
Graphique
Découvrez ce que sont les graphiques, leurs types et comment ils transforment des données brutes en informations exploitables. Guide essentiel des formats de vi...
10 min de lecture
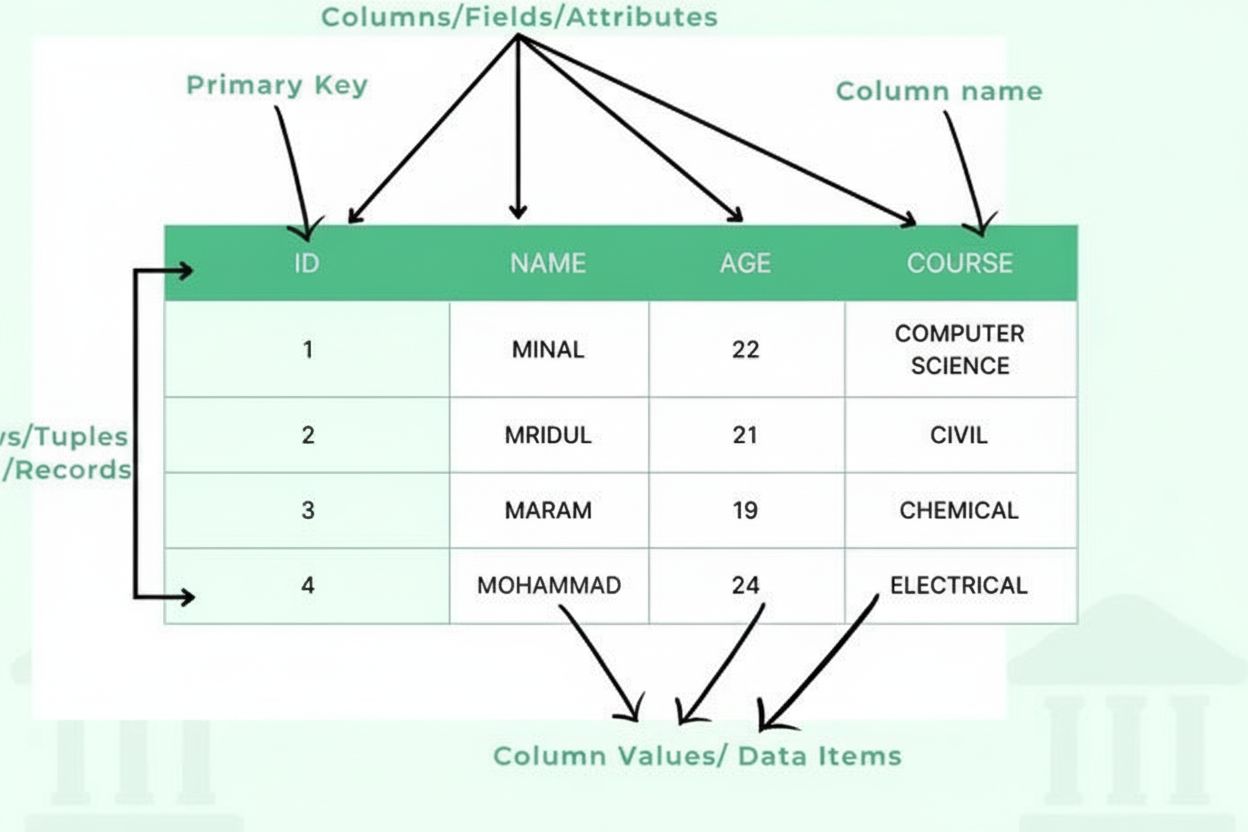
Une table est une méthode d’organisation structurée des données qui dispose l’information dans une grille à deux dimensions composée de lignes horizontales et de colonnes verticales, permettant un stockage, une récupération et une analyse efficaces des données. Les tables constituent le fondement des bases de données relationnelles, des feuilles de calcul et des systèmes de présentation de données, permettant aux utilisateurs de localiser et de comparer rapidement des informations connexes sur plusieurs dimensions.
