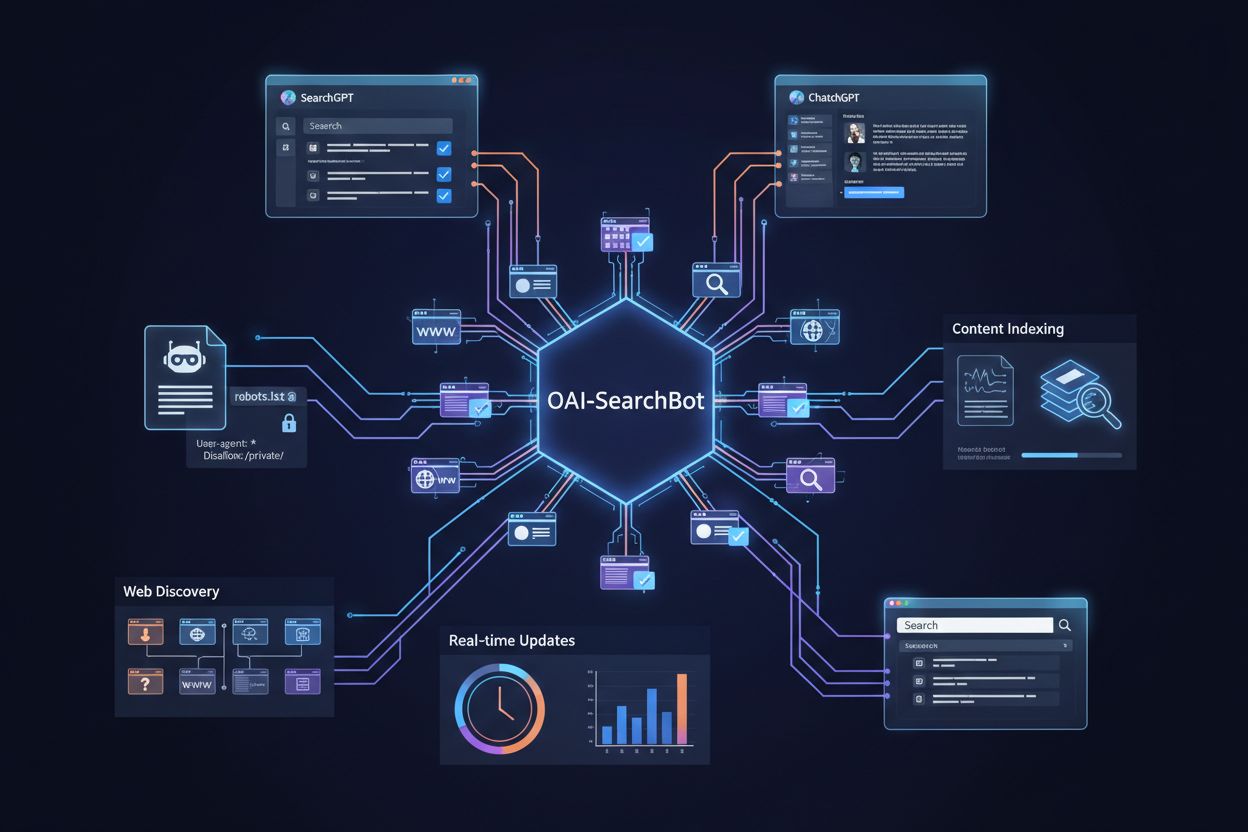
Le robot d’indexation officiel d’OpenAI qui collecte des données d’entraînement pour des modèles d’IA comme ChatGPT et GPT-4. Les propriétaires de sites web peuvent contrôler l’accès via robots.txt en utilisant les directives ‘User-agent: GPTBot’. Le crawler respecte les protocoles web standards et n’indexe que le contenu publiquement accessible.
GPTBot
Le robot d’indexation officiel d’OpenAI qui collecte des données d’entraînement pour des modèles d’IA comme ChatGPT et GPT-4. Les propriétaires de sites web peuvent contrôler l’accès via robots.txt en utilisant les directives 'User-agent: GPTBot'. Le crawler respecte les protocoles web standards et n’indexe que le contenu publiquement accessible.
Qu’est-ce que GPTBot ?
