
How Does ChatGPT Choose Which Sources to Cite? Complete Guide
Discover how ChatGPT selects and cites sources when browsing the web. Learn about credibility factors, search algorithms, and how to optimize your content for A...
7 min read

AI Source Selection is the algorithmic process by which artificial intelligence systems evaluate, rank, and choose which web sources to cite in generated responses. It involves analyzing multiple signals including domain authority, content relevance, freshness, topical expertise, and credibility to determine which sources best answer user queries.
AI Source Selection is the algorithmic process by which artificial intelligence systems evaluate, rank, and choose which web sources to cite in generated responses. It involves analyzing multiple signals including domain authority, content relevance, freshness, topical expertise, and credibility to determine which sources best answer user queries.
AI Source Selection is the algorithmic process through which artificial intelligence systems evaluate, rank, and choose which web sources to cite when generating responses to user queries. Rather than randomly pulling information from the internet, modern AI platforms like ChatGPT, Perplexity, Google AI Overviews, and Claude employ sophisticated evaluation mechanisms that assess sources across multiple dimensions—including domain authority, content relevance, freshness, topical expertise, and credibility signals. This process fundamentally determines which brands, websites, and content creators gain visibility in the rapidly expanding world of generative search. Understanding AI Source Selection is essential for anyone seeking visibility in AI-powered search results, as it represents a paradigm shift from traditional search engine optimization where backlinks once dominated authority measurement.
The concept of source selection in AI systems emerged from Retrieval-Augmented Generation (RAG), a technique developed to ground large language models in external data sources. Before RAG, AI systems generated responses purely from training data, which often contained outdated or inaccurate information. RAG solved this by enabling AI to retrieve relevant documents from knowledge bases before synthesizing answers, fundamentally changing how AI systems interact with web content. Early implementations of RAG were relatively simple, using basic keyword matching to retrieve sources. However, as AI systems evolved, source selection became increasingly sophisticated, incorporating machine learning algorithms that evaluate source quality across multiple signals simultaneously. By 2024-2025, major AI platforms had developed proprietary source selection algorithms that consider over 50 distinct factors when deciding which sources to cite, making this one of the most complex and consequential processes in modern search technology.
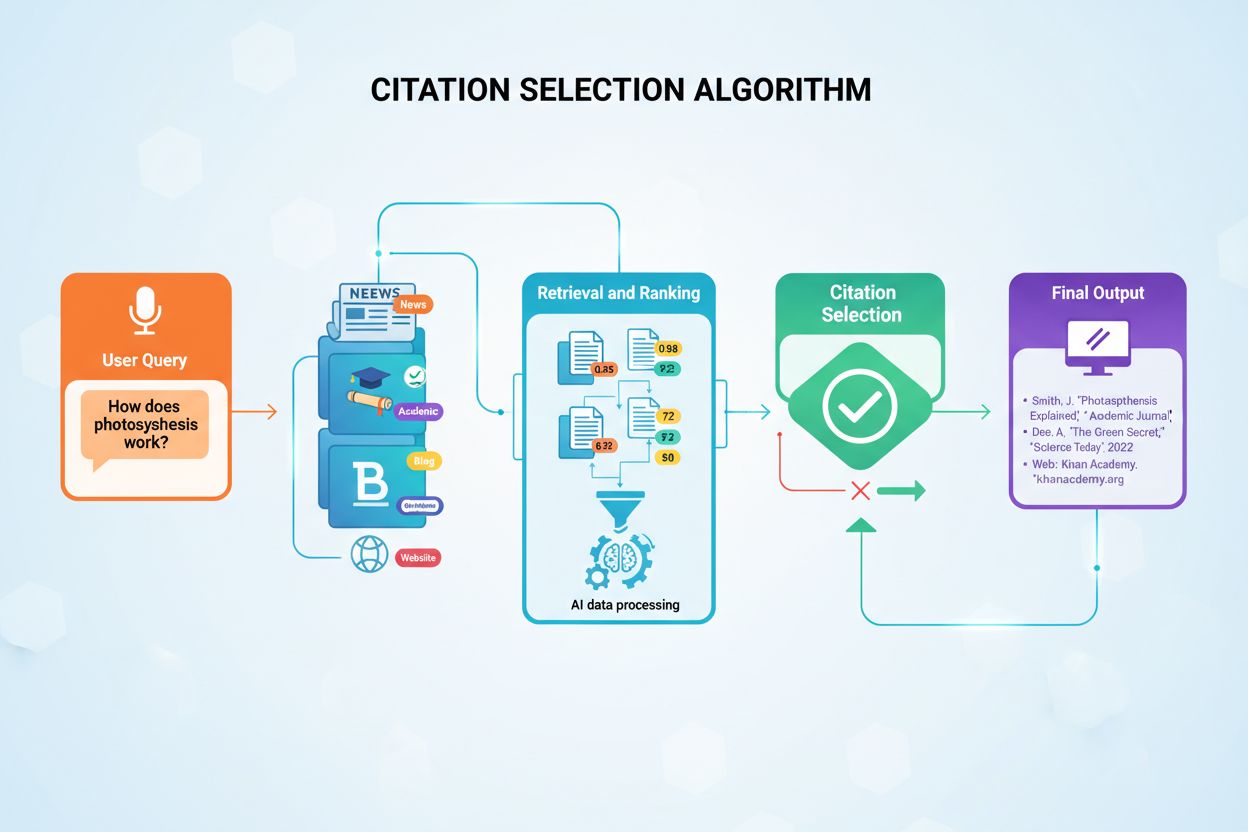
AI Source Selection operates through a multi-stage pipeline that begins with query understanding and ends with citation ranking. When a user submits a query, the AI system first decomposes it into semantic components, identifying the core intent and related subtopics. This process, known as query fan-out, generates multiple related searches that help the system understand the full scope of what the user is asking. For example, a query about “best productivity software for remote teams” might fan out into subtopics like “productivity software features,” “remote work tools,” “team collaboration,” and “software pricing.” The system then retrieves candidate sources for each subtopic from its indexed knowledge base—typically drawing from billions of web pages, academic papers, and other digital content. These candidates are then scored using multi-dimensional evaluation algorithms that assess authority, relevance, freshness, and credibility. Finally, the system applies deduplication and diversity logic to ensure the final citation set covers multiple perspectives while avoiding redundancy.
