
Données d'entraînement
Les données d'entraînement sont l'ensemble de données utilisé pour enseigner aux modèles ML les motifs et les relations. Découvrez comment la qualité des donnée...
14 min de lecture

L’entraînement sur données synthétiques est le processus d’entraînement de modèles d’IA à l’aide de données générées artificiellement plutôt que d’informations réelles créées par des humains. Cette approche répond à la rareté des données, accélère le développement des modèles et préserve la confidentialité, tout en introduisant des défis tels que le collapse de modèle et les hallucinations qui nécessitent une gestion et une validation minutieuses.
L'entraînement sur données synthétiques est le processus d'entraînement de modèles d'IA à l'aide de données générées artificiellement plutôt que d'informations réelles créées par des humains. Cette approche répond à la rareté des données, accélère le développement des modèles et préserve la confidentialité, tout en introduisant des défis tels que le collapse de modèle et les hallucinations qui nécessitent une gestion et une validation minutieuses.
L’entraînement sur données synthétiques désigne le processus d’entraînement des modèles d’intelligence artificielle à l’aide de données générées artificiellement plutôt que d’informations réelles créées par des humains. Contrairement à l’entraînement traditionnel de l’IA qui repose sur des ensembles de données authentiques collectés via des enquêtes, des observations ou du web mining, les données synthétiques sont créées par des algorithmes et des méthodes computationnelles qui apprennent les schémas statistiques à partir de données existantes ou génèrent entièrement de nouvelles données. Ce changement fondamental de méthodologie répond à un défi crucial du développement moderne de l’IA : la croissance exponentielle des besoins computationnels a dépassé la capacité de l’humanité à générer suffisamment de données réelles, et la recherche indique que les données d’entraînement générées par l’homme pourraient être épuisées dans les prochaines années. L’entraînement sur données synthétiques offre une alternative évolutive et économique, générable à l’infini sans les processus chronophages de collecte, d’étiquetage et de nettoyage de données qui consomment jusqu’à 80 % des délais de développement de l’IA traditionnelle.
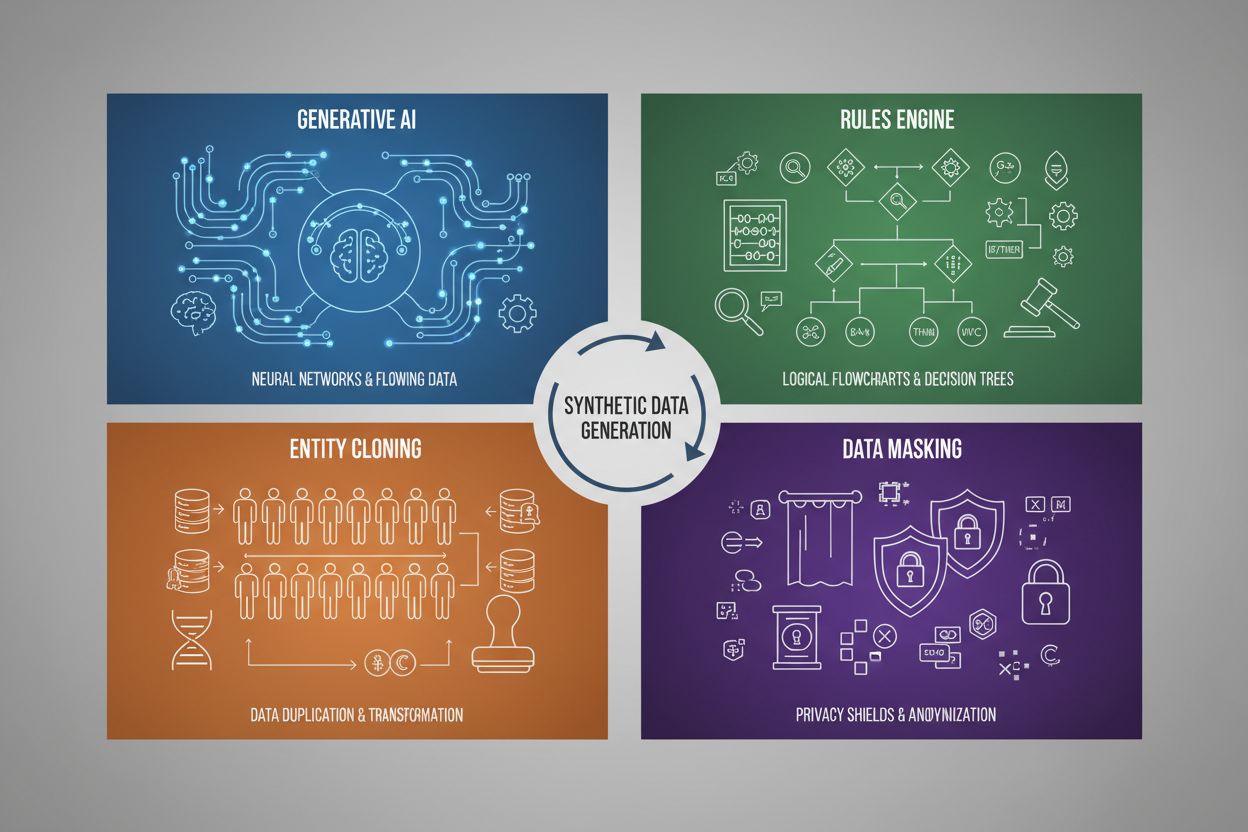
La génération de données synthétiques utilise quatre techniques principales, chacune avec des mécanismes et des applications distincts :
| Technique | Fonctionnement | Cas d’usage |
|---|---|---|
| IA générative (GAN, VAE, GPT) | Utilise des modèles d’apprentissage profond pour apprendre les schémas et distributions statistiques à partir de données réelles, puis génère de nouveaux échantillons synthétiques qui conservent les mêmes propriétés et relations statistiques. Les GAN font intervenir des réseaux adversaires où un générateur crée de fausses données tandis qu’un discriminateur évalue leur authenticité, produisant des résultats de plus en plus réalistes. | Entraînement de grands modèles de langage comme ChatGPT, génération d’images synthétiques avec DALL-E, création de jeux de données textuelles diversifiées pour des tâches de traitement du langage naturel |
