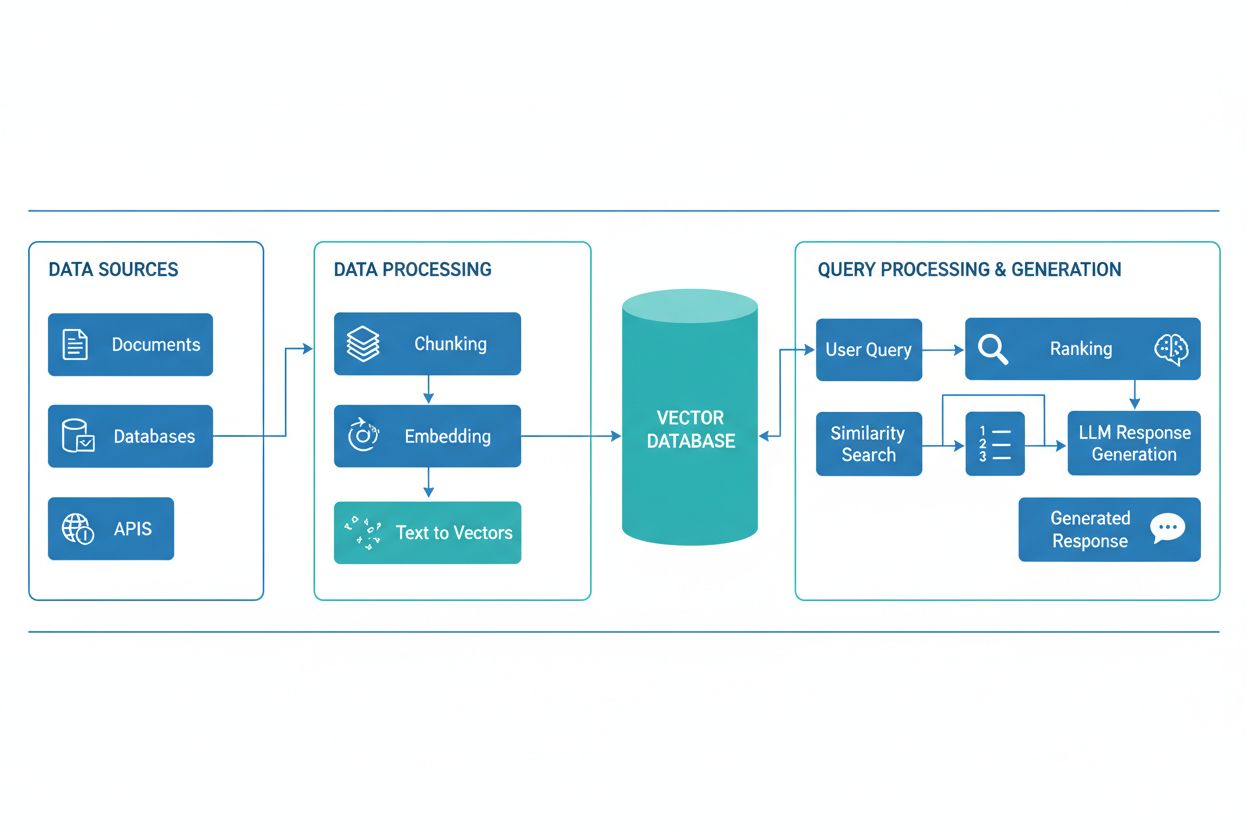
Un pipeline de génération augmentée par la récupération (RAG) est un flux de travail permettant aux systèmes d’IA de trouver, classer et citer des sources externes lors de la génération de réponses. Il combine la récupération de documents, le classement sémantique et la génération LLM pour fournir des réponses précises et contextuellement pertinentes, fondées sur des données réelles. Les systèmes RAG réduisent les hallucinations en consultant des bases de connaissances externes avant de produire des réponses, ce qui les rend essentiels pour les applications nécessitant une précision factuelle et une attribution des sources.
