
Reconnaissance d'entités
La reconnaissance d'entités est une capacité NLP de l'IA identifiant et catégorisant les entités nommées dans le texte. Découvrez son fonctionnement, ses applic...
13 min de lecture

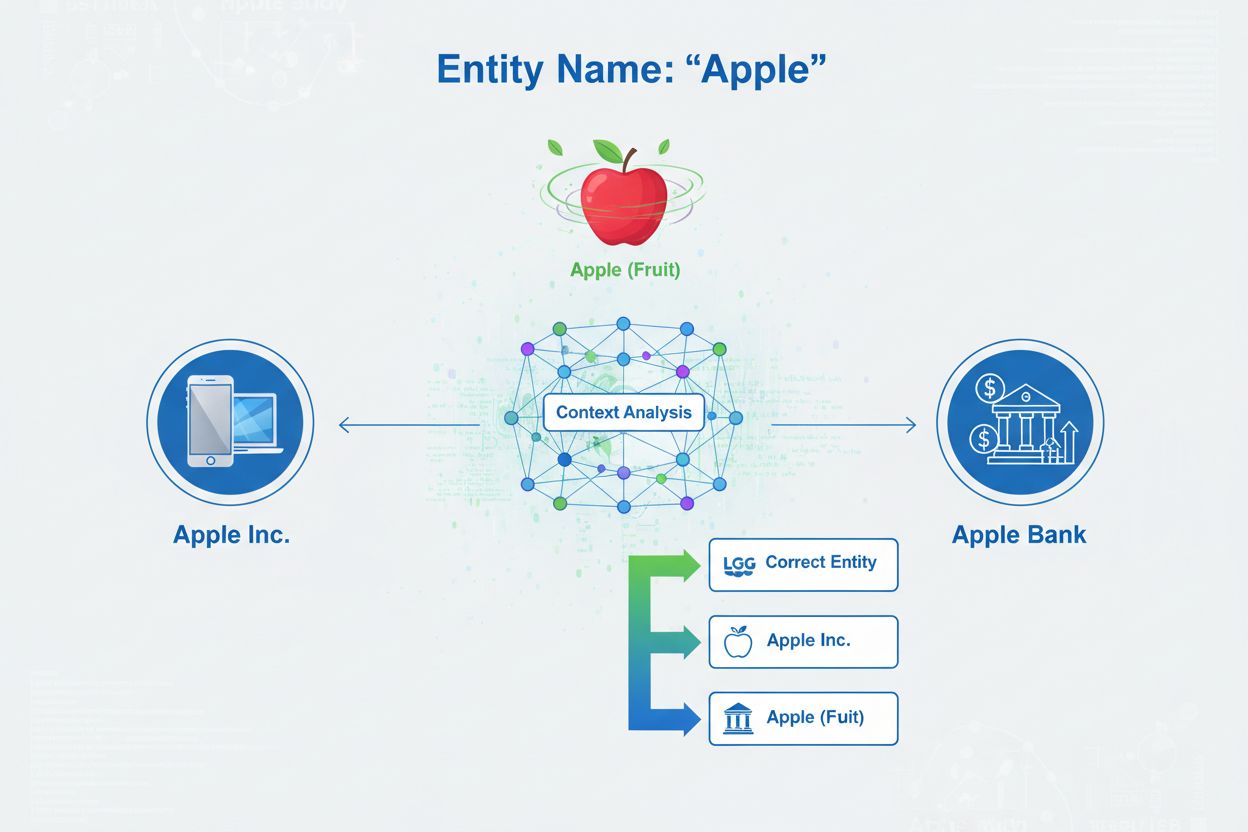
La désambiguïsation d’entité est le processus qui consiste à déterminer à quelle entité spécifique fait référence une mention particulière lorsque plusieurs entités partagent le même nom. Elle aide les systèmes d’IA à comprendre et citer précisément le contenu en résolvant l’ambiguïté des références aux entités nommées, garantissant ainsi que les mentions de « Apple » identifient correctement s’il s’agit de Apple Inc., du fruit ou d’une autre entité portant le même nom.
