes d'IA divulguent la façon dont elles sélectionnent et classent les sources lors de la génération de réponses. La transparence du classement par l'IA fait référence à la visibilité des algorithmes et des critères qui déterminent quelles sources apparaissent dans les réponses générées par l'IA, ce qui la distingue du classement traditionnel des moteurs de recherche. Cette transparence est essentielle pour les créateurs de contenu, les éditeurs et les utilisateurs qui ont besoin de comprendre comment l'information est sélectionnée et hiérarchisée. Sans transparence, les utilisateurs ne peuvent pas vérifier la crédibilité des sources ni comprendre les biais potentiels dans le contenu généré par l'IA.
Qu’est-ce que la transparence du classement par l’IA ?
La transparence du classement par l’IA fait référence à la divulgation de la manière dont les systèmes d’intelligence artificielle sélectionnent, priorisent et présentent les sources lors de la génération de réponses aux requêtes des utilisateurs. Contrairement aux moteurs de recherche traditionnels qui affichent des listes classées de liens, les plateformes d’IA modernes telles que Perplexity, ChatGPT et les AI Overviews de Google intègrent la sélection des sources dans leur processus de génération de réponses, rendant les critères de classement largement invisibles pour les utilisateurs. Cette opacité crée un écart critique entre ce que voient les utilisateurs (une réponse synthétisée) et la façon dont cette réponse a été construite (quelles sources ont été choisies, pondérées et citées). Pour les créateurs de contenu et les éditeurs, ce manque de transparence signifie que leur visibilité dépend d’algorithmes qu’ils ne peuvent ni comprendre ni influencer via les méthodes d’optimisation traditionnelles. La distinction avec la transparence des moteurs de recherche traditionnels est significative : alors que Google publie des facteurs de classement généraux et des directives de qualité, les plateformes d’IA traitent souvent leurs mécanismes de sélection des sources comme des secrets commerciaux propriétaires. Les parties prenantes concernées incluent les créateurs de contenu cherchant de la visibilité, les éditeurs préoccupés par l’attribution du trafic, les responsables de marque surveillant la réputation, les chercheurs vérifiant les sources d’information et les utilisateurs qui ont besoin de comprendre la crédibilité des réponses générées par l’IA. Comprendre la transparence du classement par l’IA est devenu essentiel pour toute personne produisant, distribuant ou s’appuyant sur du contenu numérique dans un paysage informationnel de plus en plus médié par l’IA.
Comment les plateformes d’IA classent et sélectionnent les sources
Les plateformes d’IA utilisent des systèmes de génération augmentée par récupération (RAG) qui combinent des modèles de langage avec une récupération d’information en temps réel afin d’ancrer les réponses dans des sources réelles plutôt que de s’appuyer uniquement sur les données d’entraînement. Le processus RAG comporte trois étapes principales : la récupération (trouver des documents pertinents), le classement (ordonner les sources par pertinence) et la génération (synthétiser l’information tout en maintenant les citations). Différentes plateformes mettent en œuvre des approches de classement distinctes — Perplexity privilégie l’autorité des sources et la fraîcheur, les AI Overviews de Google mettent l’accent sur la pertinence thématique et les signaux E-E-A-T (Expérience, Expertise, Autorité, Fiabilité), tandis que ChatGPT Search équilibre la qualité des sources avec l’exhaustivité des réponses. Les facteurs influençant la sélection des sources incluent généralement l’autorité du domaine (réputation établie et profil de liens), la fraîcheur du contenu (actualité de l’information), la pertinence thématique (alignement sémantique avec la requête), les signaux d’engagement (mesures d’interaction des utilisateurs) et la fréquence de citation (fréquence à laquelle les sources sont référencées par d’autres sites faisant autorité). Les systèmes d’IA pondèrent ces signaux différemment selon l’intention de la requête — les requêtes factuelles peuvent privilégier l’autorité et la fraîcheur, tandis que les requêtes d’opinion peuvent mettre l’accent sur la diversité des perspectives et l’engagement. Les algorithmes de classement restent en grande partie non divulgués, bien que la documentation des plateformes fournisse un aperçu limité de leurs mécanismes de pondération.
