
Données structurées
Les données structurées sont un balisage standardisé qui aide les moteurs de recherche à comprendre le contenu des pages web. Découvrez comment JSON-LD, schema....
12 min de lecture

Balisage schema spécialement conçu pour aider les systèmes d’IA à comprendre et citer le contenu avec précision. Les données structurées utilisent des formats standardisés comme JSON-LD pour fournir un contexte explicite sur le contenu de la page, permettant aux grands modèles de langage d’analyser l’information de façon plus fiable et de citer les sources avec une plus grande confiance.
Balisage schema spécialement conçu pour aider les systèmes d’IA à comprendre et citer le contenu avec précision. Les données structurées utilisent des formats standardisés comme JSON-LD pour fournir un contexte explicite sur le contenu de la page, permettant aux grands modèles de langage d’analyser l’information de façon plus fiable et de citer les sources avec une plus grande confiance.
Les données structurées pour l’IA désignent des informations organisées et lisibles par machine, formatées selon des schémas standardisés qui permettent aux systèmes d’intelligence artificielle de comprendre, d’interpréter et d’utiliser le contenu avec précision. Contrairement au texte non structuré, qui nécessite un traitement du langage naturel complexe pour en déchiffrer le sens, les données structurées fournissent un contexte explicite sur ce que représente l’information. Cette clarté est essentielle car les systèmes d’IA — en particulier les grands modèles de langage et les moteurs de recherche — traitent chaque jour des milliards de points de données. Lorsque le contenu est structuré selon des standards comme schema.org, JSON-LD ou microdata, l’IA peut immédiatement reconnaître les entités, relations et attributs sans ambiguïté. Cette approche structurée offre une précision 300 % supérieure dans la compréhension IA par rapport aux alternatives non structurées. Pour les organisations cherchant à être visibles dans les AI Overviews et autres résultats générés par l’IA, les données structurées sont devenues une infrastructure incontournable. Elles transforment le contenu brut en intelligence que les systèmes d’IA peuvent citer, référencer et intégrer avec confiance dans leurs réponses, changeant fondamentalement la façon dont le contenu digital gagne en découvrabilité dans un monde piloté par l’IA.

Les systèmes d’IA traitent les données structurées via un pipeline sophistiqué qui transforme le contenu balisé en intelligence exploitable. Lorsqu’une IA rencontre des données structurées correctement formatées, elle peut en extraire immédiatement les informations clés sans la surcharge computationnelle requise pour l’interprétation du langage naturel. Le mécanisme technique suit ces étapes essentielles :
Ce processus permet à l’IA d’offrir une visibilité supérieure de plus de 30 % dans les AI Overviews pour le contenu correctement structuré. L’approche structurée réduit le risque de « hallucinations » en ancrant les réponses de l’IA sur des données explicites et vérifiables plutôt que sur une génération textuelle probabiliste. Les organisations mettant en place des stratégies de données structurées complètes constatent des améliorations mesurables dans la découverte, la compréhension et la promotion de leur contenu par les systèmes d’IA sur de multiples plateformes et applications.
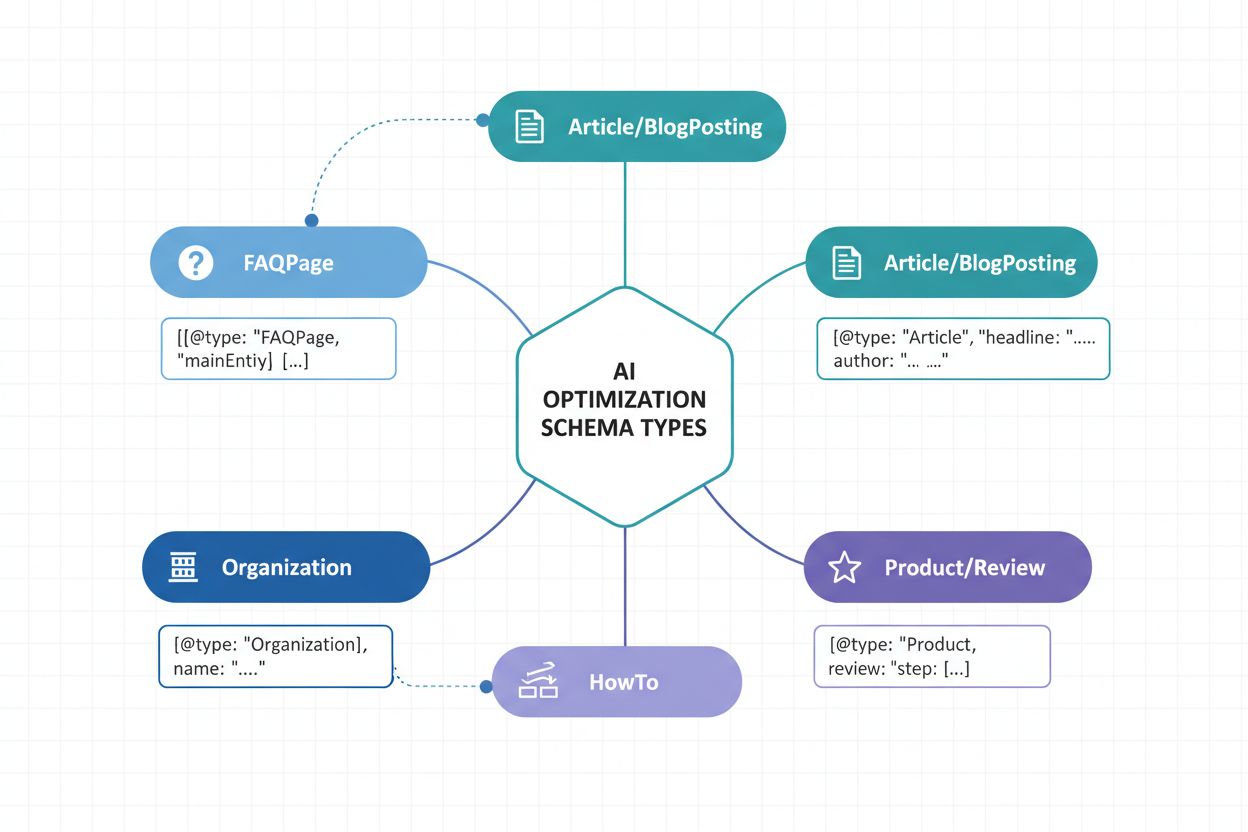
