Techniques permettant de garantir que les crawlers IA accèdent et indexent efficacement le contenu le plus important d’un site web dans les limites de leur budget de crawl. L’optimisation du budget de crawl gère l’équilibre entre la capacité de crawl (ressources serveur) et la demande de crawl (requêtes des bots) afin de maximiser la visibilité dans les réponses générées par l’IA tout en maîtrisant les coûts opérationnels et la charge serveur.
Optimisation du budget de crawl pour l'IA
Techniques permettant de garantir que les crawlers IA accèdent et indexent efficacement le contenu le plus important d’un site web dans les limites de leur budget de crawl. L’optimisation du budget de crawl gère l’équilibre entre la capacité de crawl (ressources serveur) et la demande de crawl (requêtes des bots) afin de maximiser la visibilité dans les réponses générées par l’IA tout en maîtrisant les coûts opérationnels et la charge serveur.
Qu’est-ce que le budget de crawl à l’ère de l’IA
Le budget de crawl désigne la quantité de ressources — mesurée en requêtes et en bande passante — que les moteurs de recherche et les bots IA allouent au crawl de votre site web. Traditionnellement, ce concept s’appliquait principalement au comportement de crawl de Google, mais l’émergence de bots alimentés par l’IA a fondamentalement transformé la manière dont les organisations doivent envisager la gestion du budget de crawl. L’équation du budget de crawl comporte deux variables essentielles : la capacité de crawl (le nombre maximal de pages qu’un bot peut crawler) et la demande de crawl (le nombre réel de pages que le bot souhaite crawler). À l’ère de l’IA, cette dynamique est devenue exponentiellement plus complexe, car des bots comme GPTBot (OpenAI), Perplexity Bot et ClaudeBot (Anthropic) rivalisent désormais pour les ressources serveur aux côtés des crawlers traditionnels des moteurs de recherche. Ces bots IA opèrent selon des priorités et des schémas différents de Googlebot, consommant souvent nettement plus de bande passante et poursuivant d’autres objectifs d’indexation, rendant l’optimisation du budget de crawl non plus optionnelle mais essentielle pour maintenir la performance du site et maîtriser les coûts opérationnels.
Pourquoi les crawlers IA ont changé la donne
Les crawlers IA diffèrent fondamentalement des bots de moteurs de recherche traditionnels par leurs schémas de crawl, leur fréquence et leur consommation de ressources. Googlebot respecte les limites du budget de crawl et applique des mécanismes de throttling sophistiqués, alors que les bots IA affichent souvent des comportements de crawl beaucoup plus agressifs, parfois en demandant plusieurs fois le même contenu et en prêtant moins d’attention aux signaux de charge serveur. Les recherches indiquent que le GPTBot d’OpenAI peut consommer 12 à 15 fois plus de bande passante que le crawler de Google sur certains sites, notamment ceux dotés de vastes bibliothèques de contenu ou de pages fréquemment mises à jour. Cette approche agressive découle des exigences de l’entraînement IA : ces bots doivent sans cesse ingérer du contenu frais pour améliorer les performances des modèles, ce qui crée une philosophie de crawl fondamentalement différente des moteurs de recherche focalisés sur l’indexation pour la recherche. L’impact serveur est considérable : des organisations signalent une forte augmentation des coûts de bande passante, de l’utilisation CPU et de la charge serveur, directement attribuables au trafic des bots IA. De plus, l’effet cumulatif de plusieurs bots IA qui crawlent simultanément peut dégrader l’expérience utilisateur, ralentir les temps de chargement et augmenter les dépenses d’hébergement, faisant de la distinction entre crawlers traditionnels et IA un enjeu business critique plutôt qu’une simple curiosité technique.