Pipeline RAG
Un pipeline de génération augmentée par la récupération (RAG) est un flux de travail permettant aux systèmes d’IA de trouver, classer et citer des sources externes lors de la génération de réponses. Il combine la récupération de documents, le classement sémantique et la génération LLM pour fournir des réponses précises et contextuellement pertinentes, fondées sur des données réelles. Les systèmes RAG réduisent les hallucinations en consultant des bases de connaissances externes avant de produire des réponses, ce qui les rend essentiels pour les applications nécessitant une précision factuelle et une attribution des sources.
Qu’est-ce qu’un pipeline RAG ?
Un pipeline de génération augmentée par la récupération (RAG) est une architecture d’IA qui combine la récupération d’informations avec la génération par grands modèles de langage (LLM) pour produire des réponses plus précises, contextuellement pertinentes et vérifiables. Plutôt que de s’appuyer uniquement sur les données d’entraînement du LLM, les systèmes RAG vont dynamiquement chercher des documents ou des données pertinentes dans des bases de connaissances externes avant de générer des réponses, réduisant significativement les hallucinations et améliorant la précision factuelle. Le pipeline agit comme un pont entre les données d’entraînement statiques et l’information en temps réel, permettant aux systèmes d’IA de référencer du contenu actuel, spécifique à un domaine ou propriétaire. Cette approche est devenue essentielle pour les organisations nécessitant des réponses sourcées, la conformité à des normes de précision et la transparence dans le contenu généré par l’IA. Les pipelines RAG sont particulièrement précieux pour la surveillance des systèmes d’IA où la traçabilité et l’attribution des sources sont des exigences critiques.
Composants principaux
Un pipeline RAG se compose de plusieurs éléments interconnectés qui travaillent ensemble pour récupérer des informations pertinentes et générer des réponses fondées. L’architecture comprend généralement une couche d’ingestion de documents qui traite et prépare les données brutes, une base de données vectorielle ou base de connaissances qui stocke les embeddings et le contenu indexé, un mécanisme de récupération qui identifie les documents pertinents selon les requêtes des utilisateurs, un système de classement qui priorise les résultats les plus pertinents, et un module de génération alimenté par un LLM qui synthétise les informations récupérées en réponses cohérentes. Des composants additionnels incluent des modules de traitement et de prétraitement des requêtes qui normalisent l’entrée utilisateur, des modèles d’embedding qui convertissent le texte en représentations numériques, et une boucle de rétroaction qui améliore continuellement la précision de la récupération. L’orchestration de ces composants détermine l’efficacité et la performance globale du système RAG.
Composant
Fonction
Technologies clés
Ingestion de documents
Traitement et préparation des données brutes
Apache Kafka, LangChain, Unstructured
Base de données vectorielle
Stockage des embeddings et du contenu indexé
Pinecone, Weaviate, Milvus, Qdrant
Moteur de récupération
Identification des documents pertinents
BM25, Dense Passage Retrieval (DPR)
Système de classement
Priorisation des résultats de recherche
Cross-encoders, reranking LLM
Module de génération
Synthèse des réponses à partir du contexte
GPT-4, Claude, Llama, Mistral
Processeur de requête
Normalisation et compréhension de l’entrée utilisateur
BERT, T5, pipelines NLP personnalisés
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Le pipeline RAG fonctionne selon deux phases distinctes : la phase de récupération et la phase de génération. Pendant la phase de récupération, le système convertit la requête de l’utilisateur en embedding à l’aide du même modèle d’embedding ayant traité les documents de la base de connaissances, puis interroge la base de données vectorielle pour identifier les documents ou passages les plus proches sémantiquement. Cette phase retourne généralement une liste classée de documents candidats, qui peut être affinée par des algorithmes de reranking utilisant des cross-encoders ou des scores produits par des LLM pour garantir la pertinence. Lors de la phase de génération, les documents les mieux classés sont formatés dans une fenêtre de contexte et transmis au LLM avec la requête d’origine, permettant au modèle de générer des réponses fondées sur des sources réelles. Cette approche en deux phases garantit que les réponses sont à la fois appropriées au contexte et traçables à des sources spécifiques, ce qui en fait une solution idéale pour les applications nécessitant citation et responsabilité. La qualité du résultat final dépend de manière critique à la fois de la pertinence des documents récupérés et de la capacité du LLM à synthétiser l’information de façon cohérente.