GPTBot est le robot d’indexation officiel d’OpenAI, conçu pour indexer les contenus accessibles au public sur Internet afin d’entraîner et d’améliorer des modèles d’IA comme ChatGPT et GPT-4. Contrairement aux robots d’indexation généralistes tels que Googlebot, GPTBot a une mission spécifique : collecter des données permettant à OpenAI d’améliorer ses modèles linguistiques et d’offrir de meilleures réponses pilotées par l’IA aux utilisateurs. Les propriétaires de sites peuvent identifier GPTBot grâce à sa chaîne user agent distinctive (“GPTBot/1.0”), qui apparaît dans les journaux serveur et les plateformes d’analyse lorsqu’il accède à leurs pages. GPTBot respecte le fichier robots.txt, ce qui signifie que les propriétaires de sites peuvent contrôler l’accès du robot à leur contenu en ajoutant des directives spécifiques à ce fichier. Le robot n’indexe que le contenu accessible au public et ne tente pas de contourner l’authentification ni d’accéder à des zones restreintes des sites web. Comprendre le rôle et le comportement de GPTBot est essentiel pour les propriétaires de sites souhaitant prendre des décisions éclairées sur l’autorisation ou le blocage de ce robot sur leurs propriétés numériques.
Comment fonctionne GPTBot
GPTBot fonctionne en parcourant systématiquement les pages web, en analysant leur contenu et en envoyant les données aux serveurs d’OpenAI pour traitement et entraînement des modèles. Le robot vérifie d’abord le fichier robots.txt du site pour déterminer quelles pages il est autorisé à explorer, respectant les directives des propriétaires avant toute activité d’indexation. Une fois identifié via sa chaîne user agent, GPTBot télécharge et traite le contenu des pages, extrayant le texte, les métadonnées et les informations structurelles qui alimentent les ensembles de données d’entraînement. Le robot peut générer une consommation de bande passante significative, certains sites signalant 30 To ou plus de trafic mensuel généré par tous les robots combinés, bien que l’impact individuel de GPTBot varie selon la taille du site et la pertinence du contenu.
Nom du robot
Objectif
Respecte robots.txt
Impact sur le SEO
Utilisation des données
GPTBot
Entraînement de modèles IA
Oui
Indirect (visibilité IA)
Jeux de données d’entraînement
Googlebot
Indexation des recherches
Oui
Direct (classements)
Résultats de recherche
Bingbot
Indexation des recherches
Oui
Direct (classements)
Résultats de recherche
ClaudeBot
Entraînement de modèles IA
Oui
Indirect (visibilité IA)
Jeux de données d’entraînement
Les propriétaires de sites peuvent surveiller l’activité de GPTBot dans les journaux serveur en recherchant la chaîne user agent spécifique, ce qui permet de suivre la fréquence des crawls et d’identifier d’éventuels impacts sur les performances. Le comportement du robot est conçu pour respecter les ressources serveur, mais les sites à fort trafic peuvent tout de même observer une consommation de bande passante notable lorsque plusieurs robots IA opèrent simultanément.
Pourquoi les propriétaires de sites bloquent GPTBot
De nombreux propriétaires de sites choisissent de bloquer GPTBot par crainte d’une utilisation du contenu sans compensation, OpenAI utilisant les contenus crawlés pour entraîner des modèles IA commerciaux sans offrir de bénéfices ou de paiement direct aux créateurs. La charge serveur constitue une autre préoccupation majeure, notamment pour les petits sites ou ceux à bande passante limitée, car les robots IA peuvent consommer d’importantes ressources—certains sites rapportent plus de 30 To de trafic mensuel généré par tous les robots, GPTBot y contribuant de façon significative. L’exposition des données et les risques de sécurité inquiètent aussi les créateurs qui craignent que leurs informations propriétaires, secrets commerciaux ou données sensibles soient accidentellement indexés et utilisés dans l’entraînement IA, ce qui pourrait compromettre leur avantage concurrentiel ou enfreindre des accords de confidentialité. Le contexte juridique entourant les données d’entraînement IA reste incertain, avec des questions non résolues sur la conformité RGPD, les obligations CCPA et la violation du droit d’auteur, créant des risques potentiels pour OpenAI comme pour les sites autorisant le crawling sans restriction. Les statistiques révèlent qu’environ 3,5 % des sites bloquent activement GPTBot, et que plus de 30 grandes publications du top 100 bloquent le robot, dont The New York Times, CNN, Associated Press et Reuters—signe que les créateurs de contenus à forte autorité perçoivent des risques majeurs. L’ensemble de ces facteurs rend le blocage de GPTBot de plus en plus courant chez les éditeurs, médias et sites à fort contenu qui cherchent à protéger leur propriété intellectuelle et à garder le contrôle sur l’utilisation de leurs contenus.
