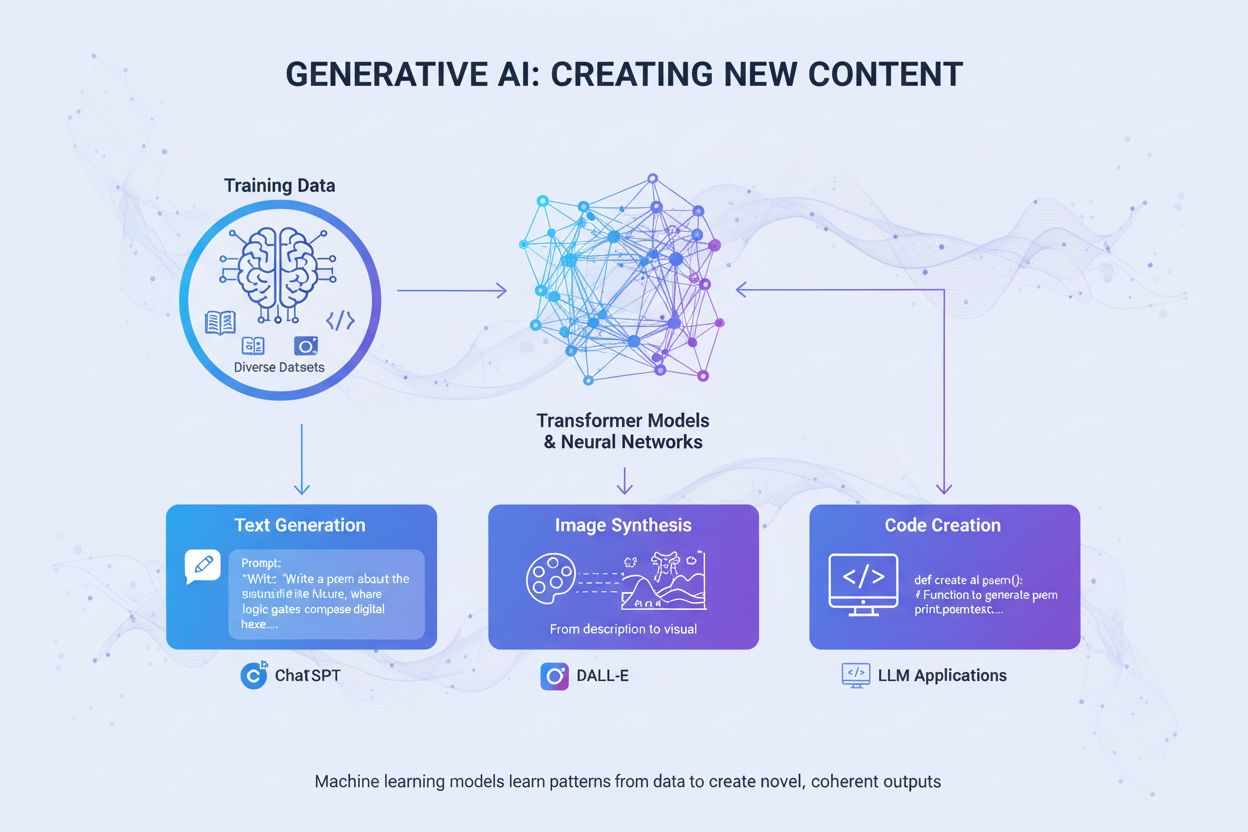
IA générative
L’IA générative crée de nouveaux contenus à partir de données d’entraînement grâce à des réseaux neuronaux. Découvrez son fonctionnement, ses applications dans ...
14 min de lecture

L’inférence est le processus par lequel un modèle d’IA entraîné génère des sorties, des prédictions ou des conclusions à partir de nouvelles données en appliquant les schémas et les connaissances acquis lors de l’entraînement. Elle représente la phase opérationnelle où les systèmes d’IA appliquent leur intelligence acquise à des problèmes concrets dans des environnements de production.
L'inférence est le processus par lequel un modèle d'IA entraîné génère des sorties, des prédictions ou des conclusions à partir de nouvelles données en appliquant les schémas et les connaissances acquis lors de l'entraînement. Elle représente la phase opérationnelle où les systèmes d'IA appliquent leur intelligence acquise à des problèmes concrets dans des environnements de production.