L’industrie de l’IA manque de pratiques normalisées de divulgation sur le fonctionnement des systèmes de classement, créant un paysage fragmenté où chaque plateforme détermine son propre niveau de transparence. ChatGPT Search d’OpenAI fournit peu d’explications sur la sélection des sources, les systèmes d’IA de Meta offrent une documentation limitée, et les AI Overviews de Google divulguent plus que leurs concurrents mais retiennent encore des détails algorithmiques critiques. Les plateformes résistent à une divulgation totale invoquant l’avantage concurrentiel, la propriété intellectuelle et la complexité d’expliquer les systèmes d’apprentissage automatique au grand public — cependant, cette opacité empêche l’audit externe et la responsabilité. Le problème du « blanchiment des sources » émerge lorsque les systèmes d’IA citent des sources qui elles-mêmes agrègent ou réécrivent du contenu original, obscurcissant la véritable origine de l’information et pouvant amplifier la désinformation à travers plusieurs couches de synthèse. La pression réglementaire augmente : l’AI Act de l’UE exige que les systèmes d’IA à haut risque tiennent une documentation sur les données d’entraînement et les processus de décision, tandis que la politique de responsabilité de l’IA de la NTIA demande aux entreprises de divulguer les capacités, les limites et les cas d’usage appropriés de leurs systèmes d’IA. Les manquements spécifiques à la divulgation incluent les difficultés initiales de Perplexity à attribuer correctement (corrigées depuis), l’explication vague de Google sur la sélection des sources dans les AI Overviews, et la transparence limitée de ChatGPT sur les raisons pour lesquelles certaines sources figurent dans les réponses et d’autres non. L’absence de métriques standardisées pour mesurer la transparence rend difficile la comparaison objective des plateformes par les utilisateurs et les régulateurs.
Impact sur les créateurs de contenu et les éditeurs
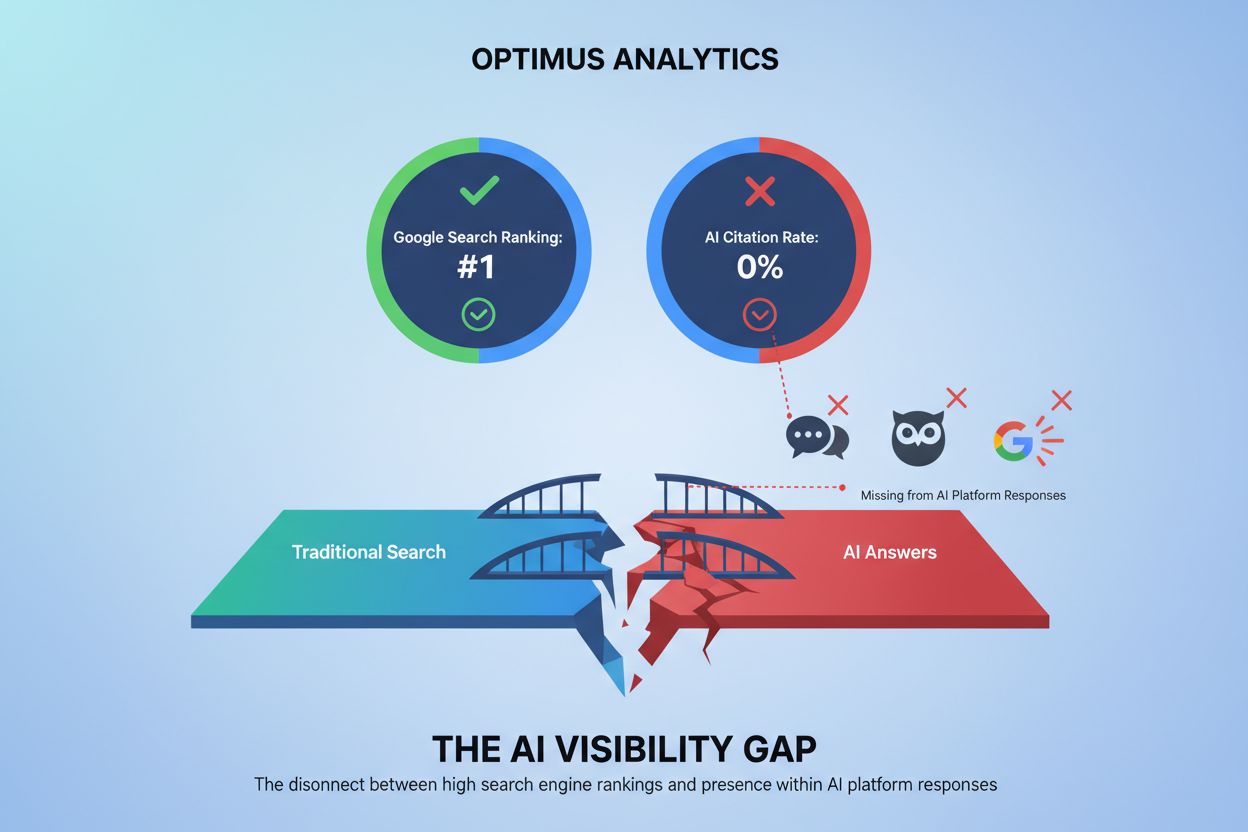
