
Qu'est-ce que MUM et comment cela affecte la recherche par IA ?
Découvrez le Multitask Unified Model (MUM) de Google et son impact sur les résultats de recherche IA. Comprenez comment MUM traite des requêtes complexes à trav...
10 min de lecture
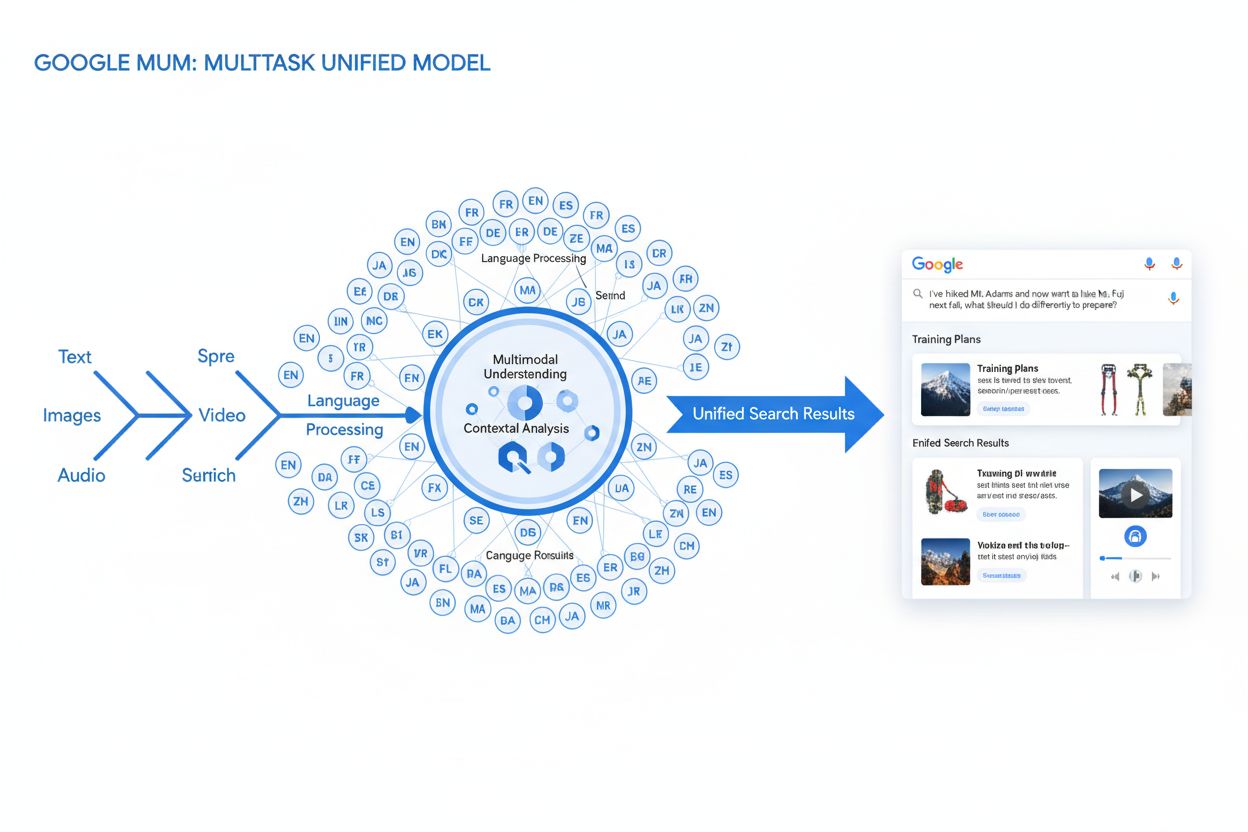
MUM (Modèle Unifié Multitâche) est le modèle d’IA multimodal avancé de Google qui traite simultanément le texte, les images, la vidéo et l’audio dans plus de 75 langues afin de fournir des résultats de recherche plus complets et contextuels. Lancé en 2021, MUM est 1 000 fois plus puissant que BERT et représente un changement fondamental dans la façon dont les moteurs de recherche comprennent et répondent aux requêtes complexes des utilisateurs.