Technologies et outils clés
L’écosystème RAG englobe une large gamme d’outils et de frameworks spécialisés conçus pour simplifier la construction et le déploiement de pipelines. Les implémentations RAG modernes s’appuient sur plusieurs catégories technologiques :
Frameworks d’orchestration : LangChain, LlamaIndex (anciennement GPT Index) et Haystack offrent des couches d’abstraction pour construire des workflows RAG sans gérer chaque composant individuellement
Bases de données vectorielles : Pinecone, Weaviate, Milvus, Qdrant et Chroma proposent un stockage et une récupération évolutifs des embeddings à latence de requête inférieure à la milliseconde
Modèles d’embedding : text-embedding-3 d’OpenAI, l’API Embed de Cohere, et des modèles open source comme all-MiniLM-L6-v2 convertissent le texte en représentations sémantiques
Fournisseurs de LLM : OpenAI (GPT-4), Anthropic (Claude), Meta (Llama) et Mistral proposent différents modèles adaptés à la génération
Solutions de reranking : l’API Rerank de Cohere, les cross-encoders de Hugging Face et des rerankers LLM propriétaires améliorent la précision de la récupération
Outils de préparation des données : Unstructured, Apache Kafka, et des pipelines ETL personnalisés gèrent l’ingestion, le découpage et le prétraitement des documents
Supervision et évaluation : des outils comme Ragas, TruLens et des frameworks d’évaluation sur mesure permettent de mesurer la performance des systèmes RAG et d’identifier les modes d’échec
Ces outils peuvent être assemblés de manière modulaire, permettant aux organisations de construire des systèmes RAG adaptés à leurs besoins et contraintes d’infrastructure spécifiques.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Mécanismes de récupération
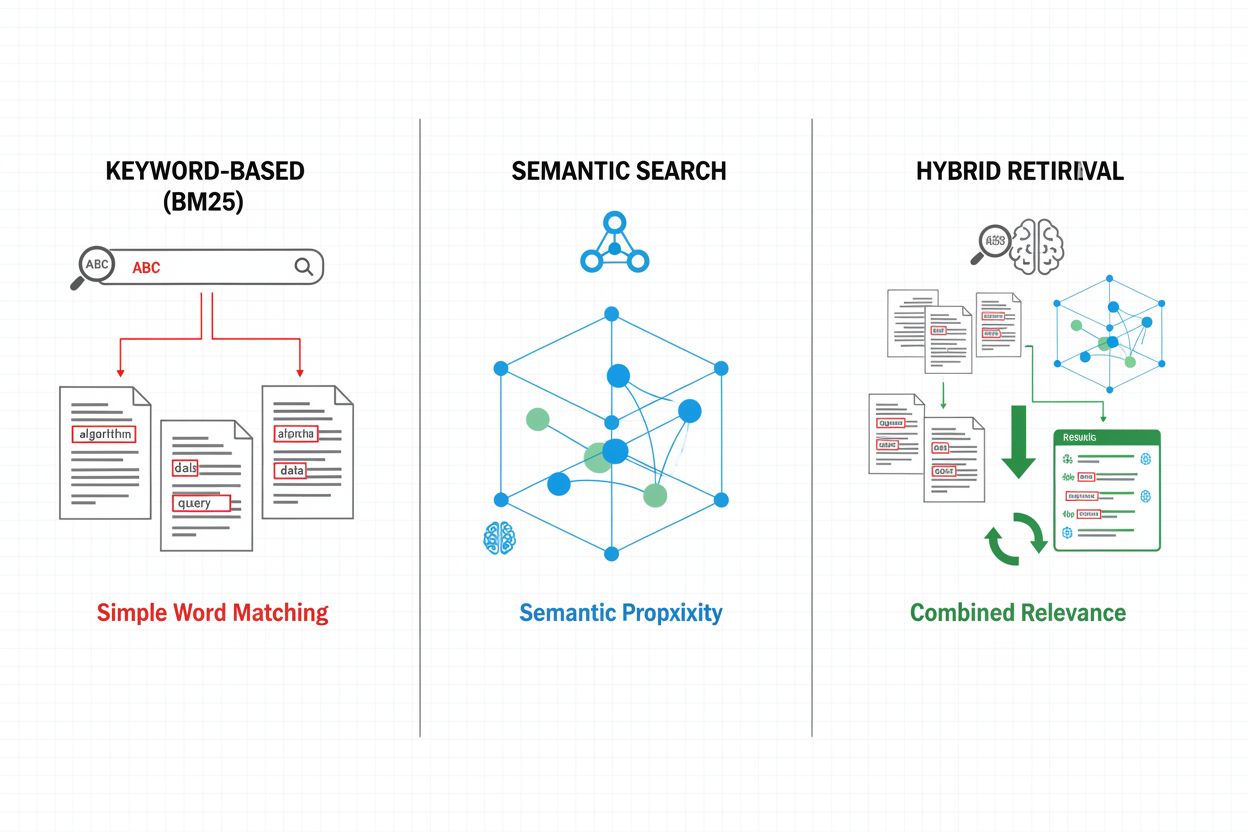
Les mécanismes de récupération forment la base de l’efficacité des pipelines RAG, évoluant d’approches simples basées sur les mots-clés vers des méthodes sophistiquées de recherche sémantique. La récupération traditionnelle par mots-clés utilisant l’algorithme BM25 reste efficace et efficiente pour les correspondances exactes, mais montre ses limites pour la compréhension sémantique et la synonymie. Dense Passage Retrieval (DPR) et d’autres méthodes neuronales pallient ces limites en encodant requêtes et documents en embeddings vectoriels denses, permettant des correspondances sémantiques dépassant la simple identification de mots. Les approches hybrides combinent