L’opacité des systèmes de classement par l’IA crée des défis significatifs de visibilité pour les créateurs de contenu, car les stratégies SEO traditionnelles conçues pour les moteurs de recherche ne s’appliquent pas directement à l’optimisation pour les plateformes d’IA. Les éditeurs ne peuvent pas facilement comprendre pourquoi leur contenu apparaît dans certaines réponses IA mais pas dans d’autres, rendant impossible le développement de stratégies ciblées pour améliorer la visibilité dans les réponses générées par l’IA. Un biais de citation émerge lorsque les systèmes d’IA favorisent de manière disproportionnée certaines sources — grands médias, institutions académiques ou sites à fort trafic — tout en marginalisant les petits éditeurs, créateurs indépendants et experts de niches qui peuvent pourtant apporter des informations de valeur égale. Les petits éditeurs font face à des désavantages particuliers car les systèmes de classement par l’IA pondèrent souvent fortement l’autorité du domaine, et les sites plus récents ou spécialisés n’ont pas le profil de liens ou la notoriété des acteurs établis. Une étude de Search Engine Land montre que les AI Overviews ont réduit le taux de clics vers les résultats de recherche traditionnels de 18 à 64 % selon le type de requête, avec un trafic concentré parmi les rares sources citées dans les réponses IA. La distinction entre SEO (Search Engine Optimization) et GEO (Generative Engine Optimization) devient cruciale — alors que le SEO vise le classement dans la recherche traditionnelle, le GEO nécessite de comprendre et d’optimiser pour les critères de sélection des plateformes IA, qui restent largement opaques. Les créateurs de contenu ont besoin d’outils comme AmICited.com pour surveiller où leur contenu apparaît dans les réponses IA, suivre la fréquence des citations et comprendre leur visibilité sur différentes plateformes d’IA.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Mécanismes et standards de transparence