MUM (Modèle Unifié Multitâche) est le modèle d'IA multimodal avancé de Google qui traite simultanément le texte, les images, la vidéo et l'audio dans plus de 75 langues afin de fournir des résultats de recherche plus complets et contextuels. Lancé en 2021, MUM est 1 000 fois plus puissant que BERT et représente un changement fondamental dans la façon dont les moteurs de recherche comprennent et répondent aux requêtes complexes des utilisateurs.
MUM (Modèle Unifié Multitâche) est le modèle d’intelligence artificielle multimodal avancé de Google conçu pour révolutionner la manière dont les moteurs de recherche comprennent et répondent aux requêtes complexes des utilisateurs. Annoncé en mai 2021 par Pandu Nayak, Google Fellow et Vice-président de la Recherche, MUM représente un changement fondamental dans la technologie de recherche d’information. Construit sur le framework T5 text-to-text et comprenant environ 110 milliards de paramètres, MUM est 1 000 fois plus puissant que BERT, le précédent modèle de traitement du langage naturel révolutionnaire de Google. Contrairement aux algorithmes de recherche traditionnels qui traitent le texte isolément, MUM traite simultanément le texte, les images, la vidéo et l’audio tout en comprenant l’information dans plus de 75 langues nativement. Cette capacité multimodale et multilingue permet à MUM de comprendre des requêtes complexes qui nécessitaient autrefois plusieurs recherches, transformant la recherche d’un simple exercice de correspondance de mots-clés en un système intelligent et contextuel de récupération d’informations. MUM ne se contente pas de comprendre le langage, il le génère également, ce qui lui permet de synthétiser des informations provenant de sources et formats divers afin de fournir des réponses complètes et nuancées qui répondent pleinement à l’intention de l’utilisateur.
Le parcours de Google vers MUM représente des années d’innovation incrémentale dans le traitement du langage naturel et l’apprentissage automatique. L’évolution a commencé avec Hummingbird (2013), qui a introduit la compréhension sémantique pour interpréter le sens des requêtes plutôt que de simplement faire correspondre des mots-clés. Cela a été suivi par RankBrain (2015), qui utilisait l’apprentissage machine pour comprendre les mots-clés longue traîne et les nouveaux schémas de recherche. Neural Matching (2018) a poussé l’innovation plus loin en utilisant des réseaux neuronaux pour associer des requêtes à du contenu pertinent à un niveau sémantique plus profond. BERT (Bidirectional Encoder Representations from Transformers), lancé en 2019, a marqué une étape majeure en comprenant le contexte au sein des phrases et des paragraphes, améliorant la capacité de Google à interpréter la langue nuancée. Cependant, BERT présentait des limitations importantes : il ne traitait que le texte, avait un support multilingue limité et ne pouvait gérer la complexité des requêtes nécessitant une synthèse d’informations sur plusieurs formats. Selon les recherches de Google, les utilisateurs émettent en moyenne huit requêtes distinctes pour répondre à des questions complexes, comme comparer deux destinations de randonnée ou évaluer des options de produits. Cette statistique a mis en évidence une lacune critique que MUM a été spécialement conçu pour combler. L’Helpful Content Update (2022) et le cadre E-E-A-T (2023) ont affiné la manière dont Google privilégie les contenus faisant autorité et dignes de confiance. MUM s’appuie sur toutes ces innovations tout en introduisant des capacités qui transcendent les limites antérieures, représentant non pas une amélioration incrémentale mais un changement de paradigme dans la façon dont les moteurs de recherche traitent et délivrent l’information.