récupération par mots-clés et recherche sémantique, tirant parti des forces de chaque méthode pour améliorer rappel et précision sur une variété de requêtes. Les mécanismes avancés intègrent l’expansion de requête, où la requête initiale est enrichie de termes associés ou reformulations pour identifier plus de documents pertinents. Les couches de reranking affinent encore les résultats en appliquant des modèles plus coûteux en calcul qui évaluent les documents candidats selon une compréhension sémantique plus profonde ou des critères de pertinence spécifiques à la tâche. Le choix du mécanisme de récupération impacte fortement à la fois la précision du contexte récupéré et le coût computationnel du pipeline RAG, imposant d’arbitrer entre rapidité et qualité.
Avantages des pipelines RAG
Les pipelines RAG offrent des avantages significatifs par rapport aux approches reposant uniquement sur les LLM, notamment pour les applications exigeant précision, actualité et traçabilité. En ancrant les réponses dans des documents récupérés, les systèmes RAG réduisent drastiquement les hallucinations—cas où les LLM produisent des réponses plausibles mais factuellement incorrectes—ce qui les rend adaptés aux domaines à enjeux élevés comme la santé, le juridique ou la finance. La capacité à référencer des bases de connaissances externes permet à RAG de fournir des informations actuelles sans devoir réentraîner les modèles, maintenant ainsi des réponses à jour à mesure que de nouvelles informations apparaissent. Les pipelines RAG offrent une personnalisation spécifique au domaine en intégrant des documents propriétaires, des bases de connaissances internes et une terminologie spécialisée, pour des réponses plus pertinentes et adaptées au contexte. La composante récupération fournit transparence et auditabilité en exposant explicitement les sources ayant informé chaque réponse, un aspect crucial pour répondre aux exigences de conformité et instaurer la confiance des utilisateurs. L’efficacité des coûts s’améliore grâce à l’utilisation de LLM plus petits et efficaces, capables de fournir des réponses de haute qualité lorsqu’ils disposent d’un contexte pertinent, réduisant ainsi la charge computationnelle par rapport à des modèles plus volumineux. Ces bénéfices rendent RAG particulièrement intéressant pour les organisations mettant en place des systèmes de surveillance de l’IA où la justesse des citations et la visibilité du contenu sont primordiales.