The technical implementation of these mechanisms varies across platforms. ChatGPT uses a combination of semantic similarity scoring and authority ranking derived from its training data, which includes web pages, books, and academic sources. Google AI Overviews leverage Google’s existing ranking infrastructure, starting with pages already identified as high-quality through traditional search algorithms, then applying additional filters for AI-specific criteria. Perplexity emphasizes real-time web search combined with authority scoring, allowing it to cite more recent sources than systems relying solely on training data. Claude employs a more conservative approach, prioritizing sources with explicit credibility signals and avoiding speculative or controversial content. Despite these differences, all major AI platforms share a common underlying principle: sources are selected based on their ability to provide accurate, relevant, and trustworthy information that directly addresses user intent.
The evaluation of domain authority in AI Source Selection differs significantly from traditional SEO’s reliance on backlinks. While backlinks still matter—they correlate with AI citations at 0.37—they are no longer the dominant signal. Instead, brand mentions show the strongest correlation with AI citations at 0.664, nearly 3x more powerful than backlinks. This represents a fundamental inversion of two decades of SEO strategy. Brand mentions include any reference to a company or individual across the web, whether in news articles, social media discussions, academic papers, or industry publications. AI systems interpret these mentions as signals of real-world relevance and authority—if people are talking about a brand, it must be important and trustworthy.
Beyond brand mentions, AI systems evaluate authority through several other mechanisms. Knowledge graph presence indicates whether a domain is recognized as an authoritative entity by major search engines and knowledge bases. Author credibility is assessed through signals like verified credentials, publication history, and professional affiliations. Institutional affiliation matters significantly—content from universities, government agencies, and established research institutions receives higher authority scores. Citation patterns within content are analyzed; sources that cite peer-reviewed research and primary sources are ranked higher than those making unsupported claims. Topical consistency across a domain’s content portfolio signals deep expertise; a website that publishes consistently on a specific topic is deemed more authoritative than one that covers disparate subjects. Research analyzing 36 million AI Overviews found that Wikipedia (18.4% of citations), YouTube (23.3%), and Google.com (16.4%) dominate across industries, but domain-specific authorities emerge within niches—NIH leads health citations at 39%, Shopify dominates e-commerce at 17.7%, and Google’s official documentation ties with YouTube for SEO topics at 39%.