La désambiguïsation d'entité est le processus qui consiste à déterminer à quelle entité spécifique fait référence une mention particulière lorsque plusieurs entités partagent le même nom. Elle aide les systèmes d’IA à comprendre et citer précisément le contenu en résolvant l’ambiguïté des références aux entités nommées, garantissant ainsi que les mentions de « Apple » identifient correctement s’il s’agit de Apple Inc., du fruit ou d’une autre entité portant le même nom.
La désambiguïsation d’entité est le processus de détermination de l’entité spécifique à laquelle une mention se rapporte lorsque plusieurs entités partagent le même nom ou des références similaires. Dans le contexte de l’intelligence artificielle et du traitement automatique du langage naturel (NLP), la désambiguïsation d’entité permet, lorsqu’un système d’IA rencontre une entité nommée dans un texte, d’identifier correctement à quel objet, personne, organisation ou lieu du monde réel il est fait référence. Cela diffère fondamentalement de la reconnaissance d’entités nommées (NER), qui ne fait qu’identifier la présence d’une entité et la classer dans une catégorie comme « personne », « organisation » ou « lieu ». Alors que la NER répond à la question « Y a-t-il une entité ici ? », la désambiguïsation d’entité répond « De quelle entité spécifique s’agit-il ? ». Par exemple, dans la phrase « Apple était l’enfant prodige de Steve Jobs », la NER identifie « Apple » comme une organisation, mais la désambiguïsation d’entité détermine s’il s’agit d’Apple Inc., l’entreprise technologique, ou potentiellement d’une autre entité portant le même nom. Cette distinction est essentielle pour les systèmes d’IA qui doivent comprendre et citer précisément le contenu, raison pour laquelle AmICited.com surveille la façon dont les systèmes d’IA comme ChatGPT, Perplexity et Google AI Overviews gèrent la désambiguïsation d’entité lors de la génération de réponses à propos de marques et d’organisations.
Le problème fondamental que résout la désambiguïsation d’entité est l’ambiguïté — le fait que de nombreux noms d’entités peuvent désigner plusieurs objets du monde réel. Cette ambiguïté pose des défis majeurs aux systèmes d’IA qui tentent de comprendre et de générer un contenu précis. Selon le Stanford AI Index 2024, plus de 18 % des productions de LLM impliquant des entités de marque contiennent soit des hallucinations, soit des erreurs d’attribution d’entité, ce qui signifie que les systèmes d’IA confondent fréquemment une entité avec une autre ou génèrent de fausses informations sur les entités. Ce taux d’erreur a de graves conséquences pour la représentation des marques et la précision du contenu. Lorsqu’un système d’IA identifie mal une entité, il peut fournir de mauvaises informations, attribuer des déclarations à la mauvaise organisation ou ne pas citer la bonne source.
| Nom d’entité | Significations possibles | Taux de confusion IA |
|---|---|---|
| Apple | Entreprise tech / Fruit / Banque | Élevé |
| Delta | Compagnie aérienne / Robinetterie / Lettre grecque | Élevé |
| Jaguar | Constructeur automobile / Espèce animale | Moyen |
| Amazon | Entreprise e-commerce / Forêt tropicale / Fleuve | Élevé |
| Orange | Couleur / Fruit / Entreprise télécom | Moyen |
Les conséquences d’une mauvaise désambiguïsation d’entité vont au-delà de simples erreurs factuelles. Pour les créateurs de contenu et les marques, une identification erronée dans les réponses générées par l’IA peut entraîner une perte de visibilité, une attribution incorrecte et une atteinte à la réputation de la marque. Lorsqu’un utilisateur interroge un système d’IA sur « Delta », il cherche peut-être des informations sur Delta Airlines, mais si le système la confond avec Delta Faucet Company, l’utilisateur reçoit une information hors sujet. C’est précisément pour cela qu’AmICited.com surveille la façon dont les systèmes d’IA désambiguïsent les entités — afin d’aider les marques à comprendre si elles sont correctement identifiées et citées dans le contenu généré par l’IA sur plusieurs plateformes.
