JSON-LD : Guide complet de l’implémentation et des bénéfices SEO
Découvrez ce qu’est JSON-LD et comment l’implémenter pour le SEO. Découvrez les avantages du balisage structuré pour Google, ChatGPT, Perplexity et la visibilit...
17 min de lecture
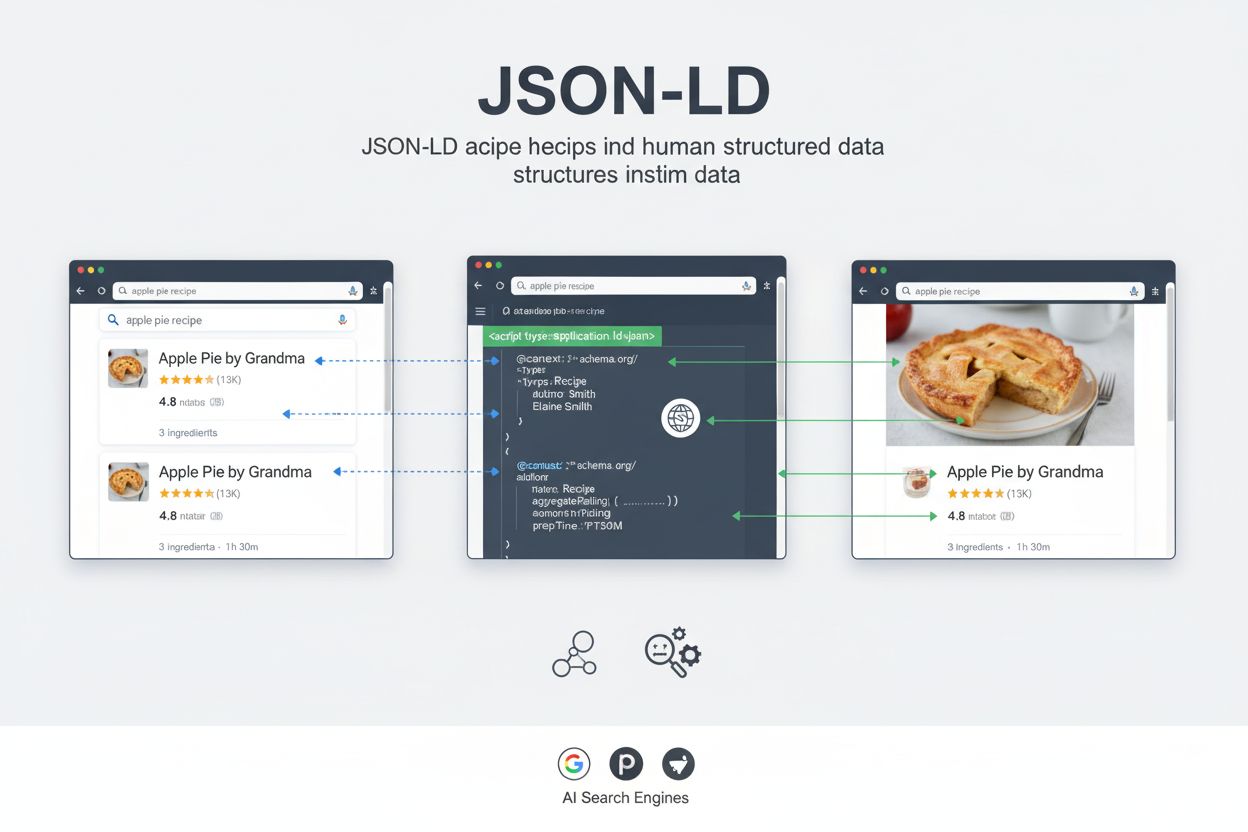
JSON-LD (JavaScript Object Notation for Linked Data) est un format léger, standardisé par le W3C, pour exprimer des données structurées en utilisant la syntaxe JSON, permettant aux moteurs de recherche et aux systèmes d’IA de comprendre le contenu web via le vocabulaire schema.org. Il est intégré dans les pages web sous forme de balisage lisible par machine, aidant les moteurs de recherche à afficher des résultats enrichis et améliorant la découvrabilité du contenu sur les plateformes alimentées par l’IA.
