
Évaluation de la pertinence du contenu
Découvrez comment l’évaluation de la pertinence du contenu utilise des algorithmes d’IA pour mesurer dans quelle mesure un contenu correspond aux requêtes et in...
8 min de lecture

L’évaluation de la pertinence par l’IA est le processus de quantification de la pertinence et de la qualité des documents ou passages récupérés par rapport à une requête utilisateur. Elle utilise des algorithmes sophistiqués pour évaluer la signification sémantique, la pertinence contextuelle et la qualité de l’information, déterminant quelles sources sont transmises aux modèles de langage pour la génération de réponses dans les systèmes RAG.
L'évaluation de la pertinence par l'IA est le processus de quantification de la pertinence et de la qualité des documents ou passages récupérés par rapport à une requête utilisateur. Elle utilise des algorithmes sophistiqués pour évaluer la signification sémantique, la pertinence contextuelle et la qualité de l'information, déterminant quelles sources sont transmises aux modèles de langage pour la génération de réponses dans les systèmes RAG.
L’évaluation de la pertinence par l’IA est le processus de quantification de la pertinence et de la qualité des documents ou passages récupérés par rapport à une requête ou une tâche utilisateur. Contrairement à la correspondance par mots-clés simple, qui ne fait qu’identifier le chevauchement de termes en surface, l’évaluation de la récupération utilise des algorithmes sophistiqués pour évaluer la signification sémantique, la pertinence contextuelle et la qualité de l’information. Ce mécanisme d’évaluation est fondamental pour les systèmes de génération augmentée par récupération (RAG), où il détermine quelles sources sont transmises aux modèles de langage pour la génération de réponses. Dans les applications modernes de LLM, l’évaluation de la récupération influence directement la précision des réponses, la réduction des hallucinations et la satisfaction des utilisateurs en garantissant que seules les informations les plus pertinentes atteignent l’étape de génération. La qualité de l’évaluation de la récupération est donc un élément crucial de la performance globale et de la fiabilité du système.
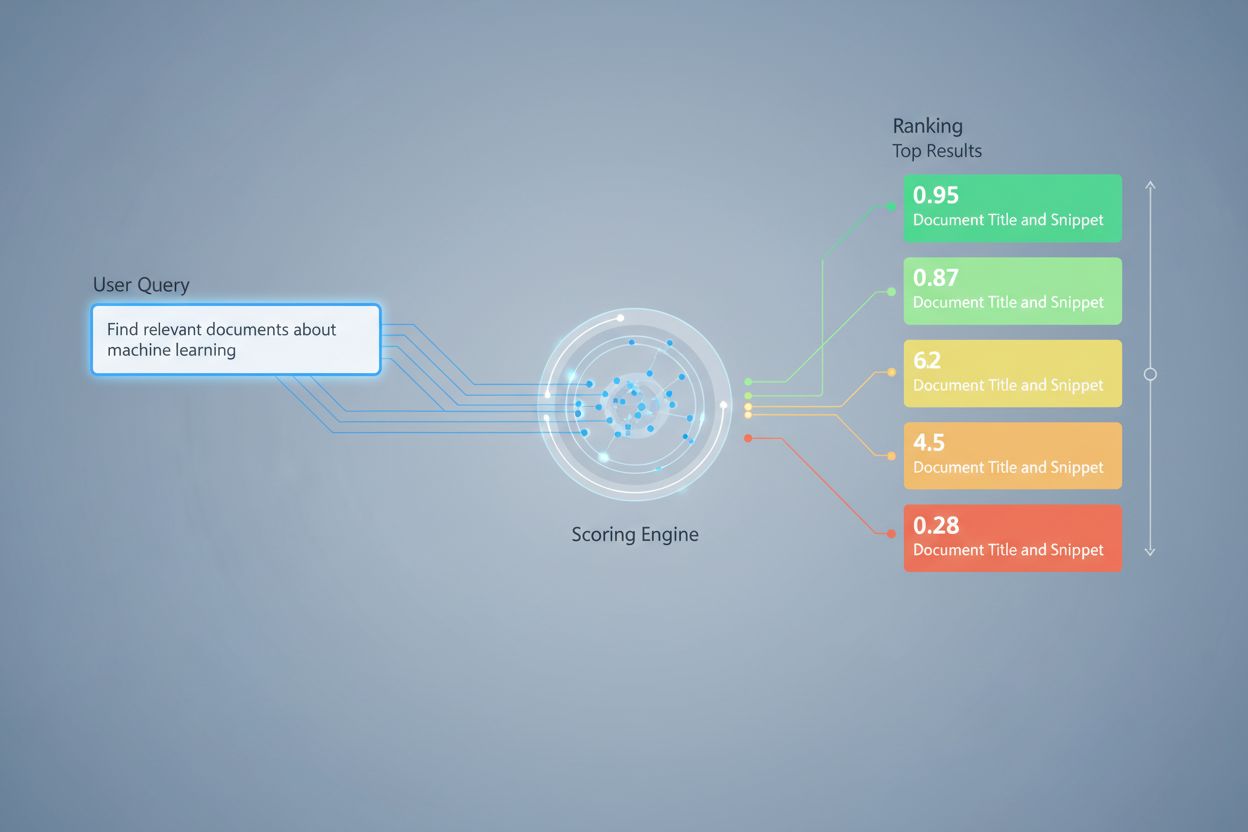
L’évaluation de la récupération utilise plusieurs approches algorithmiques, chacune ayant des atouts distincts selon les cas d’usage. L’évaluation de similarité sémantique utilise des modèles d’embedding pour mesurer l’alignement conceptuel entre les requêtes et les documents dans l’espace vectoriel, capturant le sens au-delà des mots-clés de surface. BM25 (Best Matching 25) est une fonction de classement probabiliste qui prend en compte la fréquence des termes, la fréquence inverse des documents et la normalisation de la longueur du document, ce qui le rend très efficace pour la récupération de texte traditionnelle. TF-IDF (Term Frequency-Inverse Document Frequency) pondère les termes selon leur importance dans les documents et à travers les collections, bien qu’il ne comprenne pas la sémantique. Les approches hybrides combinent plusieurs méthodes—comme la fusion des scores