Semantic alignment—the degree to which content matches the user’s intent and query language—is a critical factor in AI Source Selection. Unlike traditional keyword matching, AI systems understand meaning at a deeper level, recognizing that “best productivity tools for distributed teams” and “top software for remote collaboration” are semantically equivalent queries. Sources are evaluated not just on whether they contain relevant keywords, but on whether they comprehensively address the underlying intent. This evaluation happens through embedding-based similarity scoring, where both the user query and candidate sources are converted into high-dimensional vectors that capture semantic meaning. Sources with embeddings closest to the query embedding receive higher relevance scores.
The topical depth of content significantly influences selection. AI systems analyze whether a source provides surface-level information or comprehensive coverage of a topic. A page that briefly mentions a software tool will score lower than one that provides detailed feature comparisons, pricing analysis, and use case discussions. This preference for depth explains why listicles achieve 25% citation rates compared to 11% for narrative blog posts—structured lists with multiple items provide the comprehensive coverage AI systems favor. Entity recognition and disambiguation also matter; sources that clearly identify and explain entities (companies, products, people, concepts) are preferred over those that assume reader familiarity. For example, a source that explicitly defines “SaaS” before discussing SaaS productivity tools will rank higher than one that uses the acronym without explanation.
Query intent matching is another crucial dimension. AI systems classify queries into categories—informational (seeking knowledge), transactional (seeking to purchase), navigational (seeking a specific site), or commercial (seeking product information)—and prioritize sources that match the intent type. For informational queries, educational content and explanatory articles rank highest. For transactional queries, product pages and review sites are prioritized. This intent-based filtering ensures that sources selected are not just relevant but appropriate for what the user is actually trying to accomplish.
Content freshness plays a more prominent role in AI Source Selection than in traditional search ranking. Research shows that AI platforms cite content that is 25.7% fresher than what appears in traditional organic search results. ChatGPT demonstrates the strongest recency bias, with 76.4% of its most-cited pages updated within the last 30 days. This preference for fresh content reflects AI systems’ awareness that information becomes outdated, particularly in fast-moving fields like technology, finance, and health. Temporal signals are evaluated through multiple mechanisms: publication date indicates when content was originally created, last modified date shows when it was last updated, content versioning reveals whether updates are tracked and documented, and freshness indicators like “updated on [date]” provide explicit signals to AI systems.
The importance of freshness varies by topic. For evergreen topics like “how to write a resume,” content from several years ago may still be relevant if it hasn’t been superseded by new best practices. For time-sensitive topics like “current interest rates” or “latest AI models,” only recently updated content is considered authoritative. AI systems employ temporal decay functions that progressively reduce the ranking of older content, with the decay rate varying based on topic classification. For health and finance topics, decay is steep—content older than 30 days may be deprioritized. For historical or reference topics, decay is gentler, allowing older but authoritative sources to remain competitive. Update frequency also signals authority; sources that are regularly maintained and updated are deemed more trustworthy than those left static for years.
E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) has become the cornerstone of AI Source Selection, particularly for YMYL (Your Money, Your Life) topics like health, finance, and legal advice. AI systems evaluate each dimension through distinct mechanisms. Experience is assessed through author bios, professional credentials, and demonstrated track records. A health article written by a board-certified physician carries more weight than one by a health blogger without medical credentials. Expertise is evaluated through content depth, citation of research, and consistency across multiple pieces of content. A domain that publishes dozens of well-researched articles on a topic demonstrates expertise more convincingly than a single comprehensive article. Authoritativeness is confirmed through third-party validation—mentions in reputable publications, citations by other experts, and presence in industry directories all signal authority. Trustworthiness is assessed through transparency signals like clear authorship, disclosed conflicts of interest, and accurate citations.