L’inférence est le processus par lequel un modèle d’intelligence artificielle entraîné génère des sorties, des prédictions ou des conclusions à partir de nouvelles données en appliquant les schémas et connaissances acquis lors de la phase d’entraînement. Dans le contexte des systèmes d’IA, l’inférence représente la phase opérationnelle où les modèles d’apprentissage automatique passent du laboratoire à des environnements de production pour résoudre des problèmes concrets. Lorsque vous interagissez avec ChatGPT, Perplexity, Google AI Overviews ou Claude, vous assistez à l’inférence en IA en action—le modèle prend votre entrée et génère des réponses intelligentes basées sur les schémas appris à partir de vastes ensembles de données d’entraînement. L’inférence est fondamentalement différente de l’entraînement ; alors que l’entraînement enseigne au modèle quoi faire, l’inférence est le moment où le modèle agit concrètement, appliquant ses connaissances acquises à des données qu’il n’a jamais rencontrées auparavant.
La distinction entre entraînement de l’IA et inférence de l’IA est essentielle pour comprendre le fonctionnement des systèmes d’intelligence artificielle modernes. Lors de la phase d’entraînement, les data scientists alimentent les réseaux neuronaux avec d’énormes ensembles de données soigneusement sélectionnés, permettant au modèle d’apprendre des schémas, des relations et des règles de prise de décision grâce à une optimisation itérative. Ce processus est intensif en calcul, nécessitant souvent des semaines ou des mois de traitement sur du matériel spécialisé comme les GPU et TPU. Une fois l’entraînement terminé et le modèle ayant convergé vers des poids et paramètres optimaux, il entre en phase d’inférence. À ce stade, le modèle est figé—il n’apprend plus de nouvelles données—et applique ses schémas appris pour générer des prédictions ou des sorties sur des entrées jamais vues. Selon des recherches d’IBM et Oracle, l’inférence est là où la vraie valeur commerciale de l’IA se réalise, car elle permet aux organisations de déployer des capacités d’IA à grande échelle dans les systèmes de production. Le marché de l’inférence en IA était évalué à 106,15 milliards USD en 2025 et devrait croître jusqu’à 254,98 milliards USD d’ici 2030, reflétant la demande explosive pour les capacités d’inférence dans tous les secteurs.
L’inférence en IA fonctionne via un processus en plusieurs étapes qui transforme des données brutes en sorties intelligentes. Lorsqu’un utilisateur soumet une requête à un grand modèle de langage tel que ChatGPT, le pipeline d’inférence débute par l’encodage de l’entrée, où le texte est converti en jetons numériques que le réseau neuronal peut traiter. Le modèle entre alors dans la phase de pré-remplissage, où tous les jetons d’entrée sont traités simultanément à travers chaque couche du réseau neuronal, permettant au modèle de comprendre le contexte et les relations dans la requête de l’utilisateur. Cette phase est exigeante en calcul mais nécessaire à la compréhension. Après la phase de pré-remplissage, le modèle passe à la phase de décodage, où il génère les jetons de sortie de manière séquentielle, un à un, chaque nouveau jeton dépendant de tous les précédents dans la séquence. Cette génération séquentielle crée l’effet de flux caractéristique observé lors de l’interaction avec des chatbots IA. Enfin, l’étape de conversion de la sortie transforme les jetons prédits en texte lisible, images ou autres formats compréhensibles et exploitables par l’utilisateur. L’ensemble de ce processus doit se réaliser en quelques millisecondes pour les applications temps réel, faisant de l’optimisation de la latence d’inférence un enjeu crucial pour les fournisseurs de services IA.