Pourquoi les propriétaires de sites autorisent GPTBot
Les propriétaires de sites qui autorisent l’accès à GPTBot reconnaissent la valeur stratégique de la visibilité sur ChatGPT, sachant que la plateforme compte environ 800 millions d’utilisateurs hebdomadaires qui interagissent régulièrement avec des réponses IA pouvant référencer ou résumer leurs contenus indexés. Quand GPTBot crawl un site, il augmente la probabilité que son contenu soit cité, résumé ou mentionné dans les réponses de ChatGPT, offrant une représentation de la marque dans les interfaces IA et atteignant des utilisateurs qui se tournent de plus en plus vers ces outils plutôt que vers les moteurs de recherche traditionnels. Les études montrent que le trafic issu de la recherche IA convertit 23 fois mieux que le trafic organique traditionnel, c’est-à-dire que les utilisateurs découvrant du contenu via des synthèses IA sont beaucoup plus engagés et enclins à convertir que les visiteurs issus des moteurs classiques. Autoriser GPTBot, c’est aussi une forme de préparation à l’avenir, la recherche et la découverte de contenus pilotées par l’IA devenant rapidement dominantes dans la façon dont les internautes s’informent, ce qui fait de l’adoption anticipée une source d’avantage compétitif. Les propriétaires qui s’ouvrent à GPTBot bénéficient également de l’Optimisation pour les moteurs génératifs (GEO), une discipline émergente visant à optimiser le contenu non plus pour les algorithmes classiques mais pour les systèmes IA, générant une croissance de trafic à long terme. En autorisant GPTBot, les éditeurs et entreprises visionnaires se positionnent pour capter le trafic du segment d’utilisateurs en forte croissance qui s’appuie sur les outils IA pour s’informer et prendre des décisions.
Comment bloquer GPTBot
Bloquer GPTBot est simple et nécessite de modifier le fichier robots.txt de votre site, situé à la racine du répertoire et qui contrôle l’accès des robots à l’ensemble du domaine. L’approche la plus simple consiste à ajouter un blocage complet pour tous les robots OpenAI :
User-agent: GPTBot
Disallow: /
Si vous souhaitez bloquer GPTBot uniquement sur certains répertoires et autoriser l’accès ailleurs, utilisez des directives ciblées :
Au-delà des modifications de robots.txt, les propriétaires de sites peuvent mettre en place d’autres méthodes de blocage comme le filtrage IP via un pare-feu, des Web Application Firewalls (WAF) qui filtrent selon le user agent, ou la limitation de débit pour restreindre la bande passante consommée. Pour un contrôle maximal, certains combinent plusieurs approches—robots.txt comme principal mécanisme, blocage IP en complément contre les robots qui ignoreraient les directives. Après mise en place, vérifiez l’efficacité du blocage dans vos journaux serveur pour confirmer que GPTBot n’accède plus à votre contenu.