L’implémentation des bons types de schémas est fondamentale pour une stratégie de visibilité IA. Chaque type de contenu nécessite un balisage structuré spécifique pour communiquer sa nature et sa valeur aux systèmes d’IA. Voici les types de schémas essentiels pour maximiser la reconnaissance par l’IA :
Article Schema – Balise les articles d’actualité, blogs et contenus longs avec titre, auteur, date de publication et corps du texte. Critique pour que l’IA identifie les sources de contenu autoritaires et établisse la crédibilité de publication.
Organization Schema – Définit l’identité de l’entreprise, incluant nom, logo, coordonnées et profils sociaux. Permet à l’IA de reconnaître et d’attribuer correctement le contenu organisationnel dans divers contextes.
Product Schema – Structure les informations produit, incluant nom, description, prix, disponibilité et avis. Essentiel pour la visibilité e-commerce dans les assistants IA et les systèmes de recommandation de produits.
LocalBusiness Schema – Balise l’emplacement, les horaires, les coordonnées et les services d’une entreprise. Crucial pour les requêtes IA locales et les AI Overviews géolocalisés qui dominent de plus en plus les résultats de recherche.
BreadcrumbList Schema – Définit la hiérarchie de navigation du site, aidant l’IA à comprendre la structure et les relations entre les pages de votre architecture de l’information.
FAQPage Schema – Structure les questions fréquemment posées avec leurs réponses, permettant à l’IA d’extraire et de citer directement du contenu Q&R dans ses réponses.
NewsArticle et BlogPosting Schemas – Types d’articles spécialisés signalant la catégorie du contenu à l’IA, améliorant la précision de la catégorisation et la pertinence des correspondances.
Event Schema – Balise les détails d’événements (date, lieu, description, inscription), essentiel pour la découverte d’événements par l’IA et l’intégration aux calendriers.
Actuellement, 45 millions de domaines utilisent le balisage schema.org, représentant 12,4 % de tous les domaines dans le monde. Les organisations mettant en œuvre plusieurs types de schémas simultanément bénéficient d’effets de visibilité cumulés, l’IA obtenant une compréhension contextuelle plus riche de leur écosystème de contenu.
Une implémentation réussie des données structurées exige une planification stratégique et une précision technique. Les organisations doivent suivre ces meilleures pratiques reconnues pour maximiser la visibilité IA et garantir la qualité des données :
Voici un exemple pratique de JSON-LD pour un article :
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Données structurées pour l’IA : Guide stratégique d’implémentation",
"author": {
"@type": "Person",
"name": "Auteur du contenu"
},
"datePublished": "2024-01-15",
"image": "https://example.com/image.jpg",
"articleBody": "Texte complet de l’article ici...",
"publisher": {
"@type": "Organization",
"name": "Votre organisation",
"logo": "https://example.com/logo.png"
}
}
Une implémentation correcte permet une amélioration du CTR de 35 % grâce aux résultats enrichis dans la recherche traditionnelle, avec des bénéfices additionnels à mesure que les AI Overviews deviennent des canaux de découverte principaux. Les organisations qui surveillent leurs performances de données structurées via des solutions comme AmICited.com bénéficient d’un avantage concurrentiel en identifiant quels types de contenu et quelles implémentations schema génèrent la plus forte visibilité IA.