Les organisations qui déploient des systèmes d’IA doivent choisir entre trois principales architectures d’inférence, chacune optimisée pour des cas d’usage et des exigences de performance distincts. L’inférence par lots traite de grands volumes de données hors ligne à intervalles réguliers, ce qui la rend idéale pour des scénarios où la réponse en temps réel n’est pas requise, comme la génération de tableaux de bord analytiques quotidiens, l’évaluation des risques hebdomadaire ou la mise à jour nocturne de recommandations. Cette approche est très efficace et économique car elle permet de traiter des milliers de prédictions simultanément, amortissant les coûts informatiques sur de nombreuses requêtes. L’inférence en ligne, appelée aussi inférence dynamique, génère des prédictions instantanément à la demande avec une latence minimale, essentielle pour les applications interactives comme les chatbots, moteurs de recherche ou systèmes de détection de fraude en temps réel. L’inférence en ligne nécessite une infrastructure sophistiquée pour maintenir une faible latence et une haute disponibilité, utilisant souvent des stratégies de cache et d’optimisation de modèle pour garantir des réponses en quelques millisecondes. L’inférence en flux traite en continu les données provenant de capteurs, dispositifs IoT ou pipelines de données en temps réel, faisant des prédictions pour chaque point de données à son arrivée. Ce type alimente des applications telles que la maintenance prédictive d’équipements industriels, les véhicules autonomes qui traitent des données de capteurs en temps réel, et les systèmes de gestion urbaine qui analysent en continu les flux de circulation. Chaque type d’inférence implique des considérations architecturales, des exigences matérielles et des stratégies d’optimisation différentes.
| Aspect | Inférence par lots | Inférence en ligne | Inférence en flux |
|---|---|---|---|
| Exigence de latence | Secondes à minutes | Millisecondes | Temps réel (sous la seconde) |
| Traitement des données | Grands ensembles hors ligne | Requêtes uniques à la demande | Flux continu de données |
| Cas d’usage | Analytique, reporting, recommandations | Chatbots, recherche, détection de fraude | Surveillance IoT, systèmes autonomes |
| Efficacité des coûts | Élevée (amortie sur de nombreuses prédictions) | Moyenne (infrastructure toujours active) | Moyenne à élevée (selon le volume de données) |
| Scalabilité | Excellente (traitement en masse) | Bonne (nécessite l’équilibrage de charge) | Excellente (traitement distribué) |
| Priorité d’optimisation du modèle | Débit | Équilibre latence et débit | Équilibre latence et précision |
| Exigences matérielles | GPU/CPU standards | GPU/TPU haute performance | Matériel edge spécialisé ou systèmes distribués |
L’optimisation de l’inférence est devenue une discipline clé alors que les organisations cherchent à déployer des modèles d’IA plus efficacement et à moindre coût. La quantification est l’une des techniques d’optimisation les plus efficaces, réduisant la précision numérique des poids du modèle de 32 bits standard à 8 ou même 4 bits. Cette réduction peut diminuer la taille du modèle de 75 à 90 % tout en maintenant 95 à 99 % de la précision initiale, ce qui se traduit par des inférences plus rapides et de moindres besoins en mémoire. L’élagage du modèle élimine les neurones, connexions ou couches non essentiels du réseau neuronal, supprimant les paramètres redondants qui n’apportent pas de contribution significative aux prédictions. Les recherches montrent que l’élagage peut réduire la complexité du modèle de 50 à 80 % sans perte de précision notable. La distillation des connaissances forme un modèle “élève” plus petit et rapide à imiter le comportement d’un grand modèle “enseignant” plus précis, permettant un déploiement sur des appareils à ressources limitées tout en maintenant des performances raisonnables. L’optimisation du traitement par lots regroupe plusieurs requêtes d’inférence pour maximiser l’utilisation du GPU et le débit. Le cache clé-valeur stocke les résultats intermédiaires pour éviter des calculs redondants lors de la phase de décodage des modèles de langage. Selon des recherches de NVIDIA, la combinaison de plusieurs techniques d’optimisation peut permettre un gain de performance de 10x tout en réduisant les coûts d’infrastructure de 60 à 70 %. Ces optimisations sont essentielles pour déployer l’inférence à grande échelle, en particulier pour les organisations traitant des milliers de requêtes simultanées.