Une table est une méthode d'organisation structurée des données qui dispose l'information dans une grille à deux dimensions composée de lignes horizontales et de colonnes verticales, permettant un stockage, une récupération et une analyse efficaces des données. Les tables constituent le fondement des bases de données relationnelles, des feuilles de calcul et des systèmes de présentation de données, permettant aux utilisateurs de localiser et de comparer rapidement des informations connexes sur plusieurs dimensions.
Une table est une structure de données fondamentale qui organise l’information dans une grille à deux dimensions composée de lignes horizontales et de colonnes verticales. Sous sa forme la plus simple, une table représente un ensemble de données connexes arrangées de manière structurée, où chaque intersection d’une ligne et d’une colonne contient un seul élément de donnée ou cellule. Les tables constituent la pierre angulaire des bases de données relationnelles, des feuilles de calcul, des entrepôts de données et de pratiquement tous les systèmes nécessitant un stockage et une récupération organisés de l’information. La puissance des tables réside dans leur capacité à permettre un balayage visuel rapide, une comparaison logique des données sur plusieurs dimensions et un accès programmatique à des informations spécifiques via des langages de requête standardisés. Qu’elles soient utilisées en analyse commerciale, en recherche scientifique ou sur des plateformes de suivi IA, les tables offrent un format universellement compris pour présenter des données structurées qui peuvent être facilement interprétées par les humains comme par les machines.
Le concept d’organisation de l’information en lignes et colonnes précède de plusieurs siècles l’informatique moderne. Les civilisations anciennes utilisaient des formats tabulaires pour enregistrer des inventaires, des transactions financières et des observations astronomiques. Cependant, la formalisation des structures de tables en informatique est apparue avec le développement de la théorie des bases de données relationnelles par Edgar F. Codd en 1970, qui a révolutionné la façon dont les données pouvaient être stockées et interrogées. Le modèle relationnel a établi que les données devaient être organisées en tables avec des relations clairement définies, changeant fondamentalement les principes de conception des bases de données. Durant les années 1980 et 1990, les applications de feuilles de calcul comme Lotus 1-2-3 et Microsoft Excel ont démocratisé l’utilisation des tables, rendant l’organisation tabulaire des données accessible aux utilisateurs non techniques. Aujourd’hui, environ 97 % des organisations utilisent des applications de feuilles de calcul pour la gestion et l’analyse des données, démontrant l’importance durable de l’organisation des données sur la base des tables. L’évolution se poursuit avec les développements modernes des bases de données colonnes, des systèmes NoSQL et des data lakes, qui remettent en question les approches traditionnelles orientées lignes tout en conservant des structures similaires aux tables pour organiser l’information.
Une table se compose de plusieurs composants structurels essentiels qui coopèrent pour créer un cadre de données organisé. Les colonnes (également appelées champs ou attributs) sont verticales et représentent des catégories d’information, telles que « Nom du client », « Adresse e-mail » ou « Date d’achat ». Chaque colonne dispose d’un type de données défini, précisant la nature des informations qu’elle peut contenir : entiers, chaînes de texte, dates, décimaux ou structures plus complexes. Les lignes (aussi appelées enregistrements ou tuples) sont horizontales et représentent les entrées individuelles ou entités, chaque ligne contenant un enregistrement complet. L’intersection d’une ligne et d’une colonne crée une cellule ou élément de donnée, qui contient une seule information. Les en-têtes de colonnes identifient chaque colonne et apparaissent en haut de la table, fournissant un contexte pour les données en dessous. Les clés primaires sont des colonnes spéciales qui identifient de façon unique chaque ligne, évitant tout doublon d’enregistrement. Les clés étrangères établissent des relations entre tables en faisant référence à des clés primaires d’autres tables. Cette organisation hiérarchique permet aux bases de données de maintenir l’intégrité des données, d’éviter la redondance et de prendre en charge des requêtes complexes récupérant des informations selon plusieurs critères.