Défis et limites
Malgré leurs avantages, les pipelines RAG rencontrent plusieurs défis techniques et opérationnels nécessitant une gestion attentive. La qualité des documents récupérés détermine directement la qualité des réponses, rendant difficile la correction des erreurs de récupération—un phénomène connu sous le nom « garbage in, garbage out », où des documents non pertinents ou obsolètes dans la base de connaissances se propagent jusqu’aux réponses finales. Les modèles d’embedding peuvent avoir des difficultés avec la terminologie de niche, les langues rares ou le contenu très technique, menant à des appariements sémantiques faibles et à la perte de documents pertinents. Le coût computationnel de la récupération, de la génération des embeddings et du reranking peut être important à grande échelle, en particulier lors du traitement de grandes bases de connaissances ou de volumes élevés de requêtes. Les limitations de la fenêtre de contexte des LLM restreignent la quantité d’information récupérée pouvant être intégrée aux prompts, nécessitant une sélection et une synthèse minutieuses des passages pertinents. Le maintien de la fraîcheur et de la cohérence de la base de connaissances pose des défis opérationnels, notamment dans des environnements dynamiques où l’information évolue fréquemment ou provient de sources multiples. L’évaluation de la performance d’un système RAG requiert des métriques complètes allant au-delà de la simple précision, incluant la pertinence de la récupération, la pertinence des réponses et la justesse des citations, des aspects difficiles à évaluer automatiquement.
RAG vs autres approches
RAG représente l’une des stratégies existantes pour améliorer la précision et la pertinence des LLM, chacune présentant ses compromis. L’ajustement fin consiste à réentraîner les LLM sur des données spécifiques à un domaine, offrant une personnalisation poussée mais nécessitant des ressources de calcul importantes, des données d’entraînement annotées et une maintenance continue à mesure que l’information évolue. L’ingénierie de prompt optimise les instructions et le contexte fournis aux LLM sans modifier leurs paramètres, offrant flexibilité et faible coût mais limitée par les données d’entraînement du modèle et la taille de la fenêtre de contexte. L’apprentissage en contexte (in-context learning) s’appuie sur des exemples fournis dans les prompts pour guider le comportement du modèle, permettant une adaptation rapide mais consommant des tokens précieux et nécessitant une sélection minutieuse des exemples. Comparé à ces approches, RAG offre une solution intermédiaire : accès dynamique à l’information actuelle sans réentraînement, transparence via attribution explicite des sources, et passage à l’échelle efficace sur des domaines de connaissance variés. Cependant, RAG introduit de la complexité via l’infrastructure de récupération et le risque d’erreurs lors de la récupération, là où l’ajustement fin permet une intégration plus serrée des connaissances au sein du modèle. L’approche optimale combine souvent plusieurs stratégies—par exemple, en utilisant RAG avec des modèles ajustés finement et des prompts soigneusement conçus—pour maximiser la précision et la pertinence selon chaque cas d’usage.
Construction et déploiement d’un pipeline RAG
Mettre en œuvre un pipeline RAG en production nécessite une planification systématique couvrant la préparation des données, la conception de l’architecture et les aspects opérationnels. Le processus débute par la préparation de la base de connaissances : collecte des documents pertinents, nettoyage et standardisation des formats, et découpage du contenu en segments de taille appropriée pour équilibrer préservation du contexte et précision de la récupération. Ensuite, les organisations sélectionnent les modèles d’embedding et les bases de données vectorielles selon les exigences de performance, les contraintes de latence et la capacité à évoluer, en tenant compte de la dimensionnalité des embeddings, du débit de requête et de la capacité de stockage. Le système de récupération est alors configuré, comprenant le choix des algorithmes de récupération (par mots-clés, sémantique, ou hybride), des stratégies de reranking et des critères de filtrage des résultats. L’intégration avec les fournisseurs de LLM suit, établissant les connexions aux modèles de génération et définissant les templates de prompt qui intègrent efficacement le contexte récupéré. Les phases de test et d’évaluation sont cruciales, nécessitant des métriques de qualité de récupération (précision, rappel, MRR), de qualité de génération (pertinence, cohérence, factualité) et de performance globale du système. Le déploiement inclut la mise en place de la supervision de la précision de la récupération et de la qualité de génération, l’implémentation de boucles de feedback pour identifier et corriger les modes d’échec, et la définition de processus de mise à jour et de maintenance de la base de connaissances. Enfin, l’optimisation continue s’appuie sur l’analyse des interactions utilisateurs, l’identification des échecs fréquents, et l’amélioration itérative des mécanismes de récupération, des stratégies de reranking et de l’ingénierie des prompts pour renforcer la performance globale du système.