L’accélération matérielle est fondamentale pour atteindre les exigences de latence et de débit des charges d’inférence modernes en IA. Les unités de traitement graphique (GPU) restent les accélérateurs d’inférence les plus largement déployés grâce à leur architecture de traitement parallèle, naturellement adaptée aux opérations matricielles dominantes dans les réseaux neuronaux. Les GPU NVIDIA alimentent la majorité des déploiements d’inférence de grands modèles de langage dans le monde, leurs cœurs CUDA spécialisés permettant un parallélisme massif. Les unités de traitement tensoriel (TPU), développées par Google, sont des ASIC conçus spécifiquement pour les opérations de réseaux neuronaux, offrant des performances par watt supérieures à celles des GPU généralistes pour certains workloads. Les FPGA offrent un matériel personnalisable reprogrammable pour des tâches d’inférence spécifiques, procurant une flexibilité pour des applications spécialisées. Les ASIC comme la TPU de Google ou la WSE-3 de Cerebras sont conçus pour des charges d’inférence particulières, offrant des performances exceptionnelles mais une flexibilité limitée. Le choix du matériel dépend de nombreux facteurs : architecture du modèle, latence requise, besoins en débit, contraintes de consommation et coût total de possession. Pour l’inférence en edge sur appareils mobiles ou capteurs IoT, des accélérateurs edge spécialisés et des unités de traitement neuronal (NPU) permettent une inférence efficace avec une consommation minimale. La transition mondiale vers les usines d’IA—infrastructures hautement optimisées pour produire de l’intelligence à grande échelle—a entraîné d’importants investissements dans le matériel d’inférence, les entreprises déployant des milliers de GPU et TPU dans les data centers pour répondre à la demande croissante en services IA.
Les systèmes d’IA générative comme ChatGPT, Claude et Perplexity reposent entièrement sur l’inférence pour générer du texte, du code, des images et d’autres contenus de type humain. Lorsque vous soumettez une requête à ces systèmes, le processus d’inférence commence par la conversion de votre entrée en représentations numériques (tokenization) que le réseau neuronal peut traiter. Le modèle exécute ensuite la phase de pré-remplissage, traitant tous vos jetons d’entrée simultanément pour construire une compréhension globale de la demande : contexte, intention, nuances. Ensuite, le modèle passe à la phase de décodage, générant les jetons de sortie de façon séquentielle, prédisant le jeton le plus probable à chaque étape sur la base de tous les précédents et des schémas appris lors de l’entraînement. Cette génération jeton par jeton explique le flux de texte en temps réel lors de l’utilisation de ces services. Le processus d’inférence doit équilibrer plusieurs objectifs concurrents : générer des réponses précises, cohérentes et pertinentes tout en maintenant une faible latence pour conserver l’engagement des utilisateurs. La décodage spéculatif, une technique avancée d’optimisation de l’inférence, permet à un modèle plus petit de prédire plusieurs jetons à l’avance tandis qu’un modèle plus grand valide les prédictions, réduisant sensiblement la latence. L’échelle de l’inférence pour les grands modèles de langage est colossale—ChatGPT d’OpenAI traite des millions de requêtes d’inférence chaque jour, chacune générant des centaines ou milliers de jetons, nécessitant une infrastructure computationnelle massive et des stratégies d’optimisation sophistiquées pour rester viable économiquement.
Pour les organisations attentives à la présence de leur marque et à la citation de leur contenu dans les réponses générées par l’IA, la surveillance de l’inférence prend une importance croissante. Lorsque des systèmes comme Perplexity, Google AI Overviews ou Claude génèrent des réponses, ils effectuent des inférences sur leurs modèles entraînés pour produire des sorties susceptibles de référencer ou citer votre domaine, votre marque ou votre contenu. Comprendre le fonctionnement des systèmes d’inférence aide les organisations à optimiser leur stratégie de contenu pour assurer une représentation correcte dans les réponses générées par l’IA. AmICited est spécialisé dans la surveillance de l’apparition des marques et domaines dans les résultats d’inférence IA sur plusieurs plateformes, fournissant une visibilité sur la façon dont les systèmes d’IA citent et référencent votre contenu. Cette surveillance est cruciale car les systèmes d’inférence peuvent inclure ou non votre marque dans leurs réponses selon la qualité des données d’entraînement, les signaux de pertinence et les choix d’optimisation du modèle. Les organisations peuvent utiliser les données de surveillance de l’inférence pour comprendre quels contenus sont cités, à quelle fréquence leur marque apparaît dans les réponses de l’IA, et si leur domaine est correctement attribué. Ces informations permettent des décisions éclairées sur l’optimisation de contenu, la stratégie SEO et le positionnement de la marque dans le nouveau paysage de recherche piloté par l’IA. À mesure que l’inférence devient l’interface principale de découverte d’information, le suivi de votre présence dans les résultats générés par l’IA devient aussi important que le référencement traditionnel.