JSON-LD (JavaScript Object Notation for Linked Data) est un format léger, standardisé par le W3C, pour exprimer des données structurées en utilisant la syntaxe JSON, permettant aux moteurs de recherche et aux systèmes d’IA de comprendre le contenu web via le vocabulaire schema.org. Il est intégré dans les pages web sous forme de balisage lisible par machine, aidant les moteurs de recherche à afficher des résultats enrichis et améliorant la découvrabilité du contenu sur les plateformes alimentées par l’IA.
JSON-LD signifie JavaScript Object Notation for Linked Data et représente un format léger et standardisé pour l’expression de données structurées sur les pages web. Établi en tant que Recommandation W3C depuis janvier 2014, JSON-LD combine la simplicité de la syntaxe JSON avec la puissance sémantique des vocabulaires de données liées, en particulier schema.org. Contrairement à d’autres formats de données structurées qui entremêlent le balisage au contenu HTML, JSON-LD est intégré dans une balise <script> séparée dans l’en-tête ou le corps de la page, gardant les données distinctes du balisage de présentation. Cette séparation rend JSON-LD exceptionnellement facile à mettre en œuvre, à maintenir et à faire évoluer sur de grands sites web et systèmes de gestion de contenu.
Le but principal de JSON-LD est de fournir un contexte lisible par machine qui aide les moteurs de recherche, les systèmes d’IA et d’autres applications web à comprendre la signification et les relations dans le contenu des pages web. Lorsqu’il est correctement mis en place, JSON-LD permet aux moteurs de recherche d’afficher des résultats enrichis—des extraits de recherche améliorés qui incluent des notes, des prix, des images, des détails d’événements, et d’autres informations structurées. Pour les plateformes de recherche propulsées par l’IA comme ChatGPT, Perplexity, Google AI Overviews et Claude, JSON-LD sert de pont essentiel entre le contenu lisible par l’humain et les données interprétables par la machine, améliorant la précision et la pertinence des réponses et citations générées par l’IA.
JSON-LD est devenu le format de données structurées recommandé par Google et d’autres grands moteurs de recherche car il minimise les erreurs de mise en œuvre et fonctionne parfaitement avec les technologies web modernes, y compris les frameworks JavaScript et la génération dynamique de contenu. La flexibilité du format lui permet d’exprimer des structures de données complexes et imbriquées, ce qui le rend adapté à une grande variété de types de contenu, allant des informations produit simples à des hiérarchies organisationnelles complexes et des détails d’événements.
JSON-LD est né du besoin de faire le lien entre les formats de données JSON traditionnels et les standards du web sémantique. Avant JSON-LD, les développeurs travaillant avec des données liées utilisaient généralement des formats comme RDF/XML ou Turtle, puissants mais complexes et peu adaptés aux pratiques courantes du développement web. Le développement de JSON-LD a débuté au début des années 2010 au sein du W3C JSON-LD Community Group, reconnaissant que JSON était devenu la norme de facto pour les API web et l’échange de données. Le format a été officiellement standardisé par le W3C en 2014, avec des améliorations successives aboutissant à la recommandation complète de JSON-LD 1.1 en 2020.
L’adoption de JSON-LD a fortement accéléré après que Google et d’autres moteurs de recherche majeurs ont commencé à le recommander comme format privilégié pour le balisage schema.org en 2013. Cette recommandation a été déterminante car elle a signalé à la communauté du développement web que JSON-LD n’était pas seulement un exercice académique, mais une solution pratique et éprouvée pour les enjeux réels de SEO et de découverte de contenu. Au cours de la dernière décennie, l’adoption de JSON-LD a explosé, avec des données récentes indiquant que 41 % de tous les sites web utilisent désormais JSON-LD pour le balisage de données structurées, contre 34 % en 2022. Parmi les sites mettant en œuvre un quelconque balisage structuré, JSON-LD est utilisé par environ 70 %, ce qui en fait le format dominant dans le paysage des données structurées.
L’évolution de JSON-LD a également été façonnée par l’essor des moteurs de recherche et modèles de langage alimentés par l’IA. Alors que des plateformes comme ChatGPT, Perplexity ou Google AI Overviews se sont généralisées, l’importance de JSON-LD a augmenté car ces systèmes s’appuient fortement sur les données structurées pour extraire des informations contextuelles et précises des pages web. La capacité du format à définir clairement les types d’entités, les relations et les propriétés le rend inestimable pour l’entraînement et le fonctionnement de systèmes d’IA devant comprendre le contenu web à grande échelle.