La base technique de MUM repose sur l’architecture Transformer, en particulier le framework T5 (Text-to-Text Transfer Transformer) que Google a développé précédemment. Le framework T5 traite toutes les tâches de traitement du langage naturel comme des problèmes text-to-text, convertissant les entrées et sorties en représentations textuelles unifiées. MUM étend cette approche en intégrant des capacités de traitement multimodal, lui permettant de gérer simultanément le texte, les images, la vidéo et l’audio dans un seul modèle unifié. Ce choix architectural est significatif car il permet à MUM de comprendre les relations et le contexte entre différents types de médias, ce que les modèles précédents ne pouvaient pas faire. Par exemple, lorsqu’il traite une requête sur la randonnée au Mont Fuji accompagnée d’une image de chaussures de randonnée spécifiques, MUM n’analyse pas séparément le texte et l’image—il les traite ensemble, comprenant comment les caractéristiques des chaussures se rapportent au contexte de la requête. Les 110 milliards de paramètres du modèle lui permettent de stocker et de traiter d’énormes quantités de connaissances sur le langage, les concepts visuels et leurs relations. MUM est entraîné sur 75 langues différentes et de nombreuses tâches en même temps, ce qui lui permet de développer une compréhension plus complète de l’information et des connaissances mondiales que les modèles entraînés sur une seule langue ou une seule tâche. Cette approche d’apprentissage multitâche signifie que MUM apprend à reconnaître des schémas et des relations qui se transfèrent entre les langues et les domaines, le rendant plus robuste et généralisable que les modèles précédents. Le traitement simultané de plusieurs langues pendant l’entraînement permet à MUM de réaliser un transfert de connaissances entre les langues, c’est-à-dire qu’il peut comprendre une information écrite dans une langue et appliquer cette compréhension à des requêtes dans une autre, supprimant ainsi les barrières linguistiques qui limitaient jusque-là les résultats de recherche.
| Attribut | MUM (2021) | BERT (2019) | RankBrain (2015) | Framework T5 |
|---|---|---|---|---|
| Fonction principale | Compréhension multimodale des requêtes et synthèse de réponses | Compréhension contextuelle basée sur le texte | Interprétation des mots-clés longue traîne | Apprentissage text-to-text |
| Modalités d’entrée | Texte, images, vidéo, audio | Texte uniquement | Texte uniquement | Texte uniquement |
| Support linguistique | Plus de 75 langues nativement | Support multilingue limité | Principalement anglais | Principalement anglais |
| Paramètres du modèle | ~110 milliards | ~340 millions | Non divulgué | ~220 millions |
| Comparaison de puissance | 1 000x plus puissant que BERT | Référence de base | Prédécesseur de BERT | Fondation pour MUM |
| Capacités | Compréhension + génération | Compréhension uniquement | Reconnaissance de schémas | Transformation textuelle |
| Impact sur la SERP | Résultats enrichis multiformats | Meilleurs extraits et contexte | Pertinence accrue | Technologie de fondation |
| Gestion de la complexité des requêtes | Requêtes complexes multi-étapes | Contexte de requête unique | Variantes longue traîne | Tâches de transformation textuelle |
| Transfert de connaissances | Inter-langues et inter-modalités | Uniquement dans la langue | Transfert limité | Transfert inter-tâches |
| Applications concrètes | Recherche Google, AI Overviews | Classement recherche Google | Classement recherche Google | Base technique de MUM |