| Aspect | Tables orientées lignes | Tables orientées colonnes | Approches hybrides |
|---|---|---|---|
| Méthode de stockage | Données stockées et consultées par enregistrements complets | Données stockées et consultées par colonnes individuelles | Combine les avantages des deux approches |
| Performance des requêtes | Optimisée pour les requêtes transactionnelles sur des enregistrements complets | Optimisée pour les requêtes analytiques sur des colonnes spécifiques | Performance équilibrée pour des charges mixtes |
| Cas d’utilisation | OLTP (Traitement transactionnel en ligne), opérations métiers | OLAP (Traitement analytique en ligne), entrepôts de données | Analytique en temps réel, veille opérationnelle |
| Exemples de bases de données | MySQL, PostgreSQL, Oracle, SQL Server | Vertica, Cassandra, HBase, Parquet | Snowflake, BigQuery, Apache Iceberg |
| Efficacité de la compression | Taux de compression plus faibles en raison de la diversité des données | Taux de compression plus élevés pour des valeurs similaires en colonne | Compression optimisée pour certains schémas |
| Performance en écriture | Écritures rapides pour les enregistrements complets | Écritures plus lentes nécessitant des mises à jour de colonnes | Performance d’écriture équilibrée |
| Scalabilité | S’adapte bien au volume de transactions | S’adapte bien au volume de données et à la complexité des requêtes | Scalabilité sur les deux dimensions |
Dans les systèmes de gestion de bases de données relationnelles (SGBDR), les tables sont implémentées comme des ensembles structurés de lignes, chaque ligne respectant un schéma prédéfini. Le schéma définit la structure de la table, précisant les noms des colonnes, les types de données, les contraintes et les relations. Lorsqu’une donnée est insérée dans une table, le système de gestion de base de données valide que chaque valeur correspond au type de données de sa colonne et respecte les contraintes définies. Par exemple, une colonne définie comme INTEGER refusera les valeurs textuelles, et une colonne marquée NOT NULL refusera les entrées vides. Des index sont créés sur les colonnes fréquemment interrogées afin d’accélérer la récupération des données, servant de références organisées permettant à la base de localiser des lignes spécifiques sans parcourir toute la table. La normalisation est un principe de conception qui organise les tables pour minimiser la redondance et améliorer l’intégrité des données en répartissant l’information dans des tables reliées par des clés. Les bases de données modernes prennent en charge les transactions, qui garantissent que plusieurs opérations sur des tables réussissent ou échouent ensemble, maintenant la cohérence même en cas de défaillance système. L’optimiseur de requête des moteurs de base analyse les requêtes SQL et détermine la manière la plus efficace d’accéder aux données de la table, en tenant compte des index disponibles et des statistiques sur les tables.
Les tables servent de mécanisme principal pour présenter des données structurées aux utilisateurs dans les formats numériques et imprimés. Dans les applications de business intelligence et d’analyse, les tables affichent des indicateurs agrégés, des indicateurs de performance et des enregistrements transactionnels détaillés permettant aux décideurs de comprendre rapidement des ensembles de données complexes. Les études indiquent que 83 % des professionnels s’appuient sur les tables de données comme principal outil d’analyse, car elles permettent une comparaison précise des valeurs et la reconnaissance des schémas. Les tables HTML sur les sites web utilisent un balisage sémantique avec les éléments <table>, <tr> (ligne de table), <td> (donnée de table) et <th> (en-tête de table) pour structurer les données, tant pour l’affichage visuel que pour l’interprétation programmatique. Les applications de feuilles de calcul comme Microsoft Excel, Google Sheets et LibreOffice Calc étendent la fonctionnalité de base des tables grâce aux formules, au formatage conditionnel et aux tableaux croisés dynamiques, permettant aux utilisateurs d’effectuer des calculs et de réorganiser dynamiquement les données. Les bonnes pratiques de visualisation de données recommandent l’utilisation de tables lorsque la précision des valeurs prévaut sur la visualisation de schémas, lors de la comparaison de multiples attributs pour chaque enregistrement, ou lorsque des recherches ou des calculs sont nécessaires. L’Initiative pour l’accessibilité du Web (W3C) souligne que des tables correctement structurées, avec des en-têtes clairs et un balisage approprié, sont essentielles pour rendre les données accessibles aux personnes en situation de handicap, notamment celles utilisant des lecteurs d’écran.