L’industrie de l’IA a développé plusieurs cadres pour documenter et divulguer le comportement des systèmes, bien que leur adoption reste inégale selon les plateformes. Les Model Cards fournissent une documentation standardisée sur la performance des modèles d’apprentissage automatique, les cas d’usage prévus, les limites et l’analyse des biais — similaires aux étiquettes nutritionnelles pour les systèmes d’IA. Les Datasheets for Datasets documentent la composition, la méthodologie de collecte et les biais potentiels dans les données d’entraînement, en partant du principe que les systèmes d’IA ne valent que par la qualité de leurs données d’entraînement. Les System Cards adoptent une approche plus large, documentant le comportement du système dans son ensemble, y compris les interactions entre les composants, les modes de défaillance potentiels et la performance réelle selon les groupes d’utilisateurs. La politique de responsabilité IA de la NTIA recommande aux entreprises de tenir une documentation détaillée du développement, des tests et du déploiement des systèmes d’IA, en insistant particulièrement sur les applications à haut risque affectant l’intérêt public. L’AI Act de l’UE impose aux systèmes d’IA à haut risque de maintenir une documentation technique, des enregistrements des données d’entraînement et des journaux de performance, avec des exigences de rapports de transparence et d’information des utilisateurs. Les bonnes pratiques du secteur incluent de plus en plus :
Model Cards — Métriques de performance, cas d’usage, limites, analyse des biais
Datasheets — Sources des données d’entraînement, méthodes de collecte, biais potentiels
System Cards — Comportement global, interactions des composants, modes de défaillance
Rapports techniques — Détails d’architecture, décisions de conception, méthodologie d’évaluation
Rapports de transparence — Divulgation régulière des performances, plaintes utilisateurs, changements d’algorithmes
Documentation API — Explication des facteurs de classement, critères de sélection des sources, options de contrôle utilisateur
Comparaison des approches de transparence des plateformes d’IA
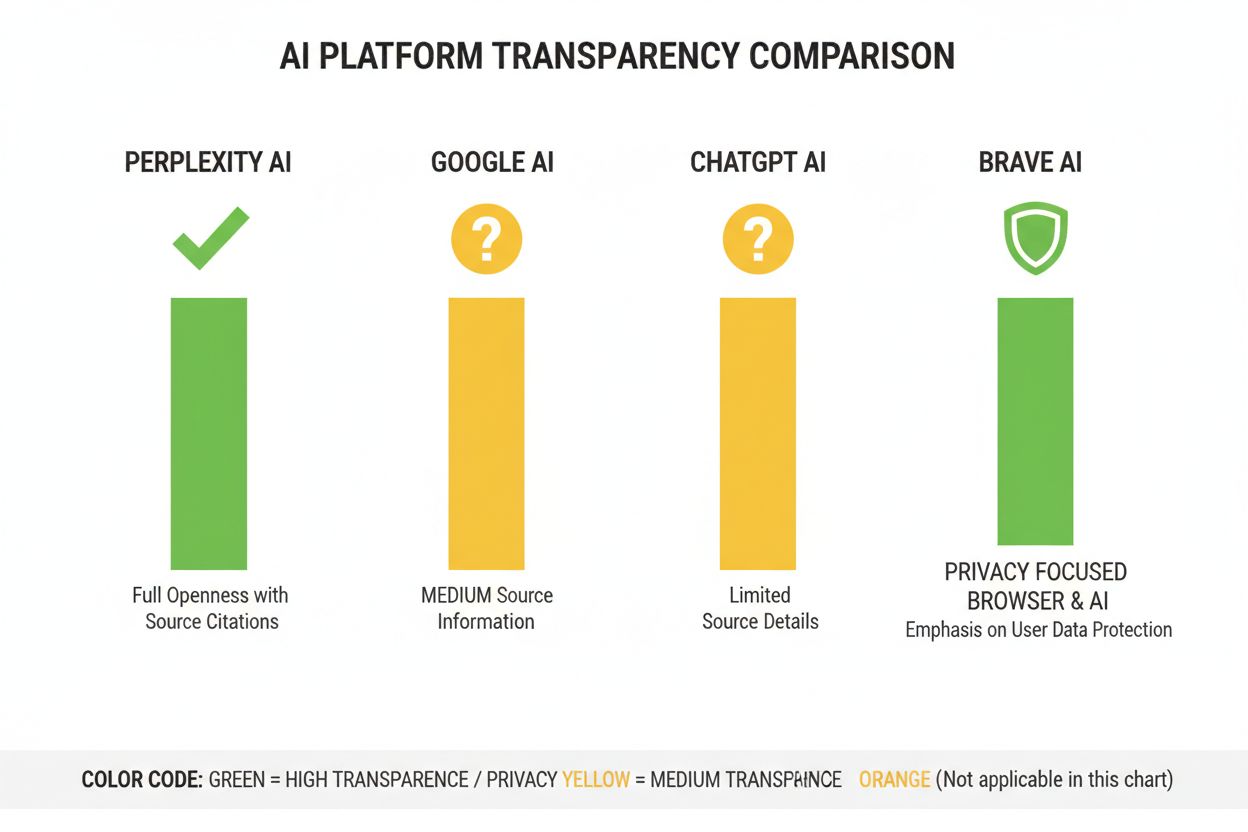