Le traitement des requêtes par MUM implique plusieurs étapes sophistiquées qui fonctionnent ensemble pour fournir des réponses complètes et contextuelles. Lorsqu’un utilisateur soumet une requête de recherche, MUM commence par effectuer un prétraitement indépendant de la langue, comprenant la requête dans l’une de ses plus de 75 langues supportées sans nécessiter de traduction. Cette compréhension native conserve les nuances linguistiques et le contexte régional qui pourraient être perdus lors d’une traduction. Ensuite, MUM utilise un appairage séquence-à-séquence, analysant toute la requête comme une séquence de sens plutôt que comme des mots-clés isolés. Cette approche permet à MUM de comprendre les relations entre les concepts—par exemple, reconnaître qu’une requête sur « se préparer pour le Mont Fuji après avoir gravi le Mont Adams » implique une comparaison, une préparation et une adaptation contextuelle. Simultanément, MUM effectue une analyse d’entrée multimodale, traitant toute image, vidéo ou autre média inclus dans la requête. Le modèle procède alors à un traitement simultané de la requête, évaluant plusieurs intentions utilisateur possibles en parallèle au lieu de se limiter à une seule interprétation. Cela signifie que MUM peut reconnaître qu’une requête sur la randonnée au Mont Fuji peut concerner la préparation physique, le choix de l’équipement, les expériences culturelles ou la logistique du voyage—et il affiche des informations pertinentes pour toutes ces interprétations. La compréhension sémantique vectorielle convertit la requête et le contenu indexé en vecteurs de grande dimension représentant le sens sémantique, permettant la récupération basée sur la similarité conceptuelle plutôt que la correspondance de mots-clés. MUM applique ensuite un filtrage du contenu via transfert de connaissances, utilisant l’apprentissage machine basé sur les historiques de recherche, les données de navigation et les comportements des utilisateurs pour privilégier les sources de qualité et faisant autorité. Enfin, MUM génère une composition de SERP enrichie en multimédia, combinant extraits textuels, images, vidéos, questions connexes et éléments interactifs dans une expérience de recherche visuellement stratifiée. Ce processus complet s’effectue en millisecondes, permettant à MUM de fournir des résultats qui répondent non seulement à la requête explicite mais aussi aux questions de suivi anticipées et aux besoins d’information connexes.
Les capacités multimodales de MUM représentent une rupture fondamentale avec les systèmes de recherche textuels classiques. Le modèle peut traiter et comprendre simultanément des informations issues du texte, d’images, de vidéos et d’audio, en extrayant le sens de chaque modalité pour le synthétiser dans des réponses cohérentes. Cette capacité est particulièrement puissante pour les requêtes qui bénéficient d’un contexte visuel. Par exemple, si un utilisateur demande « Puis-je utiliser ces chaussures de randonnée pour le Mont Fuji ? » en affichant une image de ses chaussures, MUM comprend les caractéristiques de la chaussure à partir de l’image—matériau, motif de semelle, hauteur, couleur—et relie cette compréhension visuelle aux connaissances sur le terrain, le climat et les exigences de randonnée du Mont Fuji pour fournir une réponse contextuelle. La dimension multilingue de MUM est tout aussi transformatrice. Avec un support natif pour plus de 75 langues, MUM peut effectuer un transfert de connaissances entre les langues, c’est-à-dire apprendre à partir de sources dans une langue et appliquer ce savoir à des requêtes dans une autre. Cela fait tomber une barrière majeure qui limitait auparavant les résultats de recherche au contenu dans la langue de l’utilisateur. Si des informations complètes sur le Mont Fuji existent principalement en japonais—guides de randonnée locaux, météo saisonnière, conseils culturels—MUM peut comprendre ces contenus japonais et afficher des informations pertinentes aux utilisateurs anglophones. Selon les tests de Google, MUM a pu lister 800 variantes de vaccins COVID-19 dans plus de 50 langues en quelques secondes, démontrant l’échelle et la rapidité de ses capacités multilingues. Cette compréhension multilingue est particulièrement précieuse pour les utilisateurs des marchés non anglophones et pour les requêtes sur des sujets riches en informations dans plusieurs langues. L’association du traitement multimodal et multilingue permet à MUM d’afficher l’information la plus pertinente, quel que soit son format ou sa langue d’origine, créant ainsi une expérience de recherche véritablement mondiale.