Caractéristique
Crawlers traditionnels (Googlebot)
Crawlers IA (GPTBot, ClaudeBot)
Fréquence de crawl
Adaptative, respecte le budget de crawl
Agressive, continue
Consommation de bande passante
Modérée, optimisée
Élevée, gourmande en ressources
Respect du robots.txt
Conformité stricte
Conformité variable
Comportement de cache
Caching sophistiqué
Requêtes répétées fréquentes
Identification User-Agent
Claire, cohérente
Parfois masquée
Objectif business
Indexation de recherche
Entraînement de modèles/acquisition de données
Impact sur les coûts
Minime
Significatif (12-15x supérieur)
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Les deux composantes fondamentales du budget de crawl
Comprendre le budget de crawl, c’est maîtriser ses deux composantes : la capacité de crawl et la demande de crawl. La capacité de crawl représente le nombre maximal d’URLs que votre serveur peut supporter en crawl sur une période donnée, déterminé par plusieurs facteurs interdépendants. Cette capacité dépend de :
Temps de réponse (des réponses rapides permettent un taux de crawl plus élevé)
Signaux de santé du serveur (codes HTTP, taux de timeout)
Qualité de l’infrastructure (utilisation de CDN, load-balancing, couches de cache)
Distribution géographique (l’hébergement multi-régions augmente la capacité)
La demande de crawl, à l’inverse, représente le nombre de pages que les bots souhaitent réellement crawler, guidée par les caractéristiques du contenu et les priorités des bots. Les facteurs qui influencent la demande de crawl incluent :
Actualité du contenu (pages fréquemment mises à jour attirent plus de crawl)
Qualité et autorité du contenu (les pages de qualité sont prioritaires)
Fréquence de mise à jour (les pages actualisées quotidiennement reçoivent plus d’attention)
Maillage interne (les pages bien liées sont plus souvent crawlé)
Présence dans le sitemap (les pages présentes dans les sitemaps sont prioritaires)
Historique de crawl (les bots apprennent quelles pages changent souvent)
Le défi d’optimisation survient quand la demande de crawl dépasse la capacité de crawl : les bots doivent choisir quelles pages crawler, risquant de manquer des mises à jour importantes. À l’inverse, une capacité de crawl bien supérieure à la demande gaspille des ressources serveur. L’objectif est d’atteindre l’efficacité de crawl : maximiser le crawl des pages importantes tout en minimisant le gaspillage sur du contenu à faible valeur. Cet équilibre devient encore plus complexe à l’ère de l’IA, où plusieurs types de bots aux priorités différentes rivalisent pour les mêmes ressources serveur, nécessitant des stratégies sophistiquées pour allouer efficacement le budget de crawl à tous les acteurs.
Mesurer la performance actuelle de votre budget de crawl
La mesure de la performance du budget de crawl commence avec Google Search Console, qui fournit des statistiques de crawl dans la section « Paramètres », affichant les requêtes de crawl quotidiennes, les octets téléchargés et les temps de réponse. Pour calculer votre taux d’efficacité du crawl, divisez le nombre de crawls réussis (réponses HTTP 200) par le total des requêtes de crawl ; les sites sains atteignent généralement 85-95% d’efficacité. Une formule de base : (Crawls réussis ÷ Requêtes de crawl totales) × 100 = % d’efficacité de crawl. Au-delà des données de Google, le suivi pratique nécessite :