Le déploiement de systèmes d’inférence à grande échelle présente de nombreux défis techniques, opérationnels et stratégiques auxquels les organisations doivent faire face. La gestion de la latence reste un défi majeur, car les utilisateurs attendent des réponses en moins d’une seconde des applications IA interactives, alors même que les modèles complexes comportant des milliards de paramètres exigent un temps de calcul significatif. L’optimisation du débit est tout aussi essentielle—les organisations doivent servir des milliers voire des millions de requêtes d’inférence simultanées tout en maintenant une latence et une précision acceptables. La dérive du modèle survient lorsque la performance en inférence se dégrade avec le temps à mesure que les distributions de données réelles s’éloignent des données d’entraînement, nécessitant une surveillance continue et une ré-entraîne périodique. L’interprétabilité et l’explicabilité deviennent de plus en plus importantes à mesure que les systèmes d’inférence IA prennent des décisions ayant un impact sur les utilisateurs, exigeant des organisations qu’elles comprennent et expliquent comment les modèles parviennent à certaines prédictions. La conformité réglementaire pose de nouveaux défis, avec des cadres comme l’EU AI Act imposant des exigences de transparence, détection des biais et supervision humaine dans les systèmes d’inférence IA. La qualité des données reste fondamentale—les systèmes d’inférence ne peuvent être meilleurs que les données sur lesquelles ils ont été entraînés, des données médiocres menant à des résultats biaisés, inexacts, voire dangereux. Les coûts d’infrastructure peuvent être importants, les déploiements d’inférence à large échelle nécessitant des investissements significatifs en GPU, TPU, réseaux et refroidissement. La pénurie de talents fait que les organisations peinent à trouver des ingénieurs et data scientists spécialisés dans l’optimisation de l’inférence, le déploiement de modèles et le MLOps, augmentant les coûts de recrutement et ralentissant les délais de déploiement.
L’avenir de l’inférence en IA évolue rapidement dans plusieurs directions transformatrices qui vont redéfinir la façon dont les organisations déploient et exploitent les systèmes d’IA. L’inférence en edge—l’exécution de l’inférence sur des dispositifs locaux plutôt que dans le cloud—s’accélère, portée par les progrès en compression de modèle, matériel edge spécialisé et préoccupations liées à la vie privée. Ce changement permettra des capacités IA temps réel sur smartphones, appareils IoT et systèmes autonomes sans dépendre de la connectivité cloud. L’inférence multimodale, où les modèles traitent et génèrent texte, images, audio et vidéo simultanément, devient de plus en plus courante, nécessitant de nouvelles stratégies d’optimisation et considérations matérielles. Les modèles de raisonnement qui effectuent des inférences multi-étapes pour résoudre des problèmes complexes émergent, avec des systèmes comme o1 d’OpenAI démontrant que l’inférence elle-même peut évoluer avec plus de temps de calcul et de jetons, pas seulement la taille du modèle. Les architectures de serving désagrégées gagnent du terrain, où des grappes matérielles distinctes gèrent les phases de pré-remplissage et de décodage, optimisant l’utilisation des ressources pour différents motifs de calcul. Le décodage spéculatif et d’autres techniques d’inférence avancées deviennent la norme, permettant de réduire la latence par 2 à 3. L’inférence edge combinée à l’apprentissage fédéré permettra de déployer des capacités IA localement tout en préservant la vie privée et en réduisant les besoins en bande passante. Le marché de l’inférence en IA devrait croître à un TCAC de 19,2 % jusqu’en 2030, porté par l’adoption croissante par les entreprises, de nouveaux cas d’usage et la nécessité économique d’optimiser les coûts d’inférence. À mesure que l’inférence devient la principale charge de travail de l’infrastructure IA, les techniques d’optimisation, le matériel spécialisé et les frameworks logiciels dédiés à l’inférence deviendront de plus en plus sophistiqués et essentiels pour l’avantage concurrentiel.