Les documents JSON-LD suivent la syntaxe standard JSON mais incorporent des mots-clés réservés, précédés du symbole @, qui leur confèrent une signification sémantique. Les plus fondamentaux sont @context, @type et @id. La propriété @context spécifie l’espace de noms du vocabulaire—généralement https://schema.org—qui définit la signification de toutes les propriétés et types utilisés dans le balisage. Ce contexte agit comme une déclaration d’espace de noms, similaire aux espaces de noms XML, garantissant une interprétation cohérente des noms de propriétés sur différents systèmes et plateformes.
La propriété @type indique le type de schéma de l’entité décrite, comme Product, Article, Event, Organization ou LocalBusiness. Chaque type de schema.org dispose d’un ensemble de propriétés associées pour décrire des instances de ce type. Par exemple, un type Product peut inclure des propriétés telles que name, description, price, image, aggregateRating et offers. La propriété @id fournit un identifiant unique pour l’entité, généralement une URL qui mène à plus d’informations sur cette entité.
Au-delà de ces mots-clés principaux, les documents JSON-LD contiennent des propriétés personnalisées qui correspondent directement au vocabulaire schema.org. Ces propriétés peuvent contenir des valeurs simples (chaînes, nombres, dates) ou des objets imbriqués complexes représentant des entités liées. Par exemple, une entité Product peut avoir une propriété offers contenant un objet Offer imbriqué avec son propre @type et des propriétés telles que price et priceCurrency. Cette capacité d’imbrication permet à JSON-LD d’exprimer des relations de données complexes et des hiérarchies difficiles à représenter dans des formats plus plats comme Microdata.
| Aspect | JSON-LD | Microdata | RDFa |
|---|---|---|---|
| Emplacement de l’implémentation | Balise <script> séparée dans <head> ou <body> | Intégré dans les attributs HTML | Intégré dans les attributs HTML |
| Facilité de mise en œuvre | Très facile ; modifications HTML minimales requises | Modérée ; nécessite l’ajout d’attributs HTML | Modérée à complexe ; nécessite la déclaration d’espaces de noms |
| Complexité de maintenance | Faible ; données séparées de la présentation | Moyenne ; balisage entremêlé au contenu | Moyenne à élevée ; vocabulaires multiples possibles |
| Support du contenu dynamique | Excellent ; fonctionne avec l’injection JavaScript | Limité ; nécessite un rendu côté serveur | Limité ; nécessite un rendu côté serveur |
| Recommandation Google | Recommandé | Pris en charge | Pris en charge |
| Taux d’adoption (2024) | 41 % de tous les sites ; 70 % des sites à données structurées | ~20 % des sites à données structurées | ~15 % des sites à données structurées |
| Flexibilité du vocabulaire | Un seul vocabulaire par document (généralement schema.org) | Un seul vocabulaire par document | Vocabulaires multiples pris en charge |
| Complexité d’imbrication | Excellente ; hiérarchie JSON naturelle | Bonne ; nécessite plusieurs déclarations itemscope | Bonne ; gère les relations complexes |
| Compatibilité moteurs de recherche IA | Excellente ; préférée par ChatGPT, Perplexity, Claude | Bonne ; prise en charge mais moins privilégiée | Bonne ; prise en charge mais moins privilégiée |
Lorsqu’un robot d’indexation ou un système d’IA rencontre une page web contenant du balisage JSON-LD, il analyse la balise <script type="application/ld+json"> et extrait les données structurées. Le robot utilise le @context pour comprendre le vocabulaire utilisé, puis interprète chaque propriété selon les définitions de schema.org. Ce processus permet au moteur de recherche d’extraire des informations précises et lisibles par machine sur le contenu de la page, sans dépendre du traitement du langage naturel ou d’heuristiques.
Pour Google Search, le balisage JSON-LD permet l’affichage de résultats enrichis—des extraits de recherche améliorés incluant des éléments visuels comme des notes, des prix, des images et des détails d’événements. Lorsqu’un robot Google parcourt une page produit avec un balisage JSON-LD correctement implémenté, il peut extraire le nom du produit, le prix, la disponibilité, les avis et les images directement à partir des données structurées. Ces informations servent à générer un résultat enrichi dans les résultats de recherche, généralement avec un taux de clic supérieur à celui des liens classiques. Des recherches menées par de grands sites montrent l’impact : Rotten Tomatoes a constaté un taux de clic supérieur de 25 % sur les pages enrichies de données structurées, tandis que Nestlé a mesuré un taux de clic supérieur de 82 % sur les pages affichées en résultats enrichis.