| Moteur de règles | Applique des règles logiques et des contraintes prédéfinies pour générer des données qui suivent une logique métier spécifique, des connaissances de domaine ou des exigences réglementaires. Cette approche déterministe assure que les données générées respectent des schémas connus sans nécessiter d’apprentissage automatique. | Données de transactions financières, dossiers médicaux avec exigences de conformité, données de capteurs industriels avec paramètres opérationnels connus |
| Clonage d’entités | Duplique et modifie des enregistrements réels existants via des transformations, perturbations ou variations pour créer de nouveaux exemples tout en conservant les propriétés statistiques et relations de base. Cette technique garde l’authenticité des données tout en augmentant la taille de l’ensemble de données. | Expansion de jeux de données limités dans les secteurs réglementés, création de données d’entraînement pour le diagnostic de maladies rares, augmentation de jeux de données avec des exemples de classes minoritaires insuffisants |
| Masquage et anonymisation des données | Occulte les informations sensibles ou personnelles (PII) tout en préservant la structure et les relations statistiques via des techniques comme la tokenisation, le chiffrement ou la substitution de valeurs. Cela permet de créer des versions synthétiques préservant la confidentialité des données réelles. | Jeux de données de santé ou financiers, données comportementales clients, informations personnelles sensibles en contexte de recherche |
L’entraînement sur données synthétiques permet des réductions de coûts substantielles en éliminant les processus coûteux de collecte, d’annotation et de nettoyage des données qui mobilisent traditionnellement d’importantes ressources et du temps. Les organisations peuvent générer à la demande un nombre illimité d’échantillons d’entraînement, accélérant considérablement les cycles de développement des modèles et permettant une itération et une expérimentation rapide sans attendre la collecte de données réelles. Cette technique offre de puissantes capacités d’augmentation de données, permettant aux développeurs d’étendre des jeux de données limités et de créer des ensembles d’entraînement équilibrés répondant aux problèmes de déséquilibre des classes—un enjeu critique lorsque certaines catégories sont sous-représentées dans les données réelles. Les données synthétiques sont particulièrement précieuses pour lutter contre la rareté des données dans des domaines spécialisés comme l’imagerie médicale, le diagnostic de maladies rares ou les tests de véhicules autonomes, où la collecte d’exemples réels est prohibitive ou pose des enjeux éthiques. La préservation de la confidentialité représente un avantage majeur, car les données synthétiques peuvent être générées sans exposer d’informations personnelles sensibles, ce qui les rend idéales pour l’entraînement de modèles sur des dossiers de santé, des données financières ou d’autres informations réglementées. En outre, les données synthétiques permettent une réduction systématique des biais en offrant la possibilité de créer volontairement des jeux de données équilibrés et diversifiés qui neutralisent les schémas discriminatoires présents dans les données réelles—par exemple, générer des représentations démographiques variées dans des images d’entraînement pour éviter que les modèles d’IA ne perpétuent des stéréotypes de genre ou de race dans le recrutement, le crédit ou la justice.