Analyse des logs serveur avec des outils comme Splunk ou ELK Stack pour identifier tout le trafic bot, y compris les crawlers IA
Suivi des taux d’erreur 4xx et 5xx pour repérer les pages qui gaspillent le budget de crawl sur des erreurs
Surveillance de la profondeur de crawl (jusqu’à quel niveau les bots pénètrent dans votre structure)
Mesure des tendances de temps de réponse pour détecter une dégradation due au crawl
Segmentation du trafic par user-agent pour savoir quels bots consomment le plus de ressources
Pour un suivi spécifique des crawlers IA, des outils comme AmICited.com offrent un monitoring spécialisé de GPTBot, ClaudeBot et Perplexity Bot, révélant quelles pages ces bots priorisent et à quelle fréquence ils reviennent. De plus, la mise en place d’alertes personnalisées pour les pics de crawl inhabituels — en particulier des bots IA — permet de réagir rapidement à une consommation inattendue de ressources. La métrique clé à suivre est le coût de crawl par page : diviser la totalité des ressources serveur consommées par le nombre de pages uniques crawlé indique si vous utilisez efficacement votre budget ou si vous gaspillez des ressources sur des pages à faible valeur.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Stratégies d’optimisation pour les crawlers IA
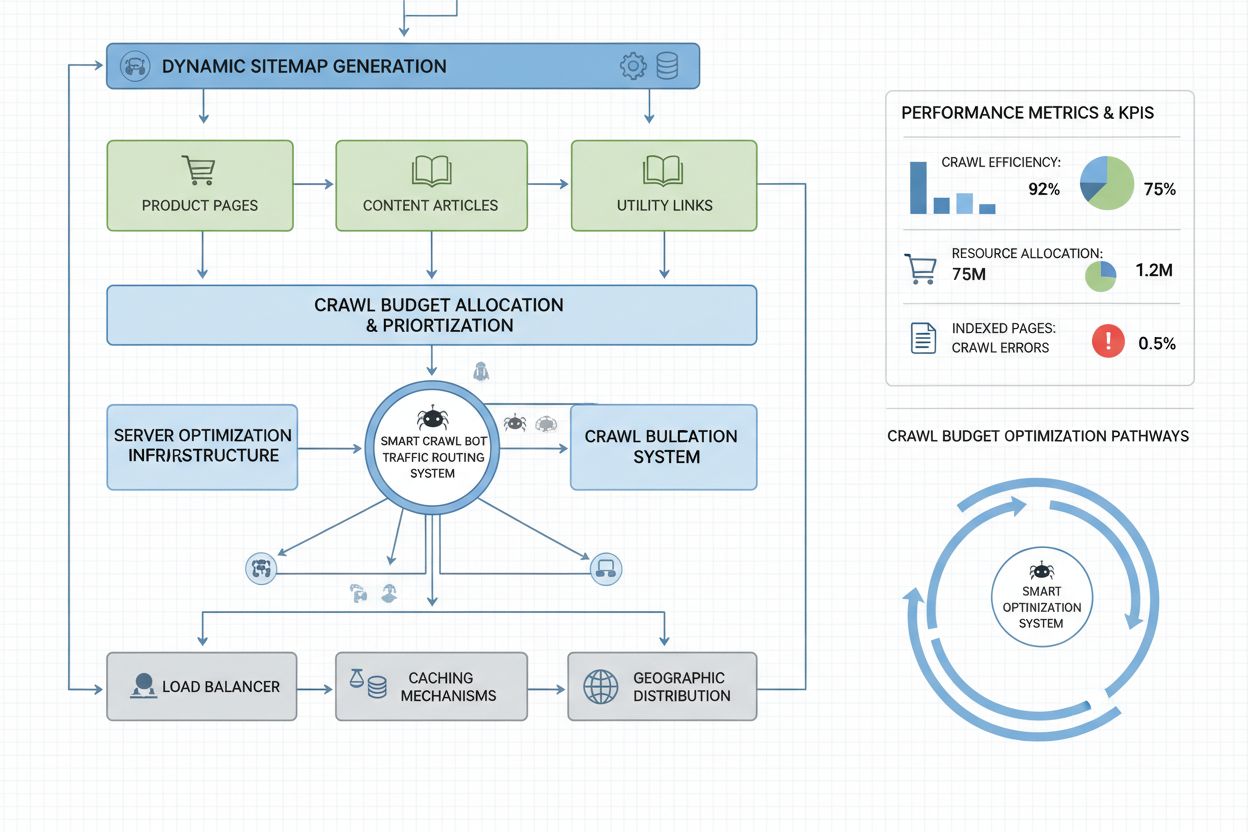
L’optimisation du budget de crawl pour les bots IA requiert une approche multi-couche, alliant mise en œuvre technique et décisions stratégiques. Les principales tactiques d’optimisation incluent :
Affinage du robots.txt : Bloquer les bots IA sur les pages à faible valeur (archives, doublons, sections admin) tout en autorisant l’accès au contenu essentiel
Sitemaps dynamiques : Créer des sitemaps distincts selon les types de contenus, en priorisant les pages fréquemment mises à jour et à forte valeur
Optimisation de la structure d’URL : Mettre en place des structures propres et hiérarchisées qui réduisent la profondeur de crawl et rendent les pages importantes plus accessibles
Blocage sélectif : Appliquer des règles spécifiques à l’user-agent pour autoriser Googlebot tout en limitant les crawlers IA trop gourmands
Directives crawl-delay : Définir des crawl-delay adaptés dans le robots.txt pour ralentir les bots (même si les bots IA peuvent ne pas les respecter)
Canonicalisation : Utiliser massivement les balises canoniques pour consolider les doublons et réduire le gaspillage du crawl sur des variantes
Le choix stratégique des tactiques dépend de votre modèle économique et de votre stratégie de contenu. Les sites e-commerce peuvent bloquer les crawlers IA sur les fiches produits pour éviter l’entraînement des concurrents, tandis que les éditeurs de contenu peuvent autoriser le crawl pour gagner en visibilité dans les réponses IA. Pour les sites qui subissent une vraie pression serveur due au trafic des bots IA, la mise en place d’un blocage spécifique à l’user-agent dans le robots.txt est la solution la plus directe : User-agent: GPTBot suivi de Disallow: / empêche totalement le crawler d’OpenAI d’accéder à votre site. Mais cette approche sacrifie la visibilité potentielle dans ChatGPT et autres IA. Une stratégie plus nuancée consiste en un blocage sélectif : autoriser les crawlers IA sur le contenu public tout en leur interdisant l’accès aux zones sensibles, archives ou contenus dupliqués ne présentant pas d’intérêt pour le bot ou vos utilisateurs.