Dans le contexte des plateformes de suivi IA comme AmICited, les tables jouent un rôle clé dans l’organisation et la présentation des données relatives à l’apparition de contenus sur différents systèmes IA. Les tables de suivi répertorient des indicateurs tels que la fréquence des citations, les dates d’apparition, les sources plateformes IA (ChatGPT, Perplexity, Google AI Overviews, Claude) ainsi que des informations contextuelles sur la manière dont les domaines et URLs sont référencés. Ces tables permettent aux organisations de comprendre leur visibilité de marque dans les réponses générées par l’IA et d’identifier les tendances sur la manière dont différents systèmes IA citent ou référencent leur contenu. La structure organisée des tables de suivi permet le filtrage, le tri et l’agrégation des données de citation, rendant possible de répondre à des questions telles que : « Quelles URL de notre site apparaissent le plus souvent dans les réponses de Perplexity ? » ou « Comment notre taux de citation a-t-il évolué le mois dernier ? » Les tables de données dans les systèmes de suivi facilitent également la comparaison sur plusieurs dimensions : comparer les schémas de citation entre différentes plateformes IA, analyser la croissance des citations dans le temps ou identifier quels types de contenus reçoivent le plus de références IA. La possibilité d’exporter les données de suivi des tables vers des rapports, des tableaux de bord ou d’autres outils d’analyse rend les tables indispensables pour les organisations souhaitant comprendre et optimiser leur présence dans les contenus générés par l’IA.
Une conception de table efficace requiert une réflexion approfondie sur la structure, les conventions de nommage et les principes d’organisation des données. Le nommage des colonnes doit utiliser des identifiants clairs et descriptifs reflétant fidèlement les données qu’elles contiennent, en évitant les abréviations sources de confusion pour les utilisateurs ou développeurs. Le choix du type de données est crucial : des types appropriés empêchent les saisies invalides et permettent le tri et la comparaison adéquats. La définition de la clé primaire garantit l’identification unique de chaque ligne, essentielle à l’intégrité des données et à l’établissement de relations avec d’autres tables. La normalisation réduit la redondance des données en organisant l’information en tables connexes plutôt qu’en stockant des doublons à différents endroits. La stratégie d’indexation doit équilibrer la rapidité des requêtes avec le surcoût de la maintenance des index lors de modifications de données. La documentation de la structure de la table, incluant la définition des colonnes, les types de données, les contraintes et les relations, est essentielle pour la maintenabilité à long terme. Un contrôle d’accès doit être mis en place pour protéger les données sensibles contre tout accès non autorisé. L’optimisation des performances implique le suivi des temps d’exécution des requêtes et des ajustements sur la structure des tables, les index ou les requêtes pour améliorer l’efficacité. Des procédures de sauvegarde et de récupération doivent être établies pour protéger les données des tables contre la perte ou la corruption.
L’avenir de l’organisation des données basée sur les tables évolue pour répondre à des besoins de plus en plus complexes tout en conservant les principes fondamentaux qui font l’efficacité des tables. Les formats de stockage colonne comme Apache Parquet et ORC deviennent la norme dans les environnements big data, optimisant les tables pour les charges analytiques tout en maintenant une structure tabulaire. Les données semi-structurées au format JSON et XML sont de plus en plus stockées dans les colonnes de table, permettant à celles-ci d’accueillir à la fois des données structurées et flexibles. L’intégration de l’apprentissage automatique permet aux bases de données d’optimiser automatiquement la structure des tables et l’exécution des requêtes selon les schémas d’utilisation. Les plateformes d’analytique en temps réel étendent les tables pour prendre en charge les flux de données et les mises à jour continues, dépassant les opérations traditionnelles de tables orientées lot. Les bases de données cloud-native repensent l’implémentation des tables pour exploiter le calcul distribué, permettant aux tables de s’étendre sur plusieurs serveurs et régions géographiques. Les cadres de gouvernance des données accordent une importance croissante aux métadonnées de table, au suivi de la lignée et aux indicateurs de qualité pour garantir la fiabilité des données. L’émergence de plateformes de données pilotées par l’IA offre de nouvelles opportunités aux tables pour servir de sources structurées d’entraînement pour les modèles de machine learning, tout en posant la question du design optimal pour fournir des données de haute qualité. À mesure que les organisations génèrent toujours plus de données, les tables restent la structure de base pour organiser, interroger et analyser l’information, les innovations portant sur la performance, la scalabilité et l’intégration avec les technologies modernes des données.