MUM transforme fondamentalement la façon dont les résultats de recherche sont affichés et vécus par les utilisateurs. Plutôt que la traditionnelle liste de liens bleus qui a dominé la recherche pendant des décennies, MUM crée des SERP enrichies et interactives combinant plusieurs formats de contenu sur une seule page. Les utilisateurs peuvent désormais voir des extraits de texte, des images haute résolution, des carrousels vidéo, des questions associées et des éléments interactifs sans quitter la page de résultats. Ce changement a des implications profondes sur la façon dont les utilisateurs interagissent avec la recherche. Au lieu d’effectuer plusieurs recherches pour rassembler des informations sur un sujet complexe, les utilisateurs peuvent explorer différentes facettes et sous-thèmes directement depuis la SERP. Par exemple, une requête sur « se préparer pour le Mont Fuji en automne » peut afficher des comparaisons d’altitude, des prévisions météo, des recommandations d’équipement, des guides vidéo et des avis utilisateurs—le tout organisé contextuellement sur une page. L’intégration de Google Lens alimentée par MUM permet de rechercher à partir d’images plutôt que de mots-clés, transformant les éléments visuels des photos en outils de découverte interactifs. Les panneaux « À savoir » décomposent les requêtes complexes en sous-thèmes digestes, guidant les utilisateurs à travers les différents aspects d’un sujet avec des extraits pertinents pour chacun. Des images zoomables haute résolution apparaissent directement dans les résultats, facilitant la comparaison visuelle et réduisant la friction dans les étapes de décision précoce. La fonctionnalité « Affiner et élargir » suggère des concepts connexes pour aider les utilisateurs à approfondir ou explorer des sujets adjacents. Ces changements marquent une transition de la recherche comme simple mécanisme de récupération vers une expérience interactive et exploratoire anticipant les besoins de l’utilisateur et fournissant une information complète dans l’interface de recherche elle-même. Les recherches montrent que cette expérience SERP enrichie réduit le nombre moyen de recherches nécessaires pour répondre à des questions complexes, mais cela signifie aussi que les utilisateurs peuvent consommer l’information directement sans cliquer sur les sites web.
Pour les organisations qui surveillent leur présence dans les systèmes d’IA, MUM représente une évolution clé dans la découverte et la mise en avant de l’information. À mesure que MUM s’intègre de plus en plus dans la Recherche Google et influence d’autres systèmes d’IA, comprendre comment les marques et domaines apparaissent dans les résultats pilotés par MUM devient essentiel pour maintenir leur visibilité. Le traitement multimodal de MUM signifie que les marques doivent optimiser leurs contenus dans plusieurs formats, pas seulement le texte. Une marque auparavant positionnée sur des mots-clés spécifiques doit désormais s’assurer que son contenu est découvrable via des images, des vidéos et des données structurées. La capacité du modèle à synthétiser l’information provenant de sources diverses signifie que la visibilité d’une marque dépend non seulement de son propre site web mais aussi de la façon dont son information circule sur l’ensemble du web. Les capacités multilingues de MUM créent de nouvelles opportunités et défis pour les marques mondiales. Un contenu publié dans une langue peut désormais être découvert par des utilisateurs recherchant dans d’autres langues, élargissant la portée potentielle. Cependant, cela signifie aussi que les marques doivent garantir l’exactitude et la cohérence de leurs informations dans toutes les langues, puisque MUM peut afficher des informations de plusieurs sources linguistiques pour une même requête. Pour les plateformes de surveillance de l’IA comme AmICited, suivre l’impact de MUM est crucial car il reflète la manière dont les systèmes d’IA modernes récupèrent et présentent l’information. Lorsqu’on surveille où une marque apparaît dans les réponses de l’IA—que ce soit dans Google AI Overviews, Perplexity, ChatGPT ou Claude—comprendre la technologie sous-jacente de MUM aide à expliquer pourquoi certains contenus sont affichés et comment optimiser leur visibilité. Le passage à une recherche multimodale et multilingue requiert une surveillance globale, qui suit la présence des marques à travers différents formats et langues, et pas seulement le positionnement sur des mots-clés traditionnels. Les organisations qui comprennent les capacités de MUM pourront mieux optimiser leur stratégie de contenu pour assurer leur visibilité dans ce nouveau paysage de recherche.