Techniques avancées pour les grands sites
Les sites d’envergure gérant des millions de pages nécessitent des stratégies de gestion du budget de crawl plus sophistiquées que la simple configuration du robots.txt. Les sitemaps dynamiques sont une avancée majeure, générés en temps réel selon l’actualité du contenu, l’importance et l’historique du crawl. Plutôt que des sitemaps XML statiques listant toutes les pages, ils mettent en avant les pages récemment mises à jour, à fort trafic et à potentiel de conversion, garantissant que les bots concentrent leur budget de crawl sur le contenu stratégique. La segmentation des URLs divise le site en zones logiques de crawl, chacune optimisée différemment : les sections actualités peuvent avoir des sitemaps très réactifs pour garantir un crawl immédiat, tandis que le contenu evergreen est mis à jour moins fréquemment.
Les optimisations côté serveur incluent la mise en place de stratégies de cache conscientes du crawl qui délivrent des réponses en cache aux bots tout en fournissant du contenu frais aux utilisateurs, réduisant la charge serveur liée aux requêtes répétées des bots. Les CDN avec routage spécifique aux bots peuvent isoler le trafic bot du trafic utilisateur, évitant que les crawlers ne consomment la bande passante réservée aux visiteurs réels. La limitation du débit par user-agent permet de réguler la fréquence des requêtes des bots IA tout en conservant la vitesse normale pour Googlebot et les utilisateurs. Pour les très grands sites, la gestion du budget de crawl répartie sur plusieurs régions serveur évite tout point de défaillance unique et permet une répartition géographique de la charge bot. La prédiction de crawl par machine learning analyse les historiques de crawl pour anticiper les prochaines pages demandées par les bots, optimisant de façon proactive la performance et le cache de ces pages. Ces stratégies de niveau entreprise transforment le budget de crawl d’une contrainte en une ressource gérée, permettant aux grandes organisations de servir des milliards de pages tout en maintenant des performances optimales pour les bots comme pour les utilisateurs humains.
La décision stratégique : bloquer ou autoriser les crawlers IA
Le choix de bloquer ou d’autoriser les crawlers IA est une décision stratégique majeure aux implications fortes sur la visibilité, la position concurrentielle et les coûts opérationnels. Autoriser les crawlers IA offre des avantages considérables : votre contenu peut figurer dans les réponses générées par l’IA, générant potentiellement du trafic depuis ChatGPT, Claude, Perplexity et autres applications IA ; votre marque gagne en visibilité sur un nouveau canal ; et vous bénéficiez des signaux SEO issus des citations par les systèmes IA. Cependant, ces avantages s’accompagnent de coûts : charge serveur et bande passante accrues, risque d’entraînement de modèles concurrents sur votre contenu propriétaire, et perte de contrôle sur la présentation et l’attribution de vos informations dans les réponses IA.