Perplexity s’est positionnée comme la plateforme d’IA la plus transparente en matière de citation, affichant des liens sources en ligne dans toutes les réponses et permettant aux utilisateurs de voir exactement quelles sources ont contribué à chaque affirmation. La plateforme fournit une documentation relativement claire sur son approche de classement, mettant l’accent sur l’autorité des sources, l’expertise thématique et la fraîcheur du contenu, bien que la pondération précise de ces facteurs reste propriétaire. Les AI Overviews de Google offrent une transparence modérée en listant les sources citées à la fin des réponses, mais fournissent peu d’explications sur les raisons du choix de certaines sources plutôt que d’autres ou la manière dont l’algorithme de classement pondère les signaux. La documentation de Google met en avant les principes E-E-A-T mais ne détaille pas complètement la façon dont ceux-ci sont mesurés ou pondérés dans le classement IA. ChatGPT Search d’OpenAI représente un compromis, affichant les sources séparément du texte de la réponse et permettant aux utilisateurs d’accéder au contenu original, tout en offrant peu d’explications sur les critères de sélection des sources ou la méthodologie de classement. Brave Leo privilégie une transparence axée sur la confidentialité, révélant qu’il utilise des sources respectueuses de la vie privée et ne trace pas les requêtes utilisateurs, au prix d’une explication moins détaillée de ses mécanismes de classement. Consensus se distingue en se concentrant exclusivement sur la recherche académique, offrant une grande transparence via des métriques de citation, le statut d’évaluation par les pairs et des indicateurs de qualité d’étude — en faisant la plateforme la plus transparente algorithmiquement pour les requêtes orientées recherche. Le contrôle utilisateur varie fortement : Perplexity permet le filtrage des sources, Consensus autorise le filtrage par type et qualité d’étude, tandis que Google et ChatGPT offrent peu de personnalisation des préférences de classement. La variation des approches de transparence reflète différents modèles économiques et publics cibles, les plateformes axées sur l’académique privilégiant la divulgation alors que les plateformes grand public équilibrent transparence et préoccupations propriétaires.