La désambiguïsation d’entité fonctionne grâce à un processus systématique combinant plusieurs techniques de NLP pour résoudre l’ambiguïté et identifier correctement les entités. Comprendre ce processus explique pourquoi certains systèmes d’IA sont plus performants que d’autres en matière de précision des citations.
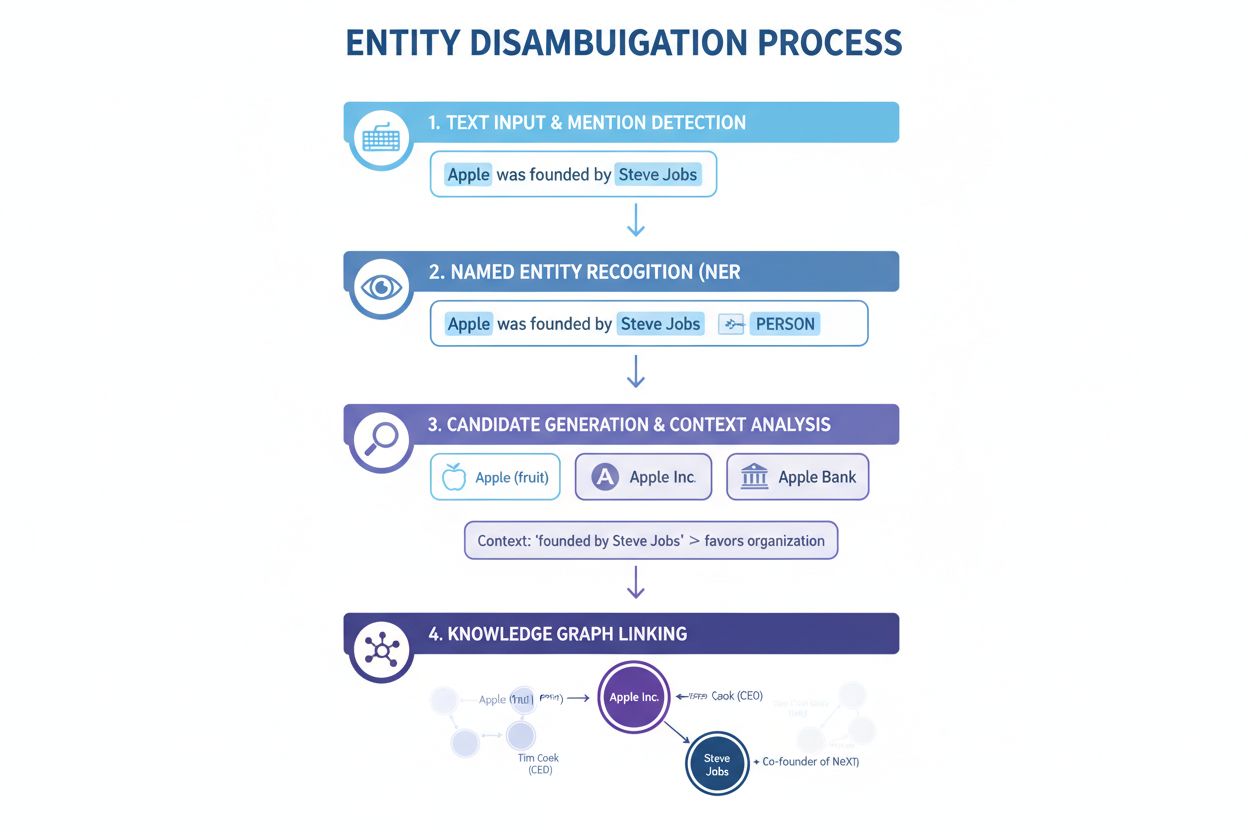
Reconnaissance d’entités nommées (NER) : La première étape consiste à identifier et classer les entités nommées dans le texte. Les systèmes NER analysent les données textuelles et repèrent les mentions d’entités, qu’ils affectent à des catégories prédéfinies comme personne, organisation, lieu, produit ou date. Par exemple, dans la phrase « Apple était l’enfant prodige de Steve Jobs », la NER identifie « Apple » et « Steve Jobs » comme entités et les classe respectivement comme organisation et personne. Cette étape est fondamentale, car il est impossible de désambiguiser sans d’abord identifier les entités présentes.