For health topics specifically, institutional authority dominates—NIH (39% of citations), Healthline (15%), Mayo Clinic (14.8%), and Cleveland Clinic (13.8%) lead because they represent established medical institutions with rigorous editorial standards. For finance, the pattern is more distributed, with YouTube (23%) leading for educational content, Wikipedia (7.3%) for definitions, and Investopedia (5.7%) for explanations. This variation reflects how different content types serve different purposes in the user journey. AI systems recognize that a user seeking to understand compound interest might benefit from a YouTube explainer, while someone researching investment strategies might need institutional analysis. The credibility assessment process is iterative; AI systems cross-reference multiple signals to confirm trustworthiness, reducing the risk of citing unreliable sources.
| Factor | AI Source Selection | Traditional SEO Ranking | Key Difference |
|---|---|---|---|
| Primary Authority Signal | Brand mentions (0.664 correlation) | Backlinks (0.41 correlation) | AI values conversational authority over link authority |
| Content Freshness Weight | Very high (76.4% within 30 days) | Moderate (varies by topic) | AI deprioritizes older content more aggressively |
| Citation Format Preference | Structured (lists, tables, FAQs) | Keyword-optimized prose | AI prioritizes extractability over keyword density |
| Multi-Platform Presence | Critical (YouTube, Reddit, LinkedIn) | Secondary (backlinks matter more) | AI rewards distributed authority across platforms |
| E-E-A-T Signals | Dominant for YMYL topics | Important but less emphasized | AI applies stricter credibility standards |
| Query Intent Matching | Explicit (intent-based filtering) | Implicit (keyword-based) | AI understands and matches user intent directly |
| Source Diversity | Actively encouraged (3-9 sources per answer) | Not a ranking factor | AI blends multiple perspectives intentionally |
| Real-Time Updates | Preferred (RAG enables live retrieval) | Limited (index updates take time) | AI can cite very recent content immediately |
| Semantic Relevance | Primary evaluation method | Secondary to keyword matching | AI understands meaning beyond keywords |
| Author Credentials | Heavily weighted | Rarely evaluated | AI verifies expertise explicitly |
Different AI platforms exhibit distinct source selection preferences that reflect their underlying architectures and design philosophies. ChatGPT, powered by OpenAI’s GPT-4o, favors established, factual sources that minimize hallucination risk. Its citation patterns show Wikipedia dominance (27% of citations), reflecting the platform’s reliance on neutral, reference-style content. News outlets like Reuters (~6%) and Financial Times (~3%) appear frequently, while blogs account for ~21% of citations. Notably, user-generated content barely registers (<1%), and vendor blogs are rarely cited (<3%), indicating ChatGPT’s conservative approach to commercial content. This pattern suggests that to be cited by ChatGPT, brands need to establish presence on neutral, reference-oriented platforms rather than relying on their own marketing content.
Google Gemini 2.0 Flash takes a more balanced approach, blending authoritative sources with community content. Blogs (~39%) and news (~26%) dominate, while YouTube emerges as the most-cited individual domain (~3%). Wikipedia appears less frequently than in ChatGPT, and community content (~2%) is included selectively. This pattern reflects Gemini’s design to synthesize professional expertise with peer perspectives, particularly for consumer-focused queries. Perplexity AI emphasizes expert sources and niche review sites, with blog/editorial content (~38%), news (~23%), and specialized review platforms (~9%) like NerdWallet and Consumer Reports leading. User-generated content appears selectively depending on topic—finance queries lean on expert sites, while e-commerce may include Reddit discussions. Google AI Overviews pull from the widest range of sources, reflecting Google Search’s diversity. Blogs (~46%) and mainstream news (~20%) form the bulk, while community content (~4%, including Reddit/Quora) and social media (LinkedIn) also contribute. Notably, vendor-authored product blogs appear (~7%), while Wikipedia is rare (<1%), suggesting Google’s AI Overviews are more open to commercial content than ChatGPT.
The technical implementation of AI Source Selection involves several interconnected systems working in concert. The retrieval stage begins with the AI system converting the user query into embeddings—high-dimensional vectors that capture semantic meaning. These embeddings are compared against embeddings of billions of indexed documents using approximate nearest neighbor search, a technique that efficiently identifies the most semantically similar documents. This retrieval stage typically returns thousands of candidate sources. The ranking stage then applies multiple scoring functions to these candidates. BM25 scoring (a probabilistic relevance framework) evaluates keyword relevance. PageRank-style algorithms assess authority based on link graphs. Temporal decay functions reduce scores for older content. Domain authority scores (derived from backlink analysis) are applied. E-E-A-T classifiers (often neural networks trained on credibility signals) evaluate trustworthiness. Diversity algorithms ensure the final set covers multiple perspectives.