Bloquer les crawlers IA élimine ces coûts mais vous fait perdre les avantages de visibilité et potentiellement des parts de marché au profit de concurrents qui autorisent le crawl. La stratégie optimale dépend de votre modèle économique : éditeurs de contenu et médias bénéficient souvent du crawl pour diffuser via les synthèses IA ; SaaS et e-commerce peuvent bloquer pour éviter l’entraînement des concurrents sur leurs données produits ; établissements éducatifs et organismes de recherche autorisent généralement le crawl pour maximiser la diffusion du savoir. Une approche hybride offre un compromis : autoriser le crawl sur le contenu public tout en bloquant l’accès aux zones sensibles, au contenu utilisateur ou propriétaire. Cette stratégie maximise la visibilité tout en protégeant les actifs de valeur. En outre, la surveillance via AmICited.com et outils similaires révèle si votre contenu est effectivement cité par les systèmes IA — si votre site n’apparaît pas dans les réponses IA malgré l’autorisation de crawl, le blocage devient une option plus pertinente, car vous supportez le coût du crawl sans en retirer le bénéfice.
Outils et monitoring pour la gestion du budget de crawl
Une gestion efficace du budget de crawl requiert des outils spécialisés offrant une visibilité sur le comportement des bots et permettant des décisions d’optimisation fondées sur les données. Conductor et Sitebulb proposent une analyse de crawl de niveau entreprise, simulant le crawl des moteurs pour identifier les inefficacités, le gaspillage sur les pages d’erreur et les opportunités d’amélioration de l’allocation du budget. Cloudflare fournit une gestion des bots au niveau réseau, permettant un contrôle granulaire des bots autorisés et la mise en place de limites de débit spécifiques aux bots IA. Pour le suivi spécifique des crawlers IA, AmICited.com est la solution la plus complète, surveillant GPTBot, ClaudeBot, Perplexity Bot et autres, avec des analyses détaillées des pages accédées, de la fréquence de visite et de la présence de votre contenu dans les réponses IA.
L’analyse des logs serveur reste fondamentale pour optimiser le budget de crawl : des outils comme Splunk, Datadog ou l’ELK Stack open-source permettent de parser les logs d’accès et de segmenter le trafic par user-agent, identifiant quels bots consomment le plus de ressources et quelles pages attirent le plus de crawl. Des tableaux de bord personnalisés permettant de suivre les tendances de crawl dans le temps montrent si vos efforts d’optimisation portent leurs fruits et si de nouveaux types de bots apparaissent. Google Search Console reste essentiel pour les données de crawl Google, tandis que Bing Webmaster Tools offre des insights similaires pour le crawler de Microsoft. Les organisations les plus performantes adoptent une stratégie de monitoring multi-outils combinant Search Console pour la recherche classique, AmICited.com pour les crawlers IA, l’analyse de logs pour une visibilité exhaustive, et des outils spécialisés comme Conductor pour la simulation et l’analyse d’efficacité. Cette approche par couches offre une vue complète de l’interaction de tous les types de bots avec votre site, permettant des optimisations sur la base de données exhaustives. Une surveillance régulière — idéalement hebdomadaire — des métriques de crawl permet d’identifier rapidement les problèmes comme les pics inattendus, l’augmentation des erreurs ou l’arrivée de nouveaux bots agressifs, et d’y répondre avant que le budget de crawl n’impacte la performance ou les coûts du site.
Questions fréquemment posées
Quelle est la différence entre le budget de crawl des bots IA et celui de Googlebot ?
Les bots IA comme GPTBot et ClaudeBot ont des priorités différentes de Googlebot. Alors que Googlebot respecte les limites du budget de crawl et applique un throttling sophistiqué, les bots IA affichent souvent des schémas de crawl plus agressifs, consommant 12 à 15 fois plus de bande passante. Les bots IA privilégient l’ingestion continue de contenu pour l’entraînement des modèles plutôt que l’indexation pour la recherche, rendant leur comportement de crawl fondamentalement différent et nécessitant des stratégies d’optimisation spécifiques.
Combien de budget de crawl les bots IA consomment-ils généralement ?
Les recherches indiquent que le GPTBot d’OpenAI peut consommer 12 à 15 fois plus de bande passante que le crawler de Google sur certains sites, en particulier ceux avec de grandes bibliothèques de contenu. La consommation exacte dépend de la taille de votre site, de la fréquence de mise à jour du contenu et du nombre de bots IA qui crawlent simultanément. Plusieurs bots IA qui crawlent en même temps peuvent augmenter significativement la charge serveur et les coûts d’hébergement.