Pourquoi la transparence du classement est importante
La confiance et la crédibilité reposent fondamentalement sur la compréhension par les utilisateurs de la façon dont l’information leur parvient — lorsque les systèmes d’IA occultent leurs sources ou leur logique de classement, les utilisateurs ne peuvent pas vérifier indépendamment les affirmations ni évaluer la fiabilité des sources. La transparence permet la vérification et la fact-checking, donnant aux chercheurs, journalistes et utilisateurs avertis la possibilité de remonter aux sources originales et d’évaluer l’exactitude et le contexte des affirmations. Les bénéfices de la prévention de la désinformation et des biais sont considérables : lorsque les algorithmes de classement sont visibles, les chercheurs peuvent identifier les biais systémiques (tels que le favoritisme envers certaines perspectives politiques ou intérêts commerciaux), et les plateformes peuvent être tenues responsables de l’amplification de fausses informations. La responsabilité algorithmique représente un droit fondamental des utilisateurs dans les sociétés démocratiques — chacun mérite de comprendre comment les systèmes qui façonnent leur environnement informationnel prennent des décisions, surtout lorsqu’ils influencent l’opinion publique, les décisions d’achat ou l’accès au savoir. Pour la recherche et le travail académique, la transparence est essentielle car les chercheurs doivent comprendre la sélection des sources pour contextualiser correctement les résumés générés par l’IA et s’assurer qu’ils ne s’appuient pas involontairement sur des ensembles de sources biaisés ou incomplets. Les implications commerciales pour les créateurs de contenu sont profondes : sans comprendre les facteurs de classement, les éditeurs ne peuvent pas optimiser leur stratégie de contenu, les petits créateurs ne peuvent pas rivaliser équitablement avec les acteurs établis, et l’ensemble de l’écosystème devient moins méritocratique. La transparence protège également les utilisateurs contre la manipulation — lorsque les critères de classement sont cachés, des acteurs malveillants peuvent exploiter des vulnérabilités inconnues pour promouvoir du contenu trompeur, alors que des systèmes transparents peuvent être audités et améliorés.
L’avenir de la transparence du classement par l’IA
Les tendances réglementaires poussent vers une transparence obligatoire : la mise en œuvre de l’AI Act de l’UE en 2025-2026 exigera une documentation et une divulgation détaillées pour les systèmes d’IA à haut risque, tandis que des réglementations similaires émergent au Royaume-Uni, en Californie et ailleurs. L’industrie évolue vers une standardisation des pratiques de transparence, avec des organisations comme le Partnership on AI et des institutions académiques développant des cadres communs pour documenter et divulguer le comportement des systèmes d’IA. La demande des utilisateurs pour la transparence augmente à mesure que la conscience du rôle de l’IA dans la distribution de l’information grandit — des enquêtes indiquent que plus de 70 % des utilisateurs souhaitent comprendre comment les systèmes d’IA sélectionnent les sources et classent l’information. Les innovations techniques en IA explicable (XAI) rendent de plus en plus possible de fournir des explications détaillées sur les décisions de classement sans exposer complètement les algorithmes propriétaires, grâce à des techniques comme LIME (Local Interpretable Model-agnostic Explanations) et SHAP (SHapley Additive exPlanations). Des outils de suivi comme AmICited.com deviendront de plus en plus importants à mesure que les plateformes déploient des mesures de transparence, aidant les créateurs de contenu et éditeurs à suivre leur visibilité sur plusieurs systèmes d’IA et à comprendre comment les changements de classement affectent leur portée. La convergence des exigences réglementaires, des attentes des utilisateurs et des capacités techniques suggère que 2025-2026 sera une période charnière pour la transparence du classement par l’IA, les plateformes adoptant probablement des pratiques de divulgation plus standardisées, mettant en œuvre de meilleurs contrôles utilisateurs sur la sélection des sources et fournissant des explications plus claires de la logique de classement. Le paysage futur sera probablement caractérisé par une transparence à plusieurs niveaux — des plateformes axées sur l’académique et la recherche en tête avec un haut niveau de divulgation, des plateformes grand public offrant une transparence modérée avec des options de personnalisation, et la conformité réglementaire devenant la norme minimale dans l’ensemble du secteur.
Questions fréquemment posées
Qu'est-ce que la transparence du classement par l'IA et pourquoi est-ce important ?
La transparence du classement par l'IA fait référence à la manière dont les plateformes d'IA divulguent ouvertement leurs algorithmes de sélection et de classement des sources dans les réponses générées. Cela importe parce que les utilisateurs doivent comprendre la crédibilité des sources, les créateurs de contenu doivent optimiser leur visibilité auprès de l'IA, et les chercheurs doivent vérifier les sources d'information. Sans transparence, les systèmes d'IA peuvent amplifier la désinformation et créer des avantages injustes pour les médias établis au détriment des petits éditeurs.