BM25 et sémantiques—pour exploiter à la fois les signaux lexicaux et sémantiques. Au-delà des méthodes d’évaluation, des métriques comme Precision@k (pourcentage de résultats pertinents dans les k premiers), Recall@k (pourcentage de tous les documents pertinents trouvés dans les k premiers), NDCG (Gain cumulatif actualisé normalisé, tenant compte de la position dans le classement) et MRR (rang réciproque moyen) fournissent des mesures quantitatives de la qualité de la récupération. Comprendre les forces et faiblesses de chaque approche—comme l’efficacité de BM25 face à la compréhension plus profonde de l’évaluation sémantique—est essentiel pour sélectionner les méthodes appropriées à des applications spécifiques.
| Méthode de notation | Fonctionnement | Idéal pour | Avantage clé |
|---|---|---|---|
| Similarité sémantique | Compare les embeddings via la similarité cosinus ou d’autres mesures de distance | Signification conceptuelle, synonymes, paraphrases | Capture les relations sémantiques au-delà des mots-clés |
| BM25 | Classement probabiliste tenant compte de la fréquence des termes et de la longueur du document | Correspondance exacte de phrases, requêtes par mots-clés | Rapide, efficace, éprouvé en production |
| TF-IDF | Pondère les termes selon leur fréquence dans le document et leur rareté dans la collection | Récupération d’information traditionnelle | Simple, interprétable, léger |
| Notation hybride | Combine approches sémantiques et par mots-clés avec fusion pondérée | Récupération généraliste, requêtes complexes | Exploite les forces de plusieurs méthodes |
| Notation basée LLM | Utilise les modèles de langage pour juger la pertinence via des prompts personnalisés | Évaluation contextuelle complexe, tâches spécifiques au domaine | Saisit des relations sémantiques nuancées |
Dans les systèmes RAG, l’évaluation de la récupération fonctionne à plusieurs niveaux pour garantir la qualité de la génération. Le système évalue généralement des fragments ou passages individuels dans les documents, permettant une appréciation fine de la pertinence plutôt que de traiter les documents entiers comme des unités atomiques. Cette notation de la pertinence par fragment permet au système d’extraire uniquement les segments d’information les plus pertinents, réduisant le bruit et le contexte non pertinent susceptible de perturber le modèle de langage. Les systèmes RAG implémentent souvent des seuils de notation ou des mécanismes de coupure qui filtrent les résultats à faible score avant qu’ils n’atteignent l’étape de génération, empêchant ainsi les sources de mauvaise qualité d’influencer la réponse finale. La qualité du contexte récupéré est directement corrélée à la qualité de la génération—des passages pertinents à haut score produisent des réponses plus précises et fondées, tandis qu’une récupération de mauvaise qualité introduit des hallucinations et des erreurs factuelles. La surveillance des scores de récupération fournit des signaux d’alerte précoce pour la dégradation du système, en faisant une métrique clé pour la surveillance des réponses d’IA et l’assurance qualité dans les systèmes en production.