Malgré ses promesses, l’entraînement sur données synthétiques introduit des défis techniques et pratiques majeurs susceptibles de dégrader la performance des modèles s’ils ne sont pas soigneusement gérés. Le problème le plus critique est le collapse de modèle, un phénomène où des modèles d’IA massivement entraînés sur des données synthétiques subissent une forte dégradation de la qualité, de la précision et de la cohérence de leurs résultats. Cela se produit car les données synthétiques, bien que statistiquement proches des données réelles, manquent de la complexité nuancée et des cas particuliers présents dans les informations humaines authentiques—lorsque les modèles s’entraînent sur du contenu généré par l’IA, ils amplifient les erreurs et artefacts, créant un problème cumulatif où chaque génération de données synthétiques devient de plus en plus médiocre.
Principaux défis :
Ces défis soulignent pourquoi les données synthétiques ne peuvent se substituer aux données réelles—elles doivent au contraire être intégrées avec soin comme complément aux ensembles authentiques, avec une assurance qualité rigoureuse et une supervision humaine tout au long du processus d’entraînement.
À mesure que les données synthétiques deviennent de plus en plus courantes dans l’entraînement des modèles d’IA, les marques font face à un nouveau défi majeur : assurer une représentation exacte et valorisante dans les résultats et citations générés par l’IA. Lorsque les grands modèles de langage et systèmes d’IA générative s’entraînent sur des données synthétiques, la qualité et les caractéristiques de ces données influencent directement la façon dont les marques sont décrites, recommandées et citées dans les résultats de recherche IA, les réponses de chatbots et la génération automatisée de contenu. Cela représente un risque important pour la sécurité de la marque, car des données synthétiques contenant des informations obsolètes, des biais concurrentiels ou des descriptions erronées peuvent s’intégrer dans les modèles d’IA, entraînant une mauvaise représentation persistante auprès de millions d’utilisateurs. Pour les organisations utilisant des plateformes comme AmICited.com afin de surveiller la présence de leur marque dans les systèmes d’IA, comprendre le rôle des données synthétiques dans l’entraînement des modèles devient essentiel—les marques ont besoin de visibilité pour savoir si les citations et mentions IA proviennent de données d’entraînement réelles ou synthétiques, car cela affecte la crédibilité et la précision. Le manque de transparence sur l’utilisation des données synthétiques dans l’entraînement de l’IA crée des défis en matière de responsabilité : les entreprises ne peuvent pas facilement déterminer si les informations concernant leur marque ont été correctement représentées dans les jeux de données synthétiques utilisés pour entraîner les modèles influençant la perception des consommateurs. Les marques visionnaires devraient prioriser la surveillance de l’IA et le suivi des citations pour détecter rapidement toute mauvaise représentation, plaider pour des standards de transparence exigeant la divulgation de l’utilisation de données synthétiques dans l’entraînement de l’IA, et collaborer avec des plateformes offrant des informations sur l’apparence de leur marque à travers des systèmes d’IA entraînés sur des données réelles et synthétiques. À mesure que les données synthétiques deviennent le paradigme d’entraînement dominant d’ici 2030, la surveillance des marques passera du suivi média traditionnel à l’intelligence sur les citations générées par l’IA, rendant indispensables les plateformes suivant la représentation des marques à travers les systèmes d’IA générative pour protéger l’intégrité et assurer la justesse de la voix de marque dans l’écosystème informationnel piloté par l’IA.
L'entraînement traditionnel de l'IA repose sur des données réelles collectées auprès des humains via des enquêtes, des observations ou du web mining, ce qui est long et de plus en plus rare. L'entraînement sur données synthétiques utilise des données générées artificiellement par des algorithmes qui apprennent les schémas statistiques à partir des données existantes ou génèrent entièrement de nouvelles données. Les données synthétiques peuvent être produites à l'infini à la demande, réduisant considérablement le temps et les coûts de développement tout en répondant aux préoccupations de confidentialité.