Secteurs devant envisager le blocage
Certains secteurs sont particulièrement exposés aux risques liés à l’accès non restreint des robots IA et doivent évaluer si le blocage de GPTBot correspond à leurs intérêts et stratégies de protection :
Éditeurs & Médias (journaux, magazines, agences de presse) : le journalisme original représente un investissement majeur et un avantage concurrentiel ; des publications comme The New York Times, Associated Press ou Reuters bloquent GPTBot pour protéger leurs exclusivités
Plateformes e-commerce (Amazon, sites de vente) : descriptions produits, stratégies tarifaires et avis clients sont des données propriétaires exploitables par la concurrence via l’IA
Plateformes à contenu généré par les utilisateurs (réseaux sociaux, forums, sites d’avis) : les contenus créés par les utilisateurs peuvent être utilisés sans consentement ni compensation, soulevant des enjeux éthiques et juridiques sur les droits des utilisateurs
Sites de données à haute autorité (institutions de recherche, bases académiques, répertoires spécialisés) : travaux propriétaires, jeux de données, savoirs spécialisés ont une grande valeur commerciale et doivent rester sous contrôle du créateur
Services juridiques et financiers : informations clients, stratégies juridiques et conseils financiers exigent la confidentialité et ne peuvent être exposés dans des jeux de données IA
Santé et contenu médical : données patients, dossiers médicaux et informations cliniques doivent respecter la réglementation (HIPAA, etc.) interdisant l’utilisation non autorisée des données
Ces secteurs doivent mettre en œuvre des stratégies de blocage pour préserver leur avantage compétitif, protéger leurs données sensibles et assurer leur conformité réglementaire.
Surveillance et détection
Les propriétaires de sites doivent surveiller régulièrement leurs journaux serveur pour identifier l’activité de GPTBot et suivre les schémas de crawling, ce qui donne de la visibilité sur la façon dont les systèmes IA accèdent et utilisent potentiellement leur contenu. L’identification de GPTBot est simple—le robot se reconnaît à la chaîne user agent “GPTBot/1.0” dans les en-têtes HTTP, ce qui le distingue facilement dans les journaux serveur et les plateformes d’analyse. La plupart des outils modernes d’analyse et de suivi SEO (Google Analytics, Semrush, Ahrefs, plateformes spécialisées) catégorisent et rapportent automatiquement l’activité de GPTBot, permettant de suivre la fréquence de crawl, la consommation de bande passante et les pages accédées sans analyse manuelle. Examiner directement les logs permet d’obtenir des informations détaillées sur les requêtes de GPTBot : horodatage, URL consultées, codes de réponse, bande passante utilisée, offrant une vision granulaire du comportement du robot. Une surveillance régulière est essentielle car le comportement des robots peut évoluer, de nouveaux robots IA apparaître, et l’efficacité des blocages doit être vérifiée périodiquement pour s’assurer du bon fonctionnement des directives. Les propriétaires de sites doivent établir des métriques de référence pour le trafic normal des robots et enquêter sur toute anomalie pouvant signaler une augmentation de l’activité IA ou des problèmes de sécurité nécessitant une attention particulière.
Les standards de sécurité d’OpenAI
OpenAI a pris des engagements publics pour un développement responsable de l’IA et la gestion des données, incluant des déclarations explicites sur le respect par GPTBot des préférences exprimées dans robots.txt et autres directives techniques. L’entreprise met en avant la protection des données et les pratiques responsables, reconnaissant que les créateurs ont un intérêt légitime à contrôler l’utilisation et la rémunération de leurs contenus, même si l’approche actuelle d’OpenAI ne prévoit pas de compensation directe. La politique officielle d’OpenAI confirme que GPTBot respecte les directives robots.txt, l’entreprise ayant intégré des mécanismes de conformité dans son infrastructure et attendant des propriétaires qu’ils utilisent les outils techniques standards pour contrôler l’accès. OpenAI s’est aussi dite prête à dialoguer avec les éditeurs et créateurs sur les questions d’utilisation des données, même si les accords formels de licence ou de rémunération restent limités. Les politiques d’OpenAI évoluent face aux défis juridiques, à la pression réglementaire et au retour de l’industrie, ce qui laisse penser que de futures versions de GPTBot pourraient intégrer plus de garanties, de transparence ou de mécanismes de compensation. Les propriétaires de sites doivent surveiller les communications officielles et mises à jour d’OpenAI pour anticiper les évolutions de la politique de crawling et d’utilisation des données.