Le réordonnancement sert de mécanisme de filtrage en seconde passe qui affine les résultats initiaux de la récupération, et améliore souvent considérablement la précision du classement. Après qu’un récupérateur initial a généré des résultats candidats avec des scores préliminaires, un réordonneur applique une logique de notation plus sophistiquée pour réorganiser ou filtrer ces candidats, généralement à l’aide de modèles plus coûteux en calcul qui peuvent se permettre une analyse approfondie. La fusion des rangs réciproques (RRF) est une technique populaire qui combine les classements de plusieurs récupérateurs en attribuant des scores selon la position du résultat, puis fusionne ces scores pour produire un classement unifié qui surpasse souvent les récupérateurs individuels. La normalisation des scores devient cruciale lors de la combinaison de résultats issus de différentes méthodes de récupération, puisque les scores bruts de BM25, de la similarité sémantique et d’autres approches opèrent sur des échelles différentes et doivent être calibrés sur des plages comparables. Les approches de récupérateurs en ensemble exploitent plusieurs stratégies de récupération simultanément, le réordonnancement déterminant l’ordre final sur la base des preuves combinées. Cette approche en plusieurs étapes améliore considérablement la précision et la robustesse du classement par rapport à la récupération en une seule étape, en particulier dans les domaines complexes où différentes méthodes capturent des signaux de pertinence complémentaires.
Precision@k : mesure la proportion de documents pertinents parmi les k premiers résultats ; utile pour vérifier la fiabilité des résultats récupérés (ex : Precision@5 = 4/5 signifie que 80 % des 5 premiers résultats sont pertinents)
Recall@k : calcule le pourcentage de tous les documents pertinents trouvés parmi les k premiers résultats ; important pour assurer une couverture complète des informations pertinentes disponibles
Hit Rate : métrique binaire indiquant si au moins un document pertinent apparaît parmi les k premiers résultats ; utile pour des vérifications rapides de qualité en production
NDCG (Gain cumulatif actualisé normalisé) : tient compte de la position dans le classement en attribuant plus de valeur aux documents pertinents apparaissant plus tôt ; varie de 0 à 1 et est idéal pour évaluer la qualité du classement
MRR (Rang réciproque moyen) : mesure la position moyenne du premier résultat pertinent sur plusieurs requêtes ; particulièrement utile pour évaluer si le document le plus pertinent est bien classé
F1 Score : moyenne harmonique de la précision et du rappel ; fournit une évaluation équilibrée lorsque les faux positifs et faux négatifs sont également importants
MAP (Mean Average Precision) : moyenne des précisions à chaque position où un document pertinent est trouvé ; métrique globale de la qualité du classement sur plusieurs requêtes
L’évaluation de la pertinence basée sur les LLM utilise les modèles de langage eux-mêmes comme juges de la pertinence des documents, offrant une alternative flexible aux approches algorithmiques traditionnelles. Dans ce paradigme, des prompts soigneusement conçus demandent à un LLM d’évaluer si un passage récupéré répond à une requête donnée, produisant soit des scores binaires de pertinence (pertinent/non pertinent), soit des scores numériques (ex : échelle 1-5 indiquant l’intensité de la pertinence). Cette approche saisit des relations sémantiques nuancées et une pertinence spécifique au domaine que les algorithmes traditionnels peuvent manquer, en particulier pour les requêtes complexes nécessitant une compréhension approfondie. Cependant, l’évaluation basée LLM introduit des défis comme le coût computationnel (l’inférence LLM est coûteuse par rapport à la similarité d’embedding), une possible incohérence selon les prompts et modèles, et la nécessité d’un calibrage avec des étiquettes humaines pour garantir que les scores reflètent la pertinence réelle. Malgré ces limites, l’évaluation basée LLM s’avère précieuse pour évaluer la qualité des systèmes RAG et pour créer des données d’entraînement pour des modèles de notation spécialisés, en faisant un outil important de la boîte à outils de surveillance de l’IA pour l’évaluation de la qualité des réponses.