Catégorisation des entités : Une fois les entités identifiées, il faut les catégoriser plus précisément. Cela ne concerne pas seulement la classification globale mais aussi la compréhension du type et du contexte de chaque entité. Le système analyse le texte environnant pour déterminer si « Apple » apparaît dans un contexte technologique (suggérant Apple Inc.), alimentaire (le fruit) ou financier (Apple Bank). Cette analyse contextuelle permet de restreindre les possibilités avant la désambiguïsation proprement dite.
Désambiguïsation : C’est l’étape clé où le système détermine à quelle entité spécifique il est fait référence. Il évalue plusieurs entités candidates correspondant au nom identifié et utilise divers signaux — contexte, descriptions, relations sémantiques, informations de graphe de connaissances — pour sélectionner l’entité correcte. Pour « Apple était l’enfant prodige de Steve Jobs », le système note que Steve Jobs est fortement associé à Apple Inc., ce qui en fait le bon choix.
Liaison à une base de connaissances : L’étape finale consiste à lier l’entité désambiguïsée à un identifiant unique dans une base de connaissances ou un graphe de connaissances externe, tel que Wikidata, Wikipedia ou une base propriétaire. Cette liaison confirme l’identité de l’entité et enrichit le texte avec des informations sémantiques exploitables pour d’autres traitements et analyses. L’entité se voit attribuer un URI (Identifiant Uniforme de Ressource) servant de référence définitive.
Différentes approches de désambiguïsation d’entité ont émergé au fil du temps, chacune présentant des avantages et limites. Comprendre ces approches éclaire pourquoi la précision varie selon les systèmes d’IA modernes.
Approches basées sur des règles : Ces systèmes utilisent des règles linguistiques prédéfinies et des patrons heuristiques pour désambiguiser les entités. Ils peuvent appliquer des règles du type « si “Apple” apparaît près de “iPhone” ou “MacBook”, il s’agit d’Apple Inc. » ou « si “Delta” apparaît près de “airline” ou “vol”, il s’agit de Delta Airlines ». Si ces systèmes sont interprétables et ne nécessitent pas de grands jeux de données d’entraînement, ils peinent face à des contextes nouveaux et ne s’adaptent pas sans intervention manuelle.
Approches par apprentissage automatique : Les modèles supervisés apprennent à partir de données annotées à prédire la bonne entité en fonction des caractéristiques contextuelles. Ils extraient des attributs du texte environnant et utilisent des algorithmes comme les SVM ou les forêts aléatoires pour classifier la probabilité d’une entité. Ces approches sont plus flexibles que les systèmes à base de règles mais requièrent beaucoup de données annotées et généralisent mal aux entités absentes de l’entraînement.
Apprentissage profond et modèles Transformers : La désambiguïsation moderne s’appuie de plus en plus sur des architectures de type Transformer comme BERT, RoBERTa, ou des modèles spécialisés tels que GENRE et BLINK. Ces modèles de réseaux neuronaux comprennent le contexte en profondeur, captent les relations sémantiques et les subtilités linguistiques. Les Transformers obtiennent d’excellentes performances sur les benchmarks et gèrent mieux les scénarios complexes. Par exemple, le système CEEL (Common English Entity Linking) d’Ontotext utilise une architecture Transformer optimisée pour l’efficacité CPU tout en maintenant une précision élevée, atteignant 96 % en reconnaissance d’entités et 76 % en liaison d’entités sur les standards du domaine.