Les quatre techniques principales sont : 1) l'IA générative (utilisation de GAN, VAE ou modèles GPT pour apprendre et reproduire les schémas de données), 2) le moteur de règles (application d'une logique métier prédéfinie et de contraintes), 3) le clonage d'entités (duplication et modification d'enregistrements existants tout en conservant les propriétés statistiques), et 4) le masquage de données (anonymisation des informations sensibles tout en maintenant la structure des données). Chaque technique répond à des cas d'usage différents et présente des avantages distincts.
Le collapse de modèle se produit lorsque des modèles d'IA entraînés massivement sur des données synthétiques connaissent une forte dégradation de la qualité et de la précision de leurs sorties. Cela arrive car les données synthétiques, bien que statistiquement similaires aux données réelles, manquent de la complexité nuancée et des cas limites de l'information authentique. Lorsque les modèles s'entraînent sur du contenu généré par l'IA, ils amplifient les erreurs et les artefacts, créant un problème cumulatif où chaque génération devient de plus en plus de mauvaise qualité, produisant finalement des résultats inutilisables.
Lorsque les modèles d'IA s'entraînent sur des données synthétiques, la qualité et les caractéristiques de ces données influencent directement la façon dont les marques sont décrites, recommandées et citées dans les résultats des IA. Des données synthétiques de mauvaise qualité contenant des informations obsolètes ou des biais de concurrents peuvent s'intégrer dans les modèles d'IA, entraînant une mauvaise représentation persistante de la marque à travers des millions d'interactions utilisateur. Cela crée un problème de sécurité de la marque nécessitant une surveillance et de la transparence sur l'utilisation des données synthétiques dans l'entraînement de l'IA.
Non, les données synthétiques doivent compléter et non remplacer les données réelles. Bien qu'elles offrent des avantages significatifs en termes de coût, de rapidité et de confidentialité, elles ne peuvent pas reproduire entièrement la complexité, la diversité et les cas limites des données humaines authentiques. L'approche la plus efficace combine données synthétiques et réelles, avec une assurance qualité rigoureuse et une supervision humaine pour garantir la précision et la fiabilité des modèles.
Les données synthétiques offrent une protection supérieure de la vie privée car elles ne contiennent aucune valeur réelle issue des données d'origine et n'ont aucune correspondance un à un avec de vraies personnes. Contrairement aux techniques traditionnelles de masquage ou d'anonymisation qui peuvent encore présenter des risques de réidentification, les données synthétiques sont créées entièrement à partir de schémas appris. Cela les rend idéales pour l'entraînement de modèles sur des informations sensibles telles que les dossiers médicaux, les données financières ou les comportements personnels sans exposer les données réelles des individus.
Les données synthétiques permettent une réduction systématique des biais en autorisant les développeurs à créer volontairement des jeux de données équilibrés et diversifiés qui neutralisent les schémas discriminatoires présents dans les données réelles. Par exemple, il est possible de générer des représentations démographiques variées dans des images d'entraînement pour éviter que les modèles d'IA ne perpétuent des stéréotypes de genre ou de race. Cette capacité est particulièrement précieuse dans les domaines du recrutement, du crédit ou de la justice pénale où les biais peuvent avoir de graves conséquences.
À mesure que les données synthétiques deviennent le paradigme d'entraînement dominant d'ici 2030, les marques doivent comprendre comment leurs informations sont représentées dans les systèmes d'IA. La qualité des données synthétiques influence directement les citations et mentions de marque dans les résultats de l'IA. Les marques doivent surveiller leur présence dans les systèmes d'IA, plaider pour des normes de transparence exigeant la divulgation de l'utilisation de données synthétiques et utiliser des plateformes comme AmICited.com pour suivre la représentation de leur marque et détecter rapidement toute mauvaise représentation.
Découvrez comment votre marque est représentée dans les systèmes d'IA entraînés sur des données synthétiques. Suivez les citations, surveillez l'exactitude et assurez la sécurité de votre marque dans l'écosystème informationnel piloté par l'IA.
Les données d'entraînement sont l'ensemble de données utilisé pour enseigner aux modèles ML les motifs et les relations. Découvrez comment la qualité des donnée...
L’IA générative crée de nouveaux contenus à partir de données d’entraînement grâce à des réseaux neuronaux. Découvrez son fonctionnement, ses applications dans ...

Guide complet pour refuser la collecte de données d'entraînement de l'IA sur ChatGPT, Perplexity, LinkedIn et d'autres plateformes. Découvrez des instructions é...