Puis-je bloquer certains crawlers IA sans affecter mon SEO ?
Oui, vous pouvez bloquer certains crawlers IA via robots.txt sans impacter le SEO traditionnel. Cependant, bloquer les crawlers IA signifie sacrifier la visibilité dans les réponses générées par l’IA de ChatGPT, Claude, Perplexity et autres applications IA. Le choix dépend de votre modèle économique : les éditeurs de contenu bénéficient généralement du crawl, tandis que les sites e-commerce peuvent bloquer pour éviter l’entraînement des concurrents.
Quel est l’impact d’une mauvaise gestion du budget de crawl sur mon site ?
Une mauvaise gestion du budget de crawl peut entraîner le non-crawl ou la non-indexation de pages importantes, un ralentissement de l’indexation des nouveaux contenus, une augmentation de la charge serveur et des coûts de bande passante, une expérience utilisateur dégradée due à la consommation de ressources par les bots, et une perte d’opportunités de visibilité dans la recherche traditionnelle comme dans les réponses générées par l’IA. Les grands sites avec des millions de pages sont les plus vulnérables à ces impacts.
À quelle fréquence dois-je surveiller mon budget de crawl ?
Pour des résultats optimaux, surveillez les métriques de budget de crawl chaque semaine, avec des contrôles quotidiens lors de lancements de contenus majeurs ou en cas de pics de trafic inattendus. Utilisez Google Search Console pour les données de crawl traditionnelles, AmICited.com pour le suivi des crawlers IA, et les logs serveur pour une visibilité complète sur les bots. Une surveillance régulière permet d’identifier rapidement les problèmes avant qu’ils n’affectent les performances du site.
Le robots.txt est-il efficace pour contrôler le crawl des bots IA ?
L’efficacité de robots.txt varie selon les bots IA. Googlebot respecte strictement les directives de robots.txt, mais les bots IA affichent une conformité inégale : certains respectent les règles, d’autres les ignorent. Pour un contrôle plus fiable, mettez en place un blocage spécifique à l’user-agent, une limitation du débit au niveau serveur, ou utilisez des outils de gestion de bots basés sur CDN comme Cloudflare pour un contrôle plus granulaire.
Quel est le lien entre le budget de crawl et la visibilité dans l’IA ?
Le budget de crawl impacte directement la visibilité dans l’IA car les bots IA ne peuvent pas citer ou référencer un contenu qu’ils n’ont pas crawlé. Si vos pages importantes ne sont pas crawlé en raison de contraintes budgétaires, elles n’apparaîtront pas dans les réponses générées par l’IA. Optimiser le budget de crawl garantit que votre meilleur contenu est découvert par les bots IA, augmentant les chances d’être cité dans les réponses de ChatGPT, Claude et Perplexity.
Comment prioriser les pages à crawler par les bots IA ?
Priorisez les pages à l’aide de sitemaps dynamiques mettant en avant le contenu récemment mis à jour, les pages à fort trafic et celles à potentiel de conversion. Utilisez robots.txt pour bloquer les pages à faible valeur comme les archives et les doublons. Mettez en œuvre des structures d’URL propres et un maillage interne stratégique pour orienter les bots vers le contenu important. Surveillez les pages effectivement crawlé par les bots IA avec des outils comme AmICited.com pour affiner votre stratégie.
Surveillez efficacement votre budget de crawl IA
Suivez comment les bots IA crawlent votre site et optimisez votre visibilité dans les réponses générées par l’IA grâce à la plateforme complète de surveillance des crawlers IA d’AmICited.com.
Qu'est-ce que le budget de crawl pour l'IA ? Comprendre l'allocation des ressources des bots IA
Découvrez ce que signifie le budget de crawl pour l'IA, en quoi il diffère des budgets de crawl traditionnels des moteurs de recherche, et pourquoi il est essen...
Le taux de crawl est la vitesse à laquelle les moteurs de recherche explorent votre site web. Découvrez comment il affecte l’indexation, la performance SEO et c...
12 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.