Les données structurées et llms.txt servent toutes deux la découvrabilité IA, mais selon des mécanismes fondamentalement différents. Les données structurées utilisent des schémas standardisés (schema.org, JSON-LD) intégrés au HTML pour baliser précisément les éléments de contenu avec une signification sémantique explicite. Cette approche s’intègre directement dans les pages web, rendant l’information immédiatement accessible aux moteurs de recherche et systèmes d’IA lors de l’exploration de contenu. Les données structurées permettent un balisage granulaire des articles, produits, événements et organisations, offrant à l’IA une compréhension précise des relations et attributs.
llms.txt, en revanche, est un fichier texte placé à la racine du site web contenant des instructions et directives à destination des grands modèles de langage. Il fonctionne comme un manifeste communiquant vos préférences sur la manière dont les systèmes IA doivent interagir avec et citer votre contenu. Bien que llms.txt fournisse des directives générales sur les droits d’utilisation et les préférences d’attribution, il n’offre pas la précision sémantique des données structurées. Les données structurées répondent à la question « qu’est-ce que ce contenu ? » avec des réponses explicites, tandis que llms.txt répond « comment utiliser ce contenu ? » à travers des consignes.
La stratégie la plus efficace combine les deux approches : les données structurées garantissent la compréhension et la citation précise de votre contenu par l’IA, tandis que llms.txt établit des politiques et exigences d’attribution claires. Les organisations mettant en place les deux constatent une probabilité 36 % plus élevée d’apparaître dans les résumés générés par l’IA par rapport à celles n’utilisant ni l’un ni l’autre. Les données structurées posent la base de la compréhension IA, llms.txt pose le cadre de gouvernance pour l’attribution et la conformité d’utilisation.
Mesurer l’efficacité des données structurées implique de suivre des métriques spécifiques révélant comment les systèmes d’IA découvrent, comprennent et citent votre contenu. Les organisations doivent surveiller ces indicateurs clés :
AmICited.com propose une surveillance spécialisée des performances de citation IA, permettant aux organisations de suivre comment leurs investissements en données structurées se traduisent en visibilité réelle et attribution. La plateforme révèle quels contenus reçoivent des citations IA, quelles requêtes déclenchent votre contenu, et comment votre fréquence de citation se compare à la concurrence. Cette approche orientée données transforme l’implémentation des données structurées d’une bonne pratique théorique à un impact business mesurable.
Les organisations mettant en œuvre des stratégies de données structurées complètes constatent que 93 % des requêtes sont répondues par l’IA sans clics, rendant la visibilité des citations plus critique que jamais pour générer du trafic. Mesurer la performance des citations garantit que vos investissements en données structurées produisent des retours quantifiables via une meilleure découvrabilité IA et une attribution de marque renforcée.
Une implémentation réussie des données structurées suit une approche progressive, créant des capacités tout en apportant de la valeur à chaque étape. Voici comment structurer votre calendrier d’implémentation :
Phase 1 : Fondations (Mois 1-2)
Phase 2 : Expansion (Mois 3-4)
Phase 3 : Optimisation (Mois 5-6)
Phase 4 : Intégration stratégique (Mois 7+)
Ce calendrier permet aux organisations d’améliorer significativement leur visibilité IA en 2 à 3 mois tout en construisant une infrastructure de données structurées à l’échelle de l’entreprise. Les premiers adoptants suivant cette feuille de route bénéficient d’un avantage concurrentiel à mesure que les AI Overviews deviennent des canaux de découverte majeurs.
Les données structurées sont passées d’un simple atout SEO optionnel à une infrastructure stratégique essentielle dans un paysage digital piloté par l’IA. À mesure que les systèmes d’IA deviennent les intermédiaires principaux de la découverte d’information, les organisations dépourvues de balisage structuré complet subissent un désavantage systémique de visibilité. Ce changement reflète l’évolution profonde des flux d’information : la recherche traditionnelle exigeait de cliquer sur des sites web, mais les AI Overviews répondent directement, faisant de la visibilité des citations le nouveau terrain de compétition.