Pour les moteurs de recherche IA comme Perplexity, ChatGPT et Google AI Overviews, JSON-LD joue un rôle différent mais tout aussi crucial. Ces systèmes utilisent les données structurées pour comprendre la signification sémantique du contenu, identifier les entités et relations clés, et extraire des informations précises à inclure dans les réponses générées par l’IA. Lorsqu’un système IA rencontre du balisage JSON-LD, il peut identifier en toute confiance le type d’entité décrit, ses propriétés et ses relations avec d’autres entités. Cette compréhension structurée aide les systèmes d’IA à fournir des réponses plus précises, contextuelles et à attribuer correctement les informations aux sites sources.
Pour une implémentation efficace de JSON-LD, il convient de respecter plusieurs principes clés. Premièrement, JSON-LD doit être placé dans la section <head> du document HTML, même s’il peut aussi se trouver dans le <body>. Le placement dans <head> est généralement privilégié car il garantit que les données structurées sont analysées avant le contenu de la page, mais les moteurs de recherche et systèmes d’IA modernes peuvent analyser JSON-LD depuis n’importe où dans la page.
Deuxièmement, le @context doit toujours être défini explicitement, généralement sous la forme "@context": "https://schema.org". Cela garantit que tous les noms de propriété et types sont interprétés conformément aux définitions de schema.org. Bien qu’il soit techniquement possible d’utiliser plusieurs contextes ou vocabulaires personnalisés, la grande majorité des implémentations web utilisent exclusivement schema.org.
Troisièmement, le balisage JSON-LD doit représenter fidèlement le contenu visible de la page. Les moteurs de recherche et systèmes d’IA attendent que les données structurées correspondent à ce que voient les utilisateurs. Ajouter un balisage JSON-LD sur des informations non visibles ou contradictoires avec le contenu affiché peut entraîner des sanctions ou l’ignorance totale du balisage. Ce principe est essentiel pour maintenir la confiance des moteurs de recherche et garantir que les systèmes d’IA citent vos contenus avec exactitude.
Quatrièmement, toutes les propriétés requises pour un type de schéma donné doivent être incluses. Même si schema.org définit de nombreuses propriétés optionnelles, inclure les propriétés obligatoires permet aux moteurs de recherche de valider et d’afficher correctement le balisage. Par exemple, un schéma Product requiert au minimum les propriétés name, description et offers pour être éligible à l’affichage en résultat enrichi.
Cinquièmement, JSON-LD doit être validé à l’aide d’outils comme le Test des résultats enrichis de Google ou le Validateur Schema.org avant son déploiement. Ces outils vérifient les erreurs de syntaxe, l’absence de propriétés requises et d’autres problèmes susceptibles d’empêcher la reconnaissance du balisage. Tester durant le développement évite que des problèmes n’atteignent la production et garantit le bon fonctionnement du balisage.
La mise en œuvre de données structurées JSON-LD apporte des bénéfices mesurables à plusieurs niveaux. D’un point de vue SEO, JSON-LD permet des résultats enrichis qui augmentent significativement le taux de clics. Food Network a converti 80 % de ses pages à l’utilisation des données structurées et mesuré une augmentation de 35 % des visites. Rakuten a constaté que les utilisateurs passent 1,5 fois plus de temps sur les pages avec données structurées par rapport aux pages non structurées, et a observé un taux d’interaction 3,6 fois supérieur sur les pages AMP dotées de fonctionnalités de recherche.
D’un point de vue visibilité dans la recherche IA, JSON-LD devient un enjeu crucial à mesure que les moteurs de recherche alimentés par l’IA se généralisent. Les sites qui mettent en place du balisage JSON-LD ont plus de chances que leur contenu soit compris, cité et mis en avant avec précision dans les réponses générées par l’IA. Ceci est particulièrement important pour les utilisateurs d’AmICited qui souhaitent suivre et surveiller la façon dont leur marque, domaine et URLs apparaissent dans les résultats IA sur des plateformes comme ChatGPT, Perplexity, Google AI Overviews et Claude. Une implémentation correcte de JSON-LD garantit que les systèmes IA disposent du contexte structuré nécessaire pour attribuer et citer fidèlement votre contenu.
D’un point de vue technique, JSON-LD réduit la complexité de mise en œuvre et la charge de maintenance. Étant donné que le balisage est séparé du contenu HTML, les développeurs peuvent gérer les données structurées indépendamment des évolutions du design des pages. Cette séparation est particulièrement précieuse pour les grandes organisations dotées de systèmes de gestion de contenu complexes, où plusieurs équipes interviennent sur le contenu et la technique.