Comment les plateformes d'IA comme Perplexity et Google sélectionnent-elles les sources ?
Les plateformes d'IA utilisent des systèmes à génération augmentée par récupération (RAG) qui combinent des modèles de langage avec une récupération d'informations en temps réel. Elles classent les sources en fonction de facteurs tels que l'autorité du domaine, la fraîcheur du contenu, la pertinence thématique, les signaux d'engagement et la fréquence de citation. Cependant, la pondération exacte de ces facteurs reste en grande partie propriétaire et non divulguée par la plupart des plateformes.
Quelle est la différence entre la transparence du classement par l'IA et le SEO traditionnel ?
Le SEO traditionnel se concentre sur le classement dans les listes de liens des moteurs de recherche, où Google publie des facteurs de classement généraux. La transparence du classement par l'IA concerne la façon dont les plateformes d'IA sélectionnent les sources pour fournir des réponses synthétisées, ce qui implique des critères différents et est largement non divulgué. Alors que les stratégies SEO sont bien documentées, les facteurs de classement de l'IA restent pour la plupart opaques.
Comment puis-je vérifier si les sources citées par l'IA sont exactes ?
Vous pouvez cliquer sur les sources originales pour vérifier les affirmations dans leur contexte complet, vérifier si les sources proviennent de domaines faisant autorité, rechercher le statut d'évaluation par les pairs (notamment pour les contenus académiques), et croiser les informations entre plusieurs sources. Des outils comme AmICited aident à suivre quelles sources apparaissent dans les réponses IA et à quelle fréquence votre contenu est cité.
Quelles plateformes d'IA sont les plus transparentes sur leurs méthodes de classement ?
Consensus se distingue par sa transparence en se concentrant exclusivement sur la recherche académique évaluée par les pairs avec des métriques de citation claires. Perplexity fournit des citations de sources en ligne et une documentation modérée sur les facteurs de classement. Les AI Overviews de Google offrent une transparence moyenne, tandis que ChatGPT Search et Brave Leo fournissent une divulgation limitée de leurs algorithmes de classement.
Que sont les model cards et les datasheets dans la transparence de l'IA ?
Les model cards sont des documents standardisés sur la performance d'un système d'IA, ses usages prévus, ses limites et l'analyse des biais. Les datasheets documentent la composition des données d'entraînement, les méthodes de collecte et les biais potentiels. Les system cards décrivent le comportement global du système. Ces outils rendent les systèmes d'IA plus transparents et comparables, à la manière des étiquettes nutritionnelles pour l'alimentation.
Comment l'AI Act de l'UE affecte-t-il la transparence du classement par l'IA ?
L'AI Act de l'UE exige que les systèmes d'IA à haut risque tiennent une documentation technique détaillée, des enregistrements des données d'entraînement et des journaux de performance. Il impose des rapports de transparence et l'information des utilisateurs sur l'utilisation du système d'IA. Ces exigences poussent les plateformes d'IA à un plus grand dévoilement des mécanismes de classement et des critères de sélection des sources.
Qu'est-ce qu'AmICited et comment surveille-t-il les citations IA ?