Une ligne est une disposition horizontale de données représentant un enregistrement ou une entité unique, tandis qu'une colonne est une disposition verticale représentant un attribut ou champ spécifique partagé par tous les enregistrements. Dans une table de base de données, chaque ligne contient l'ensemble des informations concernant une entité (comme un client), et chaque colonne contient une seule catégorie d'information (comme le nom ou l'adresse mail du client). Ensemble, lignes et colonnes créent la structure bidimensionnelle qui définit une table.
Les tables constituent la structure organisationnelle fondamentale des bases de données relationnelles, permettant un stockage, une récupération et une manipulation efficaces des données. Elles permettent aux bases de données de maintenir l'intégrité des données via des schémas structurés, de prendre en charge des requêtes complexes sur plusieurs dimensions et de faciliter les relations entre différentes entités de données grâce aux clés primaires et étrangères. Les tables rendent possible l'organisation de millions d'enregistrements de façon à la fois efficace pour l'informatique et logique pour les opérations métier.
Une table comprend plusieurs composants essentiels : les colonnes (champs/attributs) qui définissent les types et catégories de données, les lignes (enregistrements/tuples) qui contiennent les entrées individuelles, les en-têtes qui identifient chaque colonne, les éléments de données (cellules) qui stockent les valeurs réelles, les clés primaires qui identifient de façon unique chaque ligne, et éventuellement les clés étrangères qui établissent des relations avec d'autres tables. Chaque composant joue un rôle crucial dans le maintien de l'organisation et de l'intégrité des données.
Sur les plateformes de surveillance IA comme AmICited, les tables sont essentielles pour organiser et présenter les données concernant l'apparition de modèles IA, les citations et les mentions de marques sur différents systèmes IA. Les tables permettent aux systèmes de suivi d'afficher des données structurées sur le moment et l'endroit où le contenu apparaît dans les réponses IA, facilitant le suivi des indicateurs, la comparaison des performances entre plateformes et l'identification des tendances sur la façon dont les systèmes IA citent ou référencent des domaines et URL spécifiques.
Les bases de données orientées lignes (comme les bases de données relationnelles traditionnelles) stockent et accèdent aux données par enregistrements complets, ce qui les rend efficaces pour les transactions nécessitant toutes les informations sur une entité. Les bases de données orientées colonnes stockent les données par colonne, ce qui les rend plus rapides pour les requêtes analytiques qui nécessitent des attributs spécifiques sur de nombreux enregistrements. Le choix entre ces approches dépend de votre cas d'usage principal : opérations transactionnelles ou requêtes analytiques.
Des tables accessibles requièrent un balisage HTML approprié utilisant des éléments sémantiques comme `
Les colonnes de table peuvent stocker divers types de données, notamment des entiers, des nombres à virgule flottante, des chaînes de caractères/texte, des dates et heures, des booléens, et des types de plus en plus complexes comme JSON ou XML. Chaque colonne possède un type de données défini qui restreint les valeurs pouvant y être saisies, garantissant la cohérence des données et permettant le tri et la comparaison appropriés. Certaines bases de données prennent également en charge des types spécialisés comme les données géographiques, les tableaux ou les types définis par l'utilisateur.