Intégration des graphes de connaissances : Les systèmes modernes combinent de plus en plus apprentissage automatique et graphes de connaissances — des bases structurées représentant les entités et leurs relations. Les graphes apportent un contexte riche sur les entités, leurs propriétés et leurs connexions. En les interrogeant pendant la désambiguïsation, les systèmes accèdent à des métadonnées et descriptions qui les aident à lever l’ambiguïté avec précision.
La désambiguïsation d’entité est devenue essentielle dans de nombreux secteurs et cas d’usage, chacun tirant profit d’une identification et citation précises des entités.
Moteurs de recherche : Google, Bing et consorts reposent fortement sur la désambiguïsation d’entité pour fournir des résultats pertinents. Lorsqu’un internaute recherche « Apple », le moteur doit déterminer s’il s’intéresse à Apple Inc., au fruit ou à une autre entité. Les moteurs utilisent le contexte de la requête, l’historique utilisateur et les graphes de connaissances pour désambiguiser et présenter le résultat le plus pertinent. C’est pourquoi les résultats pour « Apple » montrent souvent d’abord l’entreprise de technologie : le système a appris qu’il s’agit de l’entité la plus recherchée.
Médias et édition : Les organisations de presse et plateformes de contenu utilisent la désambiguïsation d’entité pour améliorer la découvrabilité et relier les articles. Lorsqu’un article mentionne « Apple », le système peut automatiquement faire le lien avec la fiche de l’entreprise dans une base de connaissances, offrant au lecteur du contexte supplémentaire et des articles associés. Cela améliore l’engagement et la compréhension globale.
Santé : Les établissements médicaux exploitent la désambiguïsation d’entité pour identifier précisément médicaments, maladies ou procédures dans les dossiers patients et la littérature clinique. Désambiguïser les noms de médicaments est crucial : « aspirine » peut désigner la molécule générique, une marque ou un dosage. Préciser l’entité permet aux professionnels d’accéder à la bonne information et d’organiser correctement les dossiers.
Services financiers : Les sociétés d’investissement et analystes financiers utilisent la désambiguïsation d’entité pour suivre les mentions d’entreprises dans les actualités, rapports ou données de marché. Pour évaluer leur exposition, ils doivent identifier toutes les occurrences d’une entreprise à travers diverses sources. La désambiguïsation garantit que les références à « Apple » sont bien attribuées à Apple Inc. et non à d’autres entités, permettant ainsi une analyse des risques précise.
E-commerce : Les commerçants en ligne utilisent la désambiguïsation d’entité pour faire correspondre les mentions de produits aux références de leur catalogue. Lorsqu’un client cherche « ordinateur portable Apple », le système doit désambiguïser « Apple » comme entreprise et trouver les bons produits, ce qui améliore la précision de la recherche et la satisfaction.
AmICited.com applique les principes de désambiguïsation d’entité pour surveiller la façon dont les systèmes d’IA comme ChatGPT, Perplexity et Google AI Overviews traitent les mentions de marque. En suivant si ces systèmes désambiguïsent correctement les entités de marque et les citent avec précision, AmICited aide les marques à comprendre leur visibilité et leur représentation dans le contenu généré par l’IA.
Les graphes de connaissances sont devenus un pilier des systèmes modernes de désambiguïsation d’entité, en fournissant des représentations structurées des entités et de leurs relations. Un graphe de connaissances est essentiellement une base de données d’entités (nœuds) et de relations (arêtes). Chaque nœud contient des métadonnées comme le nom, la description, le type et les propriétés de l’entité. Par exemple, « Apple Inc. » peut avoir pour propriétés « fondée en 1976 », « siège à Cupertino », « secteur : technologie », et des relations telles que « fondée par Steve Jobs » ou « produit l’iPhone ».