L'entraînement d'une IA est le processus qui consiste à enseigner à un modèle à reconnaître des schémas à l'aide de grands ensembles de données, tandis que l'inférence correspond au moment où ce modèle entraîné applique ce qu'il a appris pour générer des prédictions ou des résultats sur de nouvelles données. L'entraînement est intensif en calcul et se produit une seule fois, tandis que l'inférence est généralement plus rapide, moins gourmande en ressources, et se produit en continu dans des environnements de production. On peut comparer l'entraînement à l'étude pour un examen et l'inférence au passage de l'examen lui-même.
La latence d'inférence—le temps nécessaire à un modèle pour générer une sortie—est cruciale pour l'expérience utilisateur et les applications en temps réel. Une faible latence permet des réponses instantanées dans les chatbots, la traduction en temps réel, les véhicules autonomes et les systèmes de détection de fraude. Une latence élevée peut rendre les applications inutilisables pour les tâches sensibles au temps. Les entreprises optimisent la latence grâce à des techniques telles que la quantification, l'élagage des modèles, et du matériel spécialisé comme les GPU et TPU afin de respecter les accords de niveau de service.
Les trois principaux types sont l'inférence par lots (traitement de grands ensembles de données hors ligne), l'inférence en ligne (génération de prédictions instantanément à la demande), et l'inférence en flux (traitement continu de données provenant de capteurs ou d'appareils IoT). L'inférence par lots convient à des scénarios comme les tableaux de bord analytiques quotidiens, l'inférence en ligne alimente les chatbots et moteurs de recherche, et l'inférence en flux permet des systèmes de surveillance en temps réel. Chaque type a des exigences de latence et des cas d'utilisation différents.
La quantification réduit la précision numérique des poids du modèle de 32 bits à 8 bits ou moins, ce qui réduit considérablement la taille du modèle et les besoins en calcul tout en maintenant la précision. L'élagage supprime les neurones ou connexions non critiques du réseau neuronal, réduisant ainsi la complexité. Les deux techniques peuvent réduire la latence d'inférence de 50 à 80 % et diminuer les coûts matériels. Ces méthodes d'optimisation sont essentielles pour déployer les modèles sur des appareils edge ou mobiles.
L'inférence est le mécanisme central qui permet aux systèmes d'IA générative de produire du texte, des images et du code. Lorsque vous interrogez ChatGPT, le processus d'inférence tokenize votre entrée, la traite à travers les couches du réseau neuronal entraîné, et génère des jetons de sortie un à un. La phase de pré-remplissage traite tous les jetons d'entrée simultanément, tandis que la phase de décodage génère la sortie de façon séquentielle. Cette capacité d'inférence est ce qui rend les grands modèles de langage réactifs et pratiques pour des applications réelles.
La surveillance de l'inférence suit la performance des modèles d'IA en production, y compris la précision, la latence et la qualité des sorties. Des plateformes comme AmICited surveillent où les marques et domaines apparaissent dans les réponses générées par l'IA sur des systèmes comme ChatGPT, Perplexity et Google AI Overviews. Comprendre le comportement de l'inférence aide les organisations à s'assurer que leur contenu est correctement cité et représenté lorsque les systèmes d'IA génèrent des sorties qui font référence à leurs domaines ou informations de marque.
Les accélérateurs d'inférence courants incluent les GPU (unités de traitement graphique) pour le traitement parallèle, les TPU (unités de traitement tensoriel) optimisées pour les réseaux neuronaux, les FPGA (réseaux logiques programmables sur site) pour des charges de travail personnalisables, et les ASIC (circuits intégrés spécifiques à une application) conçus pour des tâches spécifiques. Les GPU sont les plus utilisés grâce à leur bon rapport performance/coût, tandis que les TPU excellent pour l'inférence à grande échelle. Le choix dépend des besoins en débit, contraintes de latence et du budget.
Le marché mondial de l'inférence en IA était évalué à 106,15 milliards USD en 2025 et devrait atteindre 254,98 milliards USD d'ici 2030, soit un taux de croissance annuel composé (TCAC) de 19,2 %. Cette croissance rapide reflète l'adoption croissante des applications d'IA par les entreprises, avec 78 % des organisations utilisant l'IA en 2024 contre 55 % en 2023. Cette expansion est portée par la demande d'applications d'IA en temps réel dans des secteurs comme la santé, la finance, le commerce de détail et les systèmes autonomes.