Les organisations qui mettent en œuvre les données structurées se positionnent stratégiquement pour réussir sur le long terme sur toutes les plateformes IA et canaux de découverte émergents. Cet investissement dans l’infrastructure paie bien au-delà de la visibilité IA immédiate — les données structurées améliorent la gestion interne du contenu, permettent une meilleure personnalisation, optimisent la recherche vocale et créent des actifs de données utiles pour de futures applications IA. Les pionniers posant les fondations de données structurées bénéficient d’avantages cumulatifs à mesure que l’IA privilégie le contenu bien balisé.
L’avantage concurrentiel de l’adoption précoce est décisif. À mesure que l’importance des données structurées devient évidente, leur implémentation devient un prérequis pour la visibilité. Les organisations qui bâtissent une infrastructure robuste dès maintenant domineront les résultats IA à mesure que ces canaux mûrissent. À l’inverse, celles qui tardent à l’implémenter auront de plus en plus de mal à émerger, l’IA privilégiant le contenu exhaustivement balisé. Les données structurées ne sont pas qu’une implémentation technique, mais un engagement stratégique fondamental pour rester découvrable et cité dans un écosystème d’information piloté par l’IA.
Les données structurées n’influencent pas directement le classement Google, mais elles améliorent considérablement l’apparence des résultats via les extraits enrichis, ce qui augmente le taux de clics jusqu’à 35 %. Pour les systèmes d’IA, les données structurées ont un impact plus direct sur la façon dont votre contenu est cité dans les réponses générées par l’IA.
Oui, les systèmes d’IA traitent les données structurées à la fois lors de l’entraînement et des requêtes en temps réel. Bien que OpenAI n’ait pas fait de déclarations publiques, des preuves suggèrent que GPTBot et d’autres robots d’IA analysent le balisage JSON-LD. Microsoft a officiellement confirmé que les systèmes d’IA de Bing utilisent le balisage schema pour mieux comprendre le contenu.
JSON-LD est le format recommandé car il sépare le schema du contenu HTML, ce qui le rend plus facile à mettre en œuvre et à maintenir à grande échelle. Google recommande explicitement JSON-LD, et il présente moins d’erreurs d’implémentation que Microdata ou RDFa.
Les extraits enrichis peuvent apparaître dans les 1 à 4 semaines suivant la mise en œuvre. Les améliorations du taux de clics sont souvent mesurables en 2 semaines. Pour les améliorations de citation par l’IA, comptez 4 à 8 semaines pour que les fondations portent leurs fruits, avec des avantages d’autorité qui s’accumulent sur 3 à 6 mois.
Priorisez d’abord le balisage schema — il est éprouvé et largement supporté. llms.txt est encore une norme émergente avec une adoption limitée par les robots IA. Si vous êtes une entreprise axée sur les développeurs avec une documentation importante, l’effort minimal pour créer un llms.txt peut valoir le coup pour anticiper l’avenir.
Commencez par le schema Organization sur votre page d’accueil (avec les propriétés sameAs), puis l’Article schema sur les pages de contenu clés. Le schema FAQPage doit suivre — c’est le plus utile pour l’extraction IA. Ensuite, ajoutez le schema HowTo pour les guides et SoftwareApplication pour les pages de produits.
Seuls les balisages incorrectement implémentés nuisent aux performances. Les directives de Google sont claires : utilisez des types de schema pertinents correspondant au contenu visible, gardez les prix et dates exacts, et ne balisez pas de contenu invisible pour les utilisateurs. Validez toujours avec le test d’extraits enrichis de Google avant la publication.
Les données structurées fournissent un contexte explicite qui aide les systèmes d’IA à comprendre ce que représente l’information — entités, relations, attributs. Cette clarté permet à l’IA d’extraire et de citer votre contenu en toute confiance. Les LLM basés sur des graphes de connaissances atteignent une précision 300 % supérieure par rapport à ceux reposant uniquement sur des données non structurées.
Suivez comment les systèmes d’IA citent votre contenu sur ChatGPT, Perplexity, Google AI Overviews et d’autres plateformes. Obtenez une visibilité en temps réel sur votre présence IA.
Les données structurées sont un balisage standardisé qui aide les moteurs de recherche à comprendre le contenu des pages web. Découvrez comment JSON-LD, schema....
Découvrez comment les robots d’IA traitent les données structurées. Comprenez pourquoi la méthode d’implémentation JSON-LD est cruciale pour la visibilité dans ...

Découvrez comment un formatage adapté à l’IA avec des tableaux, listes et sections claires améliore la précision de l’analyse par l’IA et augmente la visibilité...