GPTBot vs autres robots IA
OpenAI exploite trois types de robots distincts pour différents usages : GPTBot (crawling général pour l’entraînement des modèles), ChatGPT-User (crawl des liens partagés par les utilisateurs ChatGPT) et ChatGPT-Plugins (accès via les intégrations plugins)—chacun ayant des chaînes user agent et des schémas d’accès différents. En dehors des robots OpenAI, le paysage IA est peuplé d’autres robots concurrents : Google-Extended (robot d’entraînement IA de Google), CCBot (Commoncrawl), Perplexity (moteur IA), Claude (modèle IA d’Anthropic), ainsi que des robots émergents d’autres sociétés, chacun avec ses finalités et usages de données. Les propriétaires de sites doivent choisir entre blocage sélectif (ciblant certains robots comme GPTBot en autorisant d’autres) ou blocage complet (restreindre tous les robots IA pour garder un contrôle total). La prolifération des robots IA signifie que bloquer GPTBot seul ne suffit pas forcément à protéger le contenu de l’entraînement IA, d’autres robots pouvant accéder et indexer le même contenu via d’autres moyens. Certains optent pour des stratégies graduelles, bloquant les robots les plus agressifs ou commerciaux tout en autorisant les plus petits ou orientés recherche. Comprendre les différences entre ces robots aide à prendre des décisions éclairées sur qui bloquer en fonction des préoccupations relatives à l’utilisation des données, à l’impact concurrentiel et aux objectifs business.
Impact sur le SEO et la visibilité
L’influence de ChatGPT sur les usages de la recherche transforme la façon dont les internautes découvrent l’information, avec 800 millions d’utilisateurs hebdomadaires se tournant de plus en plus vers l’IA, modifiant radicalement la compétition pour la visibilité. Les synthèses générées par l’IA et les extraits mis en avant dans ChatGPT constituent de nouveaux canaux de découverte : un contenu bien classé dans la recherche traditionnelle peut être ignoré s’il n’est pas retenu pour une réponse IA. L’Optimisation pour les moteurs génératifs (GEO) devient cruciale pour les créateurs de contenus innovants, se concentrant sur la structure, la clarté et l’autorité du contenu afin d’accroître les chances d’apparaître dans les réponses et synthèses IA. Les enjeux de visibilité sont majeurs : les sites qui bloquent GPTBot risquent de perdre des opportunités d’apparaître dans ChatGPT, limitant le trafic issu de la recherche IA, tandis que ceux qui autorisent l’accès se positionnent pour cette nouvelle forme de découverte. Les recherches montrent que 86,5 % du contenu du top 20 Google contient des éléments partiellement générés par l’IA, preuve que l’intégration IA devient la norme et non plus l’exception. Le positionnement compétitif dépend de plus en plus de la visibilité à la fois dans les moteurs traditionnels et les systèmes IA, rendant stratégique la décision d’autoriser ou non GPTBot pour le succès SEO à long terme et la croissance du trafic organique. Les propriétaires de sites doivent équilibrer la protection de leur contenu et le risque de perdre en visibilité dans des systèmes IA qui deviennent les principaux vecteurs de découverte pour des millions d’utilisateurs dans le monde.
Questions fréquemment posées
Qu’est-ce que GPTBot et en quoi diffère-t-il de Googlebot ?
GPTBot est le robot d’indexation officiel d’OpenAI conçu pour collecter des données d’entraînement pour des modèles d’IA tels que ChatGPT et GPT-4. Contrairement à Googlebot, qui indexe le contenu pour les résultats des moteurs de recherche, GPTBot collecte des données spécifiquement pour améliorer les modèles linguistiques. Les deux robots respectent les directives du fichier robots.txt et n’accèdent qu’au contenu publiquement disponible, mais ils remplissent des fonctions fondamentalement différentes dans l’écosystème numérique.
Dois-je bloquer GPTBot sur mon site web ?
La décision dépend de vos objectifs commerciaux et de votre stratégie de contenu. Bloquez GPTBot si vous avez du contenu propriétaire, opérez dans des secteurs réglementés ou avez des préoccupations concernant la propriété intellectuelle. Autorisez GPTBot si vous souhaitez être visible dans ChatGPT (800 M d’utilisateurs hebdomadaires), bénéficier du trafic de recherche IA (qui convertit 23 fois mieux que l’organique), ou si vous souhaitez préparer votre présence numérique pour la recherche pilotée par l’IA.
Comment bloquer GPTBot avec robots.txt ?