Bien que MUM représente une avancée majeure, il introduit aussi de nouveaux défis et limitations que les organisations doivent anticiper. La baisse des taux de clics constitue une préoccupation majeure pour les éditeurs et créateurs de contenu, puisque les utilisateurs peuvent désormais consommer l’information complète directement dans les résultats de recherche sans cliquer sur les sites. Ce changement rend les métriques de trafic traditionnelles moins fiables pour mesurer le succès du contenu. Des exigences techniques SEO accrues font qu’un contenu doit être bien structuré avec un balisage schema approprié, du HTML sémantique et des relations d’entités claires pour être correctement compris par MUM. Un contenu dépourvu de cette base technique risque de ne pas être correctement indexé ou compris par le traitement multimodal de MUM. La saturation des SERP crée des défis pour la visibilité, car plus de formats de contenu se disputent l’attention sur une même page. Même un contenu de qualité peut générer moins ou pas de clics si l’utilisateur trouve l’information suffisante dans la SERP. Le risque de résultats trompeurs existe lorsque MUM affiche des informations provenant de sources multiples qui peuvent se contredire ou lorsque le contexte est perdu lors de la synthèse. La dépendance aux données structurées signifie que les contenus non structurés ou mal formatés risquent de ne pas être compris ni affichés par MUM. Les défis liés à la nuance linguistique et culturelle peuvent apparaître lorsque MUM transfère des connaissances entre langues, pouvant manquer le contexte culturel ou les variations régionales de sens. Les ressources informatiques nécessaires pour exécuter MUM à grande échelle sont considérables, bien que Google ait investi dans des améliorations d’efficacité pour réduire l’empreinte carbone. Les questions de biais et d’équité nécessitent une attention continue pour éviter que MUM ne perpétue les biais présents dans les données d’entraînement ou ne défavorise certains points de vue ou communautés.
L’émergence de MUM impose des changements fondamentaux dans l’approche SEO et de contenu des organisations. L’optimisation traditionnelle axée sur les mots-clés devient moins efficace lorsque MUM peut comprendre l’intention et le contexte au-delà des correspondances exactes. La stratégie de contenu basée sur les sujets devient plus importante que la stratégie basée sur les mots-clés, les organisations devant créer des clusters de contenus complets abordant les sujets sous plusieurs angles. La création de contenu multimédia n’est plus optionnelle : il faut investir dans des images, vidéos et contenus interactifs de haute qualité pour compléter le contenu textuel. La mise en œuvre des données structurées devient cruciale, car le balisage schema aide MUM à comprendre la structure et les relations du contenu. La construction d’entités et l’optimisation sémantique permettent d’établir une autorité thématique et d’améliorer la compréhension des relations de contenu par MUM. La stratégie de contenu multilingue prend de l’importance puisque les capacités de transfert linguistique de MUM permettent la découverte du contenu sur plusieurs marchés linguistiques. La cartographie de l’intention utilisateur devient plus sophistiquée, les organisations devant anticiper non seulement l’intention principale mais aussi les questions connexes et les sous-thèmes explorés par les utilisateurs. La fraîcheur et l’exactitude du contenu gagnent en importance, puisque MUM synthétise l’information de sources multiples : les contenus obsolètes ou inexacts risquent d’être dépriorisés. L’optimisation cross-plateforme s’étend au-delà de la Recherche Google pour inclure la façon dont le contenu apparaît dans les systèmes d’IA comme Google AI Overviews, Perplexity et autres interfaces de recherche pilotées par l’IA. Les signaux E-E-A-T (Expérience, Expertise, Autorité, Fiabilité) deviennent de plus en plus importants à mesure que MUM privilégie les contenus provenant de sources autorisées. Les organisations qui adaptent leur stratégie pour l’aligner sur les capacités de MUM—en se concentrant sur des contenus complets, multimodaux, bien structurés et démontrant expertise et autorité—maintiendront leur visibilité dans ce paysage de recherche en constante évolution.