Commencez à suivre comment les chatbots IA mentionnent votre marque sur ChatGPT, Perplexity et d'autres plateformes. Obtenez des informations exploitables pour améliorer votre présence IA.
Découvrez ce que sont les graphiques, leurs types et comment ils transforment des données brutes en informations exploitables. Guide essentiel des formats de vi...
La visualisation des données est la représentation graphique des données à l'aide de graphiques, diagrammes et tableaux de bord. Découvrez comment les données v...
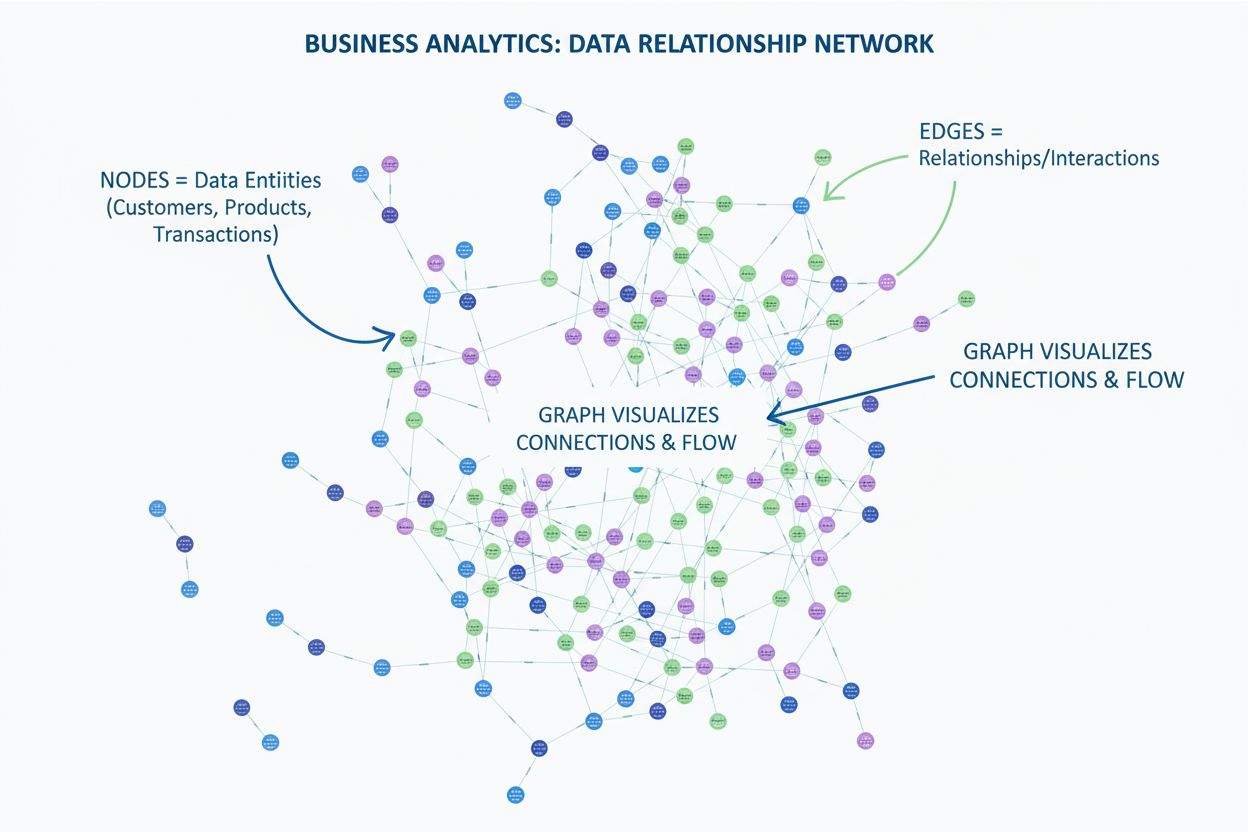
Découvrez ce qu'est un graphe en visualisation de données. Découvrez comment les graphes affichent les relations entre les données à l'aide de nœuds et d'arêtes...