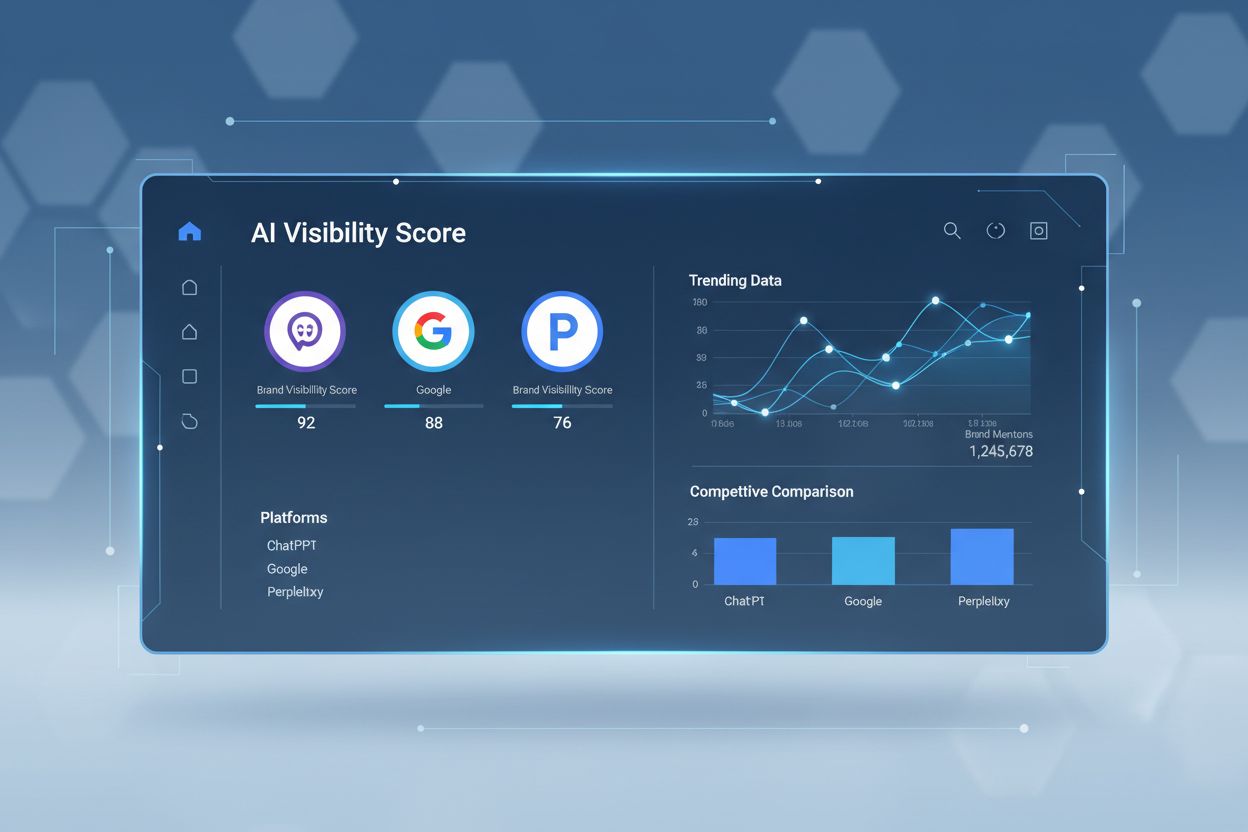
AmICited.com est une plateforme de suivi des citations IA qui analyse la façon dont les systèmes d'IA comme Perplexity, Google AI Overviews et ChatGPT citent votre marque et votre contenu. Elle offre une visibilité sur les sources apparaissant dans les réponses IA, la fréquence de citation de votre contenu, et la comparaison de votre transparence de classement sur différentes plateformes d'IA.
Surveillez la visibilité de votre marque sur les plateformes d'IA
Suivez comment les plateformes d'IA telles que Perplexity, Google AI Overviews et ChatGPT citent votre contenu. Comprenez la transparence de votre classement et optimisez votre visibilité sur les moteurs de recherche IA avec AmICited.
Relier la visibilité de l’IA aux résultats business dans les rapports
Découvrez comment relier les métriques de visibilité de l’IA à des résultats business mesurables. Suivez les mentions de votre marque dans ChatGPT, Perplexity e...
Découvrez ce qu’est l’écart de visibilité IA, pourquoi il est important pour votre marque, comment le mesurer et les stratégies pour combler l’écart entre la vi...
Maîtrisez la trousse de visibilité AI de Semrush avec notre guide complet. Découvrez comment surveiller la visibilité de votre marque dans la recherche AI, anal...
11 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.