Ajoutez ces lignes à votre fichier robots.txt pour bloquer GPTBot sur l’ensemble de votre site : User-agent: GPTBot / Disallow: /. Pour bloquer des répertoires spécifiques, remplacez le slash par le chemin du répertoire. Pour bloquer tous les robots d’OpenAI, ajoutez des entrées User-agent séparées pour GPTBot, ChatGPT-User et ChatGPT-Plugins. Les changements sont effectifs immédiatement et facilement réversibles.
Quel est l’impact de GPTBot sur mon serveur et ma bande passante ?
L’impact de GPTBot varie selon la taille de votre site et la pertinence de votre contenu. Bien que l’effet d’un robot individuel soit généralement gérable, plusieurs robots IA simultanés peuvent consommer une bande passante significative—certains sites signalent plus de 30 To de trafic mensuel généré par tous les robots. Surveillez vos journaux serveur pour suivre l’activité de GPTBot et mettez en place une limitation de débit ou un blocage IP si la consommation de bande passante devient problématique.
Puis-je bloquer partiellement GPTBot sur certaines pages ?
Oui, vous pouvez utiliser des directives ciblées dans robots.txt pour bloquer GPTBot sur des répertoires ou pages spécifiques tout en autorisant l’accès au reste du site. Par exemple, vous pouvez interdire les répertoires /private/ et /admin/ tout en autorisant le reste. Cette approche sélective permet de protéger le contenu sensible tout en maintenant la visibilité des pages publiques dans les systèmes d’IA.
Comment savoir si GPTBot visite mon site web ?
Vérifiez vos journaux serveur pour la chaîne user agent 'GPTBot/1.0' dans les en-têtes des requêtes HTTP. La plupart des plateformes d’analyse (Google Analytics, Semrush, Ahrefs) catégorisent et rapportent automatiquement l’activité de GPTBot. Vous pouvez aussi utiliser des outils de suivi SEO spécialisés pour surveiller l’activité des robots IA. Un suivi régulier vous aide à comprendre la fréquence de crawl et à identifier tout impact sur les performances.
Quelles sont les implications juridiques du blocage ou de l’autorisation de GPTBot ?
Le cadre légal évolue encore. Autoriser GPTBot soulève des questions sur la conformité RGPD, les obligations CCPA et la violation de droits d’auteur, bien qu’OpenAI affirme respecter les directives robots.txt. Bloquer GPTBot est juridiquement simple mais peut limiter votre visibilité dans les systèmes d’IA. Consultez un conseiller juridique si vous opérez dans des secteurs réglementés ou traitez des données sensibles pour déterminer la meilleure approche dans votre cas.
Quel est l’impact de l’autorisation de GPTBot sur mon SEO et ma visibilité dans la recherche ?
Autoriser GPTBot n’a pas d’impact direct sur le classement Google traditionnel, mais augmente votre visibilité dans les réponses de ChatGPT et autres résultats de recherche alimentés par l’IA. Avec 800 M d’utilisateurs de ChatGPT et un trafic de recherche IA convertissant 23 fois mieux que l’organique, autoriser GPTBot vous positionne pour une visibilité à long terme dans les systèmes d’IA. Bloquer GPTBot peut réduire les opportunités d’apparaître dans les réponses générées par l’IA, limitant potentiellement le trafic issu du segment de recherche à la croissance la plus rapide.
Surveillez votre marque dans les résultats de recherche IA
Suivez comment votre marque apparaît sur ChatGPT, Perplexity, Google AI et d’autres plateformes d’IA. Obtenez des insights en temps réel sur les citations IA et la visibilité avec AmICited.
Qu'est-ce que GPTBot et devez-vous l'autoriser ? Guide complet pour les propriétaires de sites web
Découvrez ce qu'est GPTBot, comment il fonctionne et s'il faut autoriser ou bloquer le robot d'exploration web d'OpenAI. Comprenez l'impact sur la visibilité de...
GPTBot vs OAI-SearchBot : Comprendre les différents crawlers d'OpenAI
Découvrez les principales différences entre les crawlers GPTBot et OAI-SearchBot. Comprenez leurs objectifs, leurs comportements d'exploration et comment les gé...
Découvrez ce qu'est OAI-SearchBot, comment il fonctionne et comment optimiser votre site web pour le robot de recherche dédié d'OpenAI utilisé par SearchGPT et ...
8 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.