RAG pour la surveillance et la citation dans l’IA
Les pipelines RAG sont fondamentaux pour les plateformes modernes de surveillance de l’IA comme AmICited.com, où le suivi des sources et de la précision du contenu généré par l’IA est essentiel. En récupérant et en citant explicitement des documents sources, les systèmes RAG créent un historique vérifiable permettant aux plateformes de surveillance de vérifier les affirmations, d’évaluer la précision factuelle et d’identifier d’éventuelles hallucinations ou erreurs d’attribution. Cette capacité de citation répond à un besoin critique en transparence de l’IA : les utilisateurs et auditeurs peuvent remonter jusqu’aux sources originales, permettant une vérification indépendante et renforçant la confiance dans le contenu généré. Pour les créateurs de contenu et les organisations utilisant des outils d’IA, la surveillance via RAG apporte une visibilité sur les sources ayant informé chaque réponse, facilitant la conformité aux exigences d’attribution et aux politiques de gouvernance du contenu. La composante récupération des pipelines RAG génère des métadonnées riches—notamment les scores de pertinence, les classements de documents et les métriques de confiance de récupération—que les systèmes de surveillance peuvent analyser pour évaluer la fiabilité des réponses et détecter quand les systèmes d’IA opèrent hors de leur domaine de connaissance. L’intégration de RAG aux plateformes de surveillance permet de détecter la dérive des citations, où les systèmes d’IA s’éloignent progressivement des sources faisant autorité au profit de sources moins fiables, et de faire respecter des politiques de qualité et de diversité des sources. À mesure que les systèmes d’IA s’intègrent de plus en plus aux processus critiques, la combinaison des pipelines RAG et de la surveillance approfondie crée des mécanismes de responsabilité protégeant les utilisateurs, les organisations et l’écosystème informationnel contre la désinformation générée par l’IA.
Questions fréquemment posées
Quelle est la différence entre RAG et l’ajustement fin (fine-tuning) ?
RAG et l’ajustement fin sont des approches complémentaires pour améliorer les performances des LLM. RAG récupère des documents externes au moment de la requête sans modifier le modèle, permettant un accès aux données en temps réel et des mises à jour faciles. L’ajustement fin réentraîne le modèle sur des données spécifiques au domaine, offrant une personnalisation plus poussée mais nécessitant d’importantes ressources de calcul et des mises à jour manuelles lorsque les informations changent. De nombreuses organisations utilisent les deux techniques ensemble pour des résultats optimaux.
Comment RAG réduit-il les hallucinations dans les réponses d’IA ?
RAG réduit les hallucinations en ancrant les réponses des LLM dans des documents factuels récupérés. Au lieu de s’appuyer uniquement sur les données d’entraînement, le système récupère des sources pertinentes avant la génération, fournissant au modèle des preuves concrètes à référencer. Cette approche garantit que les réponses sont basées sur des informations réelles plutôt que sur des schémas appris par le modèle, améliorant nettement la précision factuelle et réduisant les affirmations fausses ou trompeuses.
Que sont les embeddings vectoriels et pourquoi sont-ils importants dans RAG ?