The deduplication stage removes near-duplicate sources that provide redundant information. Diversity optimization then selects sources that collectively cover the broadest range of relevant subtopics. This is where query fan-out becomes critical—by identifying related subtopics, the system ensures that selected sources address not just the primary query but also likely follow-up questions. The final ranking combines all these signals using learning-to-rank models—machine learning models trained on human feedback about which sources are most helpful. These models learn to weight different signals appropriately; for health queries, E-E-A-T signals might receive 40% weight, while for technical queries, topical expertise might receive 50% weight. The top-ranked sources are then formatted as citations in the final response, with the system determining how many sources to include (typically 3-9 depending on the platform and query complexity).
Understanding AI Source Selection fundamentally changes content strategy. The traditional SEO playbook—build backlinks, optimize keywords, improve rankings—is no longer sufficient. Brands must now think about citation-worthiness: creating content that AI systems will actively choose to cite. This requires a multi-platform approach. YouTube presence is critical, as video is the single most-cited content format across nearly every vertical. Educational, well-structured videos that explain, demonstrate, or summarize complex topics in human-friendly ways are highly favored. Reddit and Quora engagement matters because AI systems recognize these platforms as sources of authentic, peer-driven insights. LinkedIn thought leadership signals expertise to AI systems evaluating author credentials. Industry publication coverage (earned media) provides third-party validation that AI systems weight heavily.
Content structure becomes as important as content quality. Listicles (25% citation rate) outperform narrative blogs (11% citation rate) because they’re easier for AI to parse and extract. FAQ sections map perfectly to how AI constructs responses. Comparison tables provide structured data that AI can easily incorporate. Clear heading hierarchies (H1, H2, H3) help AI understand content organization. Bullet points and numbered lists are preferred over dense paragraphs. Schema markup (FAQ, HowTo, Product, Article schemas) provides explicit signals about content structure. Brands should also prioritize freshness—regular content updates, even minor ones, signal to AI that information is current and maintained. Author credibility becomes a competitive advantage; bylines with verified credentials, professional affiliations, and publication history increase citation likelihood.
AI Source Selection is rapidly evolving as AI systems become more sophisticated and as the competitive landscape for AI visibility intensifies. Multimodal source selection is emerging, where AI systems evaluate not just text but also images, videos, and structured data. Real-time source verification is becoming more common, with AI systems checking source credibility in real-time rather than relying solely on pre-computed authority scores. Personalized source selection is being explored, where the sources cited vary based on user profile, location, and previous interactions. Adversarial robustness is becoming critical, as bad actors attempt to manipulate source selection through coordinated campaigns or synthetic content. Transparency and explainability are increasing, with AI systems providing more detailed explanations of why specific sources were selected.
The competitive dynamics are also shifting. As more brands optimize for AI visibility, the citation slots (typically 3-9 sources per answer) become increasingly contested. Niche authority is becoming more valuable—being the top source in a specific subtopic can earn citations even without overall domain authority. Community-driven authority is rising in importance, with platforms like Reddit and Quora gaining influence as AI systems recognize the value of peer perspectives. Real-time content is becoming more valuable, as AI systems increasingly incorporate live web search results. Original research and unique data are becoming critical differentiators, as AI systems recognize that synthesized content is less valuable than primary sources. The brands that will win in this landscape are those that combine traditional authority-building (backlinks, media coverage) with new tactics (platform presence, content structure, freshness, original research).
For brands seeking visibility in AI-powered search, the implications are profound. First, traditional SEO remains foundational—76.1% of AI-cited URLs rank in Google’s top 10, meaning strong organic rankings are still the most reliable path to AI visibility. However, ranking alone is insufficient. Second, brand authority must be built across multiple channels. A brand mentioned only on its own website will struggle to be cited; brands mentioned in news articles, industry publications, social media discussions, and community forums are far more likely to be selected. Third, content must be structured for AI extraction. Dense paragraphs, buried answers, and poor organization reduce citation likelihood regardless of content quality. Fourth, freshness matters more than ever. Regular updates, even minor ones, signal to AI that content is maintained and current. Fifth, platform diversity is critical. Brands should maintain presence on YouTube, Reddit, LinkedIn, and industry-specific platforms where AI systems actively search for sources.