MUM n’est pas une destination finale mais une étape dans l’évolution de la recherche pilotée par l’IA. Google a indiqué que MUM continuera d’étendre ses capacités, avec un traitement vidéo et audio de plus en plus sophistiqué. L’entreprise mène activement des recherches pour réduire l’empreinte computationnelle de MUM tout en maintenant, voire en améliorant ses performances, répondant ainsi aux préoccupations de durabilité liées aux modèles d’IA à grande échelle. L’intégration de MUM avec d’autres technologies Google suggère des développements futurs où la compréhension de MUM alimentera non seulement la recherche, mais aussi Google Assistant, Google Lens et d’autres produits. La pression concurrentielle d’autres systèmes d’IA comme ChatGPT d’OpenAI, Claude d’Anthropic et le moteur de recherche IA de Perplexity implique que MUM continuera probablement d’évoluer pour maintenir l’avantage concurrentiel de Google. L’attention réglementaire sur les systèmes d’IA pourrait influencer le développement de MUM, notamment sur les questions de biais, d’équité et de transparence. L’adaptation du comportement utilisateur façonnera l’évolution de MUM : à mesure que les utilisateurs s’habituent à des expériences de recherche plus riches et interactives, leurs attentes concernant la qualité et la complétude des résultats augmenteront. La montée de l’IA générative signifie que les capacités de synthèse et de génération d’information de MUM deviendront probablement plus visibles, permettant éventuellement à MUM de générer du contenu original plutôt que de simplement organiser des contenus existants. L’IA multimodale comme standard laisse penser que l’approche de MUM—traiter plusieurs formats simultanément—deviendra la norme dans l’ensemble des systèmes d’IA. Les considérations de confidentialité et de données influenceront la façon dont MUM utilise les données et signaux comportementaux pour personnaliser et améliorer les résultats. Les organisations doivent anticiper cette évolution continue en construisant des stratégies de contenu flexibles et adaptables, axées sur la qualité, la complétude et l’excellence technique plutôt que sur des tactiques spécifiques qui pourraient devenir obsolètes au fur et à mesure de l’évolution de MUM. Le principe fondamental—créer du contenu qui répond réellement à l’intention utilisateur à travers plusieurs formats et langues—restera pertinent quelle que soit l’évolution des capacités spécifiques de MUM.
Alors que BERT (2019) se concentrait sur la compréhension du langage naturel dans les requêtes textuelles, MUM représente une évolution significative. MUM est construit sur le framework T5 text-to-text et est 1 000 fois plus puissant que BERT. Contrairement au traitement textuel unique de BERT, MUM est multimodal : il traite simultanément le texte, les images, la vidéo et l'audio. De plus, MUM prend en charge plus de 75 langues nativement, tandis que BERT avait un support multilingue limité lors de son lancement. MUM peut à la fois comprendre et générer du langage, ce qui le rend capable de gérer des requêtes complexes et multi-étapes que BERT ne pouvait pas traiter efficacement.
Multimodal fait référence à la capacité de MUM à traiter et comprendre des informations provenant simultanément de plusieurs types de formats d'entrée. Plutôt qu'analyser séparément le texte des images ou de la vidéo, MUM traite tous ces formats ensemble de manière unifiée. Cela signifie que lorsque vous recherchez quelque chose comme « chaussures de randonnée pour le Mont Fuji », MUM peut comprendre votre requête textuelle, analyser des images de chaussures, regarder des avis vidéo et extraire des descriptions audio—le tout en même temps. Cette approche intégrée permet à MUM de fournir des réponses plus riches et contextuelles tenant compte des informations issues de tous ces types de médias différents.