Les embeddings vectoriels sont des représentations numériques du texte qui capturent le sens sémantique dans un espace multidimensionnel. Ils permettent aux systèmes RAG d’effectuer des recherches sémantiques, trouvant des documents au sens similaire même s’ils utilisent des mots différents. Les embeddings sont cruciaux car ils permettent à RAG d’aller au-delà de la recherche par mots-clés pour comprendre les relations conceptuelles, améliorant ainsi la pertinence de la récupération et permettant une génération de réponses plus précise.
Les pipelines RAG peuvent-ils fonctionner avec des données en temps réel ?
Oui, les pipelines RAG peuvent intégrer des données en temps réel grâce à des processus d’ingestion et d’indexation continus. Les organisations peuvent mettre en place des pipelines automatisés qui mettent régulièrement à jour la base de données vectorielle avec de nouveaux documents, garantissant ainsi l’actualité de la base de connaissances. Cette capacité rend RAG idéal pour des applications nécessitant des informations à jour comme l’analyse de l’actualité, l’intelligence tarifaire et la veille de marché, sans avoir à réentraîner le LLM sous-jacent.
Quelle est la différence entre la recherche sémantique et RAG ?
La recherche sémantique est une technique de récupération qui trouve des documents en fonction de la similarité de sens à l’aide d’embeddings vectoriels. RAG est un pipeline complet qui combine la recherche sémantique avec la génération LLM pour produire des réponses ancrées dans les documents récupérés. Alors que la recherche sémantique se concentre sur la recherche d’informations pertinentes, RAG ajoute la composante de génération qui synthétise le contenu récupéré en réponses cohérentes avec citations.
Comment les systèmes RAG décident-ils des sources à citer ?
Les systèmes RAG utilisent plusieurs mécanismes pour sélectionner les sources à citer. Ils emploient des algorithmes de récupération pour trouver les documents pertinents, des modèles de reranking pour prioriser les résultats les plus pertinents, et des processus de vérification pour s’assurer que les citations soutiennent effectivement les affirmations émises. Certains systèmes utilisent des approches ‘citer en écrivant’ où les affirmations ne sont faites que si elles sont soutenues par les sources récupérées, tandis que d’autres vérifient les citations après génération et suppriment les affirmations non étayées.
Quels sont les principaux défis dans la construction de pipelines RAG ?
Les principaux défis incluent le maintien de la fraîcheur et de la qualité de la base de connaissances, l’optimisation de la précision de la récupération sur des types de contenus variés, la gestion des coûts de calcul à grande échelle, la gestion de la terminologie spécifique à un domaine que les modèles d’embedding peuvent mal comprendre, et l’évaluation des performances du système avec des métriques complètes. Les organisations doivent également traiter les limitations de fenêtre de contexte des LLM et s’assurer que les documents récupérés restent pertinents à mesure que l’information évolue.
Comment AmICited surveille-t-il les citations RAG dans les systèmes d’IA ?
AmICited suit comment les systèmes d’IA comme ChatGPT, Perplexity et Google AI Overviews récupèrent et citent le contenu via des pipelines RAG. La plateforme surveille les sources sélectionnées pour la citation, la fréquence d’apparition de votre marque dans les réponses IA et l’exactitude des citations. Cette visibilité aide les organisations à comprendre leur présence dans la recherche médiée par l’IA et à garantir la bonne attribution de leur contenu.
Surveillez votre marque dans les réponses d’IA
Suivez comment les systèmes d’IA comme ChatGPT, Perplexity et Google AI Overviews référencent votre contenu. Obtenez de la visibilité sur les citations RAG et la surveillance des réponses IA.
Qu'est-ce que le RAG dans la recherche par IA : Guide complet sur la génération augmentée par récupération
Découvrez ce qu’est le RAG (génération augmentée par récupération) en recherche par IA. Découvrez comment RAG améliore la précision, réduit les hallucinations e...
Fonctionnement de la génération augmentée par récupération : architecture et processus
Découvrez comment RAG combine les LLM avec des sources de données externes pour générer des réponses d’IA précises. Comprenez le processus en cinq étapes, les c...
Découvrez ce qu’est la génération augmentée par la recherche (RAG), son fonctionnement et pourquoi elle est essentielle pour des réponses IA précises. Explorez ...
15 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.