Quand un système de désambiguïsation rencontre une mention ambiguë, il peut interroger le graphe pour accéder à des informations contextuelles sur les entités candidates. Cela aide à prendre de meilleures décisions de désambiguïsation. Par exemple, si le texte environnant mentionne « Steve Jobs », le système peut découvrir dans le graphe que ce dernier est fortement lié à Apple Inc., ce qui permet d’identifier la bonne entité. Des graphes comme Wikidata ou Wikipedia fournissent des informations publiques utilisées par de nombreux systèmes d’IA. Les graphes propriétaires de Google, Microsoft et autres offrent des données spécifiques à certains domaines. L’intégration des graphes avec l’apprentissage automatique a nettement amélioré la précision de la désambiguïsation, les systèmes pouvant désormais combiner des schémas appris et des données structurées.
Malgré les progrès, la désambiguïsation d’entité fait toujours face à plusieurs défis limitant sa précision et son applicabilité.
Polysémie et ambiguïté : De nombreux noms d’entités ont plusieurs sens légitimes, et le contexte ne suffit pas toujours à les départager. « Bank » peut désigner une banque ou la berge d’une rivière. « Crane » peut être un oiseau ou une machine. Certains noms sont si ambigus que même les humains hésitent sans contexte supplémentaire. Les systèmes d’IA doivent apprendre à détecter ces cas et à les gérer.
Nouvelles entités : Les bases de connaissances et jeux d’entraînement se périment à mesure que de nouvelles entités apparaissent. Lorsqu’une entreprise naît ou qu’un produit sort, les systèmes peuvent manquer d’informations. La liaison d’entité zero-shot (désambiguïsation d’entités non vues à l’entraînement) reste un défi. Les systèmes doivent savoir reconnaître une entité nouvelle et ne pas la confondre avec une existante au nom similaire.
Variantes de noms et fautes d’orthographe : Les entités possèdent souvent plusieurs noms, abréviations ou variantes. « United States », « USA », « U.S. » ou « America » désignent la même entité. Les fautes compliquent la tâche. Les systèmes doivent faire correspondre toutes ces variantes à l’entité canonique, ce qui est particulièrement difficile dans les contenus générés par les utilisateurs.
Données incomplètes ou obsolètes : Les bases de connaissances peuvent être incomplètes ou dépassées : changement de siège social, de dirigeants, acquisition, etc. Si la base n’est pas actualisée, les systèmes de désambiguïsation peuvent s’appuyer sur de mauvaises informations.
Scalabilité et performance : Traiter de gros volumes de texte avec une désambiguïsation précise demande beaucoup de ressources. La désambiguïsation en temps réel à grande échelle est coûteuse. Il faut souvent arbitrer entre précision, rapidité et coût, ce qui peut réduire la qualité.
Pour les marques et créateurs de contenu, comprendre la désambiguïsation d’entité est essentiel pour garantir une représentation fidèle dans les contenus générés par l’IA. À mesure que les systèmes d’IA gagnent en influence dans la découverte et la consommation d’informations, il devient crucial d’agir pour être correctement désambiguïsé et cité.
Stratégies en amont : Les marques peuvent mettre en place des stratégies pour faciliter leur désambiguïsation par les IA. Il s’agit de créer des signaux numériques clairs et distinctifs permettant une identification sans ambiguïté. L’une des clés est l’implémentation de données structurées via le balisage Schema.org et le format JSON-LD sur le site web de la marque. Ces données informent explicitement les IA sur l’identité de la marque : nom officiel, description, logo, siège, etc. Lorsqu’elles rencontrent le nom de la marque, les IA peuvent s’y référer pour confirmer l’entité correcte.
Optimisation du graphe de connaissances : Les marques doivent s’assurer d’une présence forte sur les graphes comme Wikidata ou Wikipedia : fiches à jour et complètes, liens vers les entités liées, etc. Plus la présence dans les graphes est riche, plus les IA disposent d’informations pour la désambiguïsation.