MUM est entraîné sur plus de 75 langues, ce qui constitue une avancée majeure pour l'accessibilité de la recherche à l'échelle mondiale. Cette capacité multilingue signifie que MUM peut transférer des connaissances entre les langues : si des informations utiles sur un sujet existent en japonais, MUM peut les comprendre et afficher des résultats pertinents aux utilisateurs anglophones. Cela supprime les barrières linguistiques qui limitaient auparavant les résultats aux contenus dans la langue maternelle de l'utilisateur. Pour les marques et les créateurs de contenu, cela signifie que leur contenu peut être visible sur plusieurs marchés linguistiques, et que les utilisateurs du monde entier peuvent accéder à l'information, quelle que soit la langue d'origine de sa publication.
T5 (Text-to-Text Transfer Transformer) est le modèle basé sur des transformeurs développé par Google et sur lequel MUM repose. Le framework T5 traite toutes les tâches de NLP comme des problèmes text-to-text, c'est-à-dire qu'il convertit les entrées et sorties en format texte pour un traitement unifié. MUM étend les capacités de T5 en intégrant le traitement multimodal (gestion des images, des vidéos et de l'audio) et en le faisant évoluer à environ 110 milliards de paramètres. Cette base permet à MUM de comprendre et de générer du langage tout en conservant l'efficacité et la flexibilité qui ont fait le succès de T5.
MUM change fondamentalement la manière dont le contenu est découvert et affiché dans les résultats de recherche. Au lieu de simples listes de liens bleus, MUM crée des SERP enrichies avec plusieurs formats de contenu—images, vidéos, extraits de texte et éléments interactifs—sur une seule page. Cela signifie que les marques doivent optimiser leurs contenus dans plusieurs formats, pas seulement le texte. Un contenu qui nécessitait auparavant plusieurs clics peut désormais apparaître directement dans les résultats de recherche. Cependant, cela peut aussi entraîner un taux de clics plus faible pour certains contenus, car les utilisateurs peuvent consommer l'information directement dans le SERP. Les marques doivent donc se concentrer sur la visibilité dans les résultats et s'assurer que leur contenu est structuré avec du balisage schema pour être correctement compris par MUM.
MUM est essentiel pour les plateformes de surveillance de l'IA car il illustre la façon dont les systèmes d'IA modernes comprennent et récupèrent l'information. À mesure que MUM devient plus présent dans la Recherche Google et influence d'autres systèmes d'IA, il devient crucial de surveiller où les marques et domaines apparaissent dans les résultats pilotés par MUM. AmICited suit la façon dont les marques sont citées et apparaissent dans les systèmes d'IA, y compris la recherche enrichie par MUM de Google. Comprendre les capacités multimodales et multilingues de MUM aide les organisations à optimiser leur présence dans différents formats et langues, en garantissant leur visibilité lorsque des systèmes d'IA comme MUM récupèrent et affichent leur information aux utilisateurs.
Oui, MUM peut traiter les images et les vidéos avec une compréhension sophistiquée. Lorsque vous téléchargez une image ou intégrez une vidéo dans une requête, MUM ne se contente pas de reconnaître des objets : il extrait le contexte, la signification et les relations. Par exemple, si vous montrez à MUM une photo de chaussures de randonnée et demandez « puis-je utiliser celles-ci pour le Mont Fuji ? », MUM comprend les caractéristiques des chaussures à partir de l'image et relie cette compréhension à votre question pour fournir une réponse contextuelle. Cette compréhension multimodale est l'une des fonctionnalités les plus puissantes de MUM, lui permettant de répondre à des questions nécessitant une compréhension visuelle combinée à des connaissances textuelles.
Commencez à suivre comment les chatbots IA mentionnent votre marque sur ChatGPT, Perplexity et d'autres plateformes. Obtenez des informations exploitables pour améliorer votre présence IA.
Découvrez le Multitask Unified Model (MUM) de Google et son impact sur les résultats de recherche IA. Comprenez comment MUM traite des requêtes complexes à trav...
Discussion communautaire expliquant Google MUM et son impact sur la recherche IA. Des experts partagent comment ce modèle d’IA multimodal affecte l’optimisation...

Découvrez comment les systèmes de recherche IA multimodale traitent ensemble texte, images, audio et vidéo pour fournir des résultats plus précis et contextuell...