Mettre en œuvre une évaluation de la récupération efficace nécessite de prendre en compte plusieurs facteurs pratiques. Le choix de la méthode dépend des exigences du cas d’usage : l’évaluation sémantique excelle à saisir le sens mais requiert des modèles d’embedding, alors que BM25 offre rapidité et efficacité pour la correspondance lexicale. Le compromis entre vitesse et précision est crucial—l’évaluation par embedding apporte une meilleure compréhension de la pertinence mais coûte en latence, tandis que BM25 et TF-IDF sont plus rapides mais moins sophistiqués sémantiquement. Les coûts computationnels incluent le temps d’inférence du modèle, les besoins en mémoire et l’évolutivité de l’infrastructure, particulièrement importants pour les systèmes de production à fort volume. Le réglage des paramètres implique d’ajuster les seuils, les pondérations dans les approches hybrides et les coupures de réordonnancement pour optimiser les performances selon les domaines et usages spécifiques. La surveillance continue des performances de la notation via des métriques comme NDCG et Precision@k permet d’identifier les dégradations dans le temps, de faciliter les améliorations proactives du système et de garantir une qualité de réponse constante dans les systèmes RAG en production.
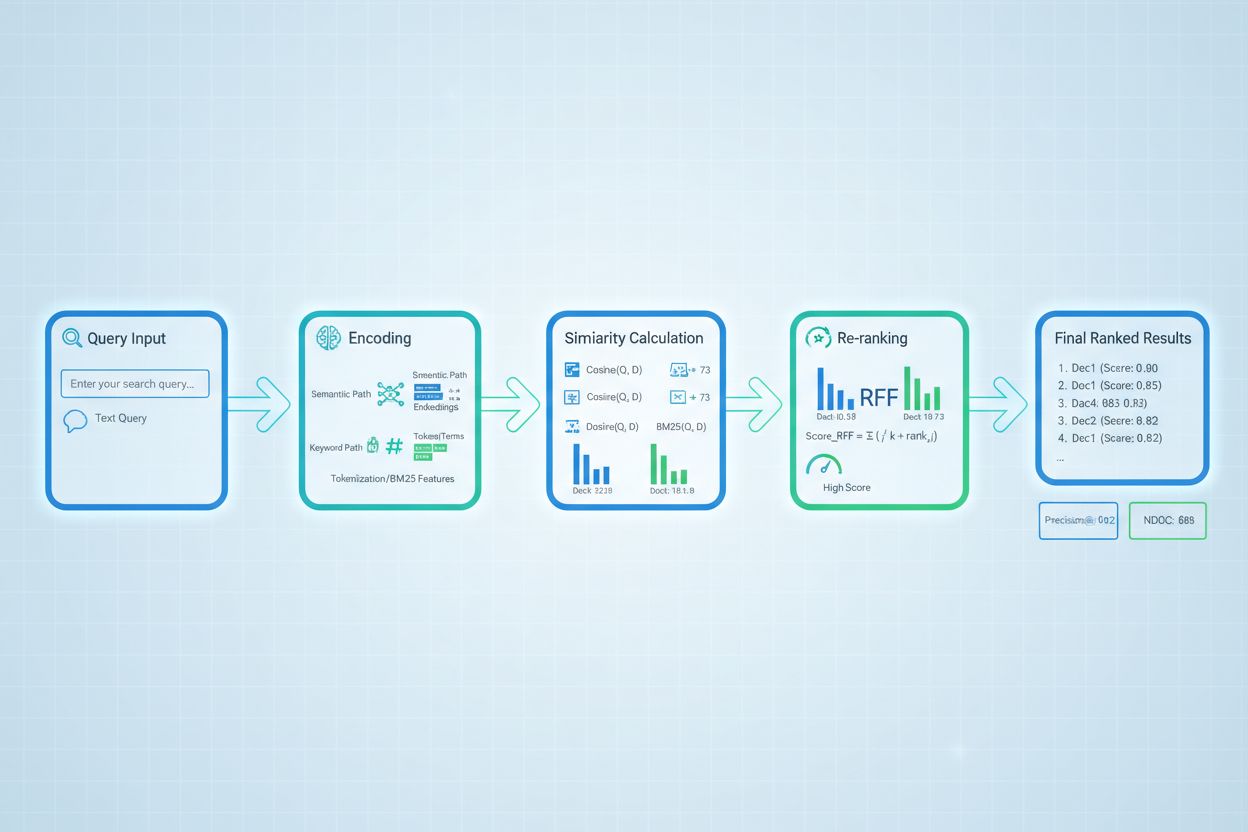
Les techniques avancées d’évaluation de la récupération vont au-delà de l’évaluation de la pertinence de base pour saisir des relations contextuelles complexes. La réécriture de requêtes peut améliorer l’évaluation en reformulant les requêtes utilisateur sous plusieurs formes sémantiquement équivalentes, permettant au récupérateur de trouver des documents pertinents qui auraient pu être manqués par une correspondance littérale. Les embeddings de documents hypothétiques (HyDE) génèrent des documents synthétiques pertinents à partir des requêtes, puis utilisent ces hypothèses pour améliorer l’évaluation de la récupération en trouvant des documents réels similaires au contenu jugé idéalement pertinent. Les approches multi-requêtes soumettent plusieurs variantes de requêtes aux récupérateurs et agrègent leurs scores, améliorant la robustesse et la couverture par rapport à la récupération à requête unique. Les modèles de notation spécifiques au domaine entraînés sur des données annotées de secteurs ou domaines de connaissances particuliers peuvent atteindre de meilleures performances que les modèles généralistes, ce qui est particulièrement précieux pour des applications spécialisées comme les systèmes d’IA médicaux ou juridiques. Les ajustements contextuels de la notation prennent en compte des facteurs comme la récence du document, l’autorité de la source et le contexte utilisateur, permettant une évaluation de la pertinence plus sophistiquée qui va au-delà de la simple similarité sémantique pour intégrer des facteurs de pertinence réels essentiels aux systèmes d’IA en production.