D’un point de vue expérience utilisateur, JSON-LD améliore indirectement l’engagement en permettant l’affichage de résultats de recherche plus riches et plus informatifs. Les utilisateurs sont plus enclins à cliquer sur des résultats incluant notes, prix, images et autres informations structurées, ce qui entraîne plus de trafic et de meilleures conversions pour les sites qui mettent en œuvre JSON-LD efficacement.
JSON-LD s’intègre parfaitement aux pratiques et technologies modernes de développement web. Contrairement à Microdata et RDFa, qui nécessitent un rendu côté serveur pour être correctement analysés par les moteurs de recherche, JSON-LD peut être injecté dynamiquement dans les pages via JavaScript. Cette capacité est cruciale pour les applications monopage (SPA), les progressive web apps (PWA) et autres sites fortement basés sur JavaScript qui génèrent dynamiquement leur contenu.
Les systèmes de gestion de contenu (CMS) comme WordPress, Shopify, Wix et Drupal offrent de plus en plus un support natif ou via des extensions pour la génération de JSON-LD. Cette démocratisation de l’implémentation JSON-LD permet même aux utilisateurs non techniques d’ajouter des données structurées à leurs pages sans écrire de code. De nombreux CMS génèrent automatiquement le balisage JSON-LD à partir des métadonnées et du contenu, réduisant ainsi la charge des développeurs et créateurs de contenu.
JSON-LD fonctionne également très bien avec les architectures CMS headless, où le contenu est géré séparément de la présentation. Dans ces systèmes, JSON-LD peut être généré côté serveur et livré avec la réponse de la page, ou généré côté client via des frameworks JavaScript comme React, Vue ou Angular. Cette flexibilité fait de JSON-LD un choix adapté à presque toutes les architectures web modernes.
https://schema.org pour garantir une interprétation cohérente du vocabulaireL’importance de JSON-LD ne peut que croître à l’avenir. À mesure que les moteurs de recherche alimentés par l’IA et les grands modèles de langage se sophistiquent, le besoin de données structurées de haute qualité et lisibles par machine augmentera. Les moteurs de recherche et systèmes d’IA utilisent de plus en plus les données structurées non seulement pour l’affichage, mais aussi comme composant clé de leurs algorithmes de compréhension et de classement.
Les évolutions émergentes de JSON-LD incluent JSON-LD-star, qui étend le format pour supporter des relations de graphe de connaissances plus complexes, et CBOR-LD, qui propose une représentation binaire plus compacte des données JSON-LD. Ces extensions laissent entrevoir que l’écosystème JSON-LD continuera d’évoluer pour répondre aux besoins croissants des applications web et systèmes IA de plus en plus sophistiqués.
L’essor des moteurs de recherche IA représente un changement de paradigme dans l’utilisation des données structurées. Les moteurs de recherche traditionnels s’en servent principalement pour l’affichage, afin de générer des résultats enrichis. Les moteurs IA, eux, s’appuient sur les données structurées comme entrée fondamentale à leurs processus de compréhension et de raisonnement. Cela signifie que les sites mettant en œuvre efficacement JSON-LD bénéficieront d’un avantage significatif en termes de visibilité et de fréquence de citation dans la recherche IA.
Enfin, avec la montée des préoccupations autour de la vie privée et de la gouvernance des données, JSON-LD pourrait jouer un rôle croissant dans l’expression de la provenance des données, des licences et des droits d’utilisation. La flexibilité et l’extensibilité du format en font un excellent outil pour exprimer des métadonnées complexes sur les sources de données et les restrictions d’usage, ce qui deviendra de plus en plus important à mesure que les organisations chercheront à garder le contrôle sur l’utilisation de leurs données par les systèmes d’IA.
Pour les organisations utilisant des plateformes comme AmICited afin de surveiller leur apparition dans les résultats de recherche IA, la mise en place d’un balisage JSON-LD complet est un investissement stratégique. En fournissant aux systèmes d’IA un contexte structuré clair sur votre contenu, vous augmentez la probabilité que votre marque, domaine et URLs soient compris, cités et mis en avant avec précision dans les réponses générées par l’IA. À mesure que la recherche IA prend de l’ampleur, JSON-LD deviendra un composant essentiel de toute stratégie globale de SEO et de visibilité de contenu.