Stratégie de contenu contextuel : Les marques peuvent créer du contenu donnant un contexte clair sur leur identité et les distinguant des entités homonymes. Des textes mentionnant explicitement le secteur, les produits, les fondateurs, la proposition de valeur aident les IA à comprendre leurs spécificités. Ce contenu contextuel nourrit l’entraînement et les analyses contextuelles des systèmes d’IA.
Surveillance des citations : Des outils comme AmICited.com permettent de surveiller la façon dont les IA désambiguïsent et citent la marque sur différentes plateformes. En suivant si ChatGPT, Perplexity, Google AI Overviews, etc., identifient et citent correctement la marque, il est possible de détecter les erreurs et d’agir. Cette surveillance est cruciale pour la visibilité à l’ère de l’IA générative.
Optimisation pour les moteurs génératifs (GEO) : La désambiguïsation devenant un enjeu clé pour la visibilité IA, il faut intégrer l’optimisation des entités à sa stratégie globale d’optimisation pour les moteurs génératifs. Cela passe par une définition claire, une documentation complète et une différenciation forte de l’entité vis-à-vis des concurrents. La GEO va au-delà du SEO traditionnel et vise à optimiser la compréhension et la représentation des marques par les IA.
La désambiguïsation d’entité évolue au rythme des progrès en IA et des nouveaux défis. Plusieurs tendances dessinent l’avenir de cette capacité critique.
Désambiguïsation multilingue : À mesure que les IA deviennent mondiales, la capacité à désambiguïser à travers les langues devient essentielle. Un nom peut s’écrire différemment selon la langue, et la même entité peut être désignée par divers noms. De nouveaux modèles multilingues avancés sont développés pour permettre une désambiguïsation entre langues, ouvrant la voie à des IA réellement globales.
Désambiguïsation en temps réel dans les grands modèles de langage : Les modèles récents comme GPT-4 ou Claude intègrent de plus en plus la désambiguïsation d’entité en temps réel lors de la génération de texte. Ils peuvent interroger des graphes de connaissances et des bases externes durant l’inférence pour vérifier les informations d’entité et garantir la précision. Cela améliore les citations et limite les hallucinations.
Amélioration du zero-shot learning : Les futurs systèmes devraient mieux gérer les entités jamais vues à l’entraînement. Les techniques d’apprentissage few-shot et zero-shot progressent, rendant possible la désambiguïsation d’entités nouvelles sans besoin de réentraînement fréquent.
Intégration avec la génération augmentée par la recherche (RAG) : Les systèmes combinant modèles de langage et recherche d’information (RAG) gagnent en popularité. Ils peuvent extraire en temps réel des données d’entités depuis des bases de connaissances durant la génération, ce qui améliore la désambiguïsation et la qualité des citations. Cette intégration est un bond en avant pour la précision des citations IA.
Standardisation et interopérabilité : Au fil de l’importance croissante de la désambiguïsation, des standards pour la représentation et la désambiguïsation des entités devraient émerger. Cela facilitera l’interopérabilité entre systèmes et bases de connaissances, permettant aux IA d’accéder et d’utiliser les informations d’entités de façon cohérente.
La désambiguïsation d’entité est passée d’une tâche de niche en NLP à une capacité fondamentale pour garantir la compréhension et la représentation précises de l’information par les IA. À mesure que l’IA influence la découverte et la consommation de contenu, l’importance d’une désambiguïsation fiable ne fera que croître. Pour les marques, créateurs et organisations, comprendre et optimiser la désambiguïsation d’entité est essentiel pour rester visible et bien représenté à l’ère de l’IA générative.