L'évaluation de la récupération attribue des valeurs numériques de pertinence aux documents en fonction de leur relation avec une requête, tandis que le classement organise les documents selon ces scores. L'évaluation est le processus d'analyse, le classement est le résultat de l'ordre. Les deux sont essentiels pour que les systèmes RAG fournissent des réponses précises.
L'évaluation de la récupération détermine quelles sources atteignent le modèle de langage pour la génération de réponses. Une évaluation de haute qualité garantit la sélection d'informations pertinentes, réduit les hallucinations et améliore la précision des réponses. Une mauvaise évaluation conduit à un contexte non pertinent et à des réponses d'IA peu fiables.
L'évaluation sémantique utilise des embeddings pour comprendre la signification conceptuelle et capture les synonymes et concepts liés. L'évaluation basée sur les mots-clés (comme BM25) correspond aux termes et phrases exacts. L'évaluation sémantique est meilleure pour comprendre l'intention, tandis que l'évaluation par mots-clés excelle à trouver des informations spécifiques.
Les principales métriques incluent Precision@k (précision des meilleurs résultats), Recall@k (couverture des documents pertinents), NDCG (qualité du classement) et MRR (position du premier résultat pertinent). Choisissez les métriques selon votre cas d'usage : Precision@k pour les systèmes orientés qualité, Recall@k pour une couverture exhaustive.
Oui, l'évaluation basée sur les LLM utilise les modèles de langage comme juges pour évaluer la pertinence. Cette approche saisit des relations sémantiques subtiles mais est coûteuse en calcul. Elle est précieuse pour évaluer la qualité des systèmes RAG et créer des données d'entraînement, bien qu'elle nécessite un calibrage avec des étiquettes humaines.
Le réordonnancement applique un filtrage en seconde passe à l'aide de modèles plus sophistiqués pour affiner les résultats initiaux. Des techniques comme la fusion des rangs réciproques combinent plusieurs méthodes de récupération, améliorant la précision et la robustesse. Le réordonnancement surpasse nettement la récupération en une seule étape dans les domaines complexes.
BM25 et TF-IDF sont rapides et légers, adaptés aux systèmes en temps réel. L'évaluation sémantique nécessite une inférence de modèles d'embedding, ajoutant de la latence. L'évaluation basée sur les LLM est la plus coûteuse. Choisissez en fonction de vos exigences de latence et des ressources de calcul disponibles.
Considérez vos priorités : évaluation sémantique pour les tâches axées sur le sens, BM25 pour la rapidité et l'efficacité, approches hybrides pour des performances équilibrées. Évaluez sur votre domaine spécifique à l'aide de métriques comme NDCG et Precision@k. Testez plusieurs méthodes et mesurez leur impact sur la qualité finale des réponses.
Suivez comment des systèmes d'IA comme ChatGPT, Perplexity et Google AI font référence à votre marque et évaluez la qualité de leur récupération et classement des sources. Assurez-vous que votre contenu est correctement cité et classé par les systèmes d'IA.
Découvrez comment l’évaluation de la pertinence du contenu utilise des algorithmes d’IA pour mesurer dans quelle mesure un contenu correspond aux requêtes et in...

Les signaux de pertinence sont des indicateurs utilisés par les systèmes d’IA pour évaluer l’applicabilité du contenu. Découvrez comment la correspondance des m...

Découvrez comment calculer efficacement le ROI de l'IA. Comprenez la différence entre ROI dur et mou, les cadres de mesure, les erreurs courantes et des études ...