JSON-LD et Microdata sont deux formats de données structurées, mais ils diffèrent dans leur implémentation. JSON-LD est intégré dans une balise <script> séparée et n’est pas entremêlé avec le contenu HTML, ce qui le rend plus facile à maintenir et à mettre en œuvre à grande échelle. Microdata utilise des attributs HTML directement dans le contenu de la page. Google recommande JSON-LD pour la plupart des implémentations car il est moins sujet aux erreurs des utilisateurs et fonctionne parfaitement avec le contenu injecté dynamiquement par les frameworks JavaScript et les systèmes de gestion de contenu.
JSON-LD permet aux moteurs de recherche de mieux comprendre le contenu des pages, ce qui peut aboutir à des résultats enrichis—des affichages de recherche améliorés avec notes, prix, images et autres informations structurées. Des études montrent que les pages avec balisage de données structurées ont des taux de clics nettement plus élevés. Par exemple, Nestlé a mesuré un taux de clics supérieur de 82 % sur les pages affichées en tant que résultats enrichis par rapport aux pages sans résultats enrichis, démontrant l’impact direct de JSON-LD sur la performance de recherche et l’engagement des utilisateurs.
Le @context dans JSON-LD spécifie l’espace de noms du vocabulaire (généralement schema.org) qui définit la signification des propriétés et des types utilisés dans le balisage. Il agit comme un espace de noms XML, indiquant aux moteurs de recherche et aux systèmes d’IA comment interpréter les données. Par exemple, @context : 'https://schema.org' indique à l’analyseur que les valeurs @type telles que 'Product' ou 'Article' font référence aux définitions de schema.org, garantissant ainsi une interprétation cohérente sur différentes plateformes et systèmes.
Oui, les données structurées JSON-LD deviennent de plus en plus importantes pour les moteurs de recherche IA. Des plateformes comme ChatGPT, Perplexity et Google AI Overviews utilisent les données structurées pour mieux comprendre et extraire des informations des pages web. JSON-LD fournit un contexte lisible par machine qui aide ces systèmes d’IA à identifier les entités clés, les relations et les types de contenu, augmentant ainsi la probabilité que votre contenu soit cité et mis en avant dans les réponses générées par l’IA.
Les propriétés clés de JSON-LD incluent @context (définit le vocabulaire), @type (spécifie le type de schéma comme Product ou Article), @id (identifiant unique pour l’entité) et des propriétés personnalisées en fonction du type de schéma. Pour un schéma Product, vous pouvez inclure name, description, price, image et aggregateRating. Chaque propriété correspond aux définitions de schema.org, permettant aux moteurs de recherche d’extraire et de comprendre des informations spécifiques sur votre contenu.
L’adoption de JSON-LD a considérablement augmenté, atteignant 41 % de tous les sites web en 2024, contre 34 % en 2022. Parmi les sites utilisant un balisage de données structurées, JSON-LD est le format le plus largement adopté, utilisé par environ 70 % des sites avec données structurées. Cette croissance reflète la recommandation de Google de privilégier JSON-LD et sa facilité de mise en œuvre par rapport à des formats alternatifs comme Microdata et RDFa.
JSON-LD offre plusieurs avantages sur RDFa : il est plus facile à mettre en œuvre et à maintenir, ne nécessite pas d’être entremêlé avec le contenu HTML, fonctionne parfaitement avec le contenu généré par JavaScript, et est moins sujet aux erreurs. Bien que RDFa permette de combiner plusieurs vocabulaires pour des besoins complexes, la simplicité de JSON-LD et la recommandation explicite de Google en font le choix privilégié pour la plupart des sites souhaitant mettre en œuvre des données structurées pour la visibilité en recherche et la découvrabilité par l’IA.
Commencez à suivre comment les chatbots IA mentionnent votre marque sur ChatGPT, Perplexity et d'autres plateformes. Obtenez des informations exploitables pour améliorer votre présence IA.
Découvrez ce qu’est JSON-LD et comment l’implémenter pour le SEO. Découvrez les avantages du balisage structuré pour Google, ChatGPT, Perplexity et la visibilit...
Discussion communautaire sur la mise en œuvre de JSON-LD pour la visibilité dans la recherche IA. Les développeurs et experts SEO partagent comment les données ...
Découvrez comment mettre en œuvre le balisage du schéma Organization pour la visibilité IA. Guide étape par étape pour ajouter des données structurées JSON-LD, ...