La reconnaissance d'entités nommées identifie la présence d’une entité dans un texte et la classe dans des catégories comme personne, organisation ou lieu. La désambiguïsation d'entité va plus loin en déterminant à quelle entité spécifique il est fait référence lorsque plusieurs entités partagent le même nom. Par exemple, la NER identifie « Apple » comme une organisation, tandis que la désambiguïsation d'entité détermine s’il s’agit de Apple Inc., Apple Bank ou une autre entité.
La désambiguïsation d'entité garantit que les systèmes d’IA comprennent précisément de quelle entité il est question et la citent correctement. Selon le Stanford AI Index 2024, plus de 18 % des sorties de LLM impliquant des entités de marque contiennent des hallucinations ou des erreurs d’attribution. Une désambiguïsation précise évite que les systèmes d’IA ne confondent une entité avec une autre, ce qui est essentiel pour préserver la réputation de la marque et l’exactitude des citations.
Les graphes de connaissances fournissent des informations structurées sur les entités et leurs relations. Lorsqu’un système d’IA rencontre une mention d’entité ambiguë, il peut interroger le graphe de connaissances pour accéder aux métadonnées, descriptions et informations de relations sur les entités candidates. Ces informations contextuelles aident le système à prendre des décisions de désambiguïsation plus éclairées et à sélectionner la bonne entité.
Oui, grâce aux approches de liaison d’entité zero-shot. Les systèmes modernes peuvent reconnaître lorsqu’une entité est nouvelle et la traiter de manière appropriée plutôt que de l’associer à tort à une entité existante. Cependant, cela reste un problème difficile, et les systèmes sont plus performants lorsque les nouvelles entités possèdent des signaux contextuels clairs les distinguant des entités existantes.
Une désambiguïsation d'entité précise garantit que votre marque est correctement identifiée et citée dans les réponses générées par l’IA. Lorsque les systèmes d’IA désambiguïsent correctement votre marque, les utilisateurs reçoivent des informations exactes sur votre organisation, ce qui améliore la visibilité et la réputation de la marque. Une mauvaise désambiguïsation peut entraîner une confusion avec des concurrents ou d’autres entités, réduisant ainsi la visibilité et pouvant nuire à la réputation.
Les principaux défis incluent la polysémie (plusieurs sens pour un même nom), les nouvelles entités absentes des données d’entraînement, les variantes de nom et les fautes d’orthographe, les bases de connaissances incomplètes ou obsolètes, ainsi que les questions de passage à l’échelle. De plus, certains noms d’entités sont intrinsèquement ambigus et le contexte seul peut ne pas suffire pour déterminer la bonne entité.
Les marques peuvent mettre en place des données structurées avec le balisage Schema.org, maintenir des pages Wikipedia et Wikidata précises, créer du contenu contextuel qui distingue clairement leur marque et surveiller la façon dont les systèmes d’IA désambiguïsent leur marque grâce à des outils comme AmICited. Ces stratégies aident les systèmes d’IA à identifier et citer correctement votre marque.
Le contexte est crucial pour la désambiguïsation d'entité. Le texte environnant, les entités liées et les relations sémantiques fournissent tous des signaux aidant les systèmes d’IA à déterminer à quelle entité il est fait référence. Par exemple, si « Apple » apparaît près de « Steve Jobs » et « technologie », le système peut utiliser ce contexte pour le désambiguiser correctement comme Apple Inc. plutôt que le fruit.
Suivez la précision de la désambiguïsation d'entité sur les plateformes d’IA et assurez-vous que votre marque est correctement identifiée et citée dans les réponses générées par l’IA.
La reconnaissance d'entités est une capacité NLP de l'IA identifiant et catégorisant les entités nommées dans le texte. Découvrez son fonctionnement, ses applic...

Découvrez comment la liaison d'entités connecte votre marque à travers les systèmes d'IA. Découvrez des stratégies pour améliorer la reconnaissance de la marque...

Découvrez comment construire et optimiser l’entité de votre marque pour la reconnaissance par l’IA. Mettez en œuvre le balisage schema, le lien d’entité et les ...