For publishers and content creators, the implications are equally significant. Original research and unique data become competitive advantages, as AI systems recognize that synthesized content is less valuable than primary sources. Expert bylines with verified credentials increase citation likelihood. Comprehensive topic coverage (addressing not just the primary query but related subtopics) improves chances of being selected. Clear, scannable formatting with lists, tables, and FAQs makes content more extractable. Transparent sourcing (citing primary research, linking to original studies) builds credibility with AI systems. Regular updates and versioning signal that content is maintained. The brands and publishers that thrive will be those that recognize AI Source Selection as a distinct discipline requiring dedicated strategy, measurement, and optimization.
Measuring AI Source Selection performance requires new metrics and tools. Citation frequency tracks how often a brand appears in AI-generated responses for relevant queries. Share of voice measures citation frequency relative to competitors. Citation sentiment assesses whether citations present the brand positively, neutrally, or negatively. Brand mention volume serves as a leading indicator of citation likelihood. Tools like Semrush AI Toolkit, Ahrefs Brand Radar, ZipTie, and Rankscale now provide granular visibility into AI citation patterns across platforms. However, measurement remains challenging because AI platforms don’t provide detailed impression data like Google Search Console does for traditional search. Most brands must rely on sampling—monitoring a representative set of queries and tracking citation patterns over time. Despite these challenges, measurement is critical; brands that don’t track AI visibility are flying blind in a landscape where AI search traffic is growing 9.7x faster than traditional organic search.
+++
AI systems evaluate sources across five core dimensions: domain authority (backlink profiles and reputation), content relevance (semantic alignment with queries), freshness (recency of updates), topical expertise (depth of coverage), and credibility signals (E-E-A-T: Experience, Expertise, Authoritativeness, Trustworthiness). Research shows brand mentions correlate 3x more strongly with AI citations than backlinks, fundamentally changing how authority is measured in the AI search era.
Traditional SEO relies heavily on backlinks and keyword optimization, while AI Source Selection prioritizes brand mentions, content structure, and conversational authority. Studies show 76.1% of AI-cited URLs rank in Google's top 10, but 24% come from outside the top 10, indicating AI uses different evaluation criteria. AI also weights content freshness more heavily, with 76.4% of ChatGPT's most-cited pages updated within 30 days.
Each AI platform has distinct algorithms, training data, and selection criteria. ChatGPT favors Wikipedia (16.3% of citations) and news outlets, Perplexity prefers YouTube (16.1%), and Google AI Overviews lean toward user-generated content like Reddit and Quora. Only 12% of sources cited match across all three platforms, meaning success requires platform-specific optimization strategies tailored to each system's preferences.
RAG is the technical foundation enabling AI systems to ground responses in external data sources. It retrieves relevant documents from knowledge bases, then uses language models to synthesize answers while maintaining citations. RAG systems evaluate source quality through ranking algorithms that assess authority, relevance, and credibility before incorporating sources into final responses, making source selection a critical component of RAG architecture.
Content structure is critical for AI extractability. Listicles achieve 25% citation rates versus 11% for narrative blogs. AI systems favor clear hierarchical organization (H1, H2, H3 tags), bullet points, tables, and FAQ sections because they're easier to parse and extract. Pages with structured data markup (schema) see 30% higher citation likelihood, making format and organization as important as content quality itself.
Yes, through strategic optimization. Building brand authority across multiple platforms, publishing fresh content regularly, implementing structured data markup, and earning mentions on authoritative third-party sites all increase citation likelihood. However, AI Source Selection cannot be directly manipulated—it rewards genuine expertise, credibility, and user value. The focus should be on creating content that naturally deserves to be cited.
Approximately 40.58% of AI Overview citations come from Google's top 10 results, with 81.10% probability that at least one top-10 source appears in any AI-generated answer. However, 24% of citations come from pages outside the top 10, and 14.4% from pages ranking beyond position 100. This shows traditional rankings matter but don't guarantee AI citations, and strong content structure can overcome lower rankings.
Start tracking how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms. Get actionable insights to improve your AI presence.
Discover how ChatGPT selects and cites sources when browsing the web. Learn about credibility factors, search algorithms, and how to optimize your content for A...
Learn how AI systems select which sources to cite versus paraphrase. Understand citation selection algorithms, bias patterns, and strategies to improve your con...

Learn how AI systems build source pools and select which websites to cite. Understand the factors influencing source pool composition and how to optimize your c...