Commencez à suivre comment les chatbots IA mentionnent votre marque sur ChatGPT, Perplexity et d'autres plateformes. Obtenez des informations exploitables pour améliorer votre présence IA.
L’IA générative crée de nouveaux contenus à partir de données d’entraînement grâce à des réseaux neuronaux. Découvrez son fonctionnement, ses applications dans ...
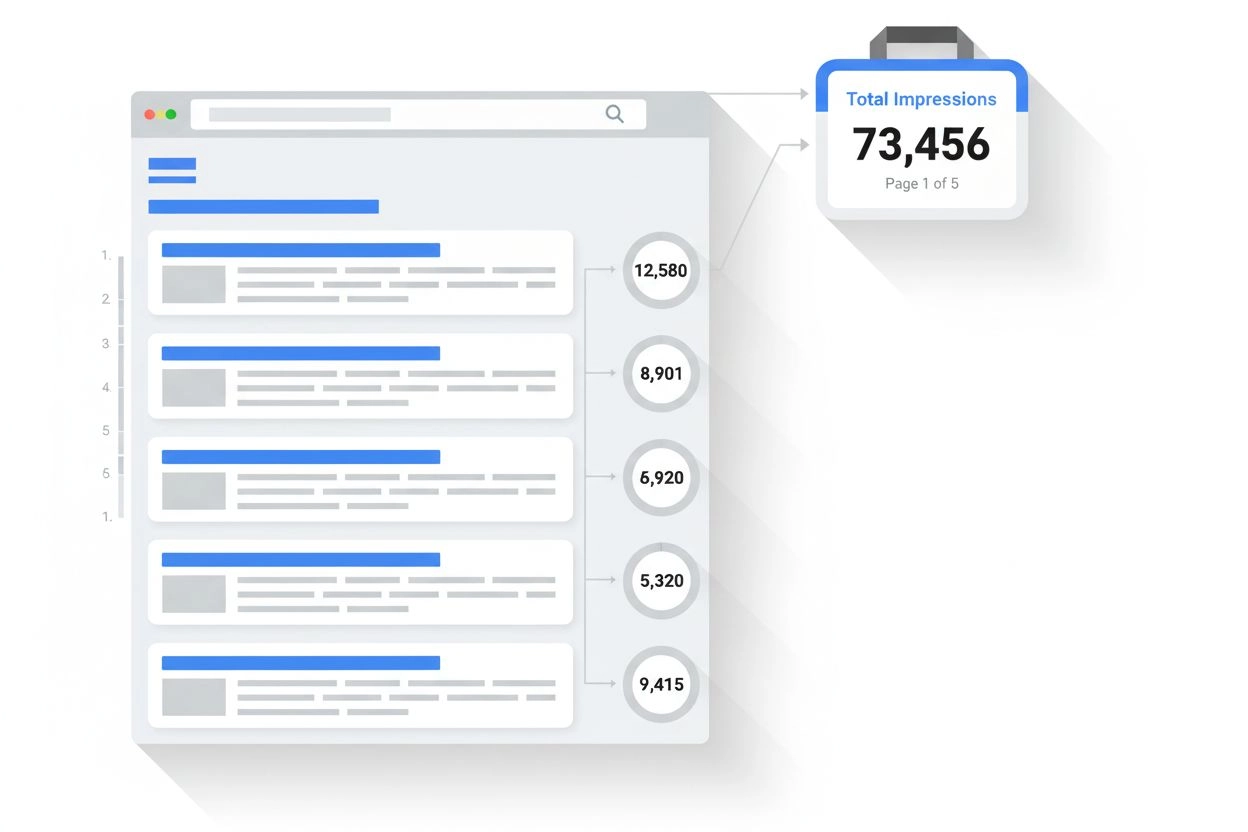
Découvrez ce qu’est une impression dans les résultats de recherche et la surveillance de l’IA. Comprenez comment les impressions sont comptabilisées sur Google ...

Découvrez ce que sont les citations IA, comment elles fonctionnent sur ChatGPT, Perplexity et Google AI, et pourquoi elles